大家好,又见面了,我是你们的朋友全栈君。
概念
变异系数
- Coefficient of Variation
- 计算公式: 变 异 系 数 = 标 准 差 / 平 均 值 变异系数=标准差/平均值 变异系数=标准差/平均值
- 比较 两组 量纲不同的数据 的 离散程度,不能用标准差,可考虑变异系数
不适用场景:数据下限小于0(导致平均值近0)
变异系数越大,离散程度越大
变异系数权重法
- 通过变异系数来赋权
- 计算方法: 权 重 i = 变 异 系 数 i / 全 部 变 异 系 数 的 和 权重_i=变异系数_i / 全部变异系数的和 权重i=变异系数i/全部变异系数的和
- 离散程度较大的列会获得较高的权重参数
- 使用变异系数计得的权重值会随着数据的变化而变化
- 该方法应用场景不多,通常不建议使用
什么场景考虑使用?没有标签 且 缺乏业务经验 时
Min-Max标准化
- 计算方法: 新 数 据 = ( 原 数 据 − 最 小 值 ) / ( 最 大 值 − 最 小 值 ) 新数据 = ( 原数据 – 最小值 ) / ( 最大值 – 最小值 ) 新数据=(原数据−最小值)/(最大值−最小值)
- 效果:
1、数据映射到[0,1]
2、消除量纲差异
3、放大差距 - 场景:
老师给学生评分(主观评分,如:文明分、品德分…)时,分数的区间是[0,100],即使有些学生很顽劣,也不会低于80分,结果所有学生的分数在80~100,优劣学生之间相差不到20%;使用Min-Max标准化或许可以还原出学生之间真实差距
Python代码实现+效果可视化
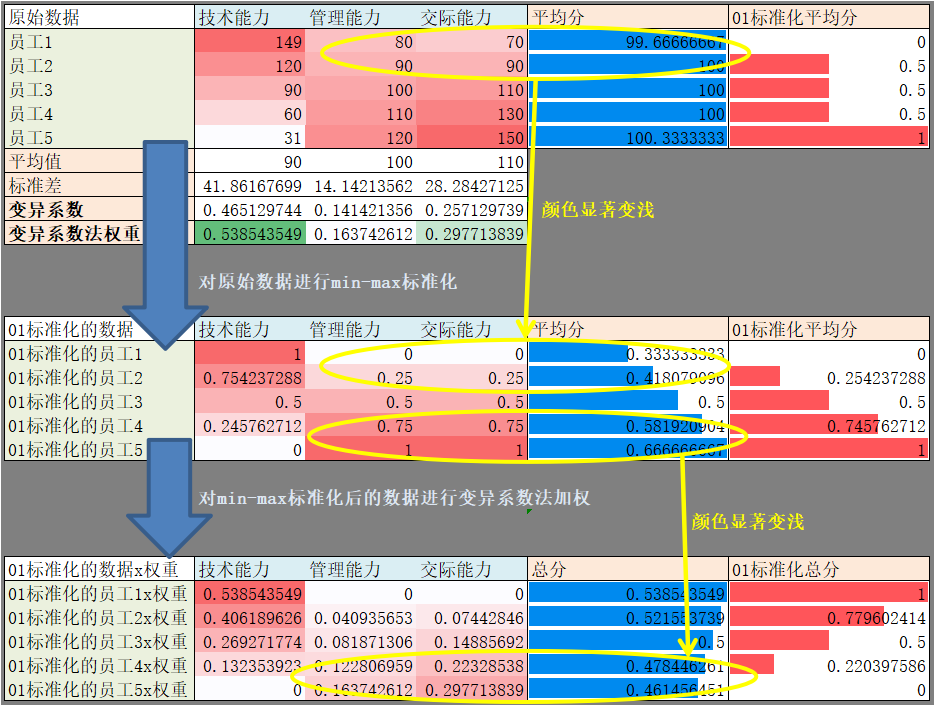

-
原始数据(第1个表)
-
平均分 可理解为 全部特征的权重相等
5个员工平均分差别不大
员工1最弱逼,员工5最流弊,员工234相等
对平均分进行min-max标准化后,员工1的弱逼程度被放大
技术能力的变异系数最大,权重最高 - 员工4>3>2(不再相等)
- 员工1反而变得最流弊,员工5反而变得最弱比
MinMax标准化后的数据的平均分(第2个表)
对min-max标准化后的数据进行变异系数法加权(第3个表)
from pandas import DataFrame, Series
from sklearn.preprocessing import minmax_scale
from numpy import ndarray
# 原始数据
df: DataFrame = DataFrame({
'员工编号': ['员工1', '员工2', '员工3', '员工4', '员工5'],
'技术能力': [149, 120, 90, 60, 31],
'管理能力': [80, 90, 100, 110, 120],
'交际能力': [70, 90, 110, 130, 150],
})
print(df)
# 变异系数
coefficient_of_variation: Series = df.std() / df.mean()
print(coefficient_of_variation)
# 权重
weight: Series = coefficient_of_variation / sum(coefficient_of_variation)
print(weight)
# 对原始数据进行Min-Max标准化
mm: ndarray = minmax_scale(df[df.columns[1:]])
print(mm)
# Min-Max标准化后的数据与权重进行矩阵乘法,计算出总分
score: Series = mm.dot(weight)
print(score)
# 对总分进行MinMax标准化
df['MinMax标准化的总分']: Series = minmax_scale(score)
print(df['MinMax标准化的总分'])
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140815.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
