大家好,又见面了,我是你们的朋友全栈君。
其它机器学习、深度学习算法的全面系统讲解可以阅读《机器学习-原理、算法与应用》,清华大学出版社,雷明著,由SIGAI公众号作者倾力打造。
机器学习是现阶段解决很多人工智能问题的主流方法,作为一个独立的方向,正处于高速发展之中。最早的机器学习算法可以追溯到20世纪初,到今天为止,已经过去了100多年。从1980年机器学习称为一个独立的方向开始算起,到现在也已经过去了近40年。在这100多年中,经过一代又一代人的努力,诞生出了大量经典的方法,在本文中,SIGAI将分有监督学习,无监督学习,概率图模型,深度学习,强化学习4个大方向对历史上出现的经典算法进行整理与总结,帮助大家理清机器学习这100多年来的发展历史,完成对机器学习的寻根问祖之旅。限于篇幅,我们无法对所有算法一一列举,只介绍有代表性的一部分。
算法的分类
总体上,机器学习算法可以分为有监督学习,无监督学习,强化学习3种类型。半监督学习可以认为是有监督学习与无监督学习的结合,不在本文讨论的范围之类。
有监督学习通过训练样本学习得到一个模型,然后用这个模型进行推理。例如,我们如果要识别各种水果的图像,则需要用人工标注(即标好了每张图像所属的类别,如苹果,梨,香蕉)的样本进行训练,得到一个模型,接下来,就可以用这个模型对未知类型的水果进行判断,这称为预测。如果只是预测一个类别值,则称为分类问题;如果要预测出一个实数,则称为回归问题,如根据一个人的学历、工作年限、所在城市、行业等特征来预测这个人的收入。
无监督学习则没有训练过程,给定一些样本数据,让机器学习算法直接对这些数据进行分析,得到数据的某些知识。其典型代表是聚类,例如,我们抓取了1万个网页,要完成对这些网页的归类,在这里,我们并没有事先定义好的类别,也没有已经训练好的分类模型。聚类算法要自己完成对这1万个网页的归类,保证同一类网页是同一个主题的,不同类型的网页是不一样的。无监督学习的另外一类典型算法是数据降维,它将一个高维向量变换到低维空间中,并且要保持数据的一些内在信息和结构。
强化学习是一类特殊的机器学习算法,算法要根据当前的环境状态确定一个动作来执行,然后进入下一个状态,如此反复,目标是让得到的收益最大化。如围棋游戏就是典型的强化学习问题,在每个时刻,要根据当前的棋局决定在什么地方落棋,然后进行下一个状态,反复的放置棋子,直到赢得或者输掉比赛。这里的目标是尽可能的赢得比赛,以获得最大化的奖励。
总结来说,这些机器学习算法要完成的任务是:
分类算法-是什么?即根据一个样本预测出它所属的类别。
回归算法-是多少?即根据一个样本预测出一个数量值。
聚类算法-怎么分?保证同一个类的样本相似,不同类的样本之间尽量不同。
强化学习-怎么做?即根据当前的状态决定执行什么动作,最后得到最大的回报。
有监督学习
我们首先来看有监督学习,这是机器学习算法中最庞大的一个家族。下图列出了经典的有监督学习算法(深度学习不在此列):

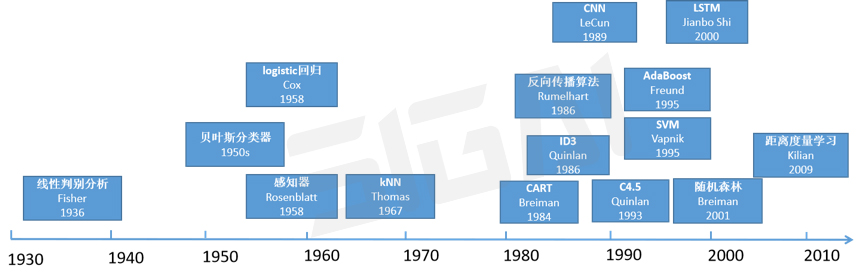
线性判别分析(LDA)[1]是Fisher发明的,其历史可以追溯到1936年,那时候还没有机器学习的概念。这是一种有监督的数据降维算法,它通过线性变换将向量投影到低维空间中,保证投影后同一种类型的样本差异很小,不同类的样本尽量不同。
贝叶斯分类器起步于1950年代,基于贝叶斯决策理论,它把样本分到后验概率最大的那个类。
logistic回归[2]的历史同样悠久,可以追溯到1958年。它直接预测出一个样本属于正样本的概率,在广告点击率预估、疾病诊断等问题上得到了应用。
感知器模型[3]是一种线性分类器,可看作是人工神经网络的前身,诞生于1958年,但它过于简单,甚至不能解决异或问题,因此不具有实用价值,更多的起到了思想启蒙的作用,为后面的算法奠定了思想上的基础。
kNN算法[7]诞生于1967年,这是一种基于模板匹配思想的算法,虽然简单,但很有效,至今仍在被使用。
在1980年之前,这些机器学习算法都是零碎化的,不成体系。但它们对整个机器学习的发展所起的作用不能被忽略。
从1980年开始,机器学习才真正成为一个独立的方向。在这之后,各种机器学习算法被大量的提出,得到了快速发展。
决策树的3种典型实现:ID3[4],CART[5],C4.5[6]是1980年代到1990年代初期的重要成果,虽然简单,但可解释性强,这使得决策树至今在一些问题上仍被使用。
1986年诞生了用于训练多层神经网络的真正意义上的反向传播算法[11],这是现在的深度学习中仍然被使用的训练算法,奠定了神经网络走向完善和应用的基础。
1989年,LeCun设计出了第一个真正意义上的卷积神经网络[13],用于手写数字的识别,这是现在被广泛使用的深度卷积神经网络的鼻祖。
在1986到1993年之间,神经网络的理论得到了极大的丰富和完善,但当时的很多因素限制了它的大规模使用。
1990年代是机器学习百花齐放的年代。在1995年诞生了两种经典的算法-SVM[9]和AdaBoost[12],此后它们纵横江湖数十载,神经网络则黯然失色。SVM代表了核技术的胜利,这是一种思想,通过隐式的将输入向量映射到高维空间中,使得原本非线性的问题能得到很好的处理。而AdaBoost则代表了集成学习算法的胜利,通过将一些简单的弱分类器集成起来使用,居然能够达到惊人的精度。
现在大红大紫的LSTM[51]在2000年就出现了,这让很多同学会感到惊讶。当在很长一段时间内一直默默无闻,直到2013年后与深度循环神经网络整合,在语音识别上取得成功。
随机森林[10]出现于2001年,于AdaBoost算法同属集成学习,虽然简单,但在很多问题上效果却出奇的好,因此现在还在被大规模使用。
2009年距离度量学习的一篇经典之作[8]算是经典机器学习算法中年轻的小兄弟,在后来,这种通过机器学习得到距离函数的想法被广泛的研究,出现了不少的论文。
从1980年开始到2012年深度学习兴起之前,有监督学习得到了快速的发展,这有些类似于春秋战国时代,各种思想和方法层出不穷,相继登场。另外,没有一种机器学习算法在大量的问题上取得压倒性的优势,这和现在的深度学习时代很不一样。
无监督学习
相比于有监督学习,无监督学习的发展一直和缓慢,至今仍未取得大的突破。下面我们按照聚类和数据降维两类问题对这些无监督学习算法进行介绍。
聚类
聚类算法的历史与有监督学习一样悠久。层次聚类算法出现于1963年[26],这是非常符合人的直观思维的算法,现在还在使用。它的一些实现方式,包括SLINK[27],CLINK[28]则诞生于1970年代。

k均值算法[25]可谓所有聚类算法中知名度最高的,其历史可以追溯到1967年,此后出现了大量的改进算法,也有大量成功的应用,是所有聚类算法中变种和改进型最多的。
大名鼎鼎的EM算法[29]诞生于1977年,它不光被用于聚类问题,还被用于求解机器学习中带有缺数数据的各种极大似然估计问题。
Mean Shift算法[32]早在1995年就被用于聚类问题,和DBSCAN算法[30],OPTICS算法[31]一样,同属于基于密度的聚类算法。
谱聚类算法[33]是聚类算法家族中年轻的小伙伴,诞生于2000年左右,它将聚类问题转化为图切割问题,这一思想提出之后,出现了大量的改进算法。
数据降维
下面来说数据降维算法。经典的PCA算法[14]诞生于1901年,这比第一台真正的计算机的诞生早了40多年。LDA在有监督学习中已经介绍,在这里不再重复。
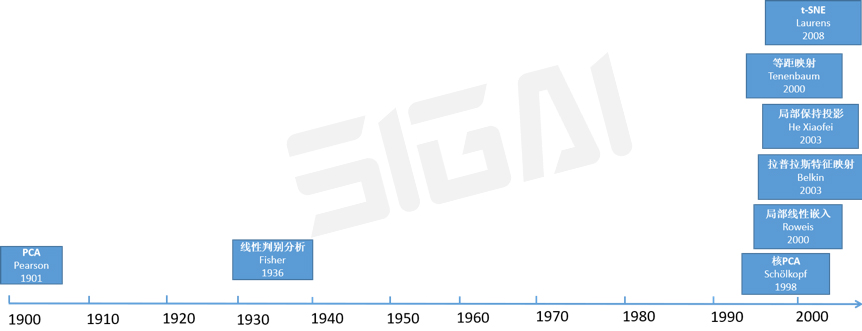
此后的近100年里,数据降维在机器学习领域没有出现太多重量级的成果。直到1998年,核PCA[15]作为非线性降维算法的出现。这是核技术的又一次登台,与PCA的结合将PCA改造成了非线性的降维算法。
从2000年开始,机器学习领域刮起了一阵流形学习的旋风,这种非线性方法是当时机器学习中炙手可热的方向,这股浪潮起始于局部线性嵌入LLL[16]。此后,拉普拉斯特征映射,局部保持投影,等距映射等算法相继提出[17-19]。流形学习在数学上非常优美,但遗憾的是没有多少公开报道的成功的应用。
t-SNE是降维算法中年轻的成员,诞生于2008年,虽然想法很简单,效果却非常好。
概率图模型
概率图模型是机器学习算法中独特的一个分支,它是图与概率论的完美结合。在这种模型中,每个节点表示随机变量,边则表示概率。因为晦涩难以理解,让很多同学谈虎色变,但如果你悟透了这类方法的本质,其实并不难。
赫赫有名的隐马尔可夫模型[21]诞生于1960年,在1980年代,它在语音识别中取得了成功,一时名声大噪,后来被广泛用于各种序列数据分析问题,在循环神经网络大规模应用之前,处于主导地位。

马尔可夫随机场诞生于1974年[23],也是一种经典的概率图模型算法。贝叶斯网络[22]是概率推理的强大工具,诞生于1985年,其发明者是概率论图模型中的重量级人物,后来获得了图灵奖。条件随机场[24]是概率图模型中相对年轻的成员,被成功用于中文分词等自然语言处理,还有其他领域的问题,也是序列标注问题的有力建模工具。
深度学习
虽然真正意义上的人工神经网络诞生于1980年代,反向传播算法也早就被提出,卷积神经网络、LSTM等早就别提出,但遗憾的是神经网络在过去很长一段时间内并没有得到大规模的成功应用,在于SVM等机器学习算法的较量中处于下风。原因主要有:算法本身的问题,如梯度消失问题,导致深层网络难以训练。训练样本数的限制。计算能力的限制。直到2006年,情况才慢慢改观。
对神经网络改进一直在进行着,在深度学习的早期,自动编码器和受限玻尔兹曼机被广泛的研究,典型的改进和实现就有去噪自动编码器[34],收缩自动编码器[36],变分自动编码器[35],DBN[37],DBM[38]等轮流出场,虽然热闹,但还是没有真正得到成功应用。
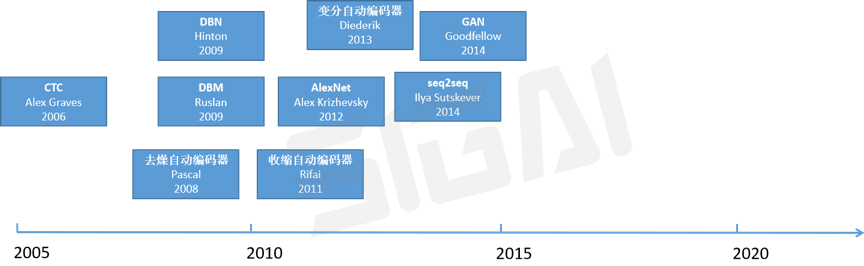
后来在语音识别中大显身手的CTC(连接主义时序分类)[39]早在2006年就被提出,然而生不逢时,在后面一直默默无闻。情况真正被改变发生在2012年,Alex网络的成功[41]使得深度神经网络卷土重来。在这之后,卷积神经网络被广泛的应用于机器视觉的各类问题。循环神经网络则被用于语音识别、自然语言处理等序列预测问题。整合了循环神经网络和编码器-解码器框架的seq2seq技术[40],巧妙了解决了大量的实际应用问题。而GAN[42]作为深度生成模型的典型代表,可以生成逼真的图像,得到了不可思议的效果,是现在深度学习中热门的研究方向。
历史选择了神经网络并非偶然,它有万能逼近定理作为保障,可以拟合闭区间上任意一个连续函数。另外,我们可以人为控制网络的规模,用来拟合非常复杂的函数,这是其他机器学习算法不具备的。深度学习的出现,让图像、语音等感知类问题取得了真正意义上的突破,离实际应用已如此之近。
强化学习
相比有监督学习和无监督学习,强化学习在机器学习领域的起步更晚。虽然早在1980年代就出现了时序差分算法[42-44],但对于很多实际问题,我们无法用表格的形式列举出所有的状态和动作,因此这些抽象的算法无法大规模实用。
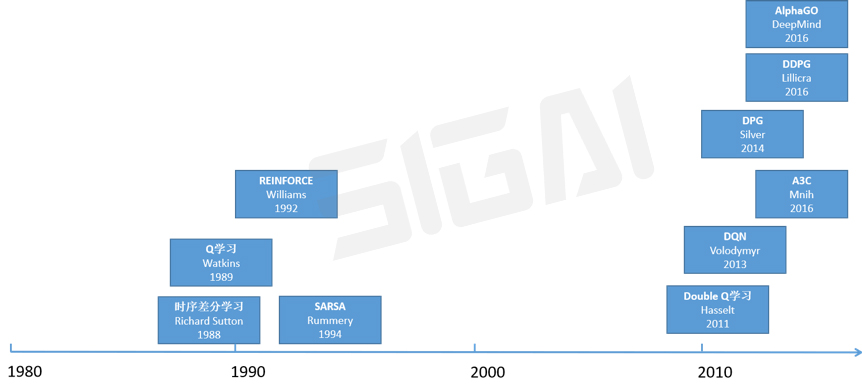
神经网络与强化学习的结合,即深度强化学习46-50],才为强化学习带来了真正的机会。在这里,深度神经网络被用于拟合动作价值函数即Q函数,或者直接拟合策略函数,这使得我们可以处理各种复杂的状态和环境,在围棋、游戏、机器人控制等问题上真正得到应用。神经网络可以直接根据游戏画面,自动驾驶汽车的摄像机传来的图像,当前的围棋棋局,预测出需要执行的动作。其典型的代表是DQN[46]这样的用深度神经网络拟合动作价值函数的算法,以及直接优化策略函数的算法[47-50]。
参考文献
[1] Fisher, R. A. (1936). The Use of Multiple Measurements in Taxonomic Problems. Annals of Eugenics. 7 (2): 179–188.
[2] Cox, DR (1958). The regression analysis of binary sequences (with discussion). J Roy Stat Soc B. 20 (2): 215–242.
[3] Rosenblatt, F. (1958). “The Perceptron: A Probalistic Model For Information Storage And Organization In The Brain”. Psychological Review. 65 (6): 386–408.
[4] Quinlan, J. R. 1986. Induction of Decision Trees. Mach. Learn. 1, 1 (Mar. 1986), 81–106
[5] Breiman, L., Friedman, J. Olshen, R. and Stone C. Classification and Regression Trees, Wadsworth, 1984.
[6] Quinlan, J. R. C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers, 1993.
[7] Thomas M Cover, Peter E Hart. Nearest neighbor pattern classification. IEEE Transactions on Information Theory, 1967.
[8] Kilian Q Weinberger, Lawrence K Saul. Distance Metric Learning for Large Margin Nearest Neighbor Classification. 2009, Journal of Machine Learning Research.
[9] Cortes, C. and Vapnik, V. Support vector networks. Machine Learning, 20, 273-297, 1995
[10] Breiman, Leo. Random Forests. Machine Learning 45 (1), 5-32, 2001.
[11] David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. Learning internal representations by back-propagating errors. Nature, 323(99): 533-536, 1986.
[12] Freund, Y. Boosting a weak learning algorithm by majority. Information and Computation, 1995.
[13] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, L. D. Jackel, Backpropagation Applied to Handwritten Zip Code Recognition. 1989.
[14] Pearson, K. (1901). On Lines and Planes of Closest Fit to Systems of Points in Space. Philosophical Magazine. 2 (11): 559–572.
[15] Schölkopf, Bernhard (1998). “Nonlinear Component Analysis as a Kernel Eigenvalue Problem”. Neural Computation. 10: 1299–1319.
[16] Roweis, Sam T and Saul, Lawrence K. Nonlinear dimensionality reduction by locally linear embedding. Science, 290(5500). 2000: 2323-2326.
[17] Belkin, Mikhail and Niyogi, Partha. Laplacian eigenmaps for dimensionality reduction and data representation. Neural computation. 15(6). 2003:1373-1396.
[18] He Xiaofei and Niyogi, Partha. Locality preserving projections. NIPS. 2003:234-241.
[19] Tenenbaum, Joshua B and De Silva, Vin and Langford, John C. A global geometric framework for nonlinear dimensionality reduction. Science, 290(5500). 2000: 2319-2323.
[20] Laurens Van Der Maaten, Geoffrey E Hinton. Visualizing Data using t-SNE. 2008, Journal of Machine Learning Research.
[21] Stratonovich, R.L. (1960). “Conditional Markov Processes”. Theory of Probability and its Applications. 5 (2): 156–178.
[22] Pearl J (1985). Bayesian Networks: A Model of Self-Activated Memory for Evidential Reasoning (UCLA Technical Report CSD-850017). Proceedings of the 7th Conference of the Cognitive Science Society, University of California, Irvine, CA. pp. 329–334. Retrieved 2009-05-01.
[23] Moussouris, John (1974). “Gibbs and Markov random systems with constraints”. Journal of Statistical Physics. 10 (1): 11–33.
[24] Lafferty, J., McCallum, A., Pereira, F. (2001). “Conditional random fields: Probabilistic models for segmenting and labeling sequence data”. Proc. 18th International Conf. on Machine Learning. Morgan Kaufmann. pp. 282–289.
[25] MacQueen, J. B. (1967). Some Methods for classification and Analysis of Multivariate Observations. Proceedings of 5th Berkeley Symposium on Mathematical Statistics and Probability. 1. University of California Press. pp. 281–297. MR 0214227. Zbl 0214.46201. Retrieved 2009-04-07.
[26] Ward, Joe H. (1963). “Hierarchical Grouping to Optimize an Objective Function”. Journal of the American Statistical Association. 58 (301): 236–244. doi:10.2307/2282967. JSTOR 2282967. MR 0148188.
[27] R. Sibson (1973). “SLINK: an optimally efficient algorithm for the single-link cluster method” (PDF). The Computer Journal. British Computer Society. 16 (1): 30–34. doi:10.1093/comjnl/16.1.30.
[28] D. Defays (1977). “An efficient algorithm for a complete-link method”. The Computer Journal. British Computer Society. 20 (4): 364–366. doi:10.1093/comjnl/20.4.364.
[29] Dempster, A.P.; Laird, N.M.; Rubin, D.B. (1977). “Maximum Likelihood from Incomplete Data via the EM Algorithm”. Journal of the Royal Statistical Society, Series B. 39 (1): 1–38. JSTOR 2984875. MR 0501537.
[30] Ester, Martin; Kriegel, Hans-Peter; Sander, Jörg; Xu, Xiaowei (1996). Simoudis, Evangelos; Han, Jiawei; Fayyad, Usama M., eds. A density-based algorithm for discovering clusters in large spatial databases with noise. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96). AAAI Press. pp. 226–231.
[31] Mihael Ankerst, Markus M. Breunig, Hans-Peter Kriegel, Jörg Sander (1999). OPTICS: Ordering Points To Identify the Clustering Structure. ACM SIGMOD international conference on Management of data. ACM Press. pp. 49–60.
[32] Yizong Cheng. Mean Shift, Mode Seeking, and Clustering. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1995.
[33] Jianbo Shi and Jitendra Malik, “Normalized Cuts and Image Segmentation”, IEEE Transactions on PAMI, Vol. 22, No. 8, Aug 2000.
[34] Pascal Vincent, Hugo Larochelle, Yoshua Bengio, Pierreantoine Manzagol. Extracting and composing robust features with denoising auto encoders. international conference on machine learning, 2008.
[35] Diederik P Kingma; Welling, Max (2013). “Auto-Encoding Variational Bayes”. arXiv:1312.6114
[36] Salah Rifai, Pascal Vincent, Xavier Muller, Xavier Glorot, Yoshua Bengio. Contractive Auto-Encoders: Explicit Invariance During Feature Extraction. international conference on machine learning, 2011.
[37]Ruslan Salakhutdinov, Geoffrey E Hinton. Deep Boltzmann Machines. international conference on artificial intelligence and statistics, 2009.
[38]Hinton G (2009). “Deep belief networks”. Scholarpedia. 4 (5): 5947.
[39]Alex Graves, Santiago Fernandez, Faustino J Gomez, Jurgen Schmidhuber. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks.international conference on machine learning. 2006.
[40]Ilya Sutskever, Oriol Vinyals, Quoc V Le. Sequence to Sequence Learning with Neural Networks. neural information processing systems. 2014.
[41]Alex Krizhevsky, Ilya Sutskever, Geoffrey E.Hinton. ImageNet Classification with Deep Convolutional Neural Networks. 2012.
[42]Goodfellow Ian, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets. Advances in Neural Information Processing Systems, 2672-2680, 2014.
[42]Richard Sutton (1988). “Learning to predict by the methods of temporal differences”. Machine Learning. 3 (1): 9–44.
[43]Watkins, C.J.C.H. (1989), Learning from Delayed Rewards (PDF) (Ph.D. thesis), Cambridge University.
[44]Online Q-Learning using Connectionist Systems” by Rummery & Niranjan (1994)
[45]van Hasselt, Hado (2011). “Double Q-learning” (PDF). Advances in Neural Information Processing Systems. 23: 2613–2622.
[46]Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou. Playing Atari with Deep Reinforcement Learning. NIPS 2013.
[47]Mnih, V., Badia, A. P., Mirza, M., Graves, A., Harley, T., Lillicrap, T. P., Silver, D., and Kavukcuoglu, K. (2016). Asynchronous methods for deep reinforcement learning. In the International Conference on Machine Learning (ICML).
[48]Williams, R. J. (1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 8(3):229–256.
[49]Silver, D., Lever, G., Heess, N., Degris, T., Wierstra, D., and Riedmiller, M. (2014). Deterministic
policy gradient algorithms. In the International Conference on Machine Learning (ICML).
[50]Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., and Wierstra, D.
(2016). Continuous control with deep reinforcement learning. In the International Conference on
Learning Representations (ICLR).
[51]S. Hochreiter, J. Schmidhuber. Long short-term memory. Neural computation, 9(8): 1735-1780, 1997.
[52] David Silver, et al. Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature, 2016.
推荐阅读
[1]机器学习-波澜壮阔40年【获取码】SIGAI0413.
[2]学好机器学习需要哪些数学知识?【获取码】SIGAI0417.
[3] 人脸识别算法演化史【获取码】SIGAI0420.
[4]基于深度学习的目标检测算法综述 【获取码】SIGAI0424.
[5]卷积神经网络为什么能够称霸计算机视觉领域?【获取码】SIGAI0426.
[6] 用一张图理解SVM的脉络【获取码】SIGAI0428.
[7] 人脸检测算法综述【获取码】SIGAI0503.
[8] 理解神经网络的激活函数 【获取码】SIGAI2018.5.5.
[9] 深度卷积神经网络演化历史及结构改进脉络-40页长文全面解读【获取码】SIGAI0508.
[10] 理解梯度下降法【获取码】SIGAI0511.
[11] 循环神经网络综述—语音识别与自然语言处理的利器【获取码】SIGAI0515
[12] 理解凸优化 【获取码】 SIGAI0518
[13] 【实验】理解SVM的核函数和参数 【获取码】SIGAI0522
[14]【SIGAI综述】行人检测算法 【获取码】SIGAI0525
[15] 机器学习在自动驾驶中的应用—以百度阿波罗平台为例(上)【获取码】SIGAI0529
[16]理解牛顿法【获取码】SIGAI0531
[17] 【群话题精华】5月集锦—机器学习和深度学习中一些值得思考的问题【获取码】SIGAI 0601
[18] 大话Adaboost算法 【获取码】SIGAI0602
[19] FlowNet到FlowNet2.0:基于卷积神经网络的光流预测算法【获取码】SIGAI0604
[20] 理解主成分分析(PCA)【获取码】SIGAI0606
[21] 人体骨骼关键点检测综述 【获取码】SIGAI0608
[22]理解决策树 【获取码】SIGAI0611
[23] 用一句话总结常用的机器学习算法【获取码】SIGAI0611
[24] 目标检测算法之YOLO 【获取码】SIGAI0615
[25] 理解过拟合 【获取码】SIGAI0618
[26]理解计算:从√2到AlphaGo ——第1季 从√2谈起 【获取码】SIGAI0620
[27] 场景文本检测——CTPN算法介绍 【获取码】SIGAI0622
[28] 卷积神经网络的压缩和加速 【获取码】SIGAI0625
[29] k近邻算法 【获取码】SIGAI0627
[30]自然场景文本检测识别技术综述 【获取码】SIGAI0627
[31] 理解计算:从√2到AlphaGo ——第2季 神经计算的历史背景 【获取码】SIGAI0704
[32] 机器学习算法地图【获取码】SIGAI0706
[33] 反向传播算法推导-全连接神经网络【获取码】SIGAI0709
[34] 生成式对抗网络模型综述【获取码】SIGAI0709.
[35]怎样成为一名优秀的算法工程师【获取码】SIGAI0711.
[36] 理解计算:从根号2到AlphaGo——第三季 神经网络的数学模型【获取码】SIGAI0716
[37]【技术短文】人脸检测算法之S3FD 【获取码】SIGAI0716
[38] 基于深度负相关学习的人群计数方法【获取码】SIGAI0718
[39] 流形学习概述【获取码】SIGAI0723
[40] 关于感受野的总结 【获取码】SIGAI0723
[41] 随机森林概述 【获取码】SIGAI0725
[42] 基于内容的图像检索技术综述——传统经典方法【获取码】SIGAI0727
[43] 神经网络的激活函数总结【获取码】SIGAI0730
[44] 机器学习和深度学习中值得弄清楚的一些问题【获取码】SIGAI0802
[45] 基于深度神经网络的自动问答系统概述【获取码】SIGAI0803
[46] 反向传播算法推导——卷积神经网络 【获取码】SIGAI0806
[47] 机器学习与深度学习核心知识点总结 写在校园招聘即将开始时 【获取 码】SIGAI0808
[48] 理解Spatial Transformer Networks【获取码】SIGAI0810
[49]AI时代大点兵-国内外知名AI公司2018年最新盘点【获取码】SIGAI0813
[50] 理解计算:从√2到AlphaGo ——第2季 神经计算的历史背景 【获取码】SIGAI0815
[51] 基于内容的图像检索技术综述–CNN方法 【获取码】SIGAI0817
[52]文本表示简介 【获取码】SIGAI0820
[53]机器学习中的最优化算法总结【获取码】SIGAI0822
[54]【AI就业面面观】如何选择适合自己的舞台?【获取码】SIGAI0823
[55]浓缩就是精华-SIGAI机器学习蓝宝书【获取码】SIGAI0824
[56]DenseNet详解【获取码】SIGAI0827
[57]AI时代大点兵国内外知名AI公司2018年最新盘点【完整版】【获取码】SIGAI0829
[58]理解Adaboost算法【获取码】SIGAI0831
[59]深入浅出聚类算法 【获取码】SIGAI0903
原创声明:本文为 SIGAI 原创文章,仅供个人学习使用,未经允许,不能用于商业目的
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/139912.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
