大家好,又见面了,我是你们的朋友全栈君。
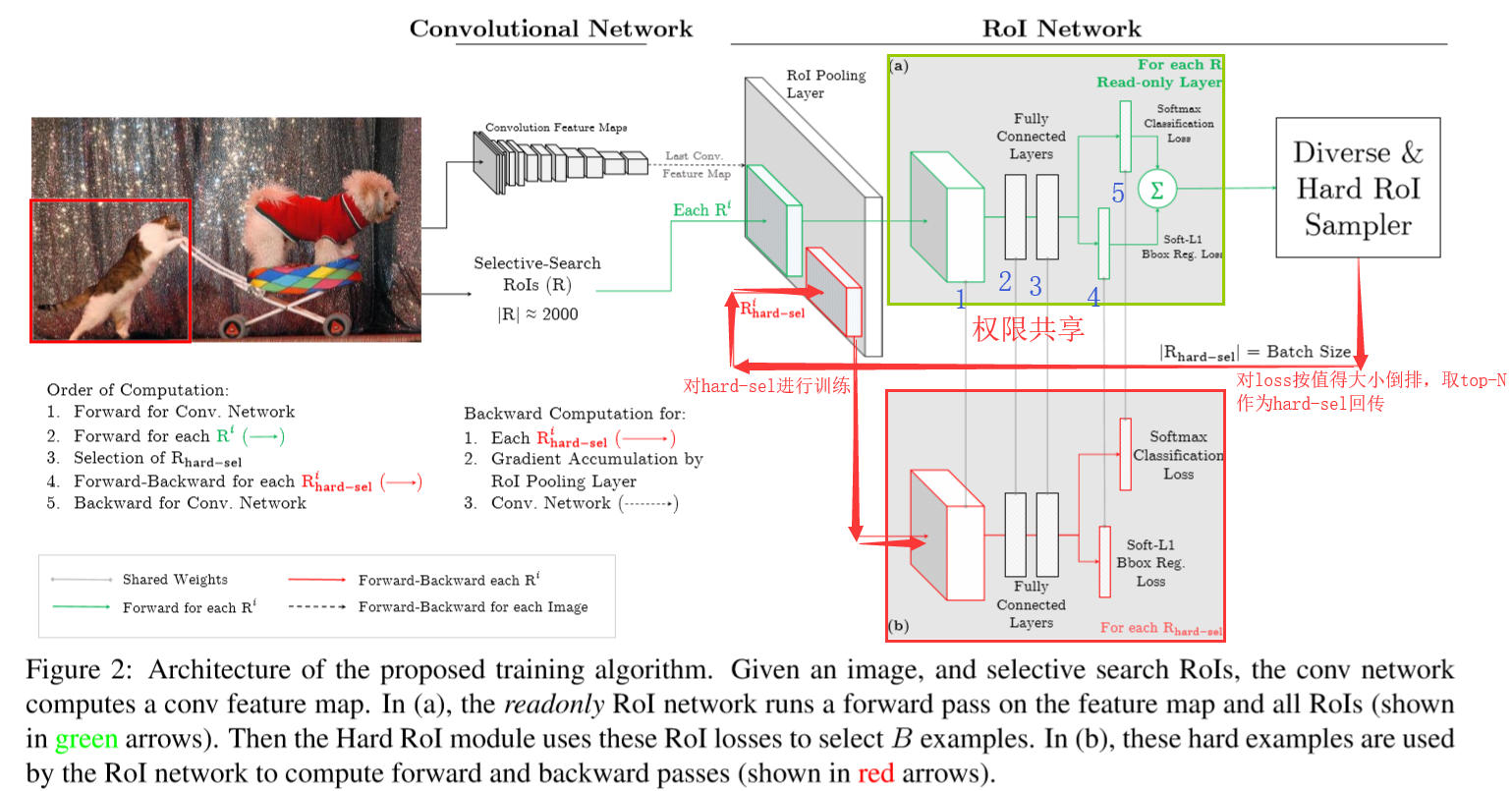

代码上如何实现Read-only Layer与R _hard-sel权限共享?
https://github.com/abhi2610/ohem/blob/master/models/pascal_voc/VGG_CNN_M_1024/fast_rcnn_ohem/train.prototxt
下面代码对应(a),前向传播过程
## Readonly RoI Network
layer {
name: "roi_pool5_readonly"
type: "ROIPooling"
bottom: "conv5"
bottom: "rois"
top: "pool5_readonly"
propagate_down: false
propagate_down: false
roi_pooling_param {
pooled_w: 6
pooled_h: 6
spatial_scale: 0.0625 # 1/16
}
}
其中:propagate_down设置为false,可实现forward inference
下面代码对应(b),前向和反向传播过程
layer {
name: "roi_pool5"
type: "ROIPooling"
bottom: "conv5"
bottom: "rois_hard"
top: "pool5"
propagate_down: true
propagate_down: false
roi_pooling_param {
pooled_w: 6
pooled_h: 6
spatial_scale: 0.0625 # 1/16
}
}
其中:propagate_down设置为True,可实现前向和后向传播,减小难样例的损失,同时可以调整卷积层的参数
为什么要hard mining?
- 1 减少fg和bg的ratio,而且不需要人为设计这个ratio;
- 2 加速收敛,减少显存需要这些硬件的条件依赖,原因是直接训练难样例,使损失最大的函数对应的样例经过训练后loss 直接减小;
- 3 hard-mining已经证实了是一种booststrapping的方式, 尤其当数据集较大而且较难的时候;
- 4 eliminates several heuristics and hyperparameters in common use by automatically selecting hard examples, thus simplifying training。 放宽了定义negative example的bg_lo threshold,即从[0.1, 0.5)变化到[0, 0.5)。
取消了正负样本在mini-batch里的ratio(原Fast-RCNN的ratio为1:3)
参考:https://blog.csdn.net/qq_36302589/article/details/84998509
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/139299.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
