大家好,又见面了,我是你们的朋友全栈君。
AI重新定义web及谷歌验证码安全
云给安全带来的影响
距离2006年Amazon发布EC2服务已经过去了11年,在这11年里,发生的不仅仅是AWS收入从几十万美金上涨到100多亿美金,更重要的是云计算已经走进每一家企业。根据信通院发布的“2016云计算白皮书”,目前近90%的企业都已经开始使用云计算(包括公有云、私有云等),这说明大规模云化对于企业而言已经不只是趋势,更是确凿的既成事实。
云化普及的同时也给安全带来很多挑战,主要包括:
云化导致以硬件设备为主的传统安全方式失效
我在跟企业交流时,不止一家企业提出了这样的担心:在上公有云的过程中,因为无法把已购买的硬件防护搬到云上,所以非常担心业务安全性。有趣的是,他们对于上云后的流量层攻击反倒不担心,因为他们认为云上的高防IP等产品可以解决大部分问题。云化导致了业务层的安全空白,这不仅发生在公有云环境,在私有云环境也时有发生,以OpenStack Icehouse版本为例,至今仍缺少能够有效横向扩展的Web安全组件。
云化导致攻击/作恶成本大大降低
云是IT领域里“共享经济”的再升级,从最早的IDC租用升级进化到Linux kernel namespace租用,但这种“共享经济”在给企业带来成本降低、使用便利等益处的同时,也顺便给攻击者带来了同样的好处。按目前市场行情,攻击者租用一个公网弹性IP的成本可低至1元/天,租用一个IaaS平台的hypervisor层的计算环境,每日成本也只有几元,如果是container层的计算环境,成本还要更低。如此低的成本,致使攻击者不再像过去那样花大力气挖掘培养肉机,而是可以在瞬间轻松拥有用于攻击的计算网络资源。以白山服务的某著名互联网招聘领域客户为例,攻击者最多可以在一天内动用上万个IP以极低的频率爬取核心用户简历。
云化导致业务可控性降低
遭遇攻击的风险大大提高。实际上云客观造成了业务的复杂性和不可控性:大量自身或合作方的业务都跑在同一个云上,其中任何一个业务被攻击,都有可能对其他部分造成影响。不可否认,现有的hypervisor隔离技术很成熟,以CPU为例,通过计算时间片分配进而在执行指令间插入各种自旋锁可以精确控制执行体的CPU分配,其他资源包括内存、IO也都可以恰当的控制。但在所有资源里,隔离性最脆弱的就是网络,尤其是公网,毕竟NAT出口、域名等很难被隔离。
所以,我们不得不面对这样的现实:在享受云计算时代红利的同时,面临的业务层安全问题也越来越严重。
安全产品需要变革
遗憾的是,很多传统安全产品并没有跟上这个时代。最明显的例子,15年前的防火墙就依靠着在命令行设定各种各样的policy工作;而15年后的今天,一切的变化只是由命令行设定policy变成了界面设置policy,这不得不说是一种悲哀!
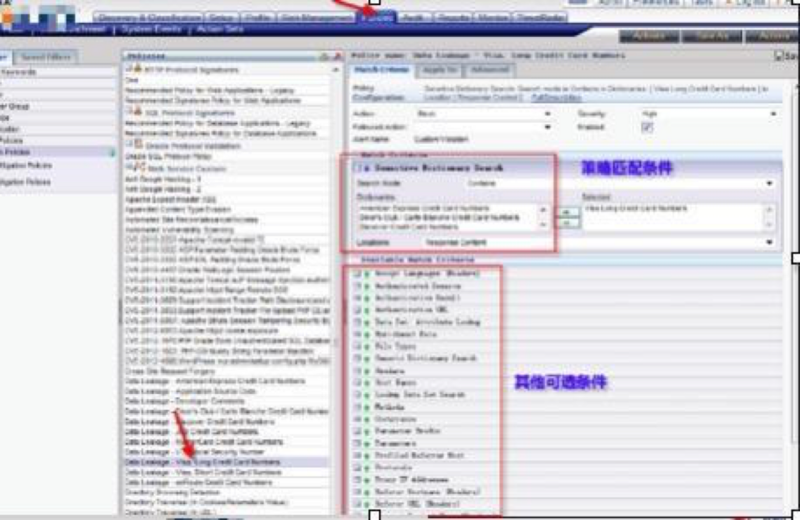

对于传统安全产品,设定policy是一种痛苦
我曾经听某著名安全厂商的布道师演讲,“买了我们的产品不代表你的业务就安全了,你必须学会怎么配置!”,这话听起来有道理,但遗憾的是,大多数公司的安全人员并不是公司的业务开发者,他们不知道业务页面应该从哪个referer过来、不应该接受哪个user-agent的请求,也不知道某个接口应该接受哪些参数,甚至不知道业务对于单个用户的合理访问频率区间。更遗憾的是,这些传统安全产品价值不菲,在你花了上百万银子后,很可能毫无作用,而最悲哀之处在于“你以为它在起作用!”
传统的安全产品因为必须要串接到业务中间,这带来了极大的不稳定性。虽然某些先进的硬件机制可以通过技术降低这个风险,但仍不可避免的是:串接会带来性能延迟+带宽瓶颈。有些企业一开始购买了100Mbps吞吐量的硬件安全产品,但当业务突增时,硬件却无法自由横向扩容。更麻烦的是,串行模式一旦分析的维度变得复杂(如策略变多时),就注定会造成业务的访问延迟;而分析维度一旦少,如退化为只做固定时间内访问频率限制,又会造成识别错误率上升。这是传统安全产品无法解决的永恒矛盾体。
不幸的是,虽然传统安全产品存在诸多问题,但很多用户仍在默默忍受,甚至习惯了每天配置策略的工作。但这并不意味着合理。
在不便中,一直蕴藏着技术革新的机会!这时,机器学习来了!
机器学习是解决安全问题的金钥匙

机器学习发展史
机器学习其实早已到来。由上图中可以看出,目前大红大紫的深度学习,其源头-神经网络,早在上世纪70年代就已经被提出。从上世纪80年代到本世纪,机器学习本身经历了几次平淡期和爆发期,随着大数据的发展和一些热点事件(如AlphaGo战胜李世石)机器学习又一次进入爆发期。
那么大数据和机器学习具有什么关系呢?这还要和深度学习挂钩,从理论上讲,深度学习本质上是利用多层的神经网络计算,代替传统特征工程的特征选取,从而达到媲美甚至超越传统特征工程进行分类算法的效果。基于这个逻辑,当标注样本足够多时(即所谓“大数据”),通过深度学习就可以构造出非常强大的分类器,如判断一个围棋的棋局对哪方有利。
AI随着目前深度学习的火爆看似非常强大,但不幸的是,坦白讲目前AI的发展成熟度远没有达到可以取代人脑抑或接近人脑的水平。根据图灵测试理论,AI本身要解决的问题无外乎:识别、理解、反馈。
这三个问题逐步递进,真正智能的机器人最终可以跟人脑一样反馈,从而在图灵测试中无法区分它是人还是机器。
按当前AI发展情况,“识别”的进展目前效果最好,无论是图像、语音还是视频,目前很多厂商都可以做到很高的识别率;但“理解”就差强人意了,大家都用过苹果的Siri,它还未能达到与人真正对话的程度;而反馈就更难了,这要求在理解的基础上不断地应变,同一个问题可能因对方身份、心情、交流场合不同,以不同的语气语调做出不同反应。
所以,目前应用机器学习效果非常好的领域,几乎都是某个特定领域内的识别问题,并非通用领域,如人脸识别、人机对弈(人机对弈本质上也是某个棋种领域的识别问题:机器通过学习成千上万的棋局后,就可以自动识别某一棋局在一方走的情况下对谁有利。)
非常幸运的是,安全领域中问题大多是特定场景下的识别问题,而非通用场景,也并未涉及理解和反馈,你只需要把相关数据交给机器学习系统,让它做出识别判断即可:安全或者不安全,不安全的原因。
正因为安全问题本质是特定领域内的识别问题,所以从理论上讲,机器学习非常适合应用在安全领域,是解决安全问题的金钥匙。
安全结合机器学习的难点
虽然机器学习早已存在,但是长久以来并未改变安全市场,不同于其他通用领域,以“土办法(设定策略)”立足的产品仍旧占据主导地位,究其原因,主要有以下几点:
1 安全结合机器学习的难点
对于机器学习而言,拥有海量、完整、客观、准确的标注样本异常重要,标注样本越多、越全面,训练出来的分类器才可能越准确。对于所有行业来讲,获取样本(标注样本)都并不容易,而安全领域尤为困难。如对人脸识别的标注,初中生甚至小学生就可以完成,但对于一次安全的威胁事件,就需要极具经验的安全人员才可以完成,两者的成本差距十分巨大。

如上图所示,这个注入攻击经多次复杂编码,非专业人事很难进行样本标注。所以目前在通用场景下,之所以安全领域中深度学习落地并不多,主要原因也是很难获取海量的标注数据。
2 安全领域的场景特点更加明显
安全领域的场景特点更加明显,判断攻击的标准会随着业务特点的不同而不同。以最简单的CC攻击为例,600次/分钟的访问对于某些企业可能意味着破坏性攻击,但对其它企业则属于正常访问范围。所以,即便有大量的标注样本,某一企业的标注样本可能对于其他企业毫无用处,这也是导致安全领域应用机器学习较为困难的另一个重要原因。
3 传统思维认为简单的特征更有效
针对传统的文本型攻击,传统思维认为简单的特征工程,甚至直接的正则匹配更有效。
我们把Web攻击分为行为型攻击和文本型攻击两类:
1 行为型攻击:
每个请求看起来都是正常的,但将其连接成请求走势图时,就会发现问题,如爬虫、撞库、刷单、薅羊毛等。以刷粉行为为例:每个请求看起来都是正常的,但攻击者可能动用大量IP在短时间内注册大量账号,并关注同一个用户。只有我们把这些行为连接起来一起分析时,才能发现问题。
2 文本型攻击:
传统的漏洞类攻击,如SQL注入、命令注入、XSS攻击等,单纯的把一个请求看成是一段文本,通过文本的特征即可识别其是否为攻击。
当特征的维度空间较低,且有些维度的区分度很高时,通过简单的线性分类器,就可以实现不错的准确率,例如我们简单的制定一些SQL注入的正则规则,也可以适用于很多场景。但是,这样的传统思维却忽略了召回率问题,实际上也很少有人知道,通过SQL注入的正则规则,可以达到多少的召回率。同时,在某些场景,假如业务的正常接口通过JSON传递SQL语句,那么这种基于正则规则的分类器就会产生极高的误判。
4 传统安全人员并不了解机器学习
这是一个不争的事实,大量传统安全公司的安全人员精于构造各种漏洞探测、挖掘各种边界条件绕过,善于制定一个又一个的补丁策略,却并不擅长AI机器学习方面的内容,这也说明了这种跨界人才的稀缺和重要。
正是由于以上原因,AI智能的安全产品迟迟没有出现,但没人可以否认,用户其实早已厌倦policy驱动的规则模式,期待有一种可以适应大多数场景、能够针对行为或文本做深入分析、不需要复杂配置就可以达到高准确率和召回率的Web安全产品。
于是,我们用AI重新定义Web安全,因为我们坚信异常行为和正常行为可以通过特征识别被区分。
用AI重新定义Web安全
那如何解决安全领域的样本标注问题呢?机器学习分为两大类:监督学习和无监督学习。监督学习要求有精准的标注样本;而无监督学习则无需标注样本,即可以针对特征空间进行聚类计算。在标注困难的安全领域,显然无监督学习是一把利器。
应用无监督学习
无监督学习无需事先准备大量标注样本,通过特征聚类就可以将正常用户和异常用户区分开,从而避免大量样本标注的难题。聚类的方式有很多,如距离聚类、密度聚类等,但其核心仍是计算两个特征向量的距离。在Web安全领域,我们获得的数据往往是用户的HTTP流量或 HTTP日志,在做距离计算时,可能会遇到一个问题:每个维度的计算粒度不一样,如两个用户的向量空间里HTTP 200返回码比例的距离是两个float值的计算,而request length的距离则是两个int值的计算,这就涉及粒度统一归一化的问题。在这方面有很多技巧,比如可以使用Mahalanobis距离来代替传统的欧式距离,Mahalanobis距离的本质是通过标准差来约束数值,当标准差大时,说明样本的随机性大,则降低数值的权值,反之,当标准差小的时候,说明样本具有相当的规律性,则提高数值的权值。
无监督的聚类可以利用EM计算模型,可以把类别、簇数或者轮廓系数(Silhouette Coefficient)看成EM计算模型中的隐变量,然后不断迭代计算来逼近最佳结果。最终我们会发现,正常用户和异常聚成不同的簇,之后就可以进行后续处理了。当然,这只是理想情况,更多情况下是正常行为与异常行为分别聚成了很多簇,甚至还有一些簇混杂着正常和异常行为,那么这时就还需要额外技巧处理。
学习规律
无监督聚类的前提是基于用户的访问行为构建的向量空间,向量空间类似:
[key1:value1,key2:value2,key3:value3…]
这里就涉及两个问题:“如何找到key”以及“如何确定value”。
找到合适的key本质是特征选择问题,如何从众多的特征维度中,选择最具有区分度和代表性的维度。为什么不像某些DeepLearning一样,将所有特征一起计算?这主要是考虑到计算的复杂度。请注意:特征选择并不等同于特征降维,我们常用的PCA主成分和SVD分解只是特征降维,本质上DeepLearning的前几层某种意义上也是一种特征降维。
特征选择的方法可以根据实际情况进行。实验表明在有正反标注样本的情况下,随机森林是一个不错的选择。如果标注样本较少或本身样本有问题,也可以使用Pearson距离来挑选特征。
最终,用户的访问行为会变成一组特征,那特征的value如何确定?以最重要的特征——访问频率为例,多高的访问频率值得我们关注?这需要我们对于每个业务场景进行学习,才能确定这些key的value。
学习的规律主要包括两大类:
行为规律:自动找出路径的关键点,根据状态转移概率矩阵,基于PageRank的power method计算原理,网站路径的状态转移矩阵的最大特征值代表的就是其关键路径(关键汇聚点和关键发散点),然后顺着关键点,就可以学习到用户的路径访问规律。
文本规律:对于API,可以学习出其输入输出规律,如输入参数数量、每个参数的类型(字符串or数字or邮箱地址等)、参数长度分布情况,任何一个维度都会被学习出其概率分布函数,然后就可以根据该函数计算其在群体中的比例。即便是最不确定的随机分布,利用切比雪夫理论也可以告诉我们这些值异常。例如:假如GET /login.php?username=中的username参数,经过统计计算得出平均长度是10,标准差是2,如果有一个用户输入的username长度是20,那么该用户的输入在整体里就属于占比小于5%群体的小众行为。
通过特征选择和行为、文本规律学习,我们就可以构建出一套完整且准确的特征空间将用户的访问向量化,进而进行无监督学习。
让系统越来越聪明
如果一个系统没有人的参与,是无法变得越来越聪明的,强大如AlphaGo也需要在同人类高手对弈中不断强化自己。在安全领域,虽然完全的样本标注不可能,但是我们可以利用半监督学习的原理,挑选具有代表性的行为交给专业的安全人员判断,经过评定校正,整个系统会越发聪明。安全人员的校正可以与强化学习和集成学习结合实现,对于算法判断准确的情况,可以加大参数权重,反之则可以适当减少。
类似的想法出现于国际人工智能顶级会议CVPR 2016的最佳论文之一,“AI2: Training a big data machine to defend”,MIT的startup团队,提出了基于半监督学习的AI2系统,可以在有限人工参与的情况下,让安全系统更安全更智能。
重新定义Web安全
基于上述几点,我们基本可以勾勒出基于AI的Web安全的基本要素:
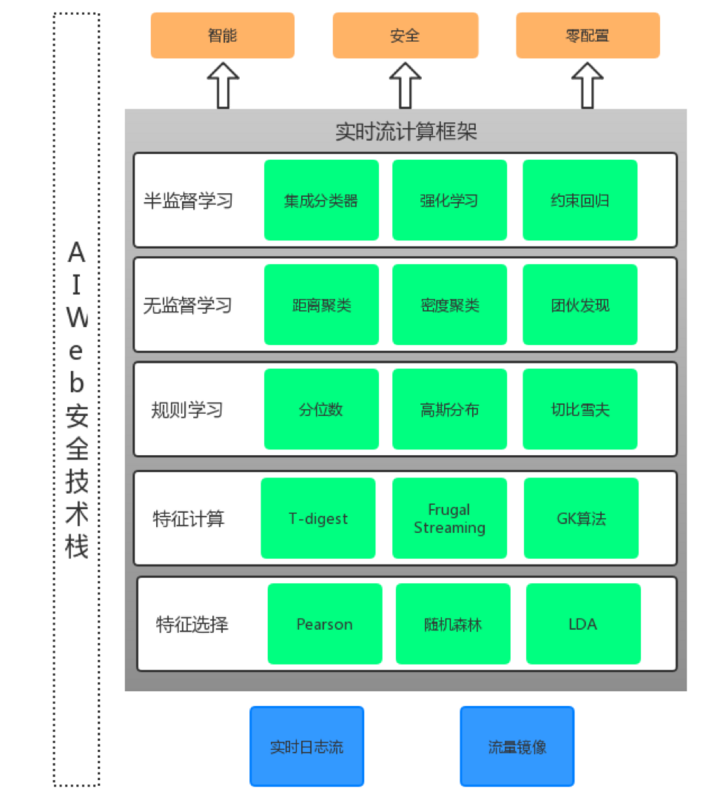
AI Web安全技术栈
从图中可以看到,所有算法均包含在实时计算框架内。实时计算框架要求数据流的输入、计算、输出都是实时的,这样才可以保证在威胁事件发生时系统迅速做出反应。但是,实时计算的要求也增加了很多挑战和难点,一些传统离线模式下不是问题的问题,在实时计算下会突然变成难题。如最简单的中位数计算,要设计一套在实时流输入的情况下同时还能保证准确性的中位数算法并不容易,T-digest是一个不错的选择,可以限定在O(K)的内存使用空间。还有一些算法可以实现在O(1)内存占用的情况下计算相对准确的中位数。
综上所述,我们可以看出利用AI实现Web安全是一个必然的趋势,它可以颠覆传统基于policy配置模式的安全产品,实现准确全面的威胁识别。但是,构造基于AI的安全产品本身也是一个复杂的工程,它涉及特征工程、算法设计和验证,以及稳定可靠的工程实现。
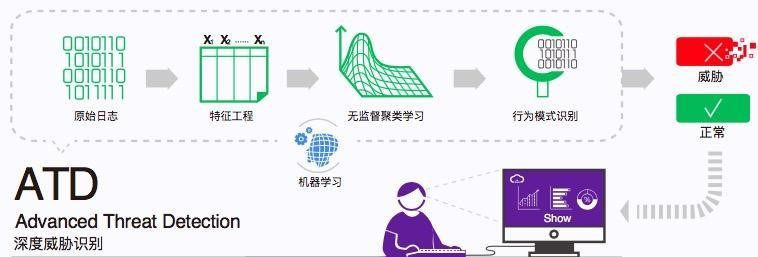
ATD深度威胁识别系统
白山一直在基于AI的Web安全方面探索,并于2017年7月正式推出ATD(Advanced Threat Detection,深度威胁识别)产品,可以准确识别并拦截各种行为或者文本攻击,包括爬虫、恶意注册、撞库、刷单刷票、薅羊毛、各种注入攻击脚本攻击等,短短半年内已经积累了30余家大中型企业客户。实践证明,机器学习确实在Web安全方面收效颇佳,如:
1) 国内某Top3招聘网站,长期以来一直被爬取简历,这些恶意爬虫非常智能,在User-agent、referer等字段上完全模拟正常用户,并内嵌PhantomJS,可以执行JavaScript脚本,使传统的JS跳转防御方式完全失效。这些爬虫动用大量弹性IP,以极低频率抓取,据统计,单个客户端每天最低可以低至十次以下,传统的安全产品对此完全丧失防御能力。而基于机器学习的 ATD则可以通过特征向量建模,准确区分低频爬虫与正常用户行为。经验证,准确率高达99.98%。
2) 国内某Top3直播平台,存在大量的恶意刷分刷排名情况,这种行为破坏了平台的公平性,本质上损害了平台利益。作恶团伙事先批量注册大量小号,在需要时冲排名。这些行为显然传统安全产品无能为力,某些新兴安全产品虽然可以解决,但需要大量定制化规则,通用性较差。机器学习算法正好弥补了以上不足,通过行为分析可以计算出关键路径和规律,然后利用子图识别等算法分析出作恶团伙,最终输出ID账号。经用户验证,ATD的准确率高达99%以上,召回率比传统安全产品提高10倍以上。
总之,基于AI的Web安全是新兴的技术领域,虽然目前还处于发展期,但最终一定会取代以policy为驱动的传统安全产品,成为保证企业Web安全的基石。
AI重新定义谷歌图形验证码安全
谷歌图形验证码安全形同虚设
谷歌已经宣布退出图形验证码服务,为何国内各种奇葩验证方式层出不穷,安全性到底如何?
《腾讯防水墙滑动拼图验证码》
《百度旋转图片验证码》
《网易易盾滑动拼图验证码》
《顶象区域面积点选验证码》
《顶象滑动拼图验证码》
《极验滑动拼图验证码》
下一代隐藏式验证安全已经出现
新昕科技 www.newxtc.com ,创始团队来自百度旗下去哪儿、易宝支付、联动优势、高阳捷讯(19pay)等支付及航旅知名企业,历时3年时间,在价值百万的风控引擎基础上 ,训练出“防短信轰炸”智能模型,彻底解决“安全”与“用户体验”的矛盾,产品经理只需专注用户体验,无需为安全让步。
1)无感:去类12306、对缺口拼图、拖动等所谓人机验证有感方式。
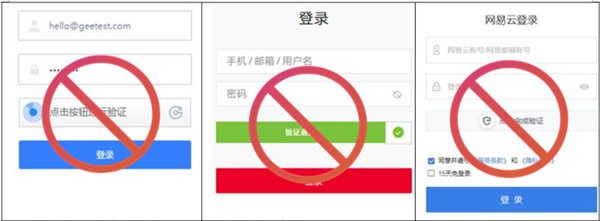
化繁为简,简单到只需输入手机号,还产品本来面目

2)保障:攻防对抗大数据训练的 AI模型,去前端交互验证方式,后端防御确保短信安全。
比如,同一个IP ,即使有1万个正常用户同时共同使用,可以确保放行,但常规的防控大多数被误拦。
反之,攻击者控制1万台主机,1万个不同IP、手机,也保证拦截,但常规的防控对此无能为力。
如何做到的, 基于AI的立体防御体系,
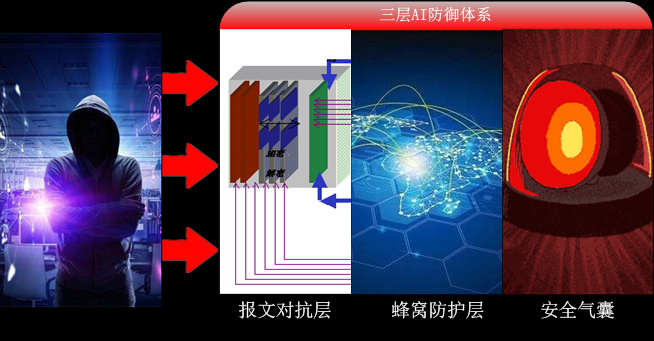
“报文对抗层” 在最外层应用加解密及混淆技术,对抗普通的攻击,
“蜂窝防护层” 由时空主体组成蜂窝,确保被攻击后“蜂窝”之间互不影响,缩小受影响的范围,
“安全气囊” 在确保老用户不受影响下, 根据攻击规模自动启停并进行动态控制。
3)高效:价值百万的风控引擎浓缩的10M “短信防火墙”安装包,本地部署运行,毫秒级响应。
避免“云模式”的网络延时问题,导致滑动条出不来等情况
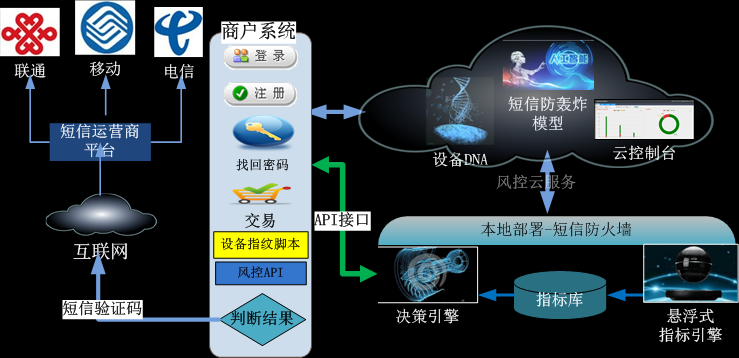
关键技术说明:
“悬浮式指标引擎”:加载AI模型,悬浮于磁盘超高速运行,随输入的业务数据生成统计指标,提供给决策引擎做进一步分析处理,
“决策引擎”: 加载“短信防轰炸”AI模型和指标后,和输入的业务数据流做逻辑判断后,输出风险结果,响应速度达到恐怖的1毫秒。
“设备指纹”:采用国际前沿技术打造,精确识别出设备唯一编号,具有精准、安全、高速的优势。
总结:随着互联网技术的不断发展,我们每日都离不开与互联网的交互。短信验证码作为互联网交互中的重要环节,保卫着网站的安全以及我们的信息安全。用户体验差、毫无安全性可言的图片验证码将退出历史舞台,未来将会是安全与体验双重保障的验证码的时代。
编者: 刘光昕 ,新昕科技创始人、CTO , 北京理工大学 学士学位,曾经在中科院大学计算中心任教,是几家知名公司交易及风控体系的缔造者,在支付及风控领域积累了丰富的实战经验,并培养了一批在交易及风控领域方面的专业技术人才 。 曾经在联动优势 、百度旗下去哪儿 、易宝支付、高阳捷讯就职,全面负责交易及安全体系的产品、技术及运营团队的管理。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140534.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
