大家好,又见面了,我是你们的朋友全栈君。
说明:CAS是国科大的简称,KG是知识图谱的缩写,这个栏目之下是我整理的国科大学习到的知识图谱的相关笔记。
课程目标
- 了解以知识图谱为代表的大数据知识工程的基本问题和方法
- 掌握基于知识图谱的语义计算关键技术
- 具备建立小型知识图谱并据此进行数据分析应用的能力
教学安排
详情请见博客:CAS-KG——课程安排
文章目录
1. 概述
什么是推理
- 人类一直强调人的智能是如何获得的——不是靠反射机制而是对知识的内部表示进行操作的推理过程。
- 推理是逻辑学、哲学、心理学、人工智能等学科中的重要概念。早在古希腊时期,著名哲学家亚里斯多德就提出三段论作为现代演绎推理的基础。在计算机科学及人工智能领域,推理是一个按照某种策略从已知事实出发去推出结论的过程。
- 推理就是通过已知知识推断出未知知识的过程。
- 推理,逻辑学指思维的基本形式之一,是由一个或几个已知的判断(前提)推出新判断(结论)的过程,有直接推理、间接推理等。——《现代汉语词典第6版》
➢ 事件必定有其原因,事件背后必定有其真相。
➢ 通过推理可以预测未来,甚至确定人类未来发展的明细。
➢ 任何一个推理都包含已知判断、新的判断和一定的推理形式。作为推理的已知判断叫前提,根据前提推出新的判断叫结论。前提与结论的关系是理由与推断,原因与结果的关系。
知识推理的分类
归纳推理与演绎推理
-
归纳推理 (induction):归纳是从特殊到一般的过程。所谓归纳推理,就是从一类事物的大量特殊事例出发,去推出该类事物的一般性结论。我们熟知的数学归纳法就是归纳推理的一个典型例子。


-
演绎推理 (deduction):演绎是从一般到特殊的过程。所谓演绎推理,就是从一般性的前提出发,通过演绎(即推导),得出具体陈述或个别结论的过程。最经典的演绎推理就是三段论 (syllogism),它包括一个一般性原则(大前提)、一个附属于大前提的特殊化陈述(小前提),以及由此引申出的特殊化陈述符合一般性原则的结论。

演绎推理不仅仅局限于三段论,也不只是从一般到特殊的过程。它有着强烈的演绎特性,重在通过利用每一个证据,逐步地推导到目标或以外的结论,多被用于数学物理证明、思维推导等各类应用。

-
演绎推理与归纳推理的区别:
演绎推理是在已知领域内的一般性知识的前提下,通过演绎求解一个具体问题或者证明一个结论的正确性。它所得出的结论实际上早已蕴含在一般性知识的前提中,演绎推理只不过是将已有事实揭示出来,因此它不能增殖新知识。而相反,归纳推理所推出的结论是没有包含在前提内容中的。这种由个别事物或现象推出一般性知识的过程,是增殖新知识的过程。
确定性推理与不确定性推理
-
确定性推理:确定性推理大多指确定性逻辑推理,它具有完备的推理过程和充分的表达能力,可以严格地按照专家预先定义好的规则准确地推导出最终结论。但是确定性推理很难应对真实世界中,尤其是存在于网络大规模知识图谱中的不确定甚至不正确的事实和知识。

-
不确定性推理:
不确定性推理也被称为概率推理,是统计机器学习中一个重要的议题。它并不是严格地按照规则进行推理,而是根据以往的经验和分析,结合专家先验知识构建概率模型,并利用统计计数、最大化后验概率等统计学习的手段对推理假设进行验证或推测。不确定性推理可以有效建模真实世界中的不确定性。
逻辑推理和非推理推理
- 逻辑推理:过程包含了严格的约束和推理过程(研究较多)。
- 非逻辑推理:推理过程相对模糊。
符号推理与数值推理
- 符号推理:符号推理的特点就是在知识图谱中的实体和关系符号上直接进行推理。确定性和不确定性逻辑推理都属于符号推理。
- 数值推理:与符号推理相对的就是数值推理。数值推理就是使用数值计算,尤其是向量矩阵计算的方法,捕捉知识图谱上隐式的关联,模拟推理的进行。本节中介绍的数值推理方法特指基于分布式知识表示的推理。
面向知识图谱应用的知识推理
知识图谱需要推理,主要体现在两种任务上:
- 知识库补全:也称知识图谱上的链接预测,其本质是根据知识库中已有的知识推断出新的、未知的知识。知识库补全可以用来建立更全面的知识库,是知识库构建的重要手段之一。
- 知识库问答:基于知识库的问答主要是通过对自然问句的解析,再从知识库中寻找答案的过程。但由于知识库中知识不完备等原因,知识库问答也需要推理技术的支撑。
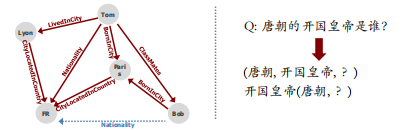
2. 归纳推理:学习推理规则
基于规则的推理:精准+可解释
- 规则学习:自动化的规则获取
典型的推理规则:一阶谓词逻辑规则

规则对于推理的作用
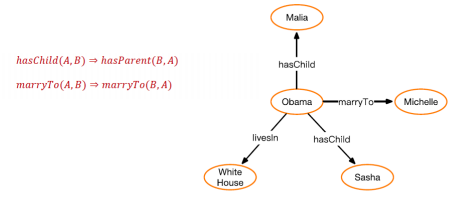
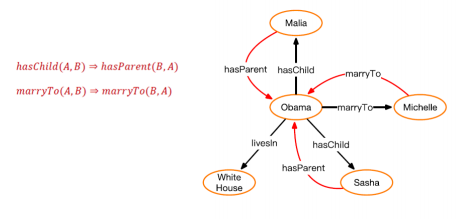
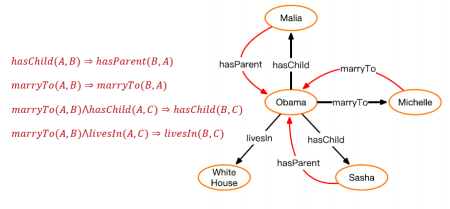
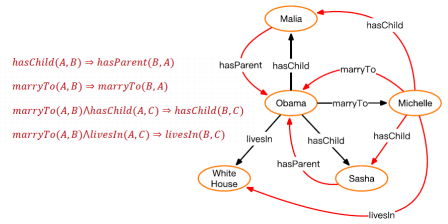
归纳逻辑程序设计
归纳逻辑程序设计(Inductive Logic Programming, ILP)使用一阶谓词逻辑来进行知识表示,通过修改和扩充逻辑表达式来完成对数据的归纳。

FOIL算法
FOIL (First Order Inductive Learner) [Quinlan, 1990] 利用序贯覆盖实现规则的学习,其基本流程为:
- ① 从空规则“? ←”开始,将目标谓词作为规则头
- ② 逐一将其他谓词加入规则体进行考察,按预定标准评估规则的优劣并选取最优规则
- ③ 将该规则覆盖的训练样例去除,以剩下的训练样例组成训练集重复上述过程
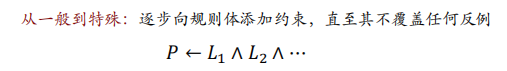
FOIL规则评估

FOIL算法示例
利用FOIL算法找到定义目标谓词 DaughterOf 的规则



传统ILP问题 VS 知识图谱
传统ILP问题:
- 谓词可以是多元的
- 需要目标谓词的正例与反例
- 封闭世界假设(Closed Word Assumption)
• 所有未声明是正例的样本全都是反例
知识图谱:
- 谓词几乎都是二元的
- 知识图谱一般不显式表示谓词的反例
- 开放世界假设(Open Word Assumption)
• 未声明是正例的样本既可以是反例,也可以是未知类别的样本
扩展阅读:Neural Logic Machines
Neural Logic Machine (NLM), a neural symbolic architecture for both inductive learning and logic reasoning.

关联规则挖掘
推理规则概述
规则:包含规则主体(body)和规则头(head)两部分

规则学习评估方法

AMIE:不完备知识库中的关联规则挖掘
AMIE (Association Rule Mining under Incomplete Evidence) [Galárraga et al., 2013] 支持从不完备的知识库中,挖掘闭式(closed)规则
- 两个谓词共享一个变量或实体,则称其为连通的。
- 规则中任意两个谓词可通过连通关系的传递性相连,则称该规则为连通的。
- 规则是连通的并且其中的变量都至少出现两次,则称其为闭式(closed)逻辑规则。
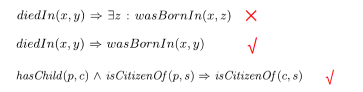
AMIE依次学习预测每种关系的规则。对于每种关系,从规则体为空的规则开始,通过三种操作扩展规则体部分,保留支持度大于阈值的候选(闭式)规则。

AMIE工作流程示意
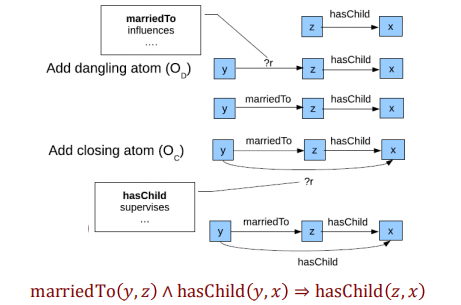
AMIE规则评估
- 支持度 (support):同时符合规则体和规则头的实例数目
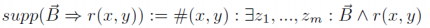
- 置信度 (confidence):支持度除以仅符合规则体的实例数目
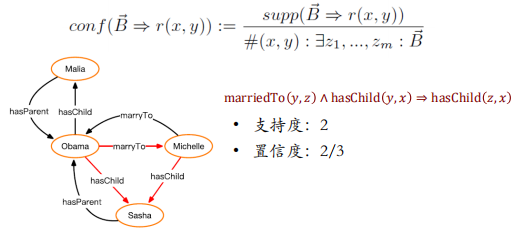
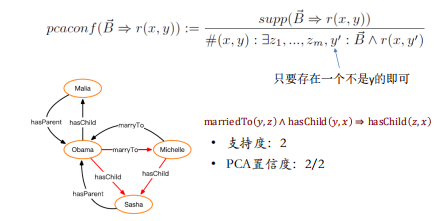
封闭世界假设 (Closed World Assumption):知识库中不存在的事实都是错误的
所以提出:
部分完整性假设 (Partial Completeness Assumption)
- 开放世界假设 (Open World Assumption):知识库中不存在的事实不一定是错误的
- 部分完整性假设 (Partial Completeness Assumption) :在知识库中,如果存在某个实体 ? 的关系 ? 属性,则知识库中包含了 ? 的所有关系 ? 属性
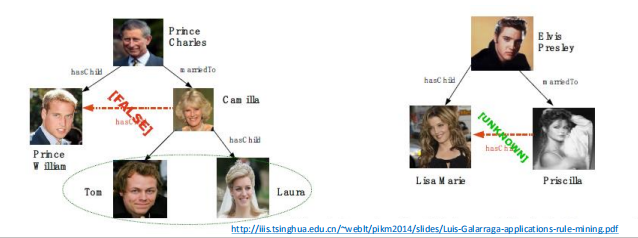
AMIE规则评估

路径排序算法
知识图谱中规则与关系路径
知识图谱中包含的仅仅是实体间的二元关系,因此规则与知识图谱中的关系路径存在对应关系。
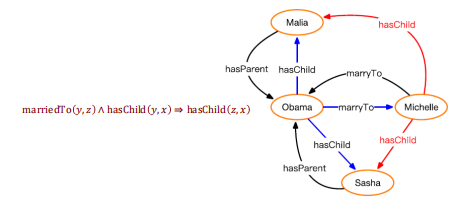
路径排序算法
PRA (Path Ranking Algorithm) [Lao et al., 2011] 以实体间的路径作为特征,来学习目标关系的分类器。
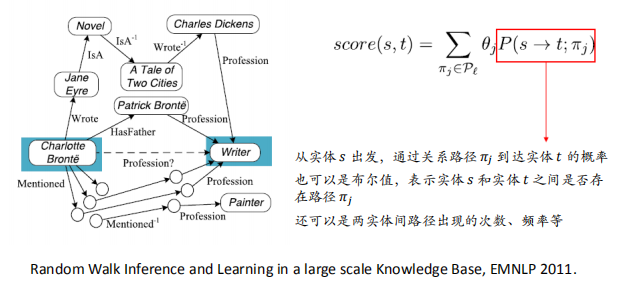
加粗样PRA工作流程式
- 特征抽取:生成并选择路径特征集合
- 特征计算:计算每个训练样例的特征值
- 分类器训练:根据训练样例,为每个目标关系训练一个分类器
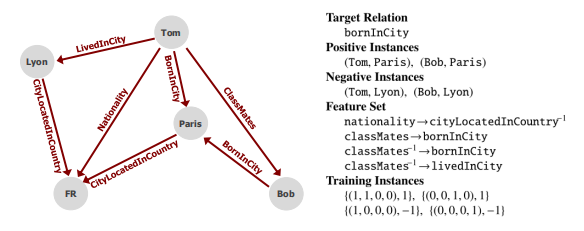

- PRA规则学习:根据分类器权重自动挖掘并筛选可靠规则
- PRA在Freebase上挖掘出的规则

PRA挖掘路径和规则

3. 演绎推理:推理具体事实
基于规则的直接推理
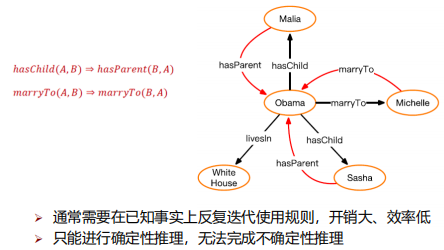
马尔可夫逻辑网
马尔可夫逻辑网 (Markov Logic Network) [Richardson and Domingos, 2006] 是将概率图模型与一阶谓词逻辑相结合的一种统计关系学习模型,其核心思想是通过为规则绑定权重的方式将一阶谓词逻辑规则中的硬性约束(hard constraints)进行软化。
- 一阶谓词逻辑知识库可看作是在一个可能世界的集合上建立一系列硬性规则,即如果一个世界违反了其中的某一条规则,那么这个世界的存在概率即为零。
- 马尔可夫逻辑网的基本思想是让那些硬性规则有所松弛,即当一个世界违反了其中的一条规则,那么这个世界存在的可能性将降低,但并非不可能。一个世界违反的规则越少,那么这个世界存在的可能性就越大。
- 为此,马尔可夫逻辑网给每条规则都加上一个特定的权重来反映其约束强度。规则的权重越大,其约束能力越强,即对于满足和不满足该规则的两个世界而言,它们之间的差异将越大。当规则的权重设置为无穷大时,其退化为硬性规则。
绑定权重的规则示例
- 这些规则在现实世界中通常是真的,但不总是真的,并且它们有着不同的成立概率。

马尔可夫逻辑网形式化定义


从马尔可夫逻辑网的定义出发,很容易得到一个图结构:
- 每个原子事实对应于图中的一个节点。
- 当两个节点所表示的原子事实出现在同一个实例化规则之中时,这两个节点之间存在一条边。
- 所有出现在同一个实例化规则之中的原子事实组成了一个团。
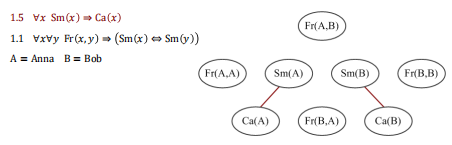
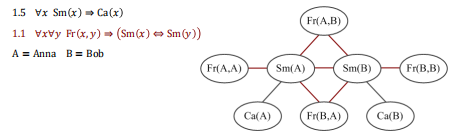
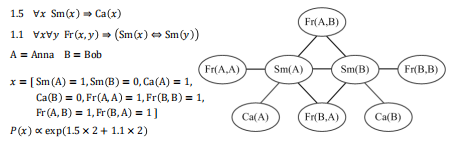
利用马尔可夫逻辑网对知识图谱进行建模后,我们可以:
- 当规则及其权重已知时:推断知识图谱中任意未知事实成立的概率(马尔可夫随机场的推断问题)
证据变量为知识图谱中的已知事实,问题变量为未知事实 - 当规则已知但其权重未知时:自动学习每条规则的权重(马尔可夫随机场的参数学习)
- 当规则及其权重均未知时:自动学习规则及其权重(马尔可夫随机场的结构学习),这实际上属于我们讨论过的归纳推理的范畴
概率软逻辑
概率软逻辑 (Probabilistic Soft Logic) [Kimmig et al., 2012]是马尔可夫逻辑网的进一步延伸,其最大优点是允许原子事实的真值可以在连续的 【0,1】 区间内任意取值,而不像马尔可夫逻辑网那样只能取 {0,1} 中的离散值。
- 马尔可夫逻辑网:给一阶谓词逻辑加入了出色的不确定性处理能力,通过建模不确定性规则,能够容忍知识库中存在的不完整性和矛盾性等问题。
- 概率软逻辑:进一步增强了马尔可夫逻辑网的不确定性处理能力,能够同时建模不确定性的规则和事实。并且连续真值的引入使得推理从原本的离散优化问题简化为连续优化问题,大大提升了推理效率。

概率软逻辑建模示例

给定一组原子事实和绑定权重的规则,概率软逻辑计算所有可能的原子事实真值取值 ? 的概率分布。更形式化地,用 ? 表示实例化的规则集合,? ∈ ? 表示一条实例化规则,那么 ? 的概率分布如下:
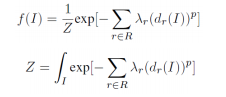
其中 ?? 是规则 ? 的权重,? 是连续型的马尔可夫随机场规范化因子,? ∈ {1,2} 提供了两种不同的损失函数
利用概率软逻辑对知识图谱进行建模后,我们可以:
- 当规则及其权重已知时:推断知识图谱中任意未知事实成立的概率(马尔可夫随机场的推断问题)
证据变量为知识图谱中的已知事实,问题变量为未知事实 - 当规则已知但其权重未知时:自动学习每条规则的权重(马尔可夫随机场的参数学习)
- 当规则及其权重均未知时:自动学习规则及其权重(马尔可夫随机场的结构学习),这实际上属于我们讨论过的归纳推理的范畴
PSL推理应用示例:事件识别
事件触发词的歧义性问题

解决方法:同时考虑多层次信息对触发词进行消歧,包括深层局部信息和全局信息
- 深层局部信息
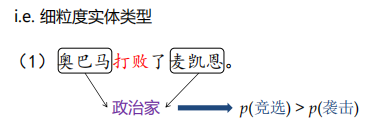
- 全局信息

事件识别方法
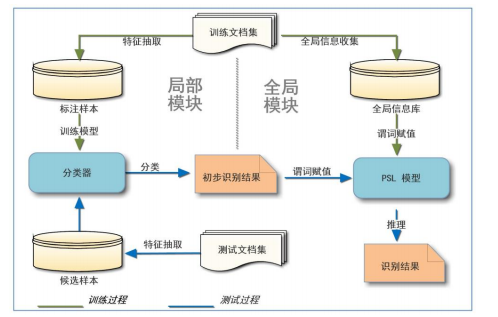
全局模块
- 目标: 联合局部模型的初步分类信息和全局信息进行全局推理
- 模型: 概率软逻辑模型(PSL)
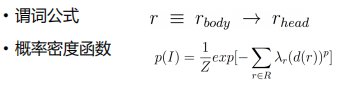
全局信息——事件之间的相关性

全局模块的谓词公式

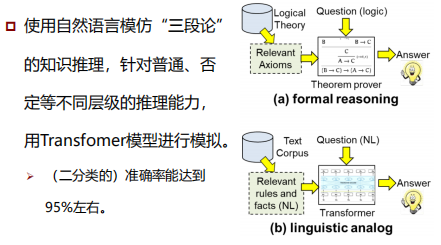
前沿:Soft Reasoners over Language
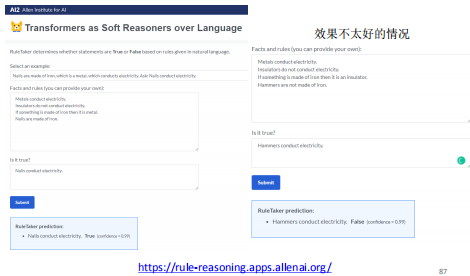
4. 基于分布式表示的推理
知识库/知识图谱
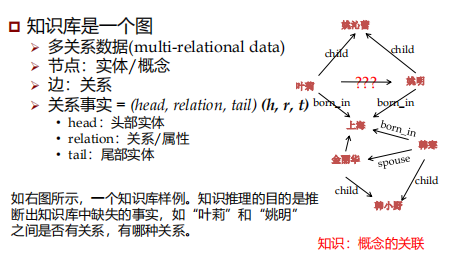
推理模式
人类进行推理时,往往呈现出以下两个特点:
- 考虑尽可能多的因素,全局推理。实际中,考虑的影响因素越全面,就越有可能得到正确的推理结论。
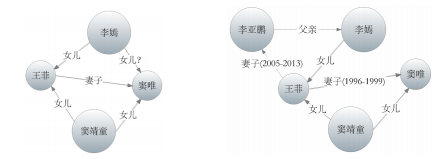
- 人的智能表现在可以利用潜在的推理模式,而这些推理模式难以穷举。有些事物之间虽然没有呈现出显式的联系,但有可能存在尚未探知的隐式规律。
符号推理 VS. 数值推理
- 之前介绍的几种归纳和演绎推理方法都属于符号推理的范畴,即在知识图谱中的实体和关系符号上直接进行推理。
- 与符号推理相对的就是数值推理,即使用数值计算,尤其是向量矩阵计算的方法,捕捉知识图谱上隐式的关联,模拟推理的进行。基于分布式知识表示的推理就是典型的数值推理方法。
➢ 捕捉实体和关系之间的隐式关联
➢ 分布式空间映射对特征间的复杂关系进行了解耦,减少了维数灾难问题(curse of dimensionality)
➢ 使符号数据可以直接参与运算且计算速度非常快
分布式知识表示
分布式知识表示(Knowledge Graph Embedding)的核心思想是将符号化的实体和关系在低维连续向量空间进行表示,在简化计算的同时最大程度保留原始的图结构
[Wang et al., 2017]。
基本步骤:
- 实体关系表示:定义实体和关系在向量空间中的表示形式(向量/矩阵/张量)。
- 打分函数定义:定义打分函数,衡量每个三元组成立的可能性。
- 表示学习:构造优化问题,学习实体和关系的低维连续向量表示。
基于分布式知识表示的推理
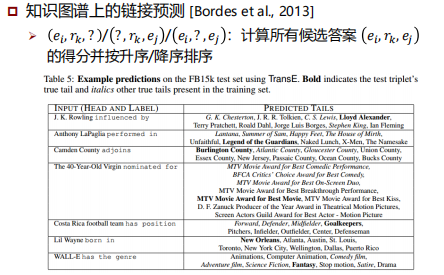
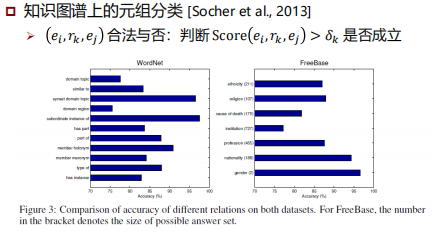
评测任务与数据集

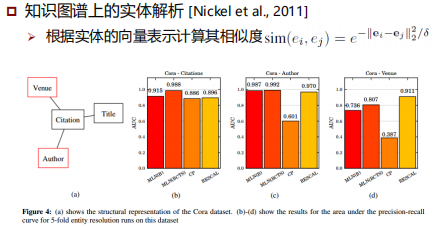
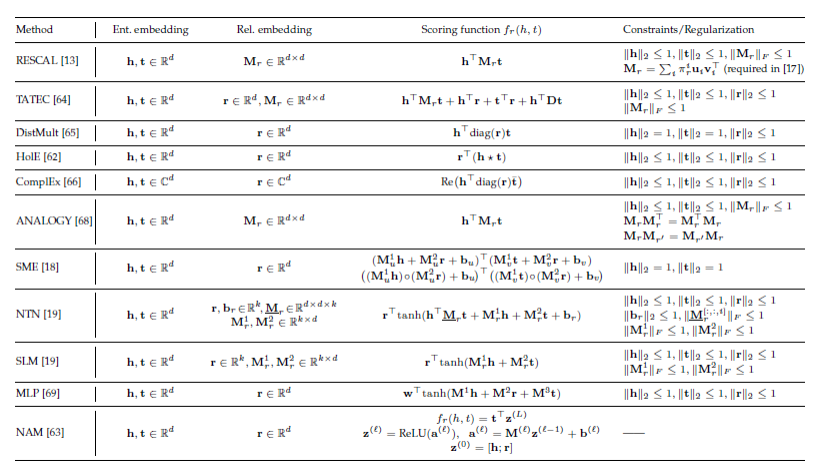
分布式知识表示方法分类
- 位移距离模型 (translational distance models):采用基于距离的打分函数来衡量三元组成立的可能性。
- 语义匹配模型 (semantic matching models):采用基于相似度的打分函数来衡量三元组成立的可能性
位移距离模型:TransE

TransE模型的不足

TransE模型的改进


位移距离模型总结

语义匹配模型
计算实体和关系在隐式向量空间的语义匹配程度,以此来判断三元组成立的可能性
- 简单匹配模型:RESCAL及其变种
将头实体和尾实体的表示进行组合后再与关系的表示进行匹配,即 Mathcing (????????, Composition (ℎ???,????)) - 复杂匹配模型:深度神经网络
利用较为复杂的神经网络结构完成实体和关系的语义匹配,即 NueralMatching (ℎ???, ????????,????)
RESCAL及其变种
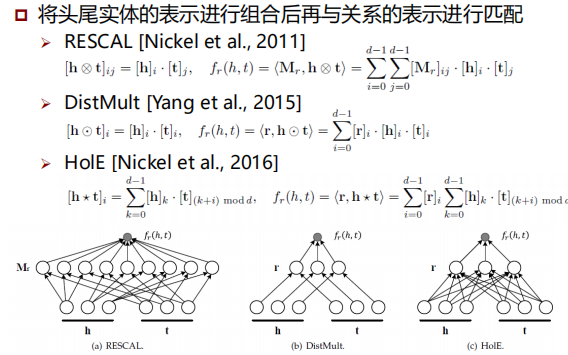
深度神经网络
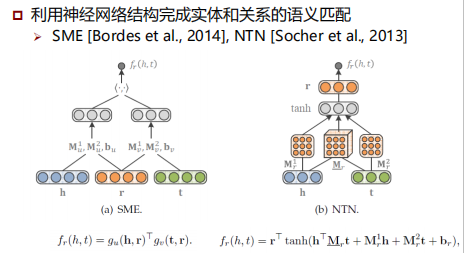

语义匹配模型总结
模型训练




融合多元化信息的分布式知识表示
上述分布式知识表示方法仅用到了知识图谱中的三元组信息,还有多种其他类型的信息也被证实能够提升分布式知识表示的效果。

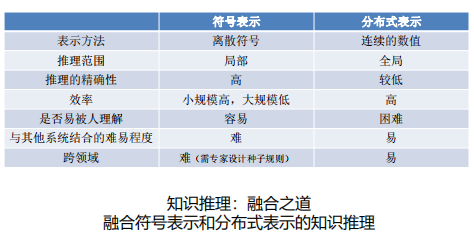
符号推理与分布式表示推理的比较
问题定义与现有两类方法
- 知识推理
➢ 仅从现有的知识库中,根据知识库的网络结构、元素关系等,预测出实体与实体间可能存在的链接,并加入到原有的知识库中,使之更加完备。 - 基于表示学习的方法
➢ 用低维向量对元素进行表示
➢ 用相似度衡量元组成立的可能性
➢ 在获得向量表示后,相似度计算容易、速度快
➢ 推理准确性不能让人满意 - 基于逻辑推理的方法
➢ 人工构造或筛选规则
➢ 推理相对准确,可解释
➢ 推理噪声较大
➢ 推理规模大,计算复杂,难以在短时间内完成推理
方法融合与动机
- 融合逻辑推理和表示学习两种方法
➢ 串行地合并表示学习和逻辑推理两种方法
➢ 表示学习方法先选出小规模备选
➢ 逻辑推理方法进一步做精确推理 - 动机
➢ 继承表示学习方法计算速度快的优点
➢ 快速构建了规模小覆盖度高的推理空间
➢ 逻辑推理在较小的推理空间上能够更加精确的推理
➢ 推理过程中的噪声已由向量表示方法过滤
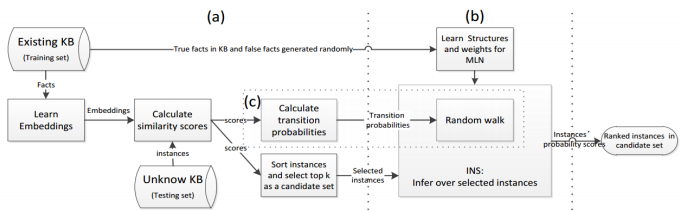
融合框架
- 使用表示学习方法对知识库中的元素进行向量化的表示
- 用马尔科夫逻辑网的方法在候选集上进行推理
- 将向量化中得到的候选元组的相似度值作为随机游走的状态转移概率注入到逻辑推理中
前沿:基于表示学习获取推理规则

前沿:时序预测推理

前沿:低资源知识推理
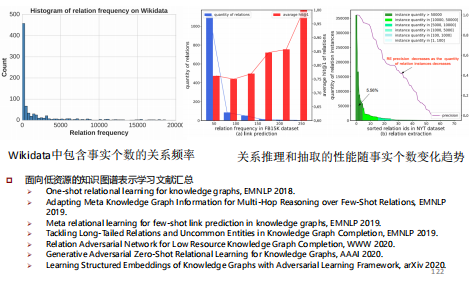
One-shot relational learning for knowledge graphs, EMNLP 2018.

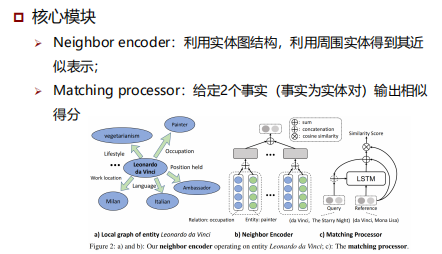
Meta relational learning for few-shot link prediction in knowledge graphs, EMNLP 2019

5. 总结
面向知识图谱应用的知识推理
知识推理的分类
推理规则概述
符号推理 VS. 数值推理
分布式知识表示
未来发展

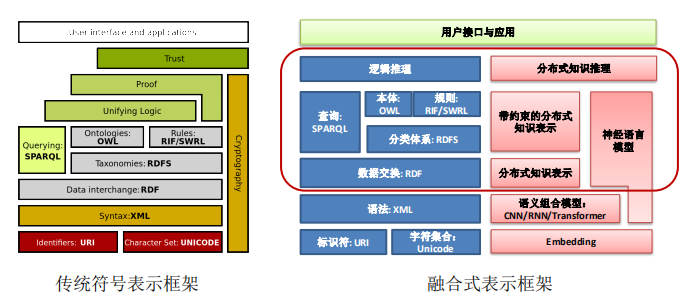
符号表示与分别式表示融合知识体系
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140861.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
