大家好,又见面了,我是你们的朋友全栈君。
目录
0.前言
最近这一个月基本没写过博客,因为一直在树莓派4B上部署yolov5的模型,已经数不清楚踩了多少坑了,来来回回折腾了一个月,终于完成了。于是写下这篇博客,一是记录下全部的流程,方便以后其他项目借鉴;二是希望和我一样有类似需求的朋友能少走些弯路。
在此之前,我想先把一些重要的东西说在前面:
1.在树莓派上部署自己训练的yolov5模型,和在电脑端运行python detect.py完完全全是两码事,差的不是一点半点。这篇博客中讲的部署需要依赖NCS2进行加速,是把.pt模型转换成.onnx模型,然后再通过openvino转换成IR中间模型(.xml模型存储网络拓扑结构,.bin模型存储权重偏置等),最后在NCS2上运行推理,并对结果进行处理。
如果这么说还是不直观的话,我举个例子:我从不知道yolov5是什么,到在电脑上训练好自己的.pt模型总共花了一下午。然而我把自己训练好的.pt模型成功部署到树莓派上运行花了20多天。
不过别被吓到,我花了这么久是因为我踩了太多的坑,浪费了太多的时间。(但我一开始也确实不知道该走哪条路,只能一条一条试啊md!!)其实部署过程真的不麻烦,但需要内心平静,不要急躁。
2.如果你想在直接在树莓派上安装pytorch然后和电脑上一样运行.pt模型的话,我建议你不要走这条路了,因为我已经走过了:用最简单的yolov5s.pt模型跑帧率大概0.3fps,这还是单线程情况下的,多线程就别提了,根本不可能满足实时推断。树莓派4B的计算资源还是太弱了,所以才要用NCS2加速推理,加速后能到3fps,勉强能用。
在接着往下看之前,希望你对下面的概念有部分了解,或者有些印象。(一点都不了解的话建议百度学习一下再来看,了解下就行,磨刀不误砍柴工。)
1 、知道yolov5,用它在电脑上训练过自己的模型更好;
2、知道什么是NCS2,知道openvino;
3、知道.onnx模型,IR中间模型;
4、有树莓派,且会基本的配置环境;
5、(可选)会使用Google Coaleb。
这篇博客更多的是对大体过程做梳理,并提到一些我遇到的坑。至于里面的细节,我会放些链接补充,当然自己遇到bug时还要自己百度处理。但我能保证整个过程没有问题。
1.我的环境
用来训练yolov5模型的电脑是win10系统,树莓派4B的系统是:2020-06-23-raspbian-buster-full(搭建好基本环境).img【32bit】
其实我yolov5模型的训练(.pt模型)和转换(转换成.onnx模型)都是在Google Colab上进行的。这是一个线上的IDE,帮你配置好了基本的环境,你可以直接用,即使没有第三方库自己安装也很方便,基本一条pip命令就行,不会出现本地配置环境时出现各种奇怪bug,大大节省时间。更NB的是它免费送你一块GPU,你可以直接用来训练模型,速度挺快的。但其实你在本地训练和转换模型也没问题。
2.整个流程
首先展示下整个部署流程,对全局有个把握,然后我再一步步具体说:
整个过程分为四大步:
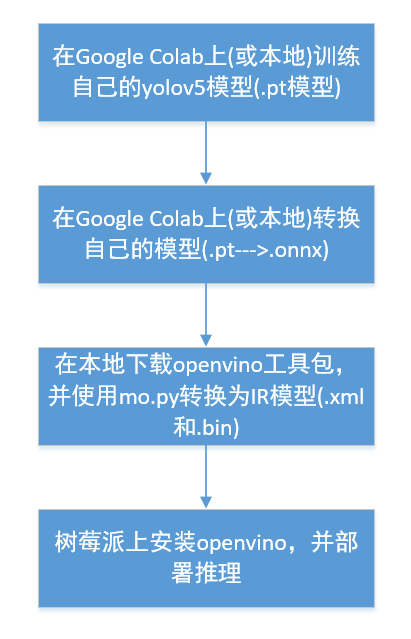

本质来看,其实就是:
(1)训练自己的模型(.pt/.tf_lite/.weights…)
(2)使用openvino转换成IR中间模型
(3)在树莓派上下载openvino,使用IR模型执行推断
即,模型的训练和转换都是在本地进行,树莓派上只使用转换后的IR模型执行推断。
3.具体过程
3.1 训练自己的yolov5模型
这一步的目的是使用自己的数据集训练,得到满足自己实际需求的.pt模型。
网上的教程多又全,可以直接看官方教程:GtiHub yolov5官方,也可以参考下面两篇文档:
colab和win10系统下yolov5的安装及训练自己的训练集
labelImg标注数据集(yolov5篇)
这步较为简单,参考这些文档,遇到小问题在CSDN上都能解决。
3.2 将.pt模型转换为.onnx模型
经过上一步我们已经得到了.pt模型,下面需要使用yolov5文件夹中自带的export.py文件将.pt转换为.onnx模型。(其实最终是要得到IR中间模型,但openvino好像不提供直接将.pt模型转换为IR模型的接口,所以只能先转为.onnx模型,再转换成IR模型)
这里我是参考官方提供的方法:官方方法
其实就是一行代码:
python export.py --weights yolov5s.pt --img 640 --batch 1 # export at 640x640 with batch size 1
把yolov5s.pt换成我们上一步得到的.pt模型即可
NOTE: 我在本地转换的时候环境总是有问题,转换不了.onnx模型,最后还是去Google Colab上转换的。当然本地转换绝对也是可以的,只是我懒得再去配环境了。
执行完就可以在export.py所在的文件夹下看到.onnx模型了。恭喜你已经走了一半了。
3.3 在本地将.onnx转换成IR模型
这里我们需要用到openvino工具包来帮忙转换,我们在本地主机和树莓派上都需要下载。本地主机上下载的比较大,因为需要进行模型转换,而树莓派上下载的很小也很方便,因为只要进行模型的推理即可。openvino也支持树莓派,所以有官方教程,我下载的是最新的openvino 2021.4。
这里还是建议参考官方文档,因为官方文档会有最新的更新,也非常全面:
本地主机(Win10)安装文档
当然CSDN上也有很多安装教程,不过可能不是最新版的。
安装好openvino后,就开始.onnx模型到IR中间模型的转换了:
(1)用管理员打开cmd
(2)cd到mo.py所在的目录:我的是在这儿

cd D:\OpenVino\Intel\openvino_2021.4.582\deployment_tools\model_optimizer
(3)把之前转换得到的.onnx模型放到和mo.py同一文件夹下
(4)开始转换
python mo.py --input_model=<这里是你转化得到的模型>.onnx --output_dir=Myonnx_IR --model_name=<这里是你希望转换出的模型的名字> --scale=255 --data_type=FP16
有几点需要注意:
1、 –input_model:这是你上一步转化得到的.onnx模型
2、–output_dir:转化后得到的IR模型存储的位置
3、–model_name:转化后得到模型的名字
4、–scale:这个参数一定一定要写,不然之后部署在树莓派上会出现在NCS2上推理和CPU上推理结果相差很多的现象。我就是在这里浪费了很多时间。
5、data_type:模型精度,树莓派NCS2支支持FP16,CPU推理支持FP32。
比如我的代码是:
python mo.py --input_model=Myonnx_IR/last.onnx --output_dir=Myonnx_IR --model_name=last.fp16.s255 --scale=255 --data_type=FP16
最终得到的结果为:

OK,到这一步我们已经得到了IR中间模型了:
.xml是我们模型的拓扑结构
.bin是模型的权重和偏置
.mapping应该是存储着一些映射信息(这个我没研究)
恭喜你已经完成了3/4,胜利在望!
3.4 在树莓派4B上使用IR模型推理
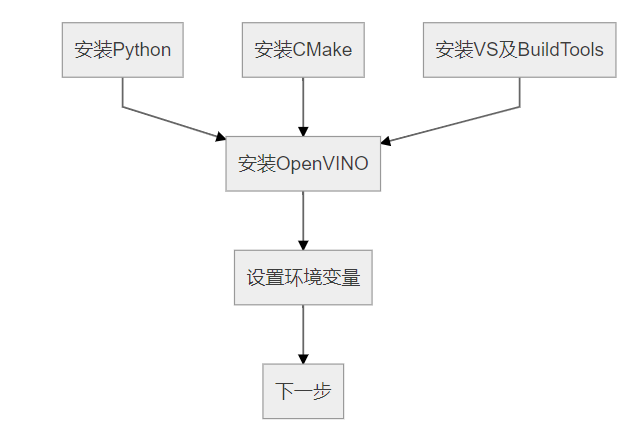
经过上一步我们已经得到了IR中间模型,最后我们就需要在树莓派上使用IR模型推理了,首先我们需要在树莓派上下载openvino和配置NCS2,这里还是强烈建议看官方文档,非常简单,就几行命令。这里我用下别人博客里的图,可以看下win10和树莓派上安装openvino的主要过程。
win10
树莓派
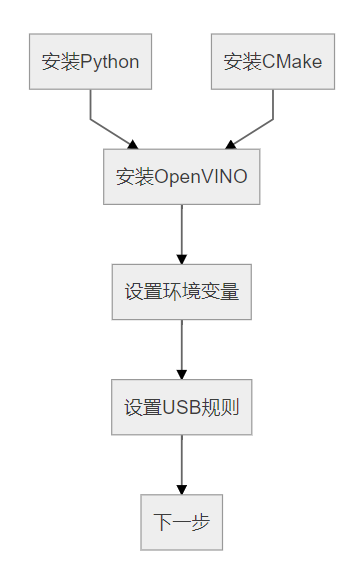
图片来源:https://blog.csdn.net/qq_40822405/article/details/105193050
参考官方文档在树莓派上安装好openvino后,就可以开始推理了,我把我推理的代码放在下面,并加上必要的注释说明:
import torch
import torchvision
from openvino.inference_engine import IECore, IENetwork
import cv2
import numpy as np
import time
import os
# 推断
def Inference(net, exec_net, image_file):
# Read image
img0 = cv2.imread(image_file)
print("img0 Size:", img0.shape)
# Padded resize
img = cv2.resize(img0, (640, 640))
print("img Size:", img.shape)
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
img = torch.from_numpy(img)
img = img.half()
img = img[None]
''' # 模型输入图片,进行推理 n, c, h, w = net.inputs[input_blob].shape frame = cv2.imread(image_file) initial_h, initial_w, channels = frame.shape # 按照AI模型要求放缩图片 image = cv2.resize(frame, (w, h)) image = torch.from_numpy(image) # 下面这两步特别关键!!!!不这么处理推断结果就会出大错!! image = image.half() image = image[None] image = image.transpose(1, 3) image = image.transpose(2, 3) '''
print("image shape is: {}".format(img.shape))
print("Starting inference in synchronous mode")
start = time.time()
res = exec_net.infer(inputs={
input_blob: img})
end = time.time()
print("Infer Time:{}ms".format((end - start) * 1000))
#return torch.from_numpy(res[out_blob]) # res.shape = [1, 25200, 8]
return torch.from_numpy(res['output'])
#return res
def xywh2xyxy(x):
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def non_max_suppression(prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, multi_label=False,
labels=(), max_det=300):
"""Runs Non-Maximum Suppression (NMS) on inference results Returns: list of detections, on (n,6) tensor per image [xyxy, conf, cls] """
nc = prediction.shape[2] - 5 # number of classes
xc = prediction[..., 4] > conf_thres # candidates
# Checks
assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {
conf_thres}, valid values are between 0.0 and 1.0'
assert 0 <= iou_thres <= 1, f'Invalid IoU {
iou_thres}, valid values are between 0.0 and 1.0'
# Settings
min_wh, max_wh = 2, 4096 # (pixels) minimum and maximum box width and height
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
time_limit = 10.0 # seconds to quit after
redundant = True # require redundant detections
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
merge = False # use merge-NMS
t = time.time()
output = [torch.zeros((0, 6), device=prediction.device)] * prediction.shape[0]
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
x = x[xc[xi]] # confidence
print("---x shape---:", x.shape)
# Cat apriori labels if autolabelling
if labels and len(labels[xi]):
l = labels[xi]
v = torch.zeros((len(l), nc + 5), device=x.device)
v[:, :4] = l[:, 1:5] # box
v[:, 4] = 1.0 # conf
v[range(len(l)), l[:, 0].long() + 5] = 1.0 # cls
x = torch.cat((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
# Compute conf
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
box = xywh2xyxy(x[:, :4])
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label:
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).T
x = torch.cat((box[i], x[i, j + 5, None], j[:, None].float()), 1)
else: # best class only
conf, j = x[:, 5:].max(1, keepdim=True)
x = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
# Apply finite constraint
# if not torch.isfinite(x).all():
# x = x[torch.isfinite(x).all(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
elif n > max_nms: # excess boxes
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
if i.shape[0] > max_det: # limit detections
i = i[:max_det]
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
weights = iou * scores[None] # box weights
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
if redundant:
i = i[iou.sum(1) > 1] # require redundancy
output[xi] = x[i]
if (time.time() - t) > time_limit:
print(f'WARNING: NMS time limit {
time_limit}s exceeded')
break # time limit exceeded
return output
if __name__ == "__main__":
DEVICE = 'MYRIAD'
#model_xml = '/home/pi/MyCode/best.fp16.s255.xml'
#model_bin = '/home/pi/MyCode/best.fp16.s255.bin'
model_xml = '/home/pi/MyCode/MyModel/9.10best.fp16.s255.xml'
model_bin = '/home/pi/MyCode/MyModel/9.10best.fp16.s255.bin'
#model_xml = '/home/pi/newYolov5/yolov5s.xml'
#model_bin = '/home/pi/newYolov5/yolov5s.bin'
image_file = '/home/pi/MyCode/testdata'
confidence = 0.6
num_classes = 4
conf_thres, iou_thres = 0.25, 0.45
classes = None
agnostic_nms = False
max_det = 300
# 初始化设备
ie = IECore()
# 读取IR模型
net = ie.read_network(model=model_xml, weights=model_bin)
# 转换输入输出张量
print("Preparing input blobs")
input_blob = next(iter(net.inputs))
out_blob = next(iter(net.outputs))
# 载入模型到CPU
print("Loading IR to the plugin...")
exec_net = ie.load_network(network=net, num_requests=1, device_name=DEVICE)
# 推断
print("Start Inference!")
pic_list = os.listdir(image_file)
for pic in pic_list:
prediction = Inference(net, exec_net, image_file+'/'+pic)
print("****prediction's shape is:******", prediction.shape)
# print(prediction)
ans = non_max_suppression(prediction, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
cls_id = ans[0][:,-1].unique()
print(pic, "\n", cls_id)
''' with open('9.10ModelTest.txt', 'a') as f: if(cls_id.shape[0]==0): f.write(pic+": None" + '\n') else: f.write(pic+": "+str(int(cls_id[0])) + '\n') '''
最终NCS2推理得到的结果和在电脑上用CPU推理得到的结果相同,部署完成。
如果觉得有些部署的地方没看懂,可以参考这篇博客:
Openvino 模型文件部署推理
具体的过程和我类似,因为他的输出处理比较简单,所以具体过程很清楚。
4. 一些坑
4.1 树莓派4B上安装pytorch
建议用>=1.7的版本,我之前安装一直失败,没法直接pip安装,应该是官网上没有对应环境的编译好的文件。这里放个GitHub上别人编译好的可以在树莓派32位系统上直接安装的Pytorch(1.8.0)和torchvision(0.9.1)
torch1.8.0+torchvision0.9.0
4.2 安装好了pytorch没法用
安装好pytorch之后import发现没法用,这可能是因为没有安装依赖:
sudo apt-get install libopenblas-dev
4.3 模型转换失败
可能会出现.pt模型转换.onnx模型失败,或者.onnx模型转换IR中间模型失败。失败的话建议使用Google Colab线上IDE,不用自己配置环境,可能会少踩不少坑。
4.4 转换好的模型推测出的结果和原模型相差较大
这是我踩的比较大的一个坑,出现这个问题可能是因为在使用mo.py转换模型时没有加–scale的选项,但更有可能的情况是输入数据的预处理出了问题。比如:yolov5要输入的形式是NCHW的数据,是否处理对了?模型转换时需要用设置–scale 255,此时输入模型的图片不需要再除以255了,等等等等。
这是我的一个感觉,不一定对:如果模型能够成功推理出结果,说明模型转换应该没出问题,若是NCS2推理得到的结果与CPU推理得到相差较大,可以看看预处理是否正确。
5. 总结
下面说的是自己的感受,方便以后自己多看看提醒下自己。
整个过程花了大概一个月,还是挺长的。但真的学到不少东西,更多的是处理问题的思路:
(1)有官方文档,尽量看官方文档。因为别的博主写的文档可能是好几年前的,不是最新版本的。或者环境和你的不一样。
(2)学会看源码,很多问题静下来看源码就能解决。
(3)不要着急!没有一劳永逸的解决方案,成功需要多尝试。当整个工程较复杂时,不要想着跟着一个博客做就能把自己的环境也完全搭好,那是不可能的。具体问题需要具体分析。
(4)透过现象看本质。这是我感触最深的一点,时刻记住自己的根本目的。比如你的目的是“构建一个目标识别模型”还是“通过yolov5构建一个目标识别模型”,很明显会是前者。所以如果一条路走不通(yolov5没法满足要求),就换条路走,不要钻牛角尖,要时刻提醒自己根本目的是什么。
OK,祝你成功 :)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140008.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
