大家好,又见面了,我是你们的朋友全栈君。
降维是一种减少特征空间维度以获得稳定的、统计上可靠的机器学习模型的技术。降维主要有两种途径:特征选择和特征变换。
特征选择通过选择重要程度最高的若干特征,移除共性的或者重要程度较低的特征。
特征转换也称为特征提取,试图将高维数据投影到低维空间。一些特征转换技术有主成分分析(PCA)、矩阵分解、自动编码器(Autoencoders)、t-Sne、UMAP等。
本文主要介绍了主成分分析以及自动编码器两种方法,具体分析两者的优缺点,并且通过一个生动的示例进行详解。
主成分分析
主成分分析是一种无监督技术,将原始数据投影到若干高方差方向(维度)。这些高方差方向彼此正交,因此投影数据的相关性非常低或几乎接近于 0。这些特征转换是线性的,具体方法是:
步骤一:计算相关矩阵数据,相关矩阵的大小为 n*n。
步骤二:计算矩阵的特征向量和特征值。
步骤三:选取特征值较高的 k 个特征向量作为主方向。
步骤四:将原始数据集投影到这 k 个特征向量方向,得到 k 维数据,其中 k≤n。
自动编码器
自动编码器是一种无监督的人工神经网络,它将数据压缩到较低的维数,然后重新构造输入。自动编码器通过消除重要特征上的噪声和冗余,找到数据在较低维度的表征。它基于编解码结构,编码器将高维数据编码到低维,解码器接收低维数据并尝试重建原始高维数据。
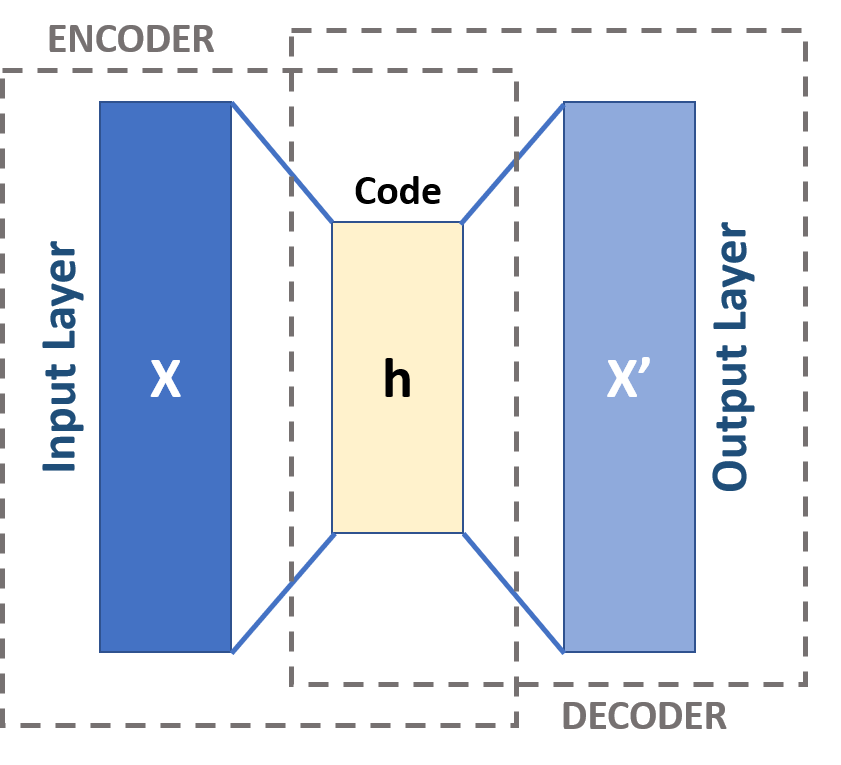

自动编码器基本结构示意图
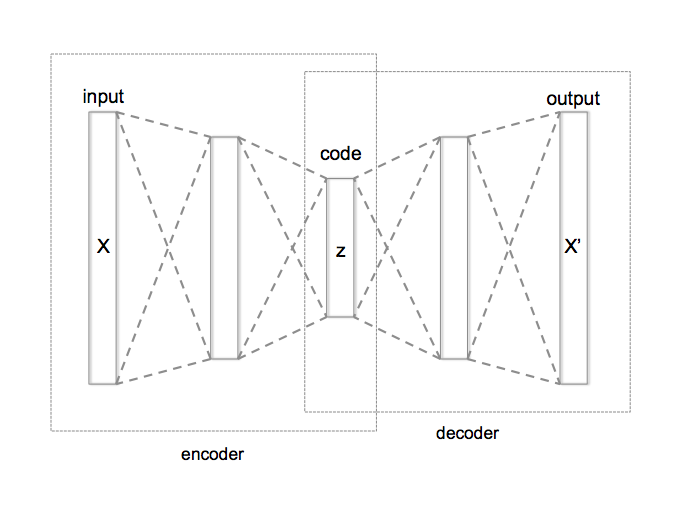
深层自动编码器结构示意图
上图中, X 是输入数据,z 是 X 在低维空间的数据表征,X’ 是重构得到的数据。根据激活函数的不同,数据从高纬度到低纬度的映射可以是线性的,也可以是非线性的。
性能对比:主成分分析 VS 自动编码器
- PCA 只能做线性变换;而自动编码器既可以做线性变换,也可以做非线性变换。
- 由于既有的 PCA 算法是十分成熟的,所以计算很快;而自动编码器需要通过梯度下降算法进行训练,所以需要花费更长的时间。
- PCA 将数据投影到若干正交的方向;而自动编码器降维后数据维度并不一定是正交的。
- PCA 是输入空间向最大变化方向的简单线性变换;而自动编码器是一种更复杂的技术,可以对相对复杂的非线性关系进行建模。
- 依据经验来看,PCA 适用于数据量较小的场景;而自动编码器可以用于复杂的大型数据集。
- PCA 唯一的超参数是正交向量的数量;而自动编码器的超参数则是神经网络的结构参数。
- 单层的并且采用线性函数作为激活函数的自动编码器与 PCA 性能一致;但是多层的以非线性函数作为激活函数的自动编码器(深度自动编码器)能够具有很好的性能,虽然可能会存在过拟合,但是可以通过正则化等方式进行解决。
降维示例:图像数据

示例图片
该示例图片的数据维度为 360*460。我们将尝试通过 PCA 和自动编码器将数据规模降低为原有的 10%。
PCA 方法
pct_reduction = 0.10
reduced_pixel = int( pct_reduction* original_dimensions[1])
#Applying PCA
pca = PCA(n_components=reduced_pixel)
pca.fit(image_matrix)
#Transforming the input matrix
X_transformed = pca.transform(image_matrix)
print("Original Input dimesnions {}".format(original_dimensions))
print("New Reduced dimensions {}".format(X_transformed.shape))
输出如下:
Original Input dimesnions (360, 460)
New Reduced dimensions (360, 46)
检查各维度的相关性:
df_pca = pd.DataFrame(data = X_transformed,columns=list(range(X_transformed.shape[1])))
figure = plt.figure(figsize=(10,6))
corrMatrix = df_pca.corr()
sns.heatmap(corrMatrix, annot=False)
plt.show()
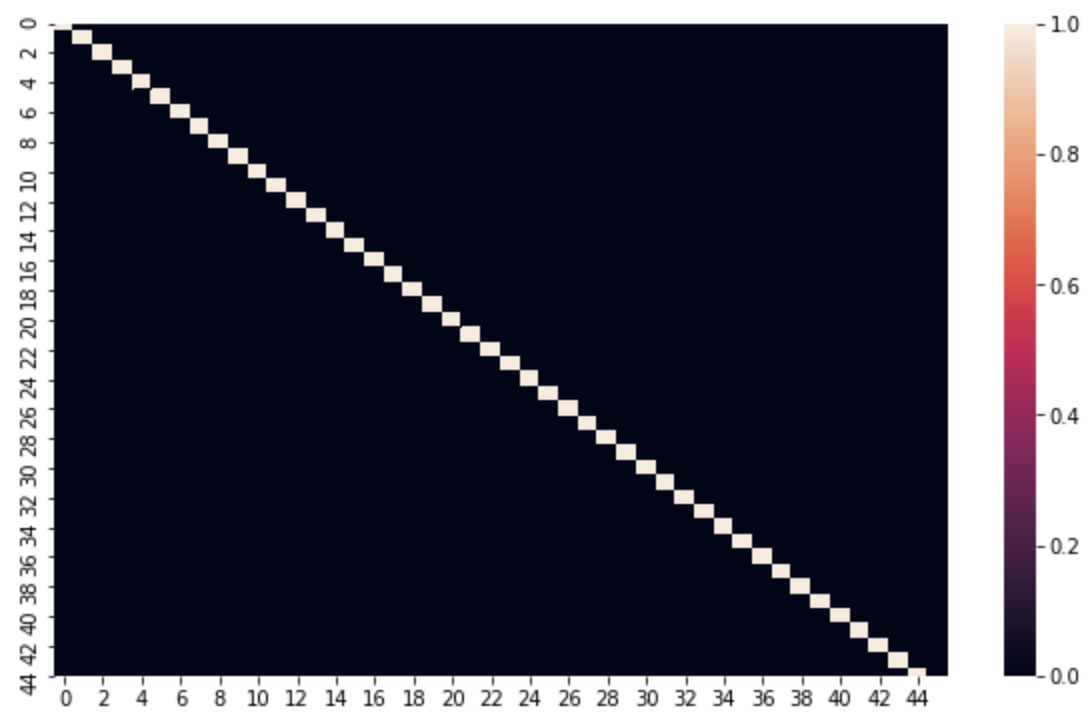
PCA降维后各维度相关性
从上图可以看出,PCA 降维后各个维度都是不相关的,也就是完全正交。
接下来,我们通过降维后的数据来重构原始数据:
reconstructed_matrix = pca.inverse_transform(X_transformed)
reconstructed_image_pca = Image.fromarray(np.uint8(reconstructed_matrix))
plt.figure(figsize=(8,12))
plt.imshow(reconstructed_image_pca,cmap = plt.cm.gray)

PCA 图像重构
计算重构后图像的均方根误差:
def my_rmse(np_arr1,np_arr2):
dim = np_arr1.shape
tot_loss = 0
for i in range(dim[0]):
for j in range(dim[1]):
tot_loss += math.pow((np_arr1[i,j] - np_arr2[i,j]),2)
return round(math.sqrt(tot_loss/(dim[0]* dim[1]*1.0)),2)
error_pca = my_rmse(image_matrix,reconstructed_matrix)
计算可知,均方根误差为11.84。
单层的以线性函数作为激活函数的自动编码器
# Standarise the Data
X_org = image_matrix.copy()
sc = StandardScaler()
X = sc.fit_transform(X_org)
# this is the size of our encoded representations
encoding_dim = reduced_pixel
# this is our input placeholder
input_img = Input(shape=(img.width,))
# "encoded" is the encoded representation of the input
encoded = Dense(encoding_dim, activation='linear')(input_img)
# "decoded" is the lossy reconstruction of the input
decoded = Dense(img.width, activation=None)(encoded)
# this model maps an input to its reconstruction
autoencoder = Model(input_img, decoded)
#Encoder
encoder = Model(input_img, encoded)
# create a placeholder for an encoded (32-dimensional) input
encoded_input = Input(shape=(encoding_dim,))
# retrieve the last layer of the autoencoder model
decoder_layer = autoencoder.layers[-1]
# create the decoder model
decoder = Model(encoded_input, decoder_layer(encoded_input))
autoencoder.compile(optimizer='adadelta', loss='mean_squared_error')
autoencoder.fit(X, X,
epochs=500,
batch_size=16,
shuffle=True)
encoded_imgs = encoder.predict(X)
decoded_imgs = decoder.predict(encoded_imgs)

自动编码器结构
检查各维度的相关性:
df_ae = pd.DataFrame(data = encoded_imgs,columns=list(range(encoded_imgs.shape[1])))
figure = plt.figure(figsize=(10,6))
corrMatrix = df_ae.corr()
sns.heatmap(corrMatrix, annot=False)
plt.show()
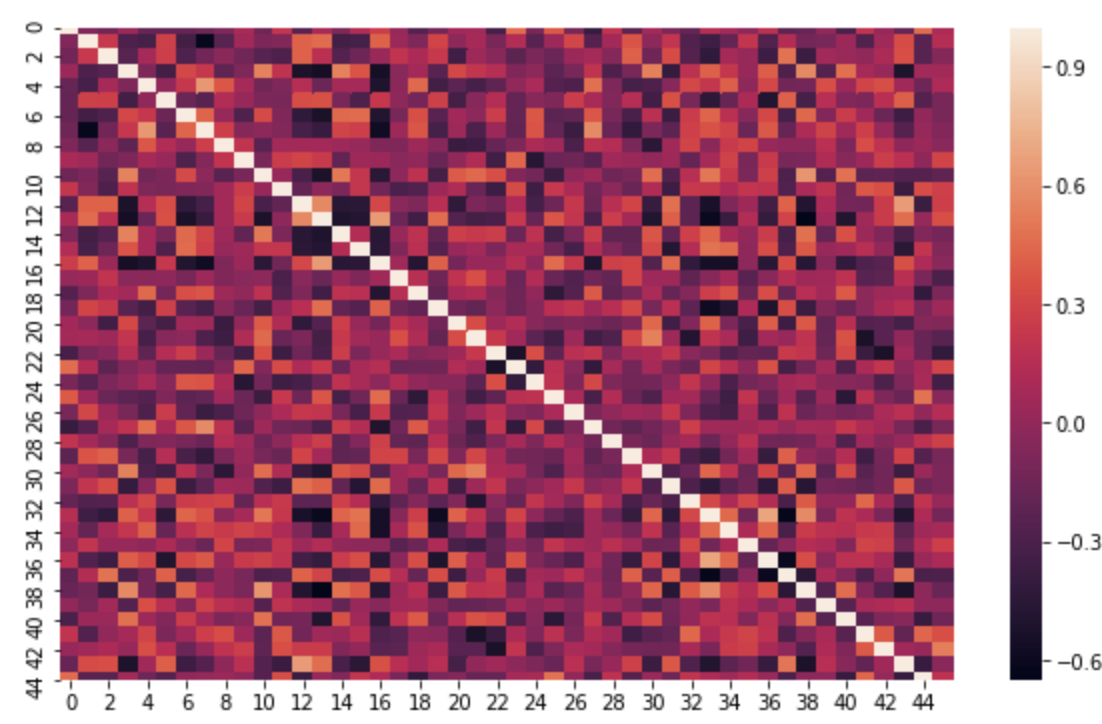
自动编码器降维后各维度相关性
相关矩阵表明新的变换特征具有一定的相关性。皮尔逊相关系数与0有很大的偏差。
接下来,我们通过降维后的数据来重构原始数据:
X_decoded_ae = sc.inverse_transform(decoded_imgs)
reconstructed_image_ae = Image.fromarray(np.uint8(X_decoded_ae))
plt.figure(figsize=(8,12))
plt.imshow(reconstructed_image_ae,cmap = plt.cm.gray)

自动编码器重构后的图像
计算重构后图像的均方根误差:
error_ae = my_rmse(image_matrix,X_decoded_ae)
计算可知,均方根误差为12.15。单层线性激活的自动编码器和 PCA 性能几乎一致。
三层的以非线性函数为激活函数的自动编码器
input_img = Input(shape=(img.width,))
encoded1 = Dense(128, activation='relu')(input_img)
encoded2 = Dense(reduced_pixel, activation='relu')(encoded1)
decoded1 = Dense(128, activation='relu')(encoded2)
decoded2 = Dense(img.width, activation=None)(decoded1)
autoencoder = Model(input_img, decoded2)
autoencoder.compile(optimizer='adadelta', loss='mean_squared_error')
autoencoder.fit(X,X,
epochs=500,
batch_size=16,
shuffle=True)
# Encoder
encoder = Model(input_img, encoded2)
# Decoder
decoder = Model(input_img, decoded2)
encoded_imgs = encoder.predict(X)
decoded_imgs = decoder.predict(X)
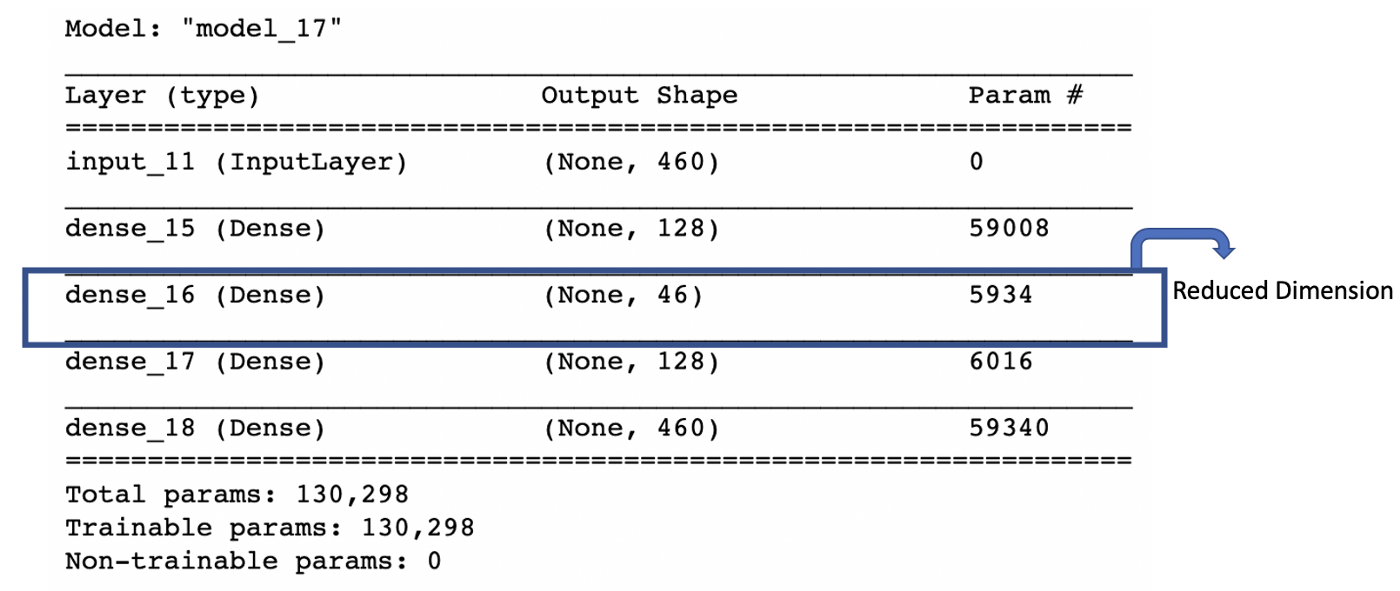
自动编码器模型结构
图像重构:
X_decoded_deep_ae = sc.inverse_transform(decoded_imgs)
reconstructed_image_deep_ae = Image.fromarray(np.uint8(X_decoded_deep_ae))
plt.figure(figsize=(8,12))
plt.imshow(reconstructed_image_deep_ae,cmap = plt.cm.gray)

计算均方误差:
error_dae = my_rmse(image_matrix,X_decoded_deep_ae)
多层自动编码器的均方误差为 8.57,性能优于 PCA,提升了 28%。
具有非线性激活的附加层的自动编码器能够更好地捕获图像中的非线性特征。它能够比PCA更好地捕捉复杂的模式和像素值的突然变化。但是它需要花费相对较高的训练时间和资源。
总结
本文主要介绍了主成分分析以及自动编码器两种方法,具体分析两者的优缺点,并且通过一个生动的示例进行详解。
完整代码 https://github.com/samread81/PCA-versus-AE
作者:Abhishek Mungoli
deephub翻译组:Oliver Lee
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140681.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
