大家好,又见面了,我是你们的朋友全栈君。
前言:最近在做kafka、mq、redis、fink、kudu等在中间件性能压测,压测kafka的时候参考了这篇文章,大家可以借鉴下!
一、测试环境
测试使用到三台机器,机器配置如下:
共同配置:
Intel® Core™ i7-7700 CPU @ 3.60GHz、Cores:4、Threads:2
32GB内存
1000Mb/sec网卡
差异化配置
2TB、7200rpm、SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
1TB、7200rpm、SATA 3.1, 6.0Gb/s (current: 6.0 Gb/s)
250G、SSD、SATA3.1, 6.0 Gb/s (current: 6.0 Gb/s)
三台机器操作系统采用centos7,Release版本为7.5.1804。其中两台机器用来搭建kafka集群,另一台机器作为客户机测试。

二、producer吞吐率
本次测试producer的吞吐率,因此不存consumer的消费场景,使用官方提供的测试工具kafka-producer-perf-test.sh来测试。
测试参数:

测试结果:
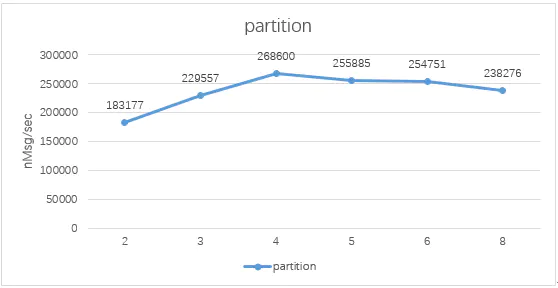
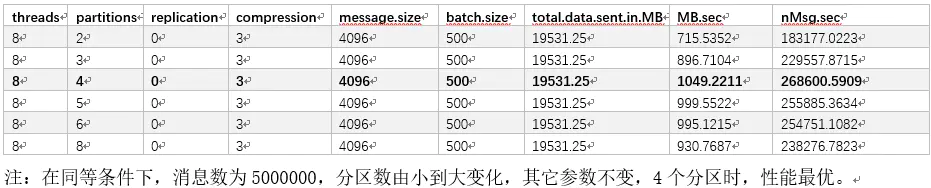
在2个broker的集群中,partition的分区数为4时,性能最优,但随着partition的增长,吞吐率呈下降区势。同时增加集群中broker数与分区数,可提升吞吐率。
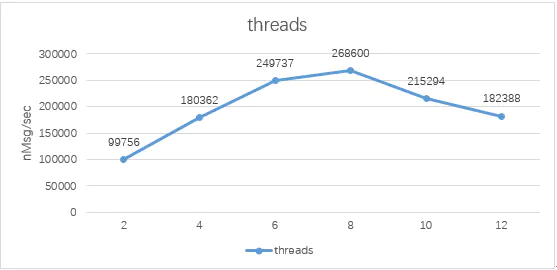
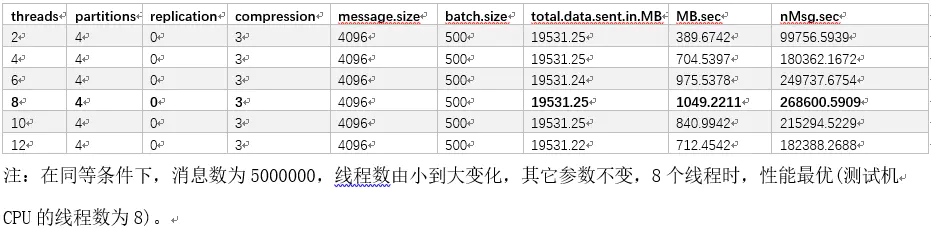
在2个broker的集群中,partition的分区数为4时,以CPU对应的线程数为性能最优,随着生产者线程数的增加,吞吐率呈下降区势。
针对kafka提供的3种压缩算法进行对比,在相同条件下,采用LZ4算法,性能最优。

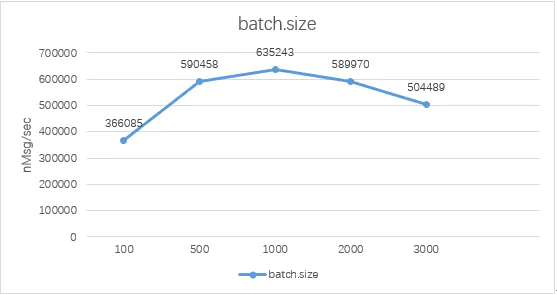
在设置message.size大小不变的前提下,不断增加batch.size的大小,但小于最大值10000,当处于1000时,性能最优,随着batch.size继续增大,吞吐率下随趋势明显。
其它参数不变,不断增加message.size的大小,即每条消息的大小,吞吐率会急剧下降。消息的大小需按实际业务来度量,在每条消息为3072B时,每秒处理的数据总量最大。

partition
threads
compression

batch.size

message.size

三、consumer吞吐率
本次测试consumer的吞吐率,使用官方提供的测试工具kafka-consumer-perf-test.sh来测试。
测试参数:

测试结果:
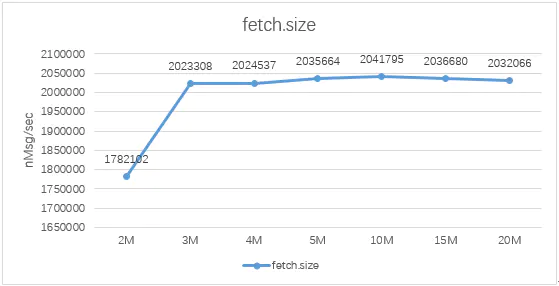
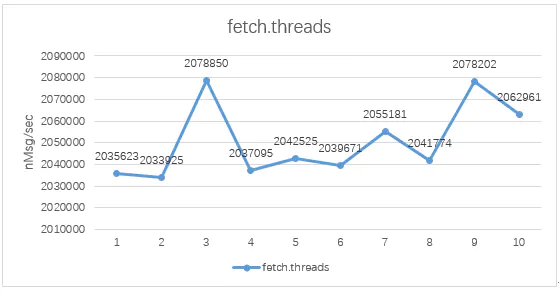
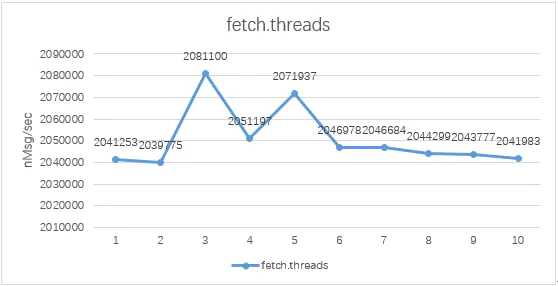
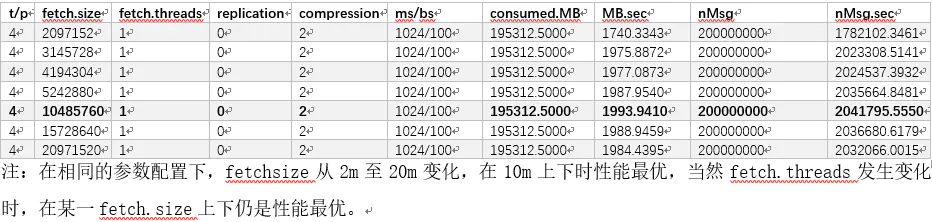
在相同的参数配置下,fetchsize从2m至20m变化,在10m上下时性能最优,当然fetch.threads发生变化时,在某一fetch.size上下仍是性能最优。
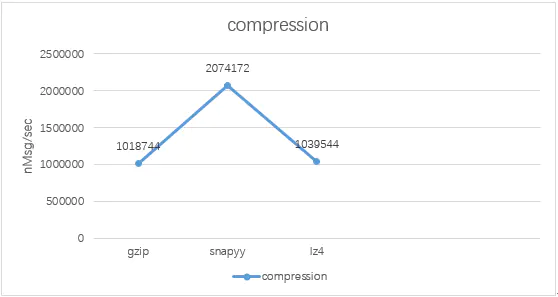
采用snapyy算法消费性能最优。
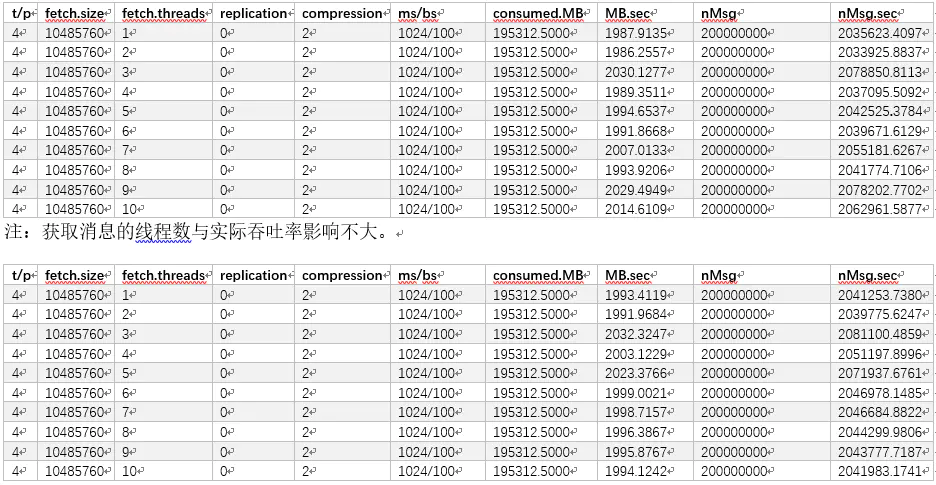
获取消息的线程数与实际吞吐率影响不大。
第一次测试数据下图:
第二次测试数据下图:
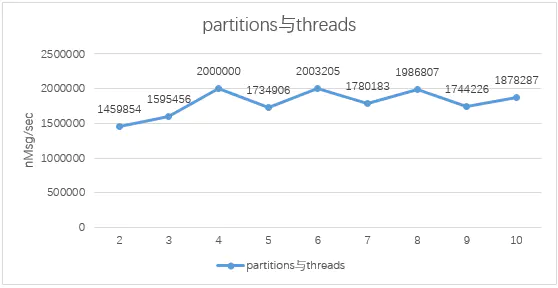
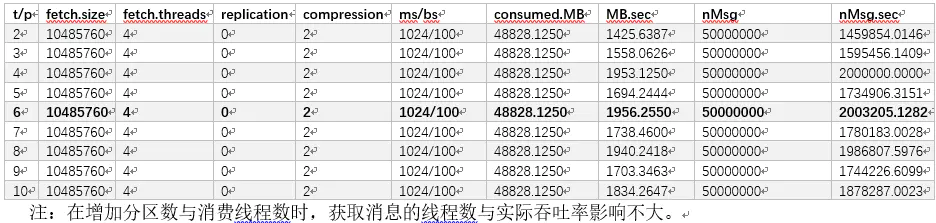
在增加分区数与消费线程数时,在小于3个分区时,3个分区与3个消费线程性能最优,在其他条件不改变的前提下,再进一步增加分区数与消费程数时,实际吞吐量变化不大。
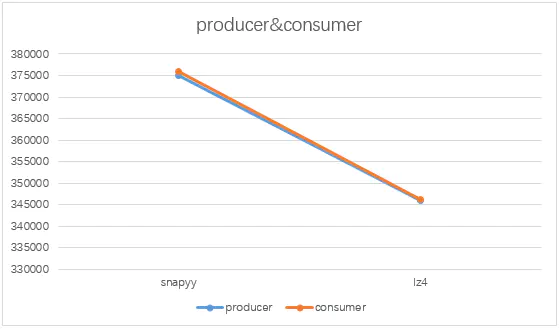
生产者与消费者同时写入与读取,不同压缩算法,snapyy方式性能最优,相比于单独消费场景,性能下降较大。
fetch.size
compression

fetch.threads
partitions与threads
producer与consume同时写入与读取

五、配置建议
基于kafka的高度可配置的特性,可以应用到不同的业务场景,比如,实时性较强的跟踪用户在页面上的行为动作、实时性不高但可靠性很高的信用卡支付操作的处理等。
可靠性配置:
复制系数,针对topic级别的配置参数是replication.factor,以本次测试为例,有3个broker实例,建议合理的复制系数为1-3,以3为例,也就是每个分区会被3个broker各复制一次,即每个broker保存一个分区,即使在2个broker失效的情况下,仍然可以向topic写入消息或从topic读取消息。总结如下:
如果复制系数为N,那么在N-1个broker失效的情况下,仍然具备读写能力,因此更高的复制系数会带来更高的可靠性,但另一方面,N个复制系数需要至少N个broker,而且会有N份数据副本(副本包含leader与follower)。
不完全的leader选举,unclean.leader.election.enable在broker级别上进行配置,默认值为true(仅在当前版本为true,后续高版本为false),官方在kafka高版本发行时,修改了这个默认值,暂时理解为官网的推荐设置,但对于实时性较高的业务,比如实时统计用户访问量的分析,一般会启用这个配置,即设置为true,但对于可靠性较高的业务,比如银行的业务,宁可花费几分钟或几个小时的延时后再处理像信用卡支付的业务,也不会冒险处理错误的消息。因此,按真实的业务场景来设置即为合理。
最少同步副本,min.insync.replicas默认是1,本次测试中采用了3个broker,因此这个值可以设置1-3,当然如果选择3时,即为最少要同步3个副本才可以向分区写入数据,即为真正的提交,需要注意的是如果有1个broker出现问题,无法同步副本,那么剩下的broker就会停止生产者的所有请求,并抛出NotEnouqhReplicasException给生产者,直至问题broker恢复,此时消费者可以正常读取消息。
producer发送确认,生产者可以选择3种不同模式的确认,acks为0时,只要生产者把消息发送出去,即认为已成功写入broker,这种模式下运行速度非常快,吞吐率和带宽利用率非常高,不过采用这种模式风险较高,容易丢失一些消息。一般压力测试都是基于这个模式的。即使实时性较高的系统,也不建议采用该模式。
acks为1时,即为leader收到消息并写入分区数据文件(不一定同步到磁盘)后,提交成功,返回确认响应。
acks为-1或all时,即leader收到消息后,会等待所有同步副本都收到消息,才会返回确认响应。
producer失败重试参数,当生产者没有收到成功的响应,重试发送次数,当前版本默认为0,根据实际业务来设置该参数,并非越大越好,也不建议设置为0,生产者收到的错误会包括2种,一种是可恢复性错误,一种是不可恢复性错误,遇到可恢复性的错误时,可以通过重试来解决,不可恢复性错误,只能由开发者手动处理。但由于网络原因造成的无法收到成功响应,此时如果无限次的重试发送,会造成分区内存在重复消息,增加了消费者读取消息时的业务处理的复杂度。因此分析实际业务场景,谨慎设置。
consumer auto.offset.reset,默认值为latest,即在没有offset时,消费者会从分区的末尾开始读取数据,减少读取重复消息的可能性,但可能会错过一些消息。设置为earliest,当出现offset不存在的情况时,从分区的开始位置读取数据,这样会读取大量重复消息,由消费端的业务逻辑来处理重复消息。增加了业务的复杂度。
consumer auto.commit.interval.ms,默认值为5000ms,即5秒提交一次,可以通过该参数来设置提交的频度,一般来说,提交频度越高,越会带来更高的系统开销,可靠性也随之提高。
1、实时类业务
实时类业务,把零延时作为第一考虑因素,比如聊天室、会议室、直播类似系统等,在保证最小延时的基础上,适当设置可靠性相关参数。建议可靠性参数如下:
replication.factor:1
unclean.leader.election.enable:true
min.insync.replicas:1
acks:0
retries:0
2、近实时类业务
即可接受一定范围内的延时,比如实时计算用户访问量等类似web监控类业务,在保证最小延时的基础上,适当设置可靠性相关参数。建议可靠性参数如下:
replication.factor:2
unclean.leader.election.enable:true
min.insync.replicas:2
acks:1
retries:1/2/3
consumer auto.commit.interval.ms:1000ms
consumer auto.offset.reset:latest
3、非实时类业务
非实时类业务,即可以允许一定时间的延时,从而来保证系统更高的可靠性。以3个broker以例,建议可靠性参数如下:
replication.factor:3
unclean.leader.election.enable:false
min.insync.replicas:2/3
acks:all
retries:MAX_INT
consumer auto.commit.interval.ms:500ms
consumer auto.offset.reset:earliest
六、疑问解答与加群学习交流

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140632.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
