大家好,又见面了,我是你们的朋友全栈君。
数据库——MySQL读写分离后的延迟解决方案
背景:
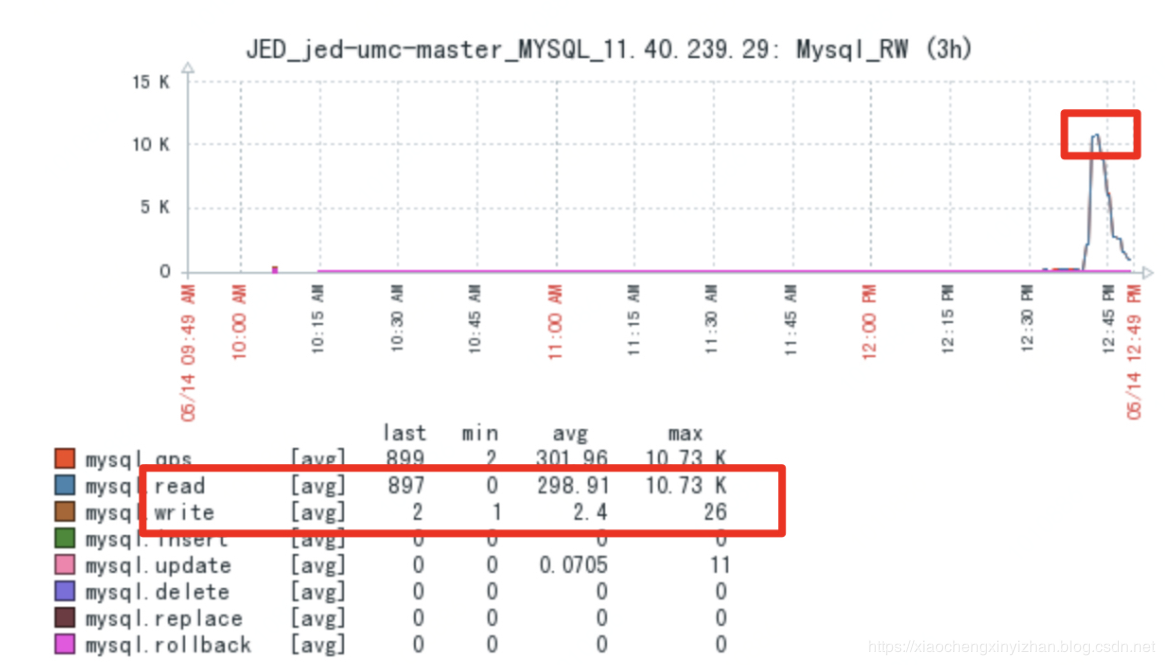

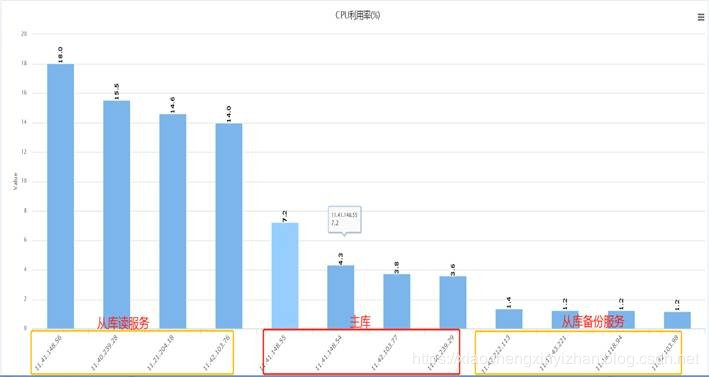
根据上图可以看到QPS:10.73k,实际上真实的并发大量数据到达的时候,我这里最高的QPS是将近15k.而目前单个数据库分片(实例)4CPU8G内存的配置下,最高的性能是7k的QPS。
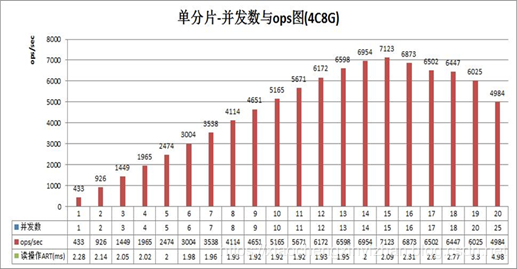
基于上篇我进行了分库分表是对于性能有很大的提高,分库分表实践和中间件的引申
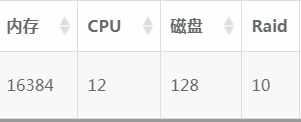
我这里讲解的例子是目前4主8从库(12个实例),以下每个实例都会称为分片。单个分片配置mysql版本5.7.19(一会说明不同版本是读写分离的不同策略),12CPU16G内存,128G的磁盘,Raid:10。
读写分离实践
读写分离可以参考上篇文章的分库分表实践中的中间件的用法来实现。主流一般会使用mycat,但是每个中间件都有自己的优点可以择优和业务特点而用。接下来讲读写分离后的后遗症。
读写分离的延迟和实时insert/update和查询操作
比如我这里的一个场景:由于数据量大,以人维度的情况下,商品量20w~50w。然后需要分页查询未同步下游状态,进行数据同步后再更新该分页数据。我当时设定了如下的四种场景,最后选择了读写分离和不分离同时存在,针对于实时要求结果高的依然是master主库读写,变动需求量小的数据,全部转移slave从库。
如下是四种场景的方案:
1、 完全分离:全量读->从库,全量读写->主库
前提:第一页查询逻辑不变
特点:半同步复制,目前是1主2从库,利用半同步复制原理,1/2的可能性会重复查询,当然这个几率需要和延时性进行测试计算可得,也就是最坏的结果可能性是重复查询50%的可能性。目前反馈主从同步延时1s
方案:
(1)冗余性:去重校验,对于50%的可能性查询出的重复数据。
(2)性能:重复数据和校验会使性能有所降低,但是从库是2个分摊QPS的压力,会使性能有所提高,相互抵消一部分。
2、 不完全分离:商品读写模块依然master主库,其他地方读->从库,写->主库。
前提:第一页查询逻辑不变
特点:由于联合营销系统场景单一,主要是围绕SKU进行。但是会改善一部分压力。
方案:
(1) 冗余性:代码冗余地方多,风格不统一。
(2) 性能:会有部分改善,但是从整体看,数据量大的时候,依然是master主库读写压力大。
3、 完全分离:全量读->从库,全量读写->主库。
前提:分页查询(不加同步状态)
特点:分页查询随着页数和数据量大的情况呈正相关也会时间越来越大。
方案:
(1) 冗余性: 会重复查询,由于分页和性能成正相关,数据量越大,耗时越大。
(2) 分页查询解决性能损耗来减少性能响应时间的方案
(2.1)可以采用延时关联策略(弹性数据库不支持)
(2.2)采用id序列(利用数据库id索引过滤)和limit组合使用(效果不大)。
4、 完全分离:全量读->从库,全量读写->主库
前提:分页查询(加同步状态),最后一次结果集退出的时候进行兜底全量count查询并重新执行上述逻辑。
特点:分页查询随着页数和数据量大的情况呈正相关也会时间越来越大。
方案:与上诉3的方案相同。但避免了查询出重复数据。
读写分离和非分离同时存在,改造后的效果图(我这里的数据量2亿):
读写分离之前master主库CPU使用率95%~99%
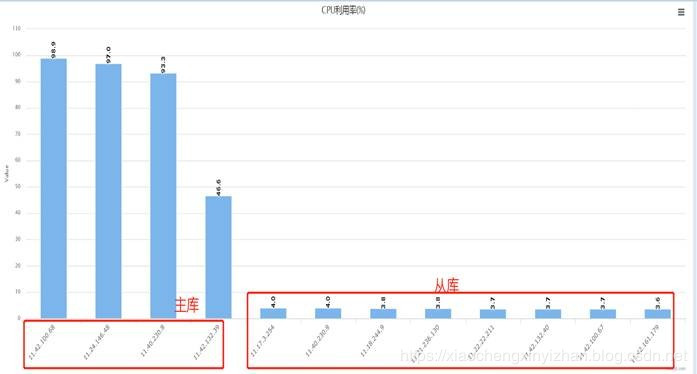
读写分离之后master主库CPU使用率10%以下。
从上述来看我们的读写分离实践效果还是蛮不错的,但是这里如下几个问题:
0、MySQL主从集群主要解决的问题?
1、MySQL主从同步的几种策略?以及区别?
2、MySQL的主从延迟到底有多大?
3、多少的延迟时间我们能接受?
4、主从延迟的根本原因是什么?
5、当数据量大读写分离只要有写的地方依然会出现延迟导致的数据不一致情况,该如何解决?
0、MySQL主从集群主要解决的问题?
# 多主库原因:
高并发的情况下,单台MySQL数据库的连接数多,这样QPS/OPS就会非常大。就像上述我提到的我这里的压测结果,MySQL最大7k的QPS。随着并发数再多,QPS的处理能力也会下降。那么如何解决这个瓶颈。这个时候就会分库,分摊QPS/OPS的能力,本来单台master库的QPS/OPS的请求是2w,我这里分片4个master主库,则相当于每个master主库分摊5000请求量。(如果不好理解可以比喻成服务器集群,在服务架构演变过程中单台服务器变为多台服务器,如果依然不能理解的话可以参考下这篇文章**大型网站的演进**)
所以这样我们可以知道降低了单台服务器的连接数请求量。
# 主从库原因:
那么对于5000单台请求量(基于刚才的假设模型),他的请求构成比例又是如何呢?以及如何防止流量并发的场景导致的系统不可用瘫痪呢?数据丢失呢?
首先我们可以考虑进行数据备份,以及进行流量分析,而一般往往我们就引入了从库:
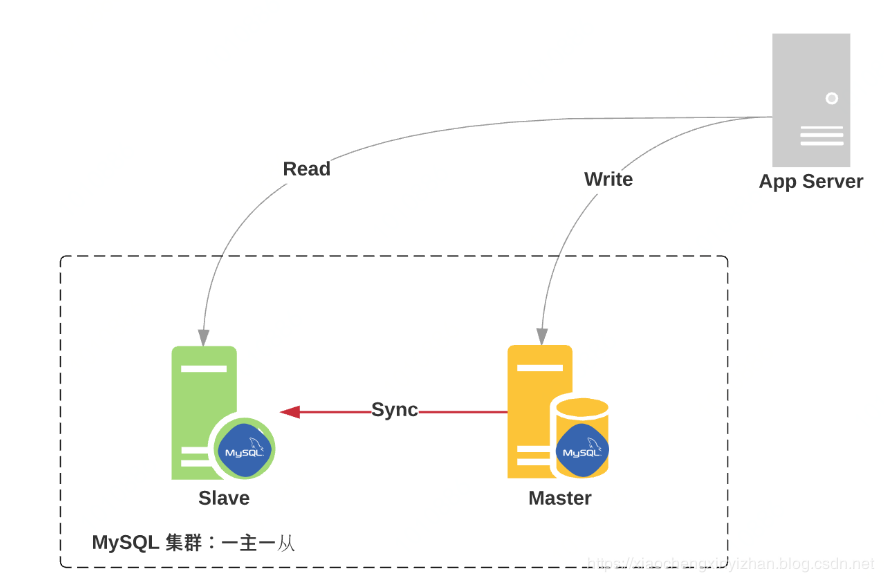
一主一从:一个 Master,一个 Slave
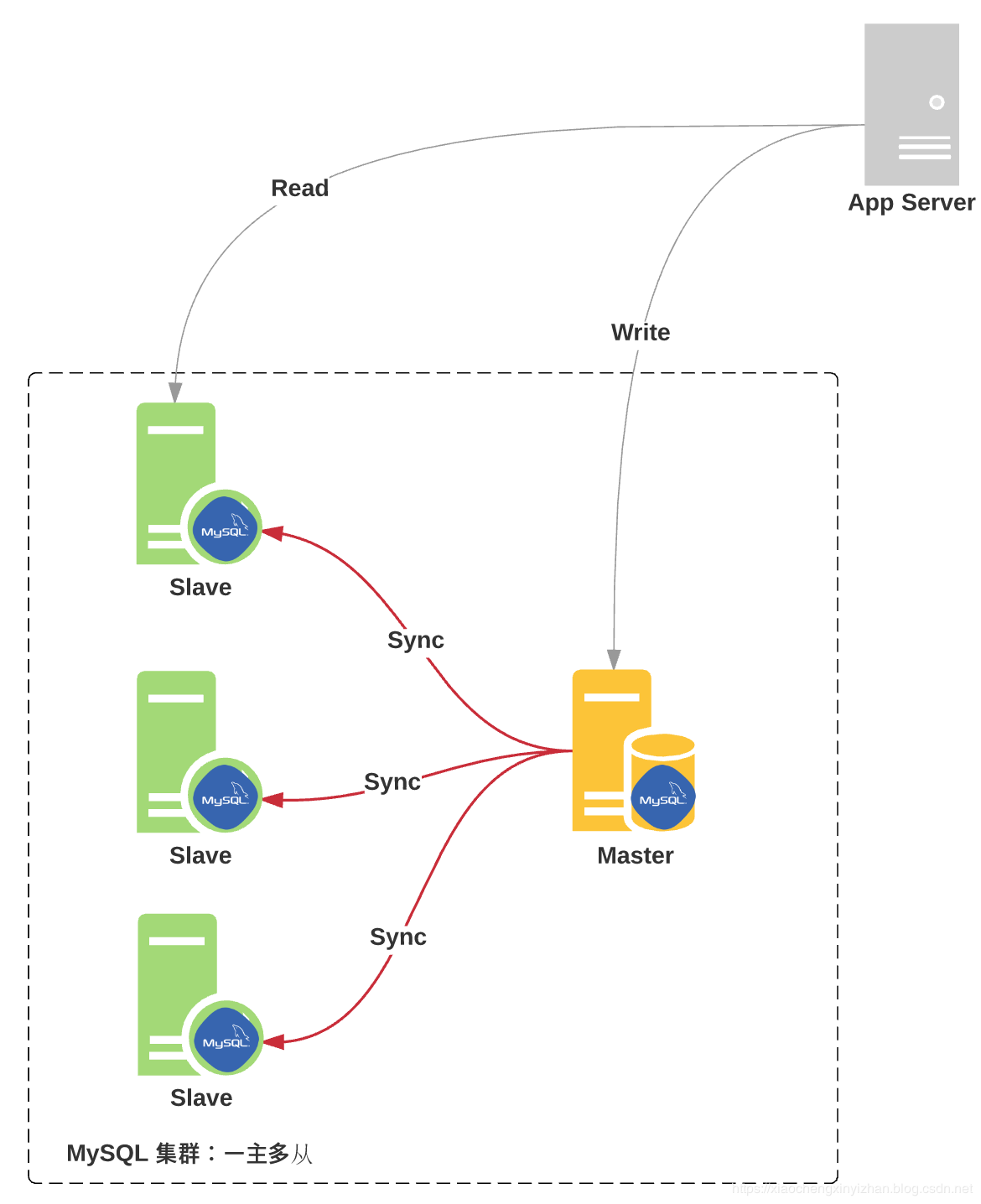
一主多从:一个 Master,多个 Slave
请求构成比例可以参考我上面的这个图(实际生产环境):

可以从图中看到比例read:write=10.73k:26 近似等于 10000:1,平均比例:298.91:2.4=150:1的比例,明显是读取操作大约写入操作,相当于1次写入的时候平均承担了150次请求读取操作。而当流量并发上来的时候更是夸张到1w:1。那么我们能不能把静态的数据读取放到备份数据从库上呢?答案明显是可以的。
1、MySQL主从同步的几种策略?以及区别?
主从同步机制:
那么这里还需要考虑的是一个复制数据的同步机制:
一主一从的情况
一主多从的情况
根据上图我们来看下他具体是如何实现同步的,我们都知道其实mysql执行的时候是根据binlog日志进行数据执行的。那么我们当然可以根据binlog日志进行最原始的数据二次处理。
2、MySQL的主从延迟到底有多大?
3、多少的延迟时间我们能接受?
4、主从延迟的根本原因是什么?
实现原理:
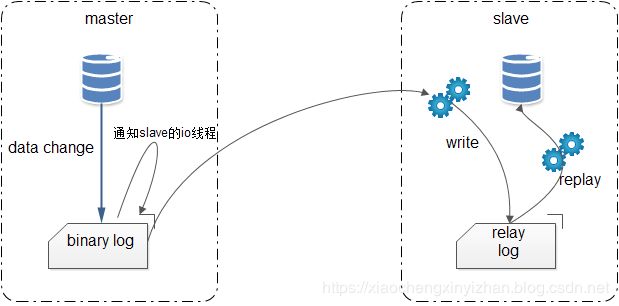
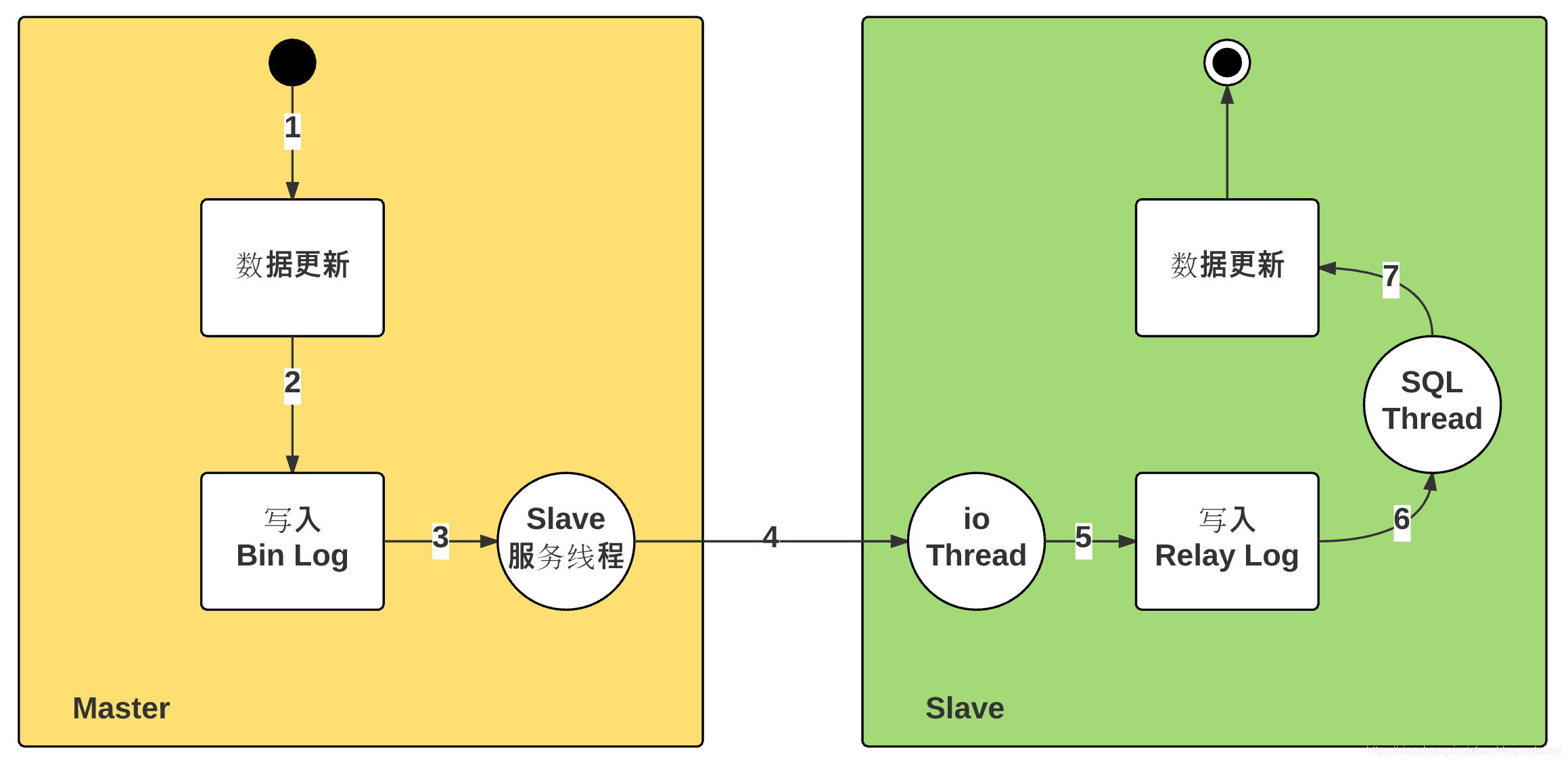
主从延时时间:Master 执行成功,到 Slave 执行成功,时间差。


由于从库从主库拷贝日志以及串行执行SQL的特点,在高并发场景下,从库的数据一定会比主库慢一些,是有延时的。所以经常出现,刚写入主库的数据可能是读不到的,要过几十毫秒,甚至几百毫秒才能读取到。
而且这里还有另外一个问题,就是如果主库突然宕机,然后恰好数据还没同步到从库,那么有些数据可能在从库上是没有的,有些数据可能就丢失了
mysql的两个机制:
# 一个是半同步复制,用来解决主库数据丢失问题;
semi-sync复制,指的就是主库写入binlog日志之后,就会将强制此时立即将数据同步到从库,从库将日志写入自己本地的relay log之后,接着会返回一个ack给主库,主库接收到至少一个从库的ack之后才会认为写操作完成了
# 一个是并行复制,用来解决主从同步延时问题。
指的是从库开启多个线程,并行读取relay log中不同库的日志,然后并行重放不同库的日志,这是库级别的并行。
监控主从延迟:
Slave 使用本机当前时间,跟 Master 上 binlog 的时间戳比较
pt-heartbeat、mt-heartbeat
本质:同一条 SQL,Master 上执行结束的时间 vs. Slave 上执行结束的时间。
5、当数据量大读写分离只要有写的地方依然会出现延迟导致的数据不一致情况,该如何解决?
1、分析mysql日志 看是否慢查询太多
2、统计高峰时期的写入语句数量以及平均值
3、检查同步时主库和从库的网络数据传输量
4、统计服务器运行状态信息
5、从探针的角度来考虑问题,方法是在Master上增加一个自增表,这个表仅含有1个的字段。当Master接收到任何数据更新的请求时,均会触发这个触发器,该触发器更新自增表中的记录。如下图所示:
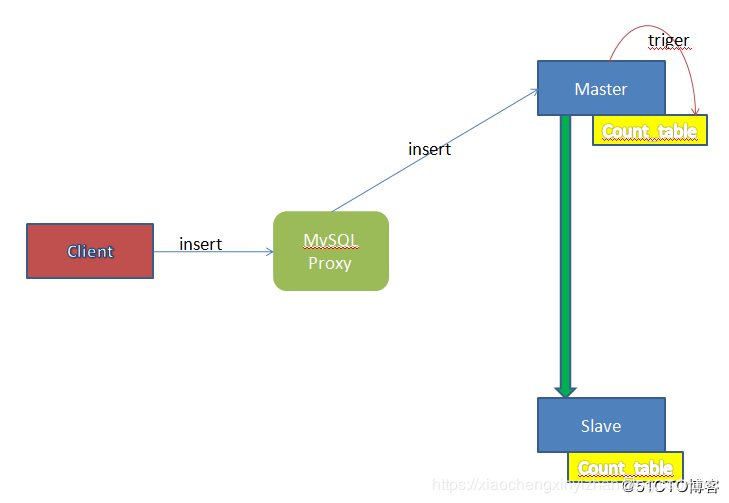
由于Count_table也参与Mysq的主从同步,因此在Master上作的 Update更新也会同步到Slave上。当Client通过Proxy进行数据读取时,Proxy可以先向Master和Slave的 Count_table表发送查询请求,当二者的数据相同时,Proxy可以认定 Master和Slave的数据状态是一致的,然后把select请求发送到Slave服务器上,否则就发送到Master上。如下图所示:
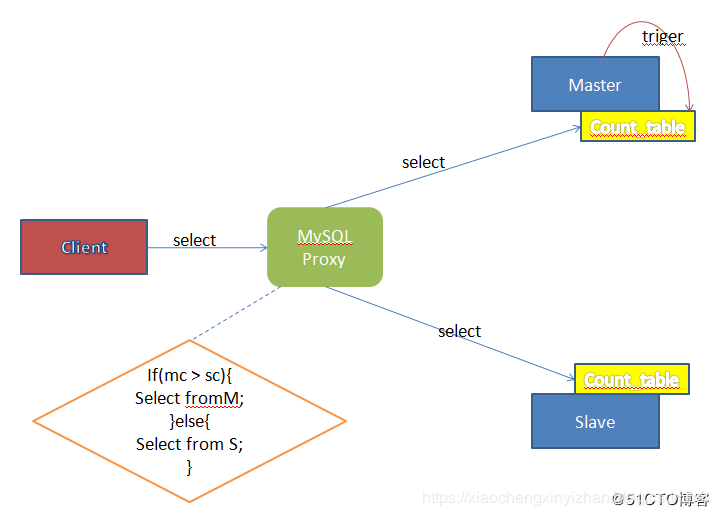
瓶颈思考的角度:sql语句包含大量慢查询,高并发,网络传输问题以及服务器配置
Note:
读写分离不适用的场景不能强行使用:
否则读写分离的主从延迟导致的影响会不止如下几条:
异常情况下, HA 无法切换: HA 软件需要检查数据的一致性,延迟时,主备不一致
备库 Hang 会引发备份失败:flush tables with read lock 会 900s 超时
以 Slave 为基准进行的备份,数据不是最新的,而是延迟的。
这样就会导致的结果读写分离没有意义,主备容灾失效。
那么又回归到了原始开始的场景,如果要使用那么区分自己的业务场景,并细化事务,提升SQL执行速度,优化索引,减少不必要的DML操作,
以及定位2/8原则到底是哪些表的数据影响主从延迟大。然后最重要的一点就是有时候往往业务逻辑是引发问题的根本原因,优化业务逻辑是
最根本的问题。动态数据变更频繁的必须走实时的读写master主库。否则高并发流量场景下,读写分离带来的损失会更大。
# 1.mysql数据库从库同步的延迟问题
首先在服务器上执行show slave satus;可以看到很多同步的参数:
Master_Log_File:SLAVE中的I/O线程当前正在读取的主服务器二进制日志文件的名称
Read_Master_Log_Pos:在当前的主服务器二进制日志中,SLAVE中的I/O线程已经读取的位置
Relay_Log_File:SQL线程当前正在读取和执行的中继日志文件的名称
Relay_Log_Pos:在当前的中继日志中,SQL线程已读取和执行的位置
Relay_Master_Log_File:由SQL线程执行的包含多数近期事件的主服务器二进制日志文件的名称
Slave_IO_Running:I/O线程是否被启动并成功地连接到主服务器上
Slave_SQL_Running:SQL线程是否被启动
Seconds_Behind_Master:从属服务器SQL线程和从属服务器I/O线程之间的时间差距,单位以秒计。
#从库同步延迟情况的出现
1、show slave status显示参数Seconds_Behind_Master不为0,这个数值可能会很大
2、show slave status显示参数Relay_Master_Log_File和Master_Log_File显示bin-log的编号
相差很大,说明bin-log在从库上没有及时同步,所以近期执行的bin-log和当前IO线程所读的bin-log相差很大
3、mysql的从库数据目录下存在大量mysql-relay-log日志,该日志同步完成之后就会被系统自动删除,存在大量日志,说明主从同步延迟很厉害
# a、MySQL数据库主从同步延迟原理
mysql主从同步原理:
主库针对写操作,顺序写binlog,从库单线程去主库顺序读”写操作的binlog”,从库取到binlog在本地原样执行(随机写),来保证主从数据逻
辑上一致。mysql的主从复制都是单线程的操作,主库对所有DDL和DML产生binlog,binlog是顺序写,所以效率很高,slave的Slave_IO_Running
线程到主库取日志,效率比较高,下一步,问题来了,slave的Slave_SQL_Running线程将主库的DDL和DML操作在slave实施。DML和DDL的IO操作是
随即的,不是顺序的,成本高很多,还可能可slave上的其他查询产生lock争用,由于Slave_SQL_Running也是单线程的,所以一个DDL卡主了,需要
执行10分钟,那么所有之后的DDL会等待这个DDL执行完才会继续执行,这就导致了延时。
有朋友会问:“主库上那个相同的DDL也需要执行10分,为什么slave会延时?”,答案是master可以并发,Slave_SQL_Running线程却不可以。
# b、 MySQL数据库主从同步延迟是怎么产生的?
当主库的TPS并发较高时,产生的DDL数量超过slave一个sql线程所能承受的范围,那么延时就产生了,当然还有就是可能与slave的大型query语句
产生了锁等待。
首要原因:数据库在业务上读写压力太大,CPU计算负荷大,网卡负荷大,硬盘随机IO太高
次要原因:读写binlog带来的性能影响,网络传输延迟。
#c、 MySQL数据库主从同步延迟解决方案。
架构方面:
1.业务的持久化层的实现采用分库架构,mysql服务可平行扩展,分散压力。
2.单个库读写分离,一主多从,主写从读,分散压力。这样从库压力比主库高,保护主库。
3.服务的基础架构在业务和mysql之间加入memcache或者redis的cache层。降低mysql的读压力。
4.不同业务的mysql物理上放在不同机器,分散压力。
5.使用比主库更好的硬件设备作为slave
总结,mysql压力小,延迟自然会变小。
硬件方面:
1.采用好服务器,比如4u比2u性能明显好,2u比1u性能明显好。
2.存储用ssd或者盘阵或者san,提升随机写的性能。
3.主从间保证处在同一个交换机下面,并且是万兆环境。
总结,硬件强劲,延迟自然会变小。一句话,缩小延迟的解决方案就是花钱和花时间。
# mysql主从同步加速
1、sync_binlog在slave端设置为0
2、–logs-slave-updates 从服务器从主服务器接收到的更新不记入它的二进制日志。
3、直接禁用slave端的binlog
4、slave端,如果使用的存储引擎是innodb,innodb_flush_log_at_trx_commit =2
# 从文件系统本身属性角度优化
master端
修改linux、Unix文件系统中文件的etime属性, 由于每当读文件时OS都会将读取操作发生的时间回写到磁盘上,对于读操作频繁的数据库文件
来说这是没必要的,只会增加磁盘系统的负担影响I/O性能。可以通过设置文件系统的mount属性,组织操作系统写atime信息,在linux上的操作为:
打开/etc/fstab,加上noatime参数
/dev/sdb1 /data reiserfs noatime 1 2
然后重新mount文件系统
#mount -oremount /data
PS:
主库是写,对数据安全性较高,比如sync_binlog=1,innodb_flush_log_at_trx_commit = 1 之类的设置是需要的
而slave则不需要这么高的数据安全,完全可以讲sync_binlog设置为0或者关闭binlog,innodb_flushlog也可以设置为0来提高sql的执行效率
1、sync_binlog=1 o
MySQL提供一个sync_binlog参数来控制数据库的binlog刷到磁盘上去。
默认,sync_binlog=0,表示MySQL不控制binlog的刷新,由文件系统自己控制它的缓存的刷新。这时候的性能是最好的,但是风险也是最大的。
一旦系统Crash,在binlog_cache中的所有binlog信息都会被丢失。
如果sync_binlog>0,表示每sync_binlog次事务提交,MySQL调用文件系统的刷新操作将缓存刷下去。最安全的就是sync_binlog=1了,表示
每次事务提交,MySQL都会把binlog刷下去,是最安全但是性能损耗最大的设置。这样的话,在数据库所在的主机操作系统损坏或者突然掉电的
情况下,系统才有可能丢失1个事务的数据。
但是binlog虽然是顺序IO,但是设置sync_binlog=1,多个事务同时提交,同样很大的影响MySQL和IO性能。
虽然可以通过group commit的补丁缓解,但是刷新的频率过高对IO的影响也非常大。对于高并发事务的系统来说,
“sync_binlog”设置为0和设置为1的系统写入性能差距可能高达5倍甚至更多。
所以很多MySQL DBA设置的sync_binlog并不是最安全的1,而是2或者是0。这样牺牲一定的一致性,可以获得更高的并发和性能。
默认情况下,并不是每次写入时都将binlog与硬盘同步。因此如果操作系统或机器(不仅仅是MySQL服务器)崩溃,有可能binlog中最后的语句丢失了。
要想防止这种情况,你可以使用sync_binlog全局变量(1是最安全的值,但也是最慢的),使binlog在每N次binlog写入后与硬盘同步。即使sync_binlog
设置为1,出现崩溃时,也有可能表内容和binlog内容之间存在不一致性。
2、innodb_flush_log_at_trx_commit (这个很管用)
抱怨Innodb比MyISAM慢 100倍?那么你大概是忘了调整这个值。默认值1的意思是每一次事务提交或事务外的指令都需要把日志写入(flush)硬盘,
这是很费时的。特别是使用电池供电缓存(Battery backed up cache)时。设成2对于很多运用,特别是从MyISAM表转过来的是可以的,它的意思
是不写入硬盘而是写入系统缓存。
日志仍然会每秒flush到硬 盘,所以你一般不会丢失超过1-2秒的更新。设成0会更快一点,但安全方面比较差,即使MySQL挂了也可能会丢失事务的
数据。而值2只会在整个操作系统 挂了时才可能丢数据。
**数据库——MySQL分库分表的演进和实践以及中间件的比较:**https://blog.csdn.net/wolf_love666/article/details/82773300
**大型网站架构演化:**https://blog.csdn.net/wolf_love666/article/details/77162031
**主从同步和主从延迟:**http://ningg.top/inside-mysql-master-slave-delay/
**解决Mysql读写分离数据延迟:**https://blog.51cto.com/ww123/2108302
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/139659.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
