大家好,又见面了,我是你们的朋友全栈君。
参考https://blog.csdn.net/yilulvxing/article/details/105028902,
数据下载地址:tcs_stock_2018-05-26.csv
简单说明几点:
数据集result,按照0.8划分为train和test,train又按照0.8进一步划分为training samples和validating samples;
此案例的归一化只是简单的所有数据除以10000,感觉还需要改进
from __future__ import print_function
import pandas as pd
import tensorflow as tf
import os
df= pd.read_csv("D:\\work\\RS\\test\\20200927\\tcs_stock_2018-05-26.csv")
df.head()
# 将date 字段设置为索引
df = df.set_index('Date')
df.head()
# 弃用一些字段
drop_columns = ['Last','Total Trade Quantity','Turnover (Lacs)']
df = df.drop(drop_columns,axis=1)
df.head()
#统一进行归一化处理
df['High'] = df['High'] / 10000
df['Open'] = df['Open'] / 10000
df['Low'] = df['Low'] / 10000
df['Close'] = df['Close'] / 10000
print(df.head())
# 将dataframe 转化为 array
#data = df.as_matrix() ##FutureWarning: Method .as_matrix will be removed in a future version. Use .values instead.
data = df.values
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from pandas import datetime
import math
import itertools
from sklearn import preprocessing
import datetime
from sklearn.metrics import mean_squared_error
from math import sqrt
# 数据切分
result=[]
time_steps = 3
for i in range(len(data)-time_steps):
result.append(data[i:i+time_steps])
result=np.array(result)
#训练集和测试集的数据量划分
train_size = int(0.8*len(result))
print(train_size)
#训练集切分
train = result[:train_size,:]
x_train = train[:,:-1]
y_train = train[:,-1][:,-1]
x_test = result[train_size:,:-1]
y_test = result[train_size:,-1][:,-1]
# 举例:timestpes设置位6,则,用前5行数据,预测第6行的最后一个数据
# train
#[[[0.126695 0.12679 0.126 0.126415]
# [0.1267 0.12724 0.125555 0.12633 ]
# [0.1265 0.1284 0.125995 0.12806 ]
# [0.1285 0.1301 0.12809 0.12992 ]
# [0.13 0.1304 0.129025 0.129485]
# [0.1295 0.13043 0.12943 0.130025]]
# x_train
# [[[0.126695 0.12679 0.126 0.126415]
# [0.1267 0.12724 0.125555 0.12633 ]
# [0.1265 0.1284 0.125995 0.12806 ]
# [0.1285 0.1301 0.12809 0.12992 ]
# [0.13 0.1304 0.129025 0.129485]]
# y_train
#[0.130025]
print(x_train)
print(y_train)
print(x_test)
print(y_test)
feature_nums = len(df.columns)
#数据重塑
x_train = x_train.reshape(x_train.shape[0],x_train.shape[1],x_train.shape[2])
x_test = x_test.reshape(x_test.shape[0],x_test.shape[1],x_test.shape[2])
print("X_train", x_train.shape)
print("y_train", y_train.shape)
print("X_test", x_test.shape)
print("y_test", y_test.shape)
#模型构建
import math
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout, Flatten, Conv1D, MaxPooling1D
from keras.layers.recurrent import LSTM
from keras import losses
from keras import optimizers
def build_model(input):
model = Sequential()
model.add(Dense(128, input_shape=(input[0], input[1])))
model.add(Conv1D(filters=112, kernel_size=1, padding='valid', activation='relu', kernel_initializer='uniform'))
model.add(MaxPooling1D(pool_size=2, padding='valid'))
model.add(Conv1D(filters=64, kernel_size=1, padding='valid', activation='relu', kernel_initializer='uniform'))
model.add(MaxPooling1D(pool_size=1, padding='valid'))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(100, activation='relu', kernel_initializer='uniform'))
model.add(Dense(1, activation='relu', kernel_initializer='uniform'))
model.compile(loss='mse', optimizer='adam', metrics=['mae'])
return model
model = build_model([2, 4, 1])
# Summary of the Model
print(model.summary())
# 训练数据预测
from timeit import default_timer as timer
start = timer()
history = model.fit(x_train,
y_train,
batch_size=128,
epochs=100,
validation_split=0.2,
verbose=2)
end = timer()
print(end - start)
##训练集和测试集损失函数曲线绘制
# 返回history
history_dict = history.history
history_dict.keys()
# 画出训练集和验证集的损失曲线
import matplotlib.pyplot as plt
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
loss_values50 = loss_values[0:150]
val_loss_values50 = val_loss_values[0:150]
epochs = range(1, len(loss_values50) + 1)
plt.plot(epochs, loss_values50, 'b', color='blue', label='Training loss')
plt.plot(epochs, val_loss_values50, 'b', color='red', label='Validation loss')
plt.rc('font', size=18)
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.xticks(epochs)
fig = plt.gcf()
fig.set_size_inches(15, 7)
# fig.savefig('img/tcstest&validationlosscnn.png', dpi=300)
plt.show()
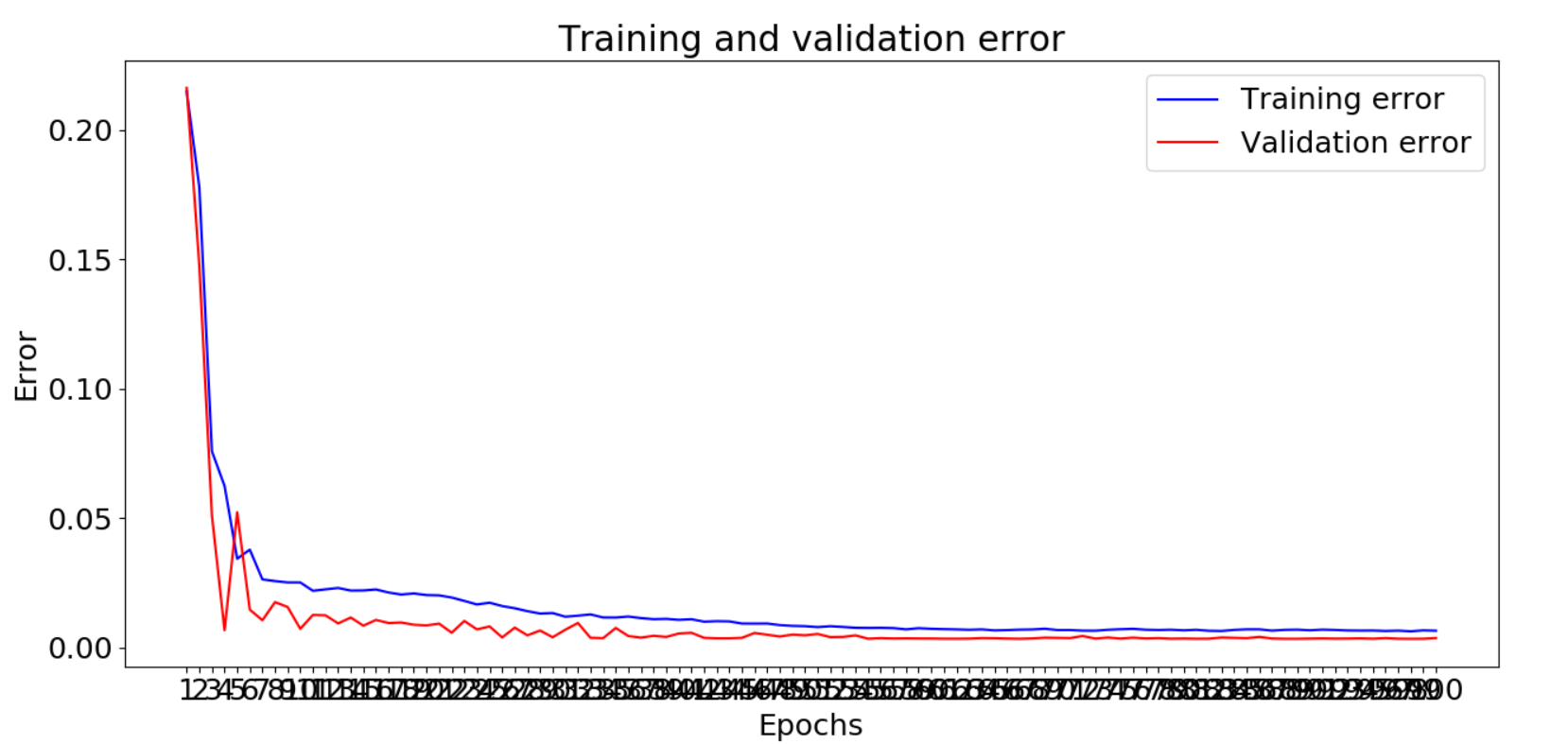
# 画出训练集和验证集的误差图像
mae = history_dict['mean_absolute_error']
vmae = history_dict['val_mean_absolute_error']
epochs = range(1, len(mae) + 1)
plt.plot(epochs, mae, 'b',color = 'blue', label='Training error')
plt.plot(epochs, vmae, 'b',color='red', label='Validation error')
plt.title('Training and validation error')
plt.xlabel('Epochs')
plt.ylabel('Error')
plt.legend()
plt.xticks(epochs)
fig = plt.gcf()
fig.set_size_inches(15,7)
#fig.savefig('img/tcstest&validationerrorcnn.png', dpi=300)
plt.show()
model.metrics_names
trainScore = model.evaluate(x_train, y_train, verbose=0)
testScore = model.evaluate(x_test, y_test, verbose=0)
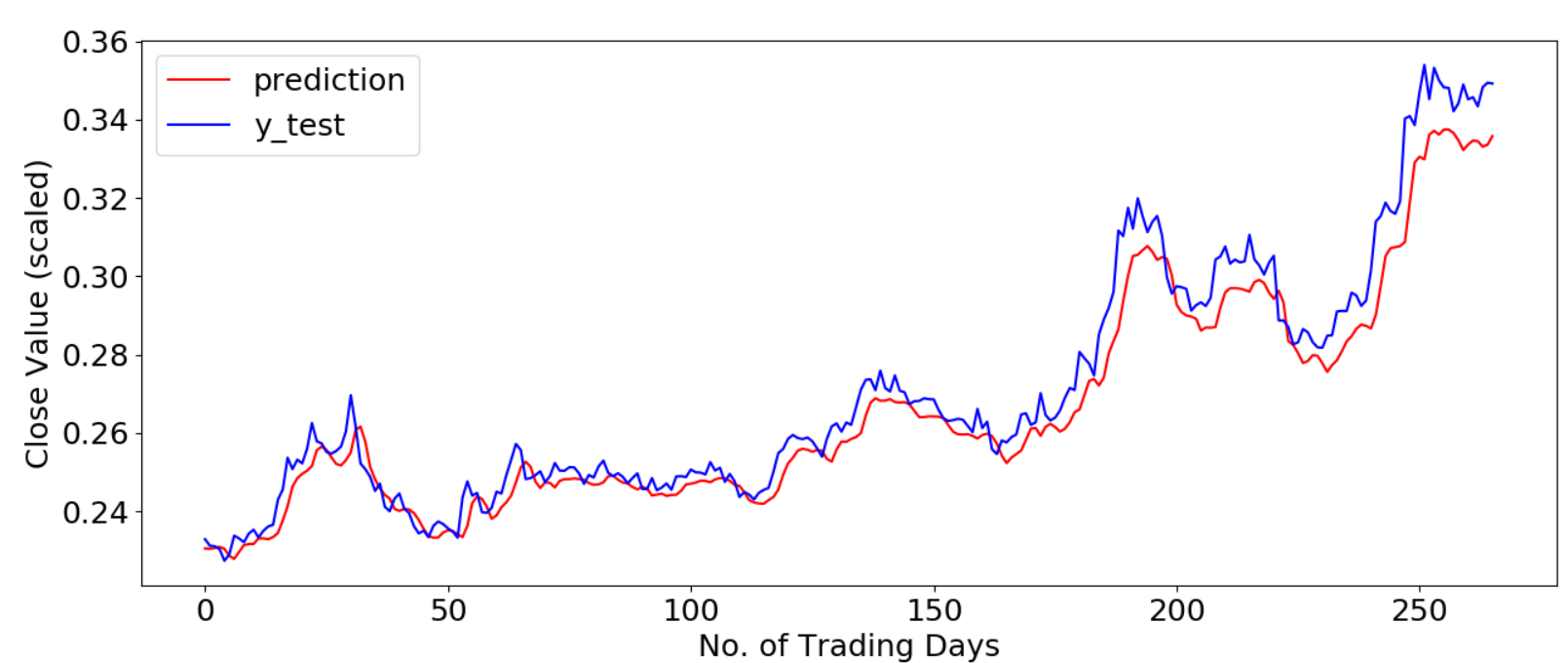
# 画出真实值和测试集的预测值之间的对比图像
p = model.predict(x_test)
plt.plot(p,color='red', label='prediction')
plt.plot(y_test,color='blue', label='y_test')
plt.xlabel('No. of Trading Days')
plt.ylabel('Close Value (scaled)')
plt.legend(loc='upper left')
fig = plt.gcf()
fig.set_size_inches(15, 5)
#fig.savefig('img/tcstestcnn.png', dpi=300)
plt.show()
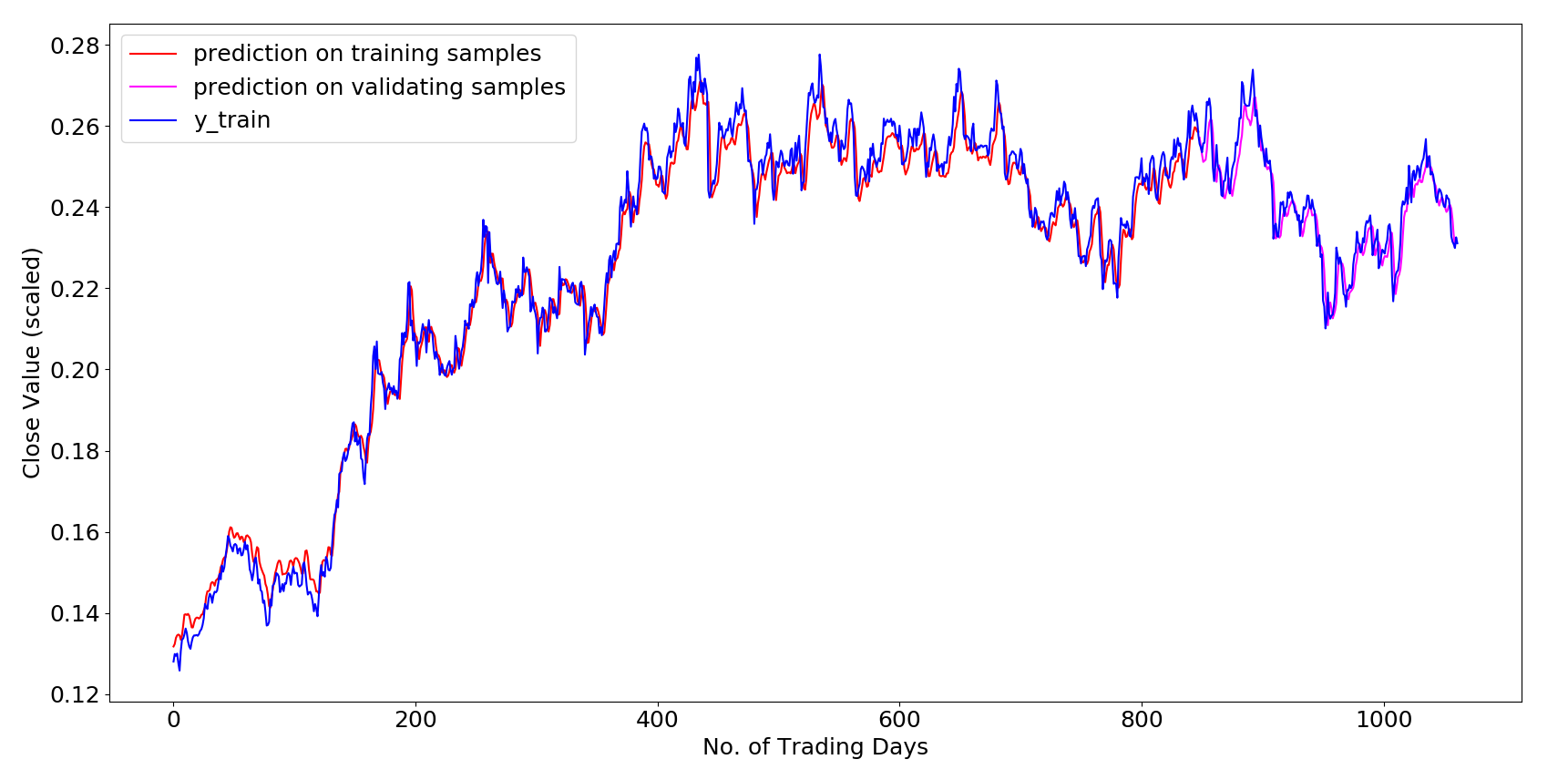
# 画出训练集中的预测值之间的误差图像
p1= model.predict(x_train)
print(p1.shape)
plt.plot(p1[:848],color='red', label='prediction on training samples')
x = np.array(range(848,1060))#848是train中的training samples和validating samples的分界,因为在前文中的model.fit中使用了validation_split=0.2,1060*0.8=848
plt.plot(x,p1[848:1060],color = 'magenta',label ='prediction on validating samples')
plt.plot(y_train,color='blue', label='y_train')
plt.xlabel('No. of Trading Days')
plt.ylabel('Close Value (scaled)')
plt.legend(loc='upper left')
fig = plt.gcf()
fig.set_size_inches(20,10)
#fig.savefig('img/tcstraincnn.png', dpi=300)
plt.show()
#将标准化的数据还原
y = y_test * 10000 # 原始数据经过除以10000进行缩放,因此乘以10000,返回到原始数据规模
y_pred = p.reshape(266) # 测试集数据大小为265
y_pred = y_pred * 10000 # 原始数据经过除以10000进行缩放,因此乘以10000,返回到原始数据规模
from sklearn.metrics import mean_absolute_error
print('Trainscore RMSE \tTrain Mean abs Error \tTestscore Rmse \t Test Mean abs Error')
print('%.9f \t\t %.9f \t\t %.9f \t\t %.9f' % (math.sqrt(trainScore[0]),trainScore[1],math.sqrt(testScore[0]),testScore[1]))
print('mean absolute error \t mean absolute percentage error')
print(' %.9f \t\t\t %.9f' % (mean_absolute_error(y,y_pred),(np.mean(np.abs((y - y_pred) / y)) * 100)))
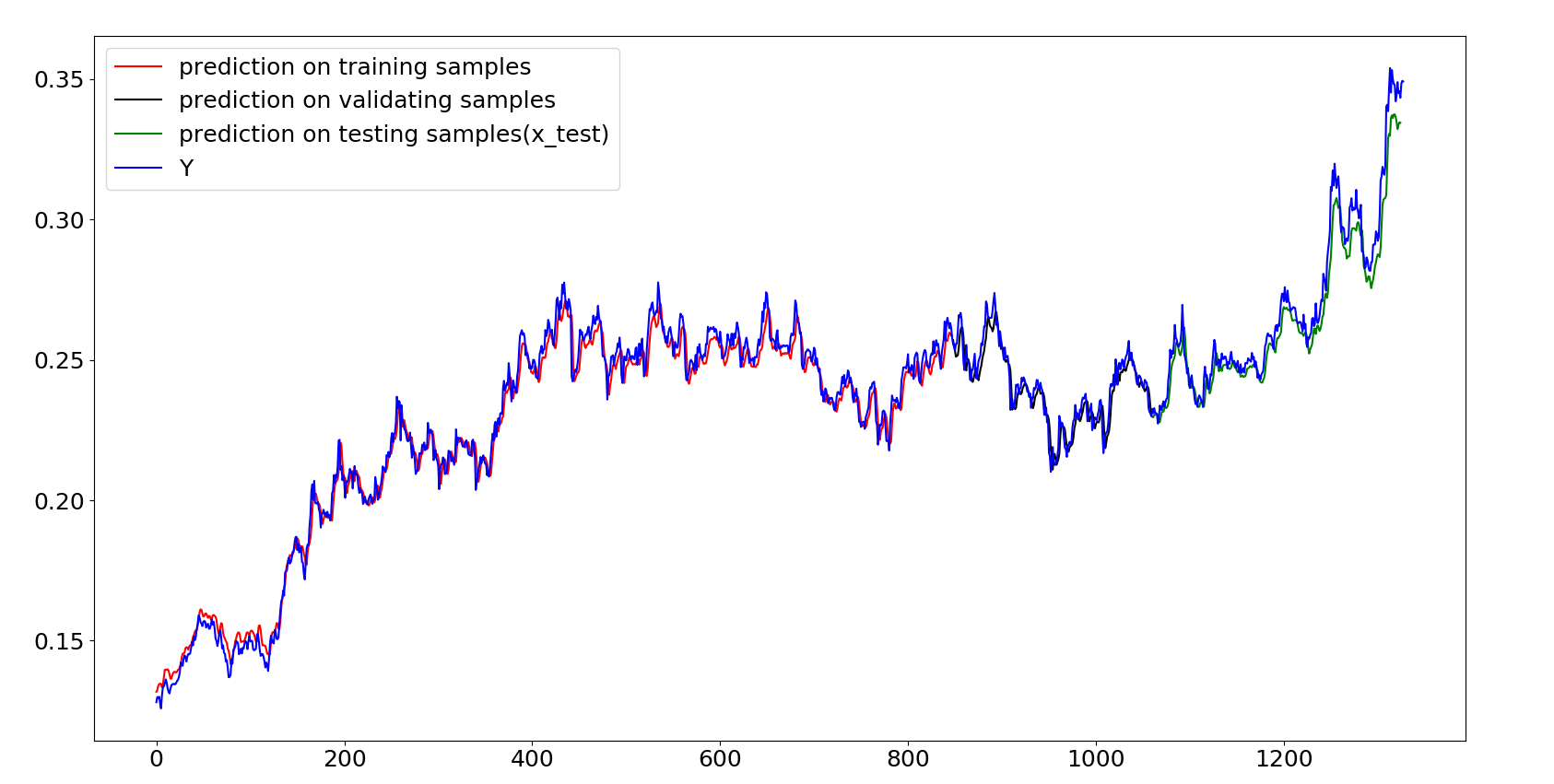
# 训练集、验证集、测试集 之间的比较
Y = np.concatenate((y_train,y_test),axis = 0)
P = np.concatenate((p1,p),axis = 0)
#plotting the complete Y set with predicted values on x_train and x_test(variable p1 & p respectively given above)
#for
plt.plot(P[:848],color='red', label='prediction on training samples')
#for validating samples
z = np.array(range(848,1060))
plt.plot(z,P[848:1060],color = 'black',label ='prediction on validating samples')
#for testing samples
x = np.array(range(1060,1325))
plt.plot(x,P[1060:1325],color = 'green',label ='prediction on testing samples(x_test)')
plt.plot(Y,color='blue', label='Y')
plt.legend(loc='upper left')
fig = plt.gcf()
fig.set_size_inches(20,12)
plt.show()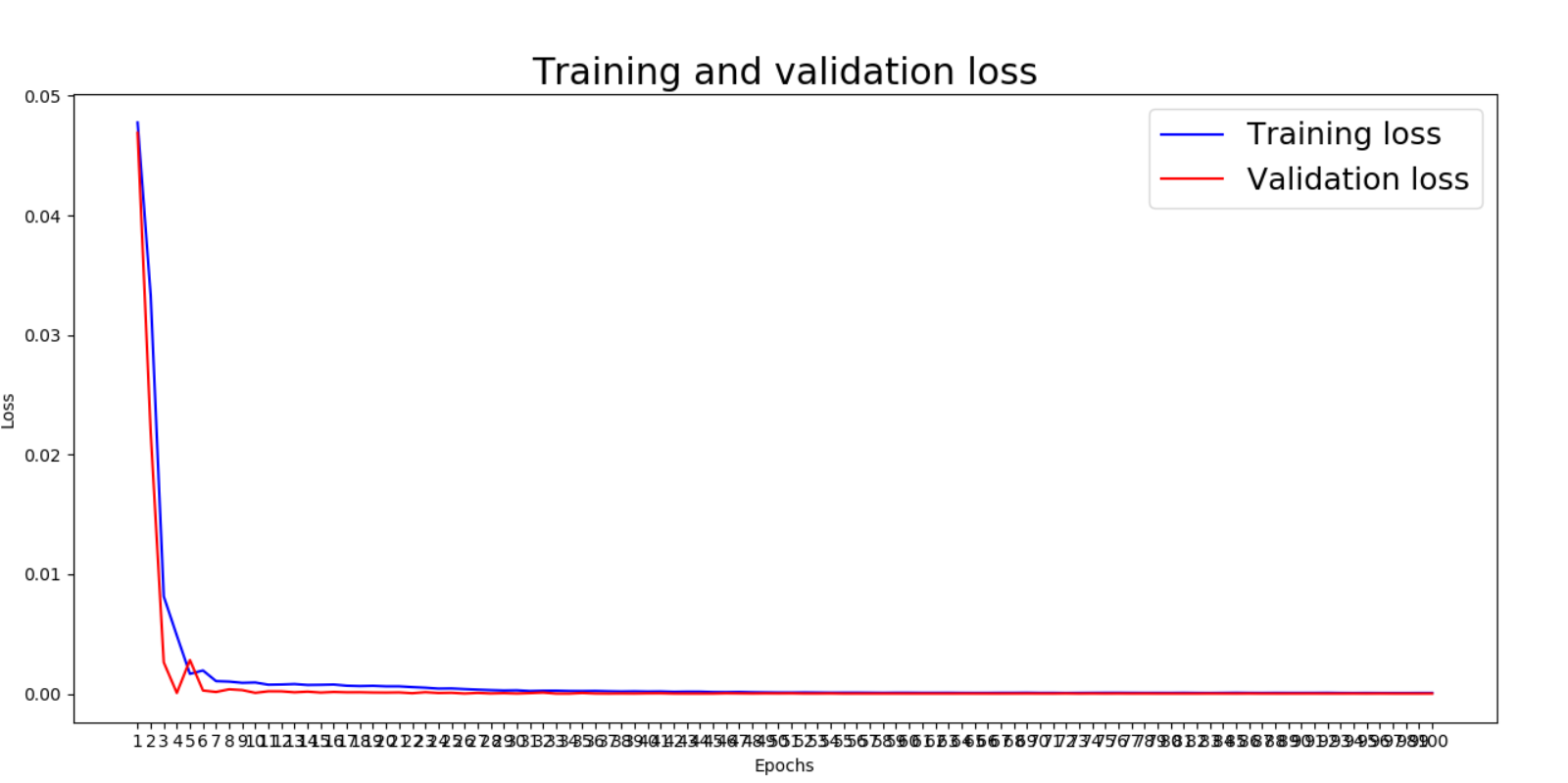

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140814.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
