大家好,又见面了,我是你们的朋友全栈君。
一:Map
Map用于保存具有映射关系的数据,总是以键值对的方式存储数据。
Map继承树

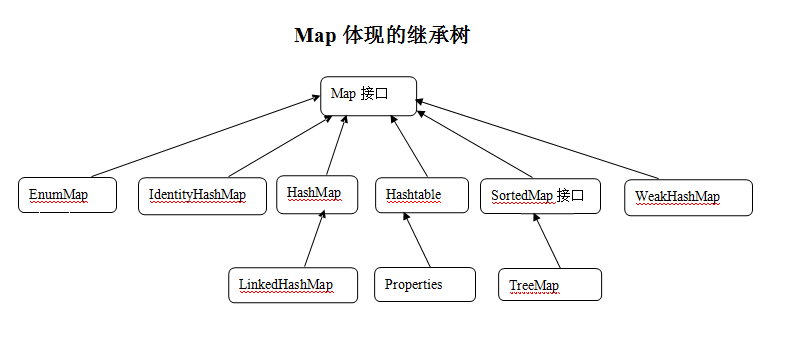
Map集合的key和value都可以是任何引用类型的数据。Map集合的key不允许重复,value允许重复。key和value之间存在单向一对一关系,即通过指定的键可以找到唯一,确定的value。Map集合中获取数据时,只要给出指定的key,就可以取出对应的value。
Map接口中定义的常用方法:
(1)void clear():删除该Map对象中所有的键值对。
(2)boolean containsKey(Object key):查询Map中是否包含指定key。
(3)boolean containsValue(Object value):查询Map中是否包含一个或多个value。
(4)Set entrySet():返回Map中所包含的键值对所组成的Set集合,每个集合元素都是Map.Entry对象。
(5)Object get(Object obj):返回指定key所对应的value。如果没有,这返回null。
(6)boolean isEmpty():查询该Map是否为空,如果为空则返回true。
(7)Set keySet():返回该Map中所有key组成的Set集合。
(8)Object put(Object key, Object value):添加一个键值对,如果当前Map中已经有一个与该key相等的键值对,则新的键值对将覆盖原来的键值对。
(9)void putAll(Map m):将指定Map中的键值对复制到m中。
(10)Object remove(Object key):删除指定key所对应的键值对,如果不存在,则返回null。
(11)int size():返回Map里的键值对个数。
(12)Collection values():返回该Map里所有的vlaue组成的Collection。
Map中包括一个内部类Entry。该类封装了一个键值对。
Entry包含的三个方法:
(1)Object getKey():返回该Entry里包含的key值。
(2)Object getValue():返回该Entry里包含的value值。
(3)Object setValue(V value):设置该Entry里包含的value值,并返回新设置的value值。
HashMap和Hashtable实现类
HashMap和Hashtable都是Map接口的典型实现类,Hashtable是一个古老的集合,JDK1.0起就出现了。
HashMap和Hashtable的典型区别:
(1)Hashtable是一个线程安全的Map实现,但HashMap是线程不安全的实现。所以HashMap比Hashtable的性能高一点。
(2)Hashtable不允许使用null作为key和value。
注意:HashMap和Hashtable判断两个key相等的标准是:两个key通过equals方法比较返回true,两个key的hashCode值也要相等。
HashMap和Hashtable包含一个containsValue方法用于判断是否包含指定vlaue,HashMap和Hashtable判断值相等的标准:只要两个对象通过equals方法比较返回true即可。
LinkedHashMap类:
LinkedHashMap和LinkedHashSet一样,也是使用双向链表来维持键值对的顺序,该链表定义了迭代顺序,该迭代顺序与键值对的插入顺序保持一致。
LinkedHashMap需要维护元素的插入顺序,因此性能略低于HashMap的性能,但在迭代方法Map集合的全部元素时将有很好的性能,因为它以链表来维护内部顺序。
Properties类
Properties类是Hashtable的子类。该对象在处理属性文件时特别方便。Properties类可以把Map对象和属性文件关联起来,从而可以把Map对象中的键值对写入属性文件,也可以把属性文件中的属性名=属性值加载到Map对象中。由于属性文件中的属性名和属性值只能是字符串类型,所以Properties里的key和value都是字符串类型。Properties提供的常用方法:
(1)String getProperty(String key):获取Properties中指定属性名对应的属性值,类似于Map的get方法。
(2)String getProperty(String key, String defaultValue):该方法与上面的方法基本类似,如果Properties中不存在指定的key值,该方法返回默认值。
(3)Object setProperty(String key,String value):设置属性值,类似Hashtable的put方法。
(4)void load(InputStream inStream):从属性文件(以输入流表示)中加载属性名=属性值,把加载到的属性名=属性值对追加到Properties里。
(5)void store(OutputStream out,String comments):将Properties中的键值对写入指定属性文件(以输出流表示)。
经典实例:
public class PropertiesTest {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
//向Properties中增加属性
props.setProperty("userName", "smarhit");
props.setProperty("password", "1234456");
//将Properties中的属性保存到test.ini文件中
props.store(new FileOutputStream("d:\\test.ini"), "smarhit");
//新键一个Properties对象
Properties props1 = new Properties();
//向Properties中增加属性
props1.setProperty("gender", "MALE");
//将test.ini文件中的属性名-属性值追加到props2中
props1.load(new FileInputStream("d:\\test.ini"));
System.out.println(props1);//{password=1234456, gender=MALE, userName=smarhit}
}
}test.ini文件的内容:
#smarhit
#Tue Mar 12 22:22:26 CST 2013
password=1234456
userName=smarhit
Properties还可以把键值对以XML文件的形式保存,也可以从XML文件中加载属性名-属性值。
SortedMap接口和TreeMap实现类
Map接口和set接口一样,也派生出一个SortedMap子接口,TreeMap是SortedMap接口的实现类。与TreeSet类似,TreeMap也是基于红黑树对TreeMap中所有key进行排序,从而保证TreeMap中所有键值对处于有序状态。
TreeMap同样有两种排序方式:自然排序,定制排序。
TreeMap判断两个key相等的标准和TreeSet判断两个元素相等的标准是一样的。TreeMap提供的方法也和TreeSet的类似【参考上一篇博客】。
WeakHashMap实现类
WeakHashMap与HashMap的用法基本相似,但与HashMap的区别在于,HashMap的key保留对实际对象的强引用,这意味着只要该HashMap对象不被销毁,该HashMap对象所有key所引用的对象不会被垃圾回收,HashMap也不会自动删除这些key所对应的键值对对象;但WeakHashMap的key只保留对实际对象的弱引用,这意味着如果该HashMap对象所有key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能被垃圾回收,HashMap也可能自动删除这些key所对应的键值对对象。
经典实例:
public class WeakHashMapTest {
public static void main(String[] args) {
// 创建WeakHashMap对象
WeakHashMap<String, String> whm = new WeakHashMap<String, String>();
// 向WeakHashMap中添加数据,三个key值都是匿名字段。
whm.put(new String("语文"), new String("优秀"));
whm.put(new String("数学"), new String("及格"));
whm.put(new String("英语"), new String("中等"));
whm.put(new String("日语"), new String("优秀"));
// 向WeakHashMap加入一条强应用数据
whm.put("德语", "不会");
System.out.println(whm);// 打印输出:{德语=不会, 数学=及格, 英语=中等, 日语=优秀, 语文=优秀}
// 通知系统立即进行垃圾回收。
System.gc();
System.runFinalization();
System.out.println(whm);// 打印输出:{德语=不会}
}
}
如果需要使用WeakHashMap的key来保留对象的弱引用,不要让该key所引用的对象具有任何强引用,否则将失去使用WeakHashMap的意义。
IdentityHashMap实现类
IdentityHashMap和HashMap基本相似,但它在处理两个key相等时比较独特:在IdentityHashMap中,当且仅当两个key严格相等(key1==key2)时,IdentityHashMap才认为两个key相等,而HashMap,只要key1和key2通过equals比较返回true,并且他们的hashCode值相等才认为两个可以相等。
IdentityHashMap提供了与HashMap基本相似的方法,也允许使用null作为key和value。
EnumMap实现类
EnumMap是一个与枚举类一起使用的Map实现。EnumMap中所有key都必须是单个枚举类的枚举值。
EnumMap在内部以数组形式保存,所以这种实现形式非常紧凑、高效。
EnumMap根据key的自然顺序(枚举值在枚举类中定义的顺序)来维护键值对的次序,
EnumMap不允许使用null作为key值,但允许使用null作为value。
操作集合的工具类:Collections
Collections该工具类提供了大量的方法对集合元素进行排序,查询和修改等操作。还提供了将集合对象设置为不可变,对集合对象实现同步控制等方法。
排序操作。
Collections提供了如下几个方法对List集合元素进行排序
(1)static void reverse(List list):反转指定List集合中元素的顺序。
(2)static void shuffle(List list):对List集合元素进行随机排序。
(3)static void sort(List list):根据元素的自然顺序对指定List集合的元素按升序进行排序。
(4)static void sort(List list,Comparator c):根据指定Comparator产生的顺序对List集合的元素进行排序。
(5)static void swap(List list,int i,int j):将指定List集合中i处元素和j处元素进行交换。
(6)static void rotate(List list,int distance):当distance为正数时,将list集合的后distance个元素移到前面;当distance为负数时,将list集合中的前distance个元素移到后面。该方法不会改变集合的长度。
查找,替换操作
Collections还提供了如下用于查找、替换集合元素的常用方法
(1)static int binarySearch(List list,Object key):使用二分搜索法搜索指定List集合,以获得指定对象在List集合中的索引。记得必须保证List中的元素已经处于有序状态。
(2)static Object max(Collection coll):根据元素的自然顺序,返回给定集合中最大元素。
(3)static Object max(Collection coll,Comparator comp):根据指定Comparator产生的顺序,返回给定集合的最大元素。
(4)static Object min(Collection coll):根据元素的自然顺序,返回给定集合中最小元素。
(5)static Object min(Collection coll,Comparator comp):根据指定Comparator产生的顺序,返回给定集合的最小元素。
(6)static void fill(List list,Object obj):使用指定元素obj替换指定List集合中的所有元素。
(7)static int frequency(Collection c,Object o):返回指定集合中等于指定对象的元素数量。
(8)static int indexOfSubList(List source,List targer):返回子List对象在母List对象中第一次出现的位置索引;如果母List中没有出现子List,返回-1。
(9)static int lastIndexOfSubList(List source,List targer):返回子List对象在母List对象中最后一次出现的位置索引;如果母List中没有出现子List,返回-1。
(10)static boolean replaceAll(List list,Object oldVal,Object newVal):使用一个新值newVal替换List对象所有的旧值oldVal。
同步控制
Collections类提供了多个synchronizedXxx方法,该方法返回指定集合对象对应的同步对象,从而可以解决多线程并发访问集合时的线程安全问题。
经典实例:
public static void main(String[] args) {
//下面创建四个同步的集合对象
Collection<String> c=Collections.synchronizedCollection(new ArrayList<String>());
List<String> list=Collections.synchronizedList(new ArrayList<String>());
Set<String> set=Collections.synchronizedSet(new HashSet<String>());
Map<String, String> map=Collections.synchronizedMap(new HashMap<String, String>());
}
设置不可变集合
Collections提供了入下三类方法来返回一个不可以变的集合:
(1)emptyXxx():返回一个空的,不可以变的集合对象,此处的集合既可以是List,也可以是Set,还可以是Map。
(2)singletonXxx():返回一个值包含指定对象(只有一个或一项元素)的,不可以变的集合对象,此处的集合既可以是List,也可以是Set,还可以是Map。
(3)unmodifiableXxx():返回指定集合对象的不可变视图。此处的集合既可以是List,也可以是Set,还可以是Map。
经典实例:
public class CollectionsTest {
public static void main(String[] args) {
//创建一个空的,不可改变的List对象
List<String> unmodifiableList=Collections.emptyList();
//创建一个只有一个元素,且不可改变的Set对象
Set<String> unmodifiableSet=Collections.singleton("Android");
//创建一个普通的map对象
Map<String, Integer> map=new HashMap<String, Integer>();
map.put("语文", 90);
map.put("Java", 80);
map.put("Android", 95);
//返回普通map对象对应的不可变版本。
Map<String, Integer> unmodifiableMap=Collections.unmodifiableMap(map);
//下面三句话都会引发java.lang.UnsupportedOperationException异常
unmodifiableList.add("smarhit");
unmodifiableSet.add("java");
unmodifiableMap.put("math", 100);
}
}
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/139346.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
