大家好,又见面了,我是你们的朋友全栈君。
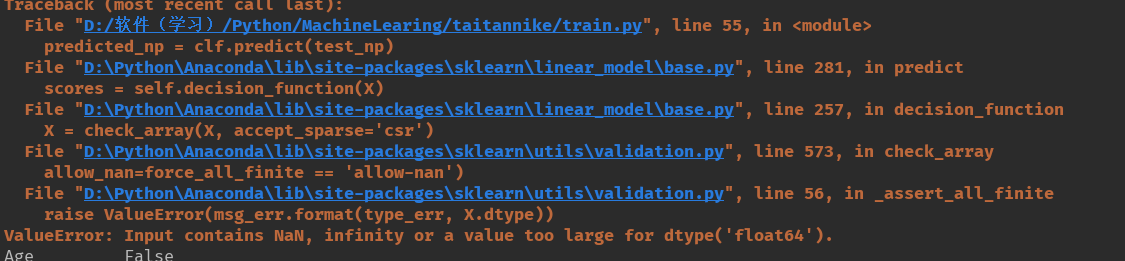
笔者在使用LogisticRegression模型进行预测时,报错
Traceback (most recent call last):
File “D:/软件(学习)/Python/MachineLearing/taitannike/train.py”, line 55, in
predicted_np = clf.predict(test_np)
File “D:\Python\Anaconda\lib\site-packages\sklearn\linear_model\base.py”, line 281, in predict
scores = self.decision_function(X)
File “D:\Python\Anaconda\lib\site-packages\sklearn\linear_model\base.py”, line 257, in decision_function
X = check_array(X, accept_sparse=‘csr’)
File “D:\Python\Anaconda\lib\site-packages\sklearn\utils\validation.py”, line 573, in check_array
allow_nan=force_all_finite == ‘allow-nan’)
File “D:\Python\Anaconda\lib\site-packages\sklearn\utils\validation.py”, line 56, in _assert_all_finite
raise ValueError(msg_err.format(type_err, X.dtype))
ValueError: Input contains NaN, infinity or a value too large for dtype(‘float64’).
Age False

问题:pandas在处理数据时出现以下错误
ValueError: Input contains NaN, infinity or a value too large for dtype(‘float64’).
解决方法:
1、检查数据中是否有缺失值
例如,读取得到的原始数据如下
读取数据
data_test = pd.read_csv('test.csv')
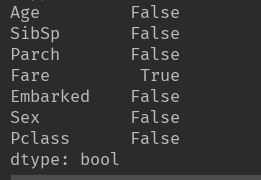
检查数据中是否有缺失值
print(np.isnan(data_test).any())
Flase:表示对应特征的特征值中无缺失值
True:表示有缺失值
2、删除有缺失值的行
train.dropna(inplace=True)
然后再看数据中是否有缺失值
也可以根据需要对缺失值进行填充处理:
train.fillna(‘100’)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/139747.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
