大家好,又见面了,我是你们的朋友全栈君。
python lasso回归算法之回归实操
基本概念
正则化
正则化是指对模型做显式约束,以避免过拟合。本文用到的lasso回归就是L1正则化。(从数学的观点来看,lasso惩罚了系数向量的L1范数,换句话说,就是系数的绝对值之和。)
正则化的具体原理就不在这里多叙述了,感兴趣的朋友可以看一下这篇文章:机器学习中正则化项L1和L2的直观理解。
算法简介
lasso回归
在了解lasso回归之前,建议朋友们先对普通最小二乘法和岭回归做一些了解,可以参考这两篇文章:最小二乘法-回归实操,岭回归-回归实操。
除了岭回归之外,lasso是另一种正则化的线性回归模型,因此它的模型公式与最小二乘法的相同,如下式所示:
y=w[0]*x[0]+w[1]*x[1]+w[2]x[2]+…+w[p]x[p]+b
与岭回归相同,使用lasso也是约束系数w使其接近于0,但用到的方法不同,叫做L1正则化。L1正则化的结果是,使用lasso时某些系数刚好是0。这说明某些特征被模型完全忽略。这可以看作是一种自动化的特征选择。某些系数刚好为0,这样模型更容易被理解,也可以呈现模型最重要的特征。
数据来源
波士顿房价:https://www.kaggle.com/altavish/boston-housing-dataset
非常经典的一个数据
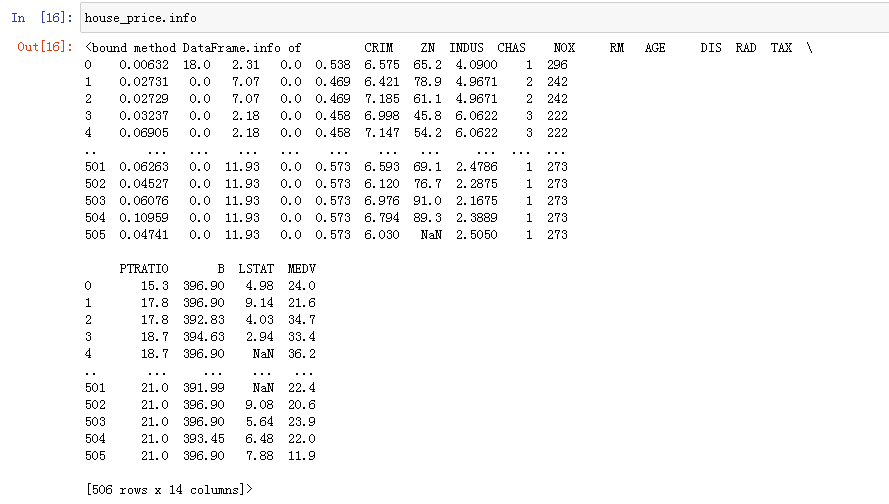

简单解释一下这个数据的几个主要指标:
ZN:25,000平方英尺以上的土地划为住宅用地的比例。
RM:每个住宅的平均房间数。
AGE:1940年之前建造的自有住房的比例
CHAS:有没有河流经过 (如果等于1,说明有,等于0就说明没有)
CRIM:犯罪率
MEDV:住房的价格
其它指标就不用说了,都是一些住房的其它指标,感兴趣的小伙伴可以自己查一下。
数据挖掘
1.导入第三方库
import pandas as pd
import numpy as np
import winreg
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Lasso###导入岭回归算法
from sklearn.metrics import r2_score
老规矩,上来先依次导入建模需要的各个模块
2.读取文件
import winreg
real_address = winreg.OpenKey(winreg.HKEY_CURRENT_USER,r'Software\Microsoft\Windows\CurrentVersion\Explorer\Shell Folders',)
file_address=winreg.QueryValueEx(real_address, "Desktop")[0]
file_address+='\\'
file_origin=file_address+"\\源数据-分析\\HousingData.csv"#设立源数据文件的桌面绝对路径
house_price=pd.read_csv(file_origin)#https://www.kaggle.com/altavish/boston-housing-dataset
因为之前每次下载数据之后都要将文件转移到python根目录里面,或者到下载文件夹里面去读取,很麻烦。所以我通过winreg库,来设立绝对桌面路径,这样只要把数据下载到桌面上,或者粘到桌面上的特定文件夹里面去读取就好了,不会跟其它数据搞混。
其实到这一步都是在走流程,基本上每个数据挖掘都要来一遍,没什么好说的。
3.清洗数据
1.查找缺失值
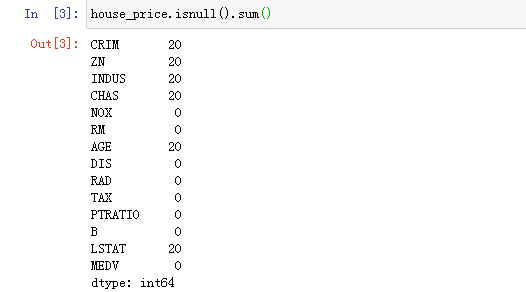
可以看到这个数据并包括一些缺失值,并不是很多,所以直接删掉就好了。
house_price1=house_price.dropna().reset_index()
del house_price1["index"]
2.突变值查找
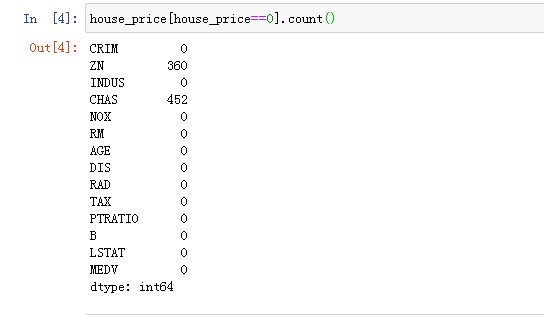
一般是看看特征值里面是否包含等于零的数据。其实说的直接一点就是看看数据里面是否包含不符合实际的数值,比如像是犯罪率,实际中不可能出现犯罪率等于0的片区。那么从上面的结果来看,这份数据并没有其它问题。
这份数据里面的ZN和CHAS都是利用0和1来当作一种指标,所以包含0是很正常的。
4.建模
train=house_price1.drop(["MEDV"],axis=1)
X_train,X_test,y_train,y_test=train_test_split(train,house_price1["MEDV"],random_state=23)
lasso=Lasso(alpha=10,max_iter=0)
lasso.fit(X_train,y_train)
print("Lasso训练模型得分:"+str(r2_score(y_train,lasso.predict(X_train))))#训练集
print("Lasso待测模型得分:"+str(r2_score(y_test,lasso.predict(X_test))))#待测集
引入lasso算法,进行建模后,对测试集进行精度评分,得到的结果如下:

如结果所见,lasso在训练集和测试集上的表现很差。这表示存在过拟合。与岭回归类似,lasso也有一个正则化参数alpha,可以控制系数趋向于0的强度。在上一个模型中,我们使用的是alpha=10,为了降低欠拟合,我们尝试减小alpha。同时,我们还需要增加max_iter的值(运行迭代的最大次数)。结果如下所示:
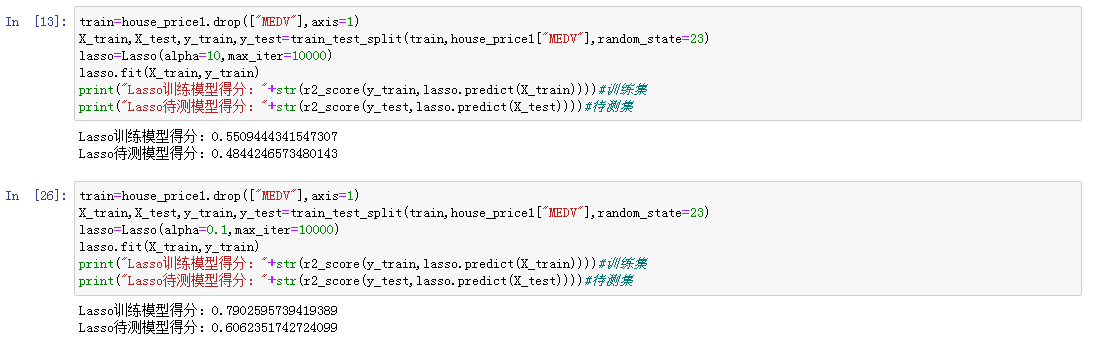
依次修改系数之后,可以看到,该模型的训练精度为79%左右,对于新的数据来说,模型精度在60%左右。
至此,这个数据集的将建模就算是完成了。
ps:如果max_iter取值过小的话,就会出现警告说需要取值取大一点,而且max_iter的取值过大并不会对模型的精度造成影响。
讨论
与岭回归算法的比较
我们通过变换约束参数的取值,来具体看一下lasso与岭回归的优缺点。
from sklearn.linear_model import Ridge###导入岭回归算法
result=pd.DataFrame(columns=["参数","lasso训练模型得分","lasso待测模型得分","岭回归训练模型得分","岭回归待测模型得分"])
for i in range(1,100):
alpha=i/10
ridge=Ridge(alpha=alpha)
lasso=Lasso(alpha=alpha,max_iter=10000)
ridge.fit(X_train,y_train)
lasso.fit(X_train,y_train)
result=result.append([{
"参数":alpha,"lasso训练模型得分":r2_score(y_train,lasso.predict(X_train)),"lasso待测模型得分":r2_score(y_test,lasso.predict(X_test)),"岭回归训练模型得分":r2_score(y_train,ridge.predict(X_train)),"岭回归待测模型得分":r2_score(y_test,ridge.predict(X_test))}])
结果如下所示:
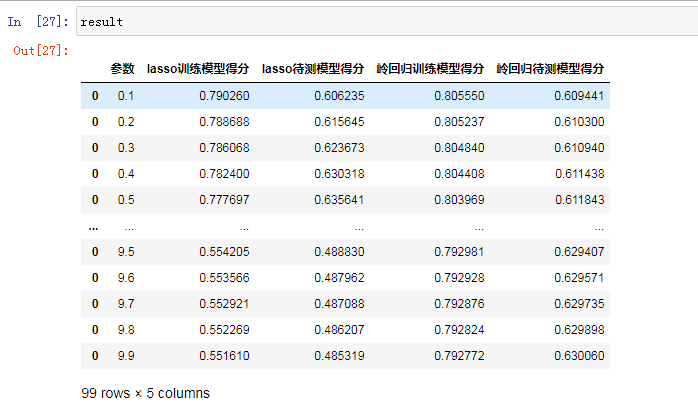
可以看出,随着alpha的变化,两个算法无论是训练模型还是待测模型都会呈现一定的规律。接下来,我们通过一个折线图来更直观地表现上面的数据:
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use("fivethirtyeight")
sns.set_style({
'font.sans-serif':['SimHei','Arial']})#设定汉字字体,防止出现方框
%matplotlib inline
#在jupyter notebook上直接显示图表
fig= plt.subplots(figsize=(15,5))
plt.plot(result["参数"],result["lasso训练模型得分"],label="lasso训练模型得分")#画折线图
plt.plot(result["参数"],result["lasso待测模型得分"],label="lasso待测模型得分")
plt.plot(result["参数"],result["岭回归训练模型得分"],label="岭回归训练模型得分")
plt.plot(result["参数"],result["岭回归待测模型得分"],label="岭回归待测模型得分")
plt.rcParams.update({
'font.size': 15})
plt.legend()
plt.xticks(fontsize=15)#设置坐标轴上的刻度字体大小
plt.yticks(fontsize=15)
plt.xlabel("参数",fontsize=15)#设置坐标轴上的标签内容和字体
plt.ylabel("得分",fontsize=15)
结果如下所示:
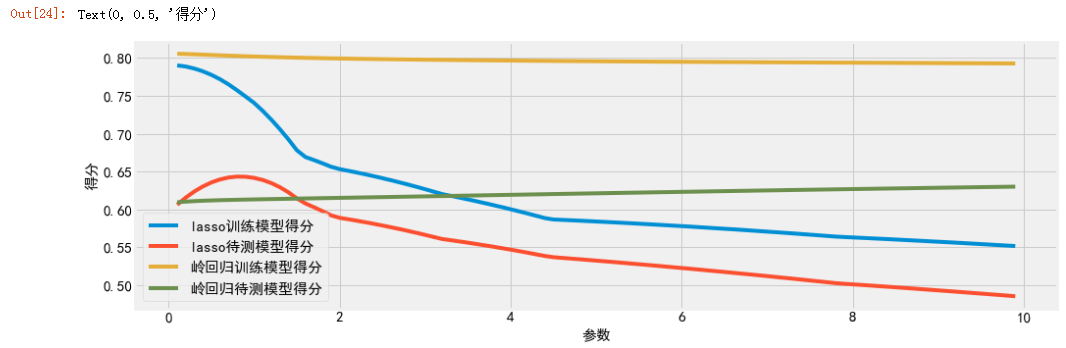
可以看出如果alpha很小,我们可以拟合一个更复杂的模型,在训练集和测试集上的表现也更好,模型的泛化能力比使用岭回归要略好一点(红线和绿线)。但随着alpha参数的增加,lasso算法模型的欠拟合现象会越来越明显(红线与蓝线),即模型精度和泛化能力都会逐渐降低。
但如果把alpha设得太小,那么就会消除正则化的效果,并出现过拟合,得到与最小二乘法类似的结果。
同时还可以看出当alpha取到某一个值的时候,岭回归的预测性能和lasso的模型类似(看两条线的交点)。
所以在实践中,对于这两个模型一般首选岭回归,从图中就可以看出来,随着参数的变化,模型得分的变化很平稳,甚至随着参数的增加,泛化能力也会有轻微的提高(绿线)。但如果特征很多,你认为只有其中几个是重要的,那么选择lasso可能更好。同样,如果你想要一个更容易解释的模型,lasso可以给出更容易理解的模型,因为它只选择了一部分特征值来做为输入。
个人博客:https://www.yyb705.com/
欢迎大家来我的个人博客逛一逛,里面不仅有技术文,也有系列书籍的内化笔记。
有很多地方做的不是很好,欢迎网友来提出建议,也希望可以遇到些朋友来一起交流讨论。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140722.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
