大家好,又见面了,我是你们的朋友全栈君。
-
计算机网络
-
操作系统
-
数据结构
-
计算机组成原理
可重点学习如下知识点
计算机网络(重点看 OSI七层模型 或 TCP/IP五层模型 理解每层含义)
数据结构(重点看 数组、栈、队列、链表、树)
算法(重点看 各种 排序算法、查找算法、去重算法,最优解算法,多去 LeetCode 刷算法题)
操作系统(重点看 进程、线程、IO、调度、内存管理)
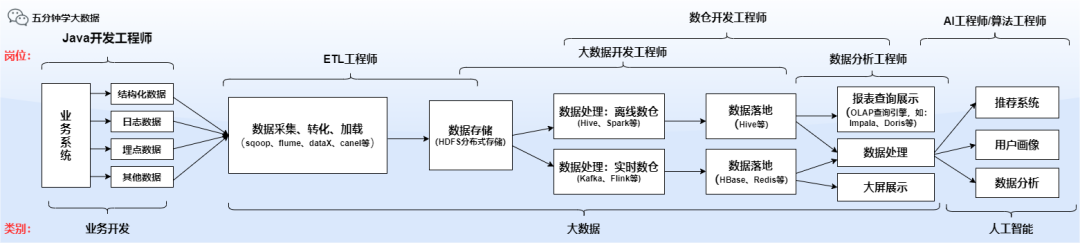

数据仓库分为离线数仓和实时数仓,但是企业在招聘时大多要求两者都会,进入公司之后可能会专注于离线或实时其中之一。
不管离线还是实时,重中之重就是:SQL
SQL 语法及调优一定要掌握,这里说的 SQL 包括 mysql 中的 sql,hive中的 hive sql,spark 中的 spark sql,flink 中 的 flink sql。
在企业招聘的笔记及面试中,一般问的关于 sql 的问题主要是以 hive sql 为主,所以请重点关注!
-
实时数仓需要重点掌握的技能:
-
Hadoop(这是大数据基础,不管离线和实时都必须掌握)
-
Kafka(重点,大数据领域中算是唯一的消息队列)
-
Flink(重中之重,这个不用说了,实时计算框架中绝对王者)
-
HBase(会使用,了解底层原理)
-
Druid(会用,了解底层原理)
-
实时数仓架构(两种数仓架构:Lambda架构和Kappa架构)
-
Hadoop(HDFS,MapReduce,YARN)
-
Hive(重点,包括hive底层原理,hive SQL及调优)
-
Spark(Spark 会用及了解底层原理)
-
Oozie(调度工具,会用即可)
-
离线数仓建设(搭建数仓,数仓建模规范)
-
维度建模(建模方式常用的有范式建模和维度建模,重点关注维度建模)
-
大数据开发分两类,第一类是编写Hadoop、Spark、Flink 的应用程序,第二类是对大数据处理系统本身进行开发,如对开源框架的扩展开发,数据中台的开发等!
-
语言:Java 和 Scala(语言以这两种为主,需要重点掌握)
-
Linux(需要对Linux有一定的理解)
-
Hadoop(需理解底层,能看懂源码)
-
Hive(会使用,能进行二次开发)
-
Spark(能进行开发。对源码有了解)
-
Kafka(会使用,理解底层原理)
-
Flink(能进行开发。对源码有了解)
-
HBase(理解底层原理)
MySQL需要学习 sql 语法,范式,事务等。
hadoop -> zookeeper -> hive -> flume && sqoop -> azkaban && oozie -> 数仓建模理论+实践 -> hbase -> redis -> kafka -> elk -> scala -> spark -> kylin -> flink -> 实时数仓项目
学完以上技能后,有时间还需要学习比较流行的 OLAP 查询引擎
Impala 、 Presto、Druid 、 Kudu 、 ClickHouse 、 Doris
如果还有时间,可以学习数据治理相关的内容,如元数据管理,数据湖等
Atlas 、 Hudi

我作的这幅图把Hadoop放在了核心位置,旁边都是围着它的组件,说明了Hadoop的重要性,需要重点学习,后面的一切都是以Hadoop为基础的。
从图中能看出这些组件的图标大多是动物,而左下角的 zookeeper 的图标是人,为动物园管理者,所以从图标中我们也能猜出zookeeper是用来管理这些大数据框架的。
再来看下 Hive,大象头,蜜蜂的身体,大象是Hadoop,蜜蜂是采蜜的,所以我们猜测Hive作为数据仓库和Hadoop密不可分的,并且收集数据的。
HBase作为数据库,图标是鲸鱼,鲸鱼是世界上最大的动物,代表HBase是存储巨量的数据
Impala是一个OLAP查询分析引擎,图标是一个斑羚羊,斑羚羊的特点就是跑的特别快,所以Impala是查询速度特别快的一个交互式查询分析引擎。
Flink是一个松鼠,松鼠的特点就是快速和灵巧,和Flink的理念相吻合。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140254.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
