大家好,又见面了,我是你们的朋友全栈君。
- Java分类
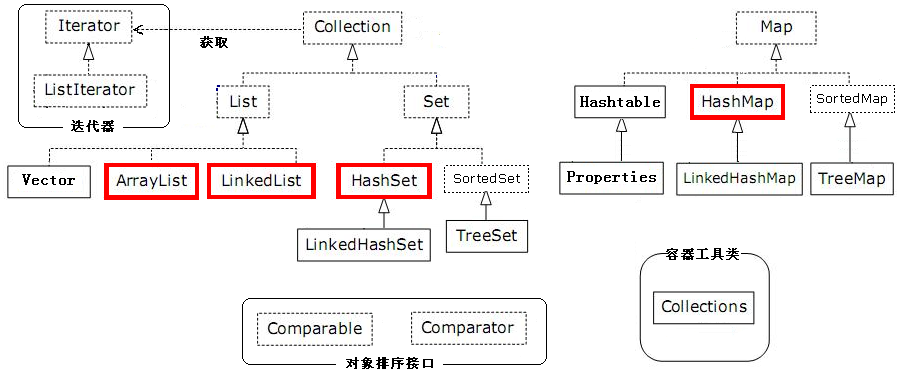
集合分为Map和Collection两大类
常用的就是ArrayList,LinkedList,HashSet,LinkedHashSet,TreeSet,HashMap,LinkedHashMap,TreeMap;
数组和集合的区别
区别1:
数组可以存储基本数据类型/引用数据类型
基本数据类型存的是值 引用数据类型存的是地址
数组在创建的时候 就会定义存储的数据类型 也就是只能存储一种数据类型
集合只能存储引用数据类型(对象)
集合中也可以存储基本数据类型(装箱)最终存储的还是 Object
如果没有泛型限定 默认存储的都是 Object类型的数据 也就是任意类型
区别2
数组长度是固定的,不能自动增长
集合是长度可变的,根据元素的多少来决定长度

集合中保存的都是引用类型,如果是基本数据类型的话会自动转成其包装类.
List是有序的(存取顺序),可以装重复元素,有索引
Set是无序的(存取顺序),不能重复,无索引值.
List下面的三个子集合的区别 |–Vector 底层数据结构是数组 查询快 增删慢 线程安全 效率低 默认长度是10 超过就会100%延长 变成20 浪费空间 |–ArrayList 底层数据结构是数组 查询快 增删慢 线程不安全 效率高
默认长度是10 超过就会new一个新的数组 50%延长 节省空间 |–LinkedList 底层数据结构是链表(双向链表)
查询慢 增删快 线程不安全 效率高Set集合的子集合 HashSet 按照哈希算法来存取集合中的对象 存取速度比较快
当程序向HashSet中 add()的一个对象的时候, 先用hashCode方法计算出该对象的哈希码 哈希码不一致 添加 哈希码一致
不添加 相同对象不添加 然后用equals判断对象的属性是否一致 比较结果为false就添加 true就不添加 不同对象添加基本数据类型包装类/String 已经重写了hashCode 和 equals 会自动比较
自定义实现类要重写其hashCode和equals方法,规定自定义类的比较规则来排重.LinkedHashSet 特点:
1.有序(存取一致)
是Set集合中唯一一个能保证怎么存就怎么取的集合对象
2.排重
3.底层是双向链表 HashSet的方法怎么用 LinkedHashSet就怎么用 TreeSet 二叉树 实现了SortedSet接口 能够对集合中对象进行排序特点:
1.排序的(升序) 自然排序 根据ASCII表大小排序
2.排重
3.无序(存取不一致)
4.底层是一个二叉树(左序中序右序)
5.只能存储同一种类型 才能排序 不然就会出现转换异常 自定义实现类 如何比较方式一 实现 Comparable 接口 重写 comparaTo方法 这种方式也称为元素的自然排序 或者是默认顺序排序 int
compareTo(T o) 比较此对象与指定对象的顺序。 如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。
负整数 此对象 < 指定对象 0 此对象 == 指定对象 正整数 此对象 > 指定对象
方式二 Comparator比较器
TreeSet(Comparator<? super E> comparator)
接口 Comparator<T>
int compare(T o1, T o2)
比较用来排序的两个参数。
根据第一个参数小于、等于或大于第二个参数分别返回负整数、零或正整数。
在实际工作中 尽量不要修改源码 使用Comparator比较器 比较个性的东西
区别:
TreeSet构造函数未传入比较器,默认按照类中的Comparable比较 如果不写 就报错
TreeSet传入Comparator比较器 就优先按照Comparator比较
遍历集合的时候 List: 普通for循环 使用get()获取元素 调用 iterator() hasNext()
next()获取元素 增强for循环 只要可以使用Iterator 的类都可以使用
Vector 集合用的是 Enumeration Set: 调用 iterator() 增强 for普通for循环 迭代器 增强for循环 是否可以在遍历的过程中删除元素?
普通 for 可以 迭代器 自己的remove() 可以 增强 for 不可以
当在用迭代器对集合进行遍历的是候,用集合的方法对集合进行操作(remove或者add)的时候,
就存在安全隐患,并发异常.可以使用ListIterator的remove方法进行删除.
Map集合 将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。
Map接口和Collection接口的不同
1.Map是双列的(夫妻 有结婚证这个联系)
Collection是单列的(单身狗)
2.Map的键是唯一的
Collection的子体系 Set是唯一的
3.Map集合的数据结构是针对键有效的 跟值无关
Collection集合的数据结构是针对元素有效 特点:
1.根据键来排重 也就是相同键的元素存储在同一个Map集合中 后添加的键值元素会将之前存储的相同的键值元素替代
2.键和值 都需要是引用数据类型实现类:
1.HashTable 底层是哈希表 不可以存入null键null值 线程同步的 jdk1.0 效率低
2.HashMap 底层是哈希表 可以存入null键null值 线程不同步的 jdk1.2 效率高
3.TreeMap 底层是二叉树 线程不同步的 可以用于给Map集合中的键进行排序 和Set很像 其实 Set底层就是用了Map集合
//遍历map集合,
//方法一: Set<K> keySet() 返回此地图中包含的键的Set视图。
Set<String> set = map.keySet();
Iterator<String> it = set.iterator();
while (it.hasNext()) {
String key = (String) it.next();
String value = map.get(key);
System.out.println(key+".."+value);
}
//增强for
for(String se:map.keySet()) {
System.out.println(se+"="+map.get(se));
}
//方法二 Set<Map.Entry<K,V>> entrySet() 返回此地图中包含的映射的Set视图。
Set<Map.Entry<String, String>> entry = map.entrySet();
Iterator<Map.Entry<String, String>> it2 = entry.iterator();
while(it2.hasNext()) {
Map.Entry<String, String> en = it2.next();
String key = en.getKey();
String value = en.getValue();
System.out.println(key+"----"+value);
}
//增强for Set<Map.Entry<K,V>> entrySet()
for(Map.Entry<String, String> en:map.entrySet()) {
System.out.println(en.getKey()+"------"+en.getValue());
}HashSet,LinkedHashSet,HashMap,LinkedHashMap,
这四个集合如果不是自定义类会自动去重,因为其他的类都自己重写了equals方法和hashCode方法,自定义类的话就需要我们自己在自定义类中重写这两个方法.
例如:
public class Girl {
private String name;
private int age;
private String phone;
@Override
public String toString() {
return "Girl [name=" + name + ", age=" + age + ", phone=" + phone + "]";
}
public int hashCode() {
return name.hashCode() + this.age*33;
}
public boolean equals(Object obj) {
if(!(obj instanceof Girl)) {
return false;
}
Girl girl = (Girl)obj;
return this.name.equals(girl.name)&&this.age==girl.age;
}
}TreeSet,TreeMap保存非自定义类会自动根据Ascll码(升序)排序,如果是是自定义类就需要自己写比较器.
两种比较器Comparator和Comparable,
实际情况下用Comparator,用法:
1.直接写成匿名内部类
TreeSet tree = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
Computer c1 = (Computer)o1;
Computer c2 = (Computer)o2;
if(c1.getType().length()>c2.getType().length()) {
return 1;
}else if(c1.getType().length()==c2.getType().length()) {
if(c1.getType().equals(c2.getType())) {
return (int) (c1.getSum()-c2.getSum());
}
return c1.getType().compareTo(c2.getType());
}
return -1;
}});2.写一个类实现Comparator接口,并重写compare方法
package com.qf.test;
import java.util.Comparator;
public class Sort1 implements Comparator{
@Override
public int compare(Object o1, Object o2) {
Computer c1 = (Computer)o1;
Computer c2 = (Computer)o2;
if(c1.getType().length()>c2.getType().length()) {
return 1;
}else if(c1.getType().length()==c2.getType().length()) {
if(c1.getType().equals(c2.getType())) {
return (int) (c1.getSum()-c2.getSum());
}
return c1.getType().compareTo(c2.getType());
}
return -1;
}
}
TreeSet tree = new TreeSet(new Sort1());Comparable的用法
public class Person implements Comparable{
private String name;
private int age ;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public Person() {
super();
}
@Override
public int compareTo(Object o) {
Person person = (Person) o;
/*if(this.getAge() > person.getAge()) { return 1; } if(this.getAge() == person.getAge()) { return this.getName().compareTo(person.getName()); } return -1;*/
/*int num = this.getAge() - person.getAge(); return num==0?this.getName().compareTo(person.getName()):num;*/
/*if(this.getName().length()>person.getName().length()) { return 1; } if(this.getName().length()==person.getName().length()) { if(this.getName().equals(person.getName())){ return this.getAge()-person.getAge(); } return this.getAge()-person.getAge(); } return -1;*/
int length = this.name.length()-person.name.length();
int num = length ==0?this.name.compareTo(person.name):length;
return num==0?this.age-person.age:num;
}
}最后讲一下 在ArrayList,LinkedList,HashSet,LinkedHashSet,HashMap,LinkedHashMap,这6种集合中元素要排序都要自己写,这里就演示一下,ArrayList中保存的是自定义类的时候的排序.
//定义Comparator比较器
import java.util.Comparator;
//排序规则:先按电脑的型号排序,型号相同按内存排(如果有固态硬盘,要加上固态硬盘内存的大小)
public class Sort1 implements Comparator{
@Override
public int compare(Object o1, Object o2) {
Computer c1 = (Computer)o1;
Computer c2 = (Computer)o2;
if(c1.getType().length()>c2.getType().length()) {
return 1;
}else if(c1.getType().length()==c2.getType().length()) {
if(c1.getType().equals(c2.getType())) {
return (int) (c1.getSum()-c2.getSum());
}
return c1.getType().compareTo(c2.getType());
}
return -1;
}
}
//自定义Computer类
package com.qf.test;
public class Computer{
private String type;
private double neicun;
private double gutai;
private double sum;
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public double getNeicun() {
return neicun;
}
public void setNeicun(double neicun) {
this.neicun = neicun;
}
public double getSum() {
return sum;
}
public Computer(String type, double neicun,double gutai) {
super();
this.type = type;
this.neicun = neicun;
this.gutai = gutai;
this.sum =neicun+gutai;
}
@Override
public String toString() {
return "Computer [type=" + type + ", neicun=" + neicun + "]";
}
}
//排序类
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Iterator;
import java.util.TreeSet;
public class Sort {
public static void main(String[] args) {
demo2();
}
public static void demo2() {
Sort1 sor = new Sort1();//实例化实现了Comparator比较器的类
ArrayList list = new ArrayList();
list.add(new Computer("huasuo",555,452));
list.add(new Computer("hu",456,74));
list.add(new Computer("hua",524,785));
list.add(new Computer("huas",852,258));
list.add(new Computer("huasuo",963,456));
//这几个集合不会自动比较,所以需要用到基本的排序方法(冒泡,选择,快速)进行排序,只是在比较的时候调用自己重写的compare方法来比较,这样的话比较的规则就是你定义的规则.
for(int i=0;i<list.size();i++) {
for(int j=0;j<list.size()-1;j++) {
//调用compare方法比较,满足条件就交换j与j+1位置上面的值进行交换,用集合的方法交换
if(sor.compare(list.get(j), list.get(j+1))>0) {
Computer c = (Computer) list.get(j);
list.set(j, list.get(j+1));
list.set(j+1, c);
}
}
}
Iterator it = list.iterator();
while(it.hasNext()) {
Computer com = (Computer) it.next();
System.out.println(com.getType()+"----"+com.getSum());
}
}
}发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140568.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
