大家好,又见面了,我是你们的朋友全栈君。
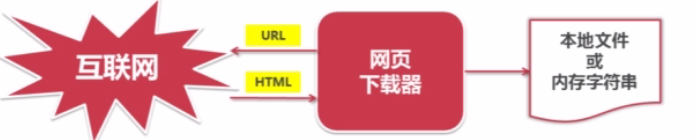
网页下载器:将互联网上URL对应的网页下载到本地的工具,是爬虫的核心组件

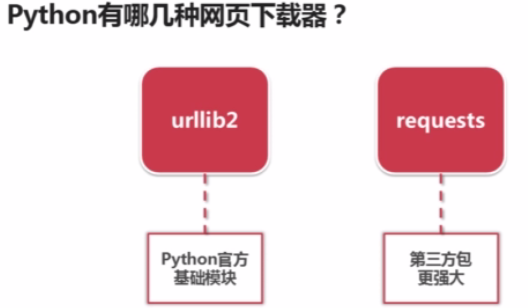
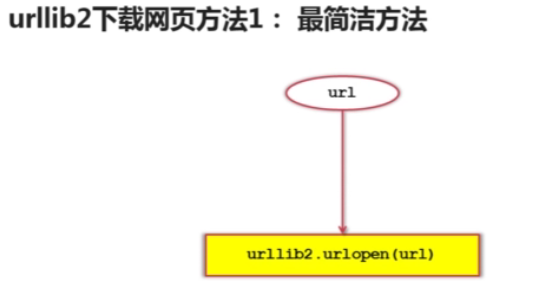
urllib2下载网页的三种方法
对应实例代码如下:
#coding:utf8
import urllib2
url = 'http://www.baidu.com'
print '第一种方法 --> 直接请求 '
response1 = urllib2.urlopen(url)
#获取状态码,如果是200表示获取成功
print response1.getcode()
# 获取读取到的内容的长度
print len(response1.read() )| 第一种方法 –> 直接请求 200 4305 |
#coding:utf8
import urllib2
url = 'http://www.baidu.com'
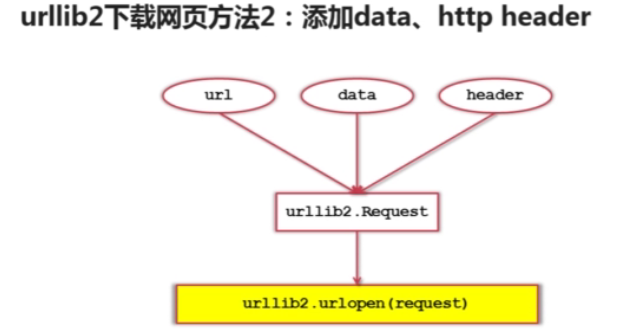
print '第二种方法:'
#创建Request对象
request= urllib2.Request(url)
#添加http的header
request.add_header('User-Agent' , 'Mozilla/5.0')
# 发送请求获取结果
response2 = urllib2.urlopen(request)
print response2.getcode()
print len(response2.read())
| 第二种方法: 200 4305 |
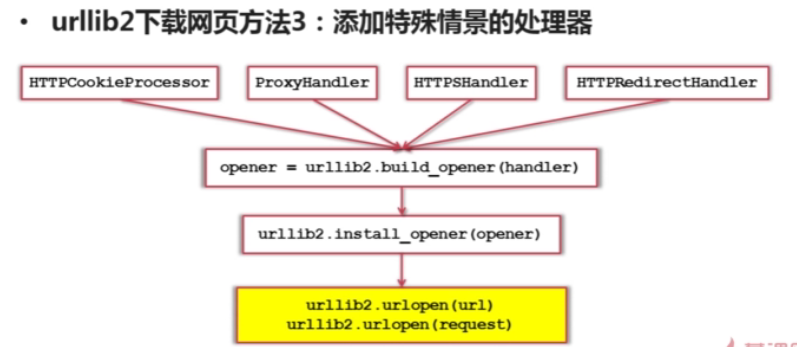
#coding:utf8
import urllib
import urllib2
import cookielib
url = 'http://www.baidu.com'
print '第三种方法:'
#创建cookie容器
cj = cookielib.CookieJar()
#创建1个opener
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
# 给urllib2安装opener
urllib2.install_opener(opener)
# 使用带有cookie的urllib2访问网页
response3 = urllib2.urlopen(url)
print response3.getcode()
print cj
print response3.read()| 第三种方法: 200 <CookieJar[]> <!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.0 Transitional//EN” “http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd”> <html xmlns=”http://www.w3.org/1999/xhtml”> <head> …… |
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140793.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
