大家好,又见面了,我是你们的朋友全栈君。
写在之前
介绍
Pytorch深度学习框架优势之一是python优先,源代码由python代码层和C语言代码层组成,一般只需要理解python代码层就可以深入理解pytorch框架的计算原理。所以学习pytorch源码需要熟练掌握python语言的各种使用技巧。
在处理任何机器学习问题之前都需要数据读取,并进行预处理。Pytorch提供了许多方法使得数据读取和预处理变得很容易。
torch.utils.data.Dataset是代表自定义数据集方法的抽象类,你可以自己定义你的数据类继承这个抽象类,非常简单,只需要定义__len__和__getitem__这两个方法就可以。- 通过继承
torch.utils.data.Dataset的这个抽象类,我们可以定义好我们需要的数据类。当我们通过迭代的方式来取得每一个数据,但是这样很难实现取batch,shuffle或者多线程读取数据,所以pytorch还提供了一个简单的方法来做这件事情,通过torch.utils.data.DataLoader类来定义一个新的迭代器,用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入。
总之,通过torch.utils.data.Dataset和torch.utils.data.DataLoader这两个类,使数据的读取变得非常简单,快捷。
这两个抽象类中用到的python知识点
能够熟练的使用python语言的技巧,是理解pytorch源码的关键。在torch.utils.data.Dataset和torch.utils.data.DataLoader这两个类中会用到python抽象类的魔法方法,包括__len__(self),__getitem__(self)和__iter__(self)
__len__(self)定义当被len()函数调用时的行为(返回容器中元素的个数)__getitem__(self)定义获取容器中指定元素的行为,相当于self[key],即允许类对象可以有索引操作。__iter__(self)定义当迭代容器中的元素的行为
下面通过介绍python定制容器的方式来介绍__len__(self),__getitem__(self)两种方法。
在python中,像序列类型(如列表,元组和字符串)或映射类型(如字典)都属于容器类型。讲定制容器,那就必须要知道,定制容器有关的一些协议:
- 如果你希望定制的容器是不可变的话,你只需要定义
__len__()和__getitem__这两个魔法方法。 - 如果你希望定制的容器是可变的话,除了
__len__()和__getitem__这两个魔法方法,还需要定义__setitem__()和__delitem__()两个方法。
小案例:编写一个不可变的自定义列表,要求记录列表中每个元素被访问的次数。
class CountList:
def __init__(self, *args):
self.values = [x for x in args]
self.count = {
}.fromkeys(range(len(self.values)),0)
# 这里使用列表的下标作为字典的键,注意不能用元素作为字典的键
# 因为列表的不同下标可能有值一样的元素,但字典不能有两个相同的键
def __len__(self):
return len(self.values)
def __getitem__(self, key):
self.count[key] += 1
return self.values[key]
c1 = CountList(1,3,5,7,9)
c2 = CountLIst(2,4,6,8,10)
# 调用
c1[1] ## 3
c2[1] ## 4
c1[1] + c2[1] ## 7
c1.count ## {0:0,1:2,2:0,3:0,4:0}
c2.count ## {0:0,1:2,2:0,3:0,4:0}
接下来讲解__iter__(self)方法。这个魔法方法是在python构造迭代器的时候需要定义的。迭代的意思类似于循环,每一次重复的过程被称为一次迭代的过程,而每一次迭代得到的结果会被用来作为下一次迭代的初始值。提供迭代方法的容器称为迭代器,通常接触的迭代器有序列(列表、元组和字符串)还有字典也是迭代器,都支持迭代操作。那么实现迭代器的魔法方法有两个:
__iter__()__next__()
一个容器如果是迭代器,那就必须实现__iter__()魔法方法,这个方法实际上是返回迭代器本身。接下来重点要实现的是__next__()魔法方法,因为它决定了迭代的规则。举个简单的例子:
class Fibs:
def __init__(self, n=20):
self.a = 0
self.b = 1
self.n = n
def __iter__(self):
return self
def __next__(self):
self.a, self.b = self.b, self.a + self.b
if self.a > self.n:
raise StopIteration
return self.a
## 调用
fibs = Fibs()
for each in fibs:
print(each)
## 输出
1
1
2
3
5
8
13
torch.utils.data.Dataset类
源码:
class Dataset(object):
"""An abstract class representing a Dataset. All other datasets should subclass it. All subclasses should override ``__len__``, that provides the size of the dataset, and ``__getitem__``, supporting integer indexing in range from 0 to len(self) exclusive. """
def __getitem__(self, index):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])
一个用来表示数据集的抽象类,其他所有的数据集都应该是这个类的子类,并且需要重写__len__和__getitem__。
torch.utils.data.DataLoader类
DataLoader类源码如下。先看看__init__中的几个重要的输入:1、dataset,这个就是PyTorch已有的数据读取接口(比如torchvision.datasets.ImageFolder)或者自定义的数据接口的输出,该输出要么是torch.utils.data.Dataset类的对象,要么是继承自torch.utils.data.Dataset类的自定义类的对象。2、batch_size,根据具体情况设置即可。3、shuffle,一般在训练数据中会采用。4、collate_fn,是用来处理不同情况下的输入dataset的封装,一般采用默认即可,除非你自定义的数据读取输出非常少见。5、batch_sampler,从注释可以看出,其和batch_size、shuffle等参数是互斥的,一般采用默认。6、sampler,从代码可以看出,其和shuffle是互斥的,一般默认即可。7、num_workers,从注释可以看出这个参数必须大于等于0,0的话表示数据导入在主进程中进行,其他大于0的数表示通过多个进程来导入数据,可以加快数据导入速度。8、pin_memory,注释写得很清楚了: pin_memory (bool, optional): If True, the data loader will copy tensors into CUDA pinned memory before returning them. 也就是一个数据拷贝的问题。9、timeout,是用来设置数据读取的超时时间的,但超过这个时间还没读取到数据的话就会报错。
在__init__中,RandomSampler类表示随机采样且不重复,所以起到的就是shuffle的作用。BatchSampler类则是把batch size个RandomSampler类对象封装成一个,这样就实现了随机选取一个batch的目的。这两个采样类都是定义在sampler.py脚本中,地址:https://github.com/pytorch/pytorch/blob/master/torch/utils/data/sampler.py。以上这些都是初始化的时候进行的。当代码运行到要从torch.utils.data.DataLoader类生成的对象中取数据的时候,比如:
train_data=torch.utils.data.DataLoader(…)
for i, (input, target) in enumerate(train_data):
…
就会调用DataLoader类的__iter__方法,__iter__方法就一行代码:return DataLoaderIter(self),输入正是DataLoader类的属性。因此当调用__iter__方法的时候就牵扯到另外一个类:DataLoaderIter,接下来介绍。
class DataLoader(object):
r""" Data loader. Combines a dataset and a sampler, and provides single- or multi-process iterators over the dataset. Arguments: dataset (Dataset): dataset from which to load the data. batch_size (int, optional): how many samples per batch to load (default: 1). shuffle (bool, optional): set to ``True`` to have the data reshuffled at every epoch (default: False). sampler (Sampler, optional): defines the strategy to draw samples from the dataset. If specified, ``shuffle`` must be False. batch_sampler (Sampler, optional): like sampler, but returns a batch of indices at a time. Mutually exclusive with batch_size, shuffle, sampler, and drop_last. num_workers (int, optional): how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default: 0) collate_fn (callable, optional): merges a list of samples to form a mini-batch. pin_memory (bool, optional): If ``True``, the data loader will copy tensors into CUDA pinned memory before returning them. drop_last (bool, optional): set to ``True`` to drop the last incomplete batch, if the dataset size is not divisible by the batch size. If ``False`` and the size of dataset is not divisible by the batch size, then the last batch will be smaller. (default: False) timeout (numeric, optional): if positive, the timeout value for collecting a batch from workers. Should always be non-negative. (default: 0) worker_init_fn (callable, optional): If not None, this will be called on each worker subprocess with the worker id (an int in ``[0, num_workers - 1]``) as input, after seeding and before data loading. (default: None) .. note:: By default, each worker will have its PyTorch seed set to ``base_seed + worker_id``, where ``base_seed`` is a long generated by main process using its RNG. However, seeds for other libraies may be duplicated upon initializing workers (w.g., NumPy), causing each worker to return identical random numbers. (See :ref:`dataloader-workers-random-seed` section in FAQ.) You may use ``torch.initial_seed()`` to access the PyTorch seed for each worker in :attr:`worker_init_fn`, and use it to set other seeds before data loading. .. warning:: If ``spawn`` start method is used, :attr:`worker_init_fn` cannot be an unpicklable object, e.g., a lambda function. """
__initialized = False
def __init__(self, dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None,
num_workers=0, collate_fn=default_collate, pin_memory=False, drop_last=False,
timeout=0, worker_init_fn=None):
self.dataset = dataset
self.batch_size = batch_size
self.num_workers = num_workers
self.collate_fn = collate_fn
self.pin_memory = pin_memory
self.drop_last = drop_last
self.timeout = timeout
self.worker_init_fn = worker_init_fn
if timeout < 0:
raise ValueError('timeout option should be non-negative')
if batch_sampler is not None:
if batch_size > 1 or shuffle or sampler is not None or drop_last:
raise ValueError('batch_sampler option is mutually exclusive '
'with batch_size, shuffle, sampler, and '
'drop_last')
self.batch_size = None
self.drop_last = None
if sampler is not None and shuffle:
raise ValueError('sampler option is mutually exclusive with '
'shuffle')
if self.num_workers < 0:
raise ValueError('num_workers option cannot be negative; '
'use num_workers=0 to disable multiprocessing.')
if batch_sampler is None:
if sampler is None:
if shuffle:
sampler = RandomSampler(dataset)
else:
sampler = SequentialSampler(dataset)
batch_sampler = BatchSampler(sampler, batch_size, drop_last)
self.sampler = sampler
self.batch_sampler = batch_sampler
self.__initialized = True
def __setattr__(self, attr, val):
if self.__initialized and attr in ('batch_size', 'sampler', 'drop_last'):
raise ValueError('{} attribute should not be set after {} is '
'initialized'.format(attr, self.__class__.__name__))
super(DataLoader, self).__setattr__(attr, val)
def __iter__(self):
return _DataLoaderIter(self)
def __len__(self):
return len(self.batch_sampler)
DataLoaderIter类源码如下。self.index_queue = multiprocessing.SimpleQueue()中的multiprocessing是Python中的多进程管理包,而threading则是Python中的多线程管理包,二者很大一部分的接口用法类似。还是照例先看看__init__,前面部分都是一些赋值操作,比较特殊的是self.sample_iter = iter(self.batch_sampler),得到的self.sample_iter可以通过next(self.sample_iter)来获取batch size个数据的index。self.rcvd_idx表示读取到的一个batch数据的index,初始化为0,该值在迭代读取数据的时候会用到。if self.num_workers语句是针对多进程或单进程的情况进行初始化,如果不是设置为多进程读取数据,那么就不需要这些初始化操作,后面会介绍单进程数据读取。在if语句中通过multiprocessing.SimpleQueue()类创建了一个简单的队列对象。multiprocessing.Process类就是构造进程的类,这里根据设定的进程数来启动,然后赋值给self.workers。接下来的一个for循环就通过调用start方法依次启动self.workers中的进程。接下来关于self.pin_memory的判断语句,该判断语句内部主要是实现了多线程操作。self.pin_memory的含义在前面已经介绍过了,当为True的时候,就会把数据拷到CUDA中。self.data_queue = queue.Queue()是通过Python的queue模块初始化得到一个先进先出的队列(queue模块也可以初始化得到先进后出的队列,需要用queue.LifoQueue()初始化),queue模块主要应用在多线程读取数据中。在threading.Thread的args参数中,第一个参数in_data就是一个进程的数据,一个进程中不同线程的数据也是通过队列来维护的,这里采用的是Python的queue模块来初始化得到一个队列:queue.Queue()。初始化结束后,就会调用__next__方法,接下来介绍。
总的来说,如果设置为多进程读取数据,那么就会采用队列的方式来读,如果不是采用多进程来读取数据,那就采用普通方式来读。
class _DataLoaderIter(object):
r"""Iterates once over the DataLoader's dataset, as specified by the sampler"""
def __init__(self, loader):
self.dataset = loader.dataset
self.collate_fn = loader.collate_fn
self.batch_sampler = loader.batch_sampler
self.num_workers = loader.num_workers
self.pin_memory = loader.pin_memory and torch.cuda.is_available()
self.timeout = loader.timeout
self.done_event = threading.Event()
self.sample_iter = iter(self.batch_sampler)
base_seed = torch.LongTensor(1).random_().item()
if self.num_workers > 0:
self.worker_init_fn = loader.worker_init_fn
self.index_queues = [multiprocessing.Queue() for _ in range(self.num_workers)]
self.worker_queue_idx = 0
self.worker_result_queue = multiprocessing.SimpleQueue()
self.batches_outstanding = 0
self.worker_pids_set = False
self.shutdown = False
self.send_idx = 0
self.rcvd_idx = 0
self.reorder_dict = {
}
self.workers = [
multiprocessing.Process(
target=_worker_loop,
args=(self.dataset, self.index_queues[i],
self.worker_result_queue, self.collate_fn, base_seed + i,
self.worker_init_fn, i))
for i in range(self.num_workers)]
if self.pin_memory or self.timeout > 0:
self.data_queue = queue.Queue()
if self.pin_memory:
maybe_device_id = torch.cuda.current_device()
else:
# do not initialize cuda context if not necessary
maybe_device_id = None
self.worker_manager_thread = threading.Thread(
target=_worker_manager_loop,
args=(self.worker_result_queue, self.data_queue, self.done_event, self.pin_memory,
maybe_device_id))
self.worker_manager_thread.daemon = True
self.worker_manager_thread.start()
else:
self.data_queue = self.worker_result_queue
for w in self.workers:
w.daemon = True # ensure that the worker exits on process exit
w.start()
_update_worker_pids(id(self), tuple(w.pid for w in self.workers))
_set_SIGCHLD_handler()
self.worker_pids_set = True
# prime the prefetch loop
for _ in range(2 * self.num_workers):
self._put_indices()
def __len__(self):
return len(self.batch_sampler)
def _get_batch(self):
if self.timeout > 0:
try:
return self.data_queue.get(timeout=self.timeout)
except queue.Empty:
raise RuntimeError('DataLoader timed out after {} seconds'.format(self.timeout))
else:
return self.data_queue.get()
def __next__(self):
if self.num_workers == 0: # same-process loading
indices = next(self.sample_iter) # may raise StopIteration
batch = self.collate_fn([self.dataset[i] for i in indices])
if self.pin_memory:
batch = pin_memory_batch(batch)
return batch
# check if the next sample has already been generated
if self.rcvd_idx in self.reorder_dict:
batch = self.reorder_dict.pop(self.rcvd_idx)
return self._process_next_batch(batch)
if self.batches_outstanding == 0:
self._shutdown_workers()
raise StopIteration
while True:
assert (not self.shutdown and self.batches_outstanding > 0)
idx, batch = self._get_batch()
self.batches_outstanding -= 1
if idx != self.rcvd_idx:
# store out-of-order samples
self.reorder_dict[idx] = batch
continue
return self._process_next_batch(batch)
next = __next__ # Python 2 compatibility
def __iter__(self):
return self
def _put_indices(self):
assert self.batches_outstanding < 2 * self.num_workers
indices = next(self.sample_iter, None)
if indices is None:
return
self.index_queues[self.worker_queue_idx].put((self.send_idx, indices))
self.worker_queue_idx = (self.worker_queue_idx + 1) % self.num_workers
self.batches_outstanding += 1
self.send_idx += 1
def _process_next_batch(self, batch):
self.rcvd_idx += 1
self._put_indices()
if isinstance(batch, ExceptionWrapper):
raise batch.exc_type(batch.exc_msg)
return batch
def __getstate__(self):
# TODO: add limited pickling support for sharing an iterator
# across multiple threads for HOGWILD.
# Probably the best way to do this is by moving the sample pushing
# to a separate thread and then just sharing the data queue
# but signalling the end is tricky without a non-blocking API
raise NotImplementedError("_DataLoaderIter cannot be pickled")
def _shutdown_workers(self):
try:
if not self.shutdown:
self.shutdown = True
self.done_event.set()
for q in self.index_queues:
q.put(None)
# if some workers are waiting to put, make place for them
try:
while not self.worker_result_queue.empty():
self.worker_result_queue.get()
except (FileNotFoundError, ImportError):
# Many weird errors can happen here due to Python
# shutting down. These are more like obscure Python bugs.
# FileNotFoundError can happen when we rebuild the fd
# fetched from the queue but the socket is already closed
# from the worker side.
# ImportError can happen when the unpickler loads the
# resource from `get`.
pass
# done_event should be sufficient to exit worker_manager_thread,
# but be safe here and put another None
self.worker_result_queue.put(None)
finally:
# removes pids no matter what
if self.worker_pids_set:
_remove_worker_pids(id(self))
self.worker_pids_set = False
def __del__(self):
if self.num_workers > 0:
self._shutdown_workers()
DataLoaderIter类的__next__方法如下,包含3个if语句和1个while语句。
第一个if语句是用来处理self.num_workers等于0的情况,也就是不采用多进程进行数据读取,可以看出在这个if语句中先通过indices = next(self.sample_iter)获取长度为batch size的列表:indices,这个列表的每个值表示一个batch中每个数据的index,每执行一次next操作都会读取一批长度为batch size的indices列表。然后通过self.collate_fn函数将batch size个tuple(每个tuple长度为2,其中第一个值是数据,Tensor类型,第二个值是标签,int类型)封装成一个list,这个list长度为2,两个值都是Tensor,一个是batch size个数据组成的FloatTensor,另一个是batch size个标签组成的LongTensor。所以简单讲self.collate_fn函数就是将batch size个分散的Tensor封装成一个Tensor。batch = pin_memory_batch(batch)中pin_memory_batch函数的作用就是将输入batch的每个Tensor都拷贝到CUDA中,该函数后面会详细介绍。
第二个if语句是判断当前想要读取的batch的index(self.rcvd_idx)是否之前已经读出来过(已读出来的index和batch数据保存在self.reorder_dict字典中,可以结合最后的while语句一起看,因为self.reorder_dict字典的更新是在最后的while语句中),如果之前已经读取过了,就根据这个index从reorder_dict字典中弹出对应的数据。最后返回batch数据的时候是 return self._process_next_batch(batch),该方法后面会详细介绍。主要做是获取下一个batch的数据index信息。
第三个if语句,self.batches_outstanding的值在前面初始中调用self._put_indices()方法时修改了,所以假设你的进程数self.num_workers设置为3,那么这里self.batches_outstanding就是3*2=6,可具体看self._put_indices()方法。
最后的while循环就是真正用来从队列中读取数据的操作,最主要的就是idx, batch = self._get_batch(),通过调用_get_batch()方法来读取,后面有介绍,简单讲就是调用了队列的get方法得到下一个batch的数据,得到的batch一般是长度为2的列表,列表的两个值都是Tensor,分别表示数据(是一个batch的)和标签。_get_batch()方法除了返回batch数据外,还得到另一个输出:idx,这个输出表示batch的index,这个if idx != self.rcvd_idx条件语句表示如果你读取到的batch的index不等于当前想要的index:selg,rcvd_idx,那么就将读取到的数据保存在字典self.reorder_dict中:self.reorder_dict[idx] = batch,然后继续读取数据,直到读取到的数据的index等于self.rcvd_idx。
pin_memory_batch函数不是定义在DataLoader类或DataLoaderIter类中。该函数主要是对batch中的Tensor执行batch.pin_memory()操作,这里的很多条件语句只是用来判断batch的类型,假如batch是一个列表,列表中的每个值是Tensor,那么就会执行 elif isinstance(batch, collections.Sequence):这个条件,从而遍历该列表中的每个Tensor,然后执行第一个条件语句的内容: return batch.pin_memory()
def pin_memory_batch(batch):
if isinstance(batch, torch.Tensor):
return batch.pin_memory()
elif isinstance(batch, string_classes):
return batch
elif isinstance(batch, collections.Mapping):
return {
k: pin_memory_batch(sample) for k, sample in batch.items()}
elif isinstance(batch, collections.Sequence):
return [pin_memory_batch(sample) for sample in batch]
else:
return batch
DataloaderIter类的_get_batch方法。主要根据是否设置了超时时间来操作,如果超过指定的超时时间后没有从队列中读到数据就报错,如果不设置超时时间且一致没有从队列中读到数据,那么就会一直卡着且不报错,这部分是PyTorch后来修的一个bug。
DataLoaderIter类的_process_next_batch方法。首先对self.rcvd_idx进行加一,也就是更新下下一个要读取的batch数据的index。然后调用_put_indices()方法获取下一个batch的每个数据的index。
DataLoaderIter类的_put_indices方法。该方法主要实现从self.sample_iter中读取下一个batch数据中每个数据的index:indices = next(self.sample_iter, None),注意这里的index和前面idx是不一样的,这里的index是一个batch中每个数据的index,idx是一个batch的index;然后将读取到的index通过调用queue对象的put方法压到队列self.index_queue中:self.index_queue.put((self.send_idx, indices))
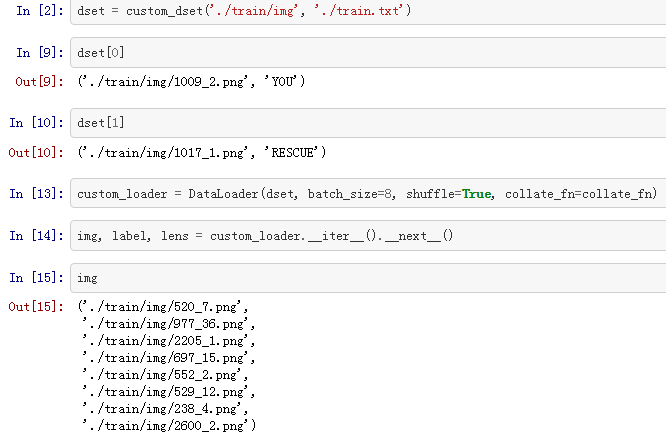
例子
来源:https://github.com/L1aoXingyu/pytorch-beginner/tree/master/12-data io
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
from PIL import Image
import os
def default_loader(img):
return Image.open(img)
class custom_dset(Dataset):
def __init__(self,
img_path,
txt_path,
img_transform=None,
loader=default_loader):
with open(txt_path, 'r') as f:
lines = f.readlines()
self.img_list = [
os.path.join(img_path, i.split()[0]) for i in lines
]
self.label_list = [i.split()[1] for i in lines]
self.img_transform = img_transform
self.loader = loader
def __getitem__(self, index):
img_path = self.img_list[index]
label = self.label_list[index]
# img = self.loader(img_path)
img = img_path
if self.img_transform is not None:
img = self.img_transform(img)
return img, label
def __len__(self):
return len(self.label_list)
def collate_fn(batch):
batch.sort(key=lambda x: len(x[1]), reverse=True)
img, label = zip(*batch)
pad_label = []
lens = []
max_len = len(label[0])
for i in range(len(label)):
temp_label = [0] * max_len
temp_label[:len(label[i])] = label[i]
pad_label.append(temp_label)
lens.append(len(label[i]))
return img, pad_label, lens


参考
- https://blog.csdn.net/u014380165/article/details/79058479
- https://pytorch.org/docs/stable/_modules/torch/utils/data/dataloader.html#DataLoader
- https://blog.csdn.net/u014380165/article/details/78634829(这篇博客写的也很好)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140660.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
