大家好,又见面了,我是你们的朋友全栈君。
最近碰到一个问题,需要读取后缀为xlsx的文件,因此在此总结一下python对于xlsx文件的读写。
一般如果是后缀xls的话,用xlwt和xlrd进行读写;而后缀是xlsx的话,用openpyxl进行读写。在此主要介绍openpyxl库对xlsx的读写。
参考链接:python之openpyxl模块
xlsx文件的写入
新建工作簿和新建工作表
首先,openpyxl库中有个Workbook对象,其代表一个Excel文档。
Workbook提供的部分常用属性如下:
| 属性 | 含义 |
|---|---|
| active | 获取当前活跃的Worksheet |
| worksheets | 以列表的形式返回所有的sheet对象(表格对象) |
| read_only | 判断是否以read_only模式打开Excel文档 |
| write_only | 判断是否以write_only模式打开Excel文档 |
| encoding | 获取文档的字符集编码 |
| properties | 获取文档的元数据,如标题,创建者,创建日期等 |
| sheetnames | 以列表的形式返回工作簿中的表的表名(表名字符串) |
Workbook对象提供的部分常用方法如下:
| 方法 | 含义 |
|---|---|
| get_sheet_names | 获取所有表格的名称(新版已经不建议使用,通过Workbook的sheetnames属性即可获取) |
| get_sheet_by_name | 通过表格名称获取Worksheet对象(新版也不建议使用,通过Workbook[‘表名‘]获取) |
| get_active_sheet | 获取活跃的表格(新版建议通过active属性获取) |
| remove_sheet | 删除一个表格 |
| create_sheet | 创建一个空的表格 |
| copy_worksheet | 在Workbook内拷贝表格 |
例如,如下代码创建一个名为data1的工作簿,在有默认sheet的基础上,为其创建一个新的sheet,名为sheet2。
from openpyxl import Workbook
# 创建一个Workbook对象
wb = Workbook()
# 如果不指定sheet索引和表名,默认在第二张表位置新建表名sheet1
wb.create_sheet(index=1, title="sheet2")
# 获取当前活跃的sheet,默认为第一张sheet
ws = wb.active
print(ws)
# 获取当前工作簿的所有sheet对象
sheets = wb.worksheets
print(sheets)
# 获取所有sheet的名字
sheets_name = wb.sheetnames
print(sheets_name)
# 保存为工作簿data1.xlsx
wb.save('data1.xlsx')
打印结果如下,结果可以看出,当前sheet名字为Sheet,新建的sheet名字为sheet2。wb.worksheets返回的是Worksheet对象,wb.sheetnames返回的是表名字符串列表。
<Worksheet "Sheet">
[<Worksheet "Sheet">, <Worksheet "sheet2">]
['Sheet', 'sheet2']
为工作表添加内容
Workbook对象代表一张工作簿,而其中有一张或多张sheet,这些sheet便是一个个Worksheet对象。
Worksheet对象的属性如下:
| 属性 | 含义 |
|---|---|
| title | 表格的标题 |
| dimensions | 表格的大小,这里的大小是指含有数据的表格的大小,即:左上角的坐标:右下角的坐标 |
| max_row | 表格的最大行 |
| min_row | 表格的最小行 |
| max_column | 表格的最大列 |
| min_column | 表格的最小列 |
| rows | 按行获取单元格(Cell对象) – 生成器 |
| columns | 按列获取单元格(Cell对象) – 生成器 |
| freeze_panes | 冻结窗格 |
| values | 按行获取表格的内容(数据) – 生成器 |
| Worksheet对象的方法如下: | |
| 方法 | 含义 |
| :—- | :—– |
| iter_rows | 按行获取所有单元格,内置属性有(min_row,max_row,min_col,max_col) |
| iter_columns | 按列获取所有的单元格 |
| append | 在表格末尾添加数据 |
| merged_cells | 合并多个单元格 |
| unmerged_cells | 移除合并的单元格 |
例如,如下代码新建一个data1.xlsx的工作簿,并为当前活跃的第一张sheet表添加了一行表头和两行数据。
from openpyxl import Workbook
# 创建一个Workbook对象
wb = Workbook()
# 获取当前活跃的sheet,默认是第一个sheet
ws = wb.active
ws['A1'] = 'class'
ws['B1'] = 'name'
ws['C1'].value = 'score'
row1 = ['class1', 'zhangsan', 90]
row2 = ['class2', 'lisi', 88]
ws.append(row1)
ws.append(row2)
wb.save('data1.xlsx')
添加之后结果如下:
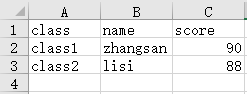

对于一张sheet表,每一个格子是一个Cell对象,其可以用来定位表中任一位置。
Cell对象常用的属性如下:
| 属性 | 含义 |
|---|---|
| row | 单元格所在的行 |
| column | 单元格坐在的列 |
| value | 单元格的值 |
| coordinate | 单元格的坐标 |
因此,也可以通过Cell对象为sheet添加内容。如下是为表添加表头的代码:
ws.cell(row=1, column=1) = 'class'
ws.cell(1,2).value = 'name'
ws.cell(1,3).value = 'score'
xlsx文件的读取
通过Cell对象读取每一格内容,代码如下:
from openpyxl import load_workbook
wb = load_workbook('data1.xlsx')
sheets = wb.worksheets # 获取当前所有的sheet
print(sheets)
# 获取第一张sheet
sheet1 = sheets[0]
# sheet1 = wb['Sheet'] # 也可以通过已知表名获取sheet
print(sheet1)
# 通过Cell对象读取
cell_11 = sheet1.cell(1,1).value
print(cell_11)
cell_11 = sheet1.cell(1,2).value
print(cell_11)
打印结果如下
[<Worksheet "Sheet">]
<Worksheet "Sheet">
class
name
读取表中的一行或者一列内容,代码如下:
from openpyxl import load_workbook
wb = load_workbook('data1.xlsx')
sheets = wb.worksheets # 获取当前所有的sheet
print(sheets)
# 获取第一张sheet
sheet1 = sheets[0]
print(sheet1)
# 获取第一行所有数据
row1 = []
print(sheet1[1])
for row in sheet1[1]:
print(row)
row1.append(row.value)
print(row1)
# 获取第一列所有数据
col1 = []
for col in sheet1['A']:
col1.append(col.value)
print(col1)
结果如下,表中的每一行或者每一列都是一个元组,每一个元素都是一个Cell对象。因此要获取数值必须用Cell对象的value属性。
[<Worksheet "Sheet">]
<Worksheet "Sheet">
(<Cell 'Sheet'.A1>, <Cell 'Sheet'.B1>, <Cell 'Sheet'.C1>)
<Cell 'Sheet'.A1>
<Cell 'Sheet'.B1>
<Cell 'Sheet'.C1>
['class', 'name', 'score']
['class', 'class1', 'class2']
通过sheet对象的rows和columns属性读取表的行或者列,代码如下:
from openpyxl import load_workbook
wb = load_workbook('data1.xlsx')
sheets = wb.worksheets # 获取当前所有的sheet
print(sheets)
# 获取第一张sheet
sheet1 = sheets[0]
print(sheet1)
rows = sheet1.rows
columns = sheet1.columns
print(rows)
print(columns)
print('')
# 迭代读取所有的行
for row in rows:
print(row)
row_val = [col.value for col in row]
print(row_val)
print('')
# 迭代读取所有的列
for col in columns:
print(col)
col_val = [row.value for row in col]
print(col_val)
结果如下,首先,第一部分的第三行和第四行表明获取的rows或者columns是generator object对象。而从第二部分、第三部分奇数行打印的结果看,generator object对象的每一个元素都是一个元组,而元组中的每一个元素是Cell对象。
[col.value for col in row] 可以理解为循环读取row中的每一个Cell对象,并获取Cell对象的value,并将所有的值放到一个列表中。
[<Worksheet "Sheet">]
<Worksheet "Sheet">
<generator object Worksheet._cells_by_row at 0x000001DC06330DE0>
<generator object Worksheet._cells_by_col at 0x000001DC06330F48>
(<Cell 'Sheet'.A1>, <Cell 'Sheet'.B1>, <Cell 'Sheet'.C1>)
['class', 'name', 'score']
(<Cell 'Sheet'.A2>, <Cell 'Sheet'.B2>, <Cell 'Sheet'.C2>)
['class1', 'zhangsan', 90]
(<Cell 'Sheet'.A3>, <Cell 'Sheet'.B3>, <Cell 'Sheet'.C3>)
['class2', 'lisi', 88]
(<Cell 'Sheet'.A1>, <Cell 'Sheet'.A2>, <Cell 'Sheet'.A3>)
['class', 'class1', 'class2']
(<Cell 'Sheet'.B1>, <Cell 'Sheet'.B2>, <Cell 'Sheet'.B3>)
['name', 'zhangsan', 'lisi']
(<Cell 'Sheet'.C1>, <Cell 'Sheet'.C2>, <Cell 'Sheet'.C3>)
['score', 90, 88]
读取有公式的表格
如果碰到带有公式的表格,而只想要读取其中计算的结果时,可以在读取工作簿的时候加上data_only=True的属性,例如:
from openpyxl import load_workbook
wb = load_workbook('data1.xlsx', data_only=True)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/139250.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
