大家好,又见面了,我是你们的朋友全栈君。


虽然,POW算法其实并没有协调选择博弈论中的安全性,因为多数联盟可以形成和有益的审查和回复块。但是当我们考虑PoW的攻击时,通常不会考虑到矿工联合攻击,而是想到购买矿工设备或者对更重链进行挖矿。这篇文章主要是谈论PoW对抗控制半数哈希力攻击的能力,不允许租用,或贿赂矿工,或与矿工进行任何其他形式的合作。
外部攻击
外部攻击者购买足够的GPU或者ASIC直到完成对可信网络的“51%攻击”,或者至少不与攻击者合作。
假设通过给1个GUP可挖矿的区块链增加X哈希力,并且会让这个X哈希算力的GPU矿工从挖这个区块链转移到其他区块链(因为如果不这样,攻击者的链就会获利变少)。GPU挖掘假设是一种有效的、完全竞争的区块链市场。
在这个“简单模型”中,对于有T算力的区块链,攻击者需要的算力是X=T/2,这些是非常多的GPU。
同时,假设通过增加X的ASIC算力,ASIC网络的算力提升了X。ASIC挖矿区块链是一种垄断市场。在另个“简单模型”中,如果要攻击T算力的ASIC区块链,则需要有T算力才能发动攻击。
事实上,真实的情况是介于两者之间。区块链GPU矿工市场并不是完全竞争的,区块链ASIC矿工也不是完全垄断。
尽管这非常有趣,但是我们尽量保持简单:不再讨论ASIC,假设我们就需要T/2的算力,来攻击拥有T算力的区块链。
而且,这其实应该是“充分竞争”的场景,因为矿工在发现有攻击者出现的时候,就会立刻去挖别的,因为区块链受到攻击意味着利润降低。
所以,我们模型的关键,就是持有T/2的算力,就可以攻击拥有T算力的区块链。
内部攻击者
内部攻击者不会去购买足够的GPU来获得T/2的算力,而是购买更少部分的算力X= p*T。内部攻击者开始挖矿,并且现在网络最诚实的部分拥有Y = T – X = (1 – p)*T算力。内部攻击者继续在最长的链上挖矿,获得区块奖励,和其他矿工竞争。
内部攻击者会将挖矿奖励用于购买更多算力。假设在我们的模型,内部攻击者能够以每月1+r的速率来增加算力。也就是说,如果内部攻击者在0月份获得X算力,那么在1月份就会获得X(1 + r)的算力。
同时也假设最诚实的矿工也投资来获得更多算力,但是按照每月1+h的速率增加。
在这个实验中,我们假设1 + r > 1 + h。攻击者都会想要最大化自己的算力。最诚实的矿工专注于利润。攻击者也许会因为这种利益获得赞助,或者长期的策略。最诚实的矿工不会和这个攻击者合作,并且不知道有攻击者的存在(攻击者会看起来是诚实挖矿,但是自私挖矿会增加r – h的值)。
在N个月之后,内部攻击者已经有了X(1+r)N的算力,而且网络还剩下Y(1+h)N算力。攻击者在获得和网络同样算力的时候,就胜利了。 X(1+r)^N =Y(1+h)^N <==> ((1+r)/(1+h))^N = Y/X = (1-p)/p 我们把(1+r)/(1+h)比例成为攻击者的“优势”,并且记为a。所以当a^N = (1-p)/p时,攻击者胜利。
内部攻击者有a和初始哈希力的比例p,因此可以在经过N = ln((1 – p)/p)/ln(a) months月后,进行成功的攻击。同时,也不一定就是月份,在任何阶段数学都是不变的,只要我们能够计算出“a”。
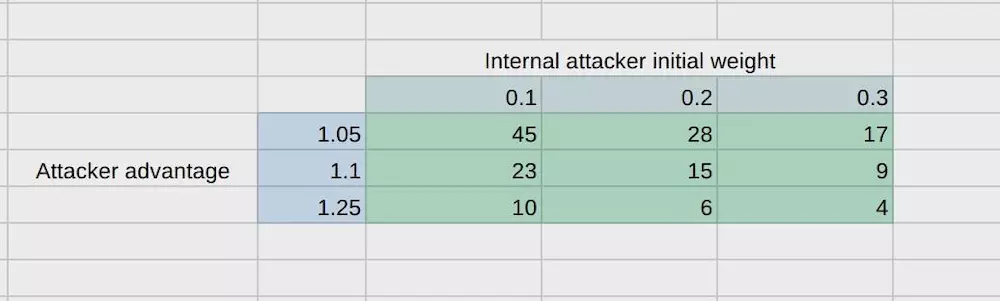
下面表格中的数字可以帮助我们理解:
根据上面的数字,对于内部攻击来说,每个月都有5%, 10% 和25%的涨幅,而且网络的初始算力有10%, 20% 或者 30%。
那么对于这个模型,我们有多少的安全性呢?
了解这个“内部”策略的外部攻击者有选项。如果他们知道他们会在N个月后进行攻击,而且他们也知道自己的a是多少,然后他们就会计算需要的初始算力比重。也就说,他们可以计算出自己所需要的GPU.
如果攻击者知道他们所需要的GPU,已经a的值,那么他们就可以计算所需要的月数来获得他们攻击目标的大多数算力。
那么区块奖励让我们获得了什么?
增加区块奖励可以增加购买算力的成本。攻击者之前可以买得起10%的算力,但是现在可能只能买得起5%的算力,来开始他们的攻击。
如果将区块奖励翻倍,那么就会延迟区块奖励: ∆N =ln((1 – p/2)/(p/2))/ln(a) – ln((1 – p)/p)/ln(a) = (ln((2 – p)/p) – ln(p/(1 – p)))/ln(a) = ln((2-p)/(1-p))/ln(a) 所以如果增加区块奖励,就可以降低a的值,然而降低了购买哈希算力p的能力,从而也降低了∆N = ln((1-p)/(2-p))/ln(a)攻击成功的概率。
请看另一个表格。
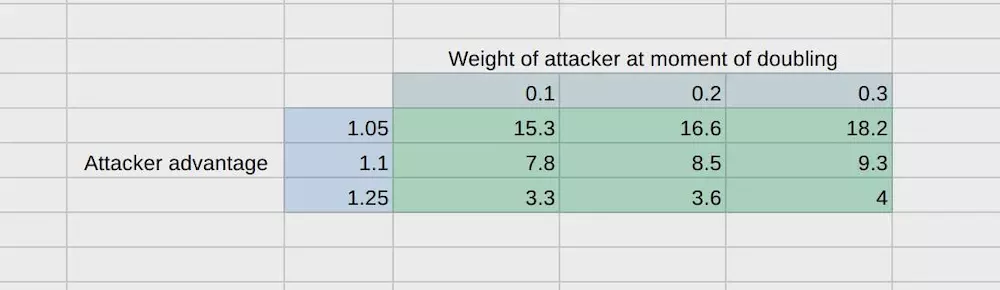
由于加倍了区块奖励,拥有10%,20%或者30%比重的攻击者,假设他们有5%,10%或者25%的a值,所需要的月份都会增加。假设在哈希算力增加的情况下,网络哈希力也会增加(在完全竞争市场的假设)。
区块奖励翻倍将攻击延迟了10个月。但是,每10个月增加区块奖励,这样来永久推迟攻击,代价非常昂贵。
总结
其实这个模式非常简单,假设攻击者最初有一定的算力,同时也能够按照一定比例来增加算力,这会比现在矿工的算力呈指数级增加。这是可靠的假设,因为利润和算力呈正比,并且因为这使得数学非常可行。
我们可以看到一些数字,究竟攻击者需要几个月,才可以在给定的a值下,完成攻击,而且如果增加区块奖励,他们的攻击会被延迟多久。 所以,很明显如果增加区块奖励,在这个模型中,是可以增加网络的安全性。假设,矿工不会和攻击者合作,而且攻击者会购买哈希算力来进行网络攻击(不论他们是否会在购买后进行诚实挖矿)。
但是,这个模型能否真实使用,仍然需要证实。如果有人提出更加合理的a值,那么就会更好了,当攻击者尝试不同的策略,都可以适用。 这些数字会帮助我们思考有多少安全矿工在抵御这些不和矿工合作的攻击者。
原文:https://medium.com/@Vlad_Zamfir/simple-model-of-an-internal-pow-attacker-1a713cf00672
作者:Vlad Zamfir
编译:nuszjj
稿源(译):巴比特资讯(http://www.8btc.com/simple-model-of-an-internal-pow-attacker)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140277.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
