大家好,又见面了,我是你们的朋友全栈君。
OHEM 详解
Training Region-based Object Detectors with Online Hard Example Mining
在 two-stage 的目标检测方法中,经过区域生成算法或者网络生成的 region proposals 通常会经过正负样本的筛选和比例平衡后,才送入之后的检测网络进行训练。但是正负样本的定义和训练的比例是需要人为定义的。如果要筛选 hard mining。通常使用的都是 hard negative mining 的方法。但是此方法不适用于 end-to-end 的模型。因为会大大降低模型的训练速度。
作者观察到传统 hard negative mining 的缺点后,提出了一种 Online Hard Example Mining 的方法。可以自动地选择 had negative 来进行训练,不仅效率高而且性能好。
一、Hard Negative Mining Method
对于 two-stage 的目标检测方法,我们会先生成很多的 region proposals,然后再放入之后的网络进行训练。但是在这些生成的 region proposals 中,正负样本的比例严重不平衡。极端的情况,假如我们有 99 个负样本和 1 个正样本。我们的网络只用预测所有的样本都为负样本就可以达到 99% 的正确率,所以我们需要对正负样本的数量进行平衡,只选出那些 hard negative 的样本进行训练。
(一)Hard Negative Mining Method 思想
解决上述问题的传统方法是用 Hard Negative Mining Method 的方法,它的 思想如下:
对于 hard Negative Mining(困难样本挖掘)可以理解为错题集,你不会把所有的错题都放到错题集中,你会挑出那些你最容易错的题放到错题集中,Hard Negative Mining Method 就是这样。
首先是 negative,即负样本,其次是 hard,说明是困难样本,也可以说是容易将负样本看成正样本的那些样本,例如 roi 里没有物体,全是背景,这时候分类器很容易正确分类成背景,这个就叫 easy negative;如果 roi 里有二分之一个物体,标签仍是负样本,这时候分类器就容易把他看成正样本,这时候就是 had negative。hard negative mining 就是多找一些 hard negative 加入负样本集,进行训练,这样会比 easy negative 组成的负样本集效果更好。
(二)Hard Negative Mining Method 使用
通常 使用 Hard Negative Mining Method 的方法为:
迭代地交替训练,用样本集更新模型,然后再固定模型 来选择分辨错的目标框并加入到样本集中继续训练。传统,我们会使用 SVM + Hard Negative Mining Method 进行训练
(三)Hard Negative Mining Method 缺点
那么传统的 Hard Negative Mining Method 有什么 缺点 呢?
Hard Negative Mining Method 很难应用到 end-to-end 的检测模型。 因为 Hard Negative Mining Method 需要迭代训练,如果我们将他使用到 end-to-end 的卷积神经网络,需要每次将网络冻结一段时间用来生成 hard negative。而这对于使用线上优化的算法来说是不可能的,例如 SGD (随机梯度下降算法)。使用 SGD 来训练网络需要上万次更新网络,如果每迭代几次就固定模型一次,这样的速度会慢得不可想象。
我们可以观察到在 fast rcnn 和 faster rcnn 中都没有用到 Hard Negative Mining Method。这就是因为如上的原因,一般使用 SVM 分类器才能使用此方法(SVM 分类器和 Hard Negative Mining Method 交替训练)
二、OHEM
我们知道,基于 SVM 的检测器,在训练时,使用 hard example mining 来选择样本需要交替训练,先固定模型,选择样本,然后再用样本集更新模型, 这样反复交替训练直到模型收敛。
作者认为可以把交替训练的步骤和 SGD 结合起来。之所以可以这样,作者认为虽然 SGD 每迭代一次只用到少量的图片,但每张图片都包含上千个 RoI,可以从中选择 hard examples,这样的策略可以只在一个 mini-batch 中固定模型,因此模型参数是一直在更新的。
更具体的,在第 t 次迭代时,输入图片到卷积网络中得到特征图,然后把特征图和所有的 RoIs 输入到 RoI 网络中并计算所有 RoIs 的损失,把损失从高到低排序,然后选择 B / N (B 为 Roi 总个数,N 为输入图片个数)个 RoIs。这里有个小问题,位置上相邻的 RoIs 通过 RoI 网络后会输出相近的损失,这样损失就翻倍。作者为了解决这个问题,使用了 NMS(非最大值抑制) 算法,先把损失按高到低排序,然后选择最高的损失,并计算其他 RoI 与这个 RoI 的 IoU (交叉比),移除 IoU 大于一定阈值的 RoI,然后反复上述流程直到选择了 B/N 个 RoIs。
(一)训练方式
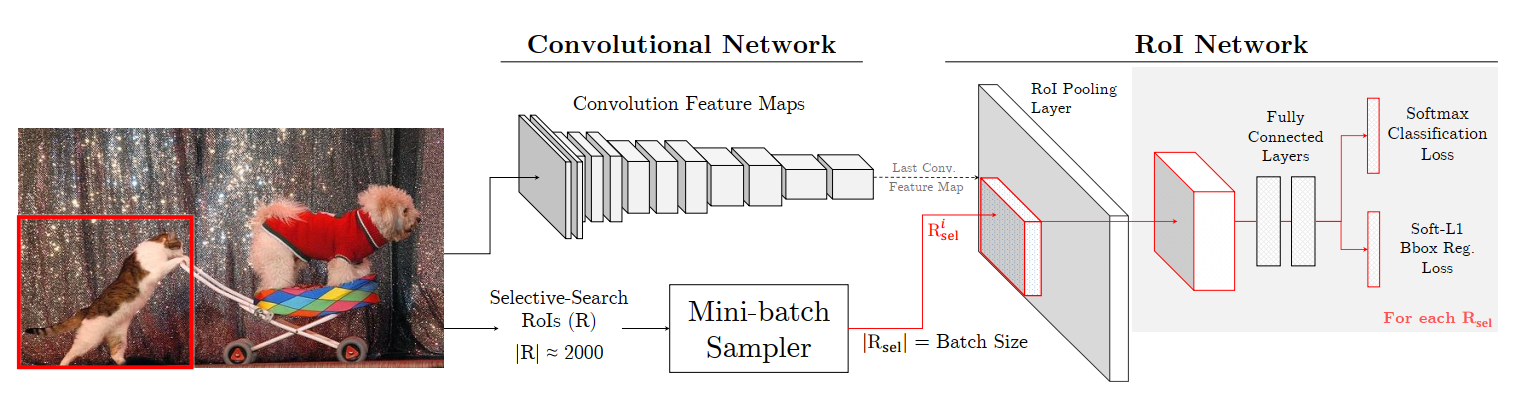

Fast R-CNN(上图)是使用SGD来优化模型的,每个RoI的损失包括分类损失和回归 损失,其中不断降低分类损失使得模型分类更准确,不断降低回归损失使得 预测标注框更准确。
SGD是以mini-batch为单位来更新模型的。对于每个mini-batch,先从数据 集中取N张,然后每张图片采样B/N个RoIs
1. Foreground RoIs
一个RoIs怎样才算作一个目标RoI(也就是含有目标的RoI)呢,在R-CNN, SPPnet, and MR-CNN等把RoI与真实框的交叉比(IOU)大于等于0.5即判定 为目标RoI,在本文中也是这样的设置
2. Background RoIs
而如果要被判定为背景RoI,则要求该RoI与真实框的交叉比大于等于 bg_lo这个阈值并且小于0.5。虽然这样的设置能加快收敛和检测准确度, 但这样的设置会忽略不怎么出现但又十分重要的比较难分辨的背景。因 此,在本文的OHTM方法中,作者去掉了这样的设置。
3. Balancing fg-bg RoIs
为了解决目标框和背景框之间的不平衡,Fast R-CNN设置在一个 mini-batch中,它们之间的比例是1:3。作者发现,这样的一个比例对 于Fast R-CNN的性能是十分重要的,增大或者减小这个比例,都会使模 型的性能有所下降,但使用OHEM便可以把这个比例值去掉。
(二)实现方式 1
直接修改损失层,然后直接进行 hard example selection。损失层计算所有的 RoIs,然后按损失从大到小排序,当然这里有个 NMS(非最大值抑制) 操作,选择 hard RoIs 并 non-hard RoIs 的损失置0。虽然这方法很直接,
但效率是低下的,不仅要为所有 RoI 分配内存,还要对所有 RoI 进行反向传播,即使有些 RoI 损失为0。
(三)实现方式 2
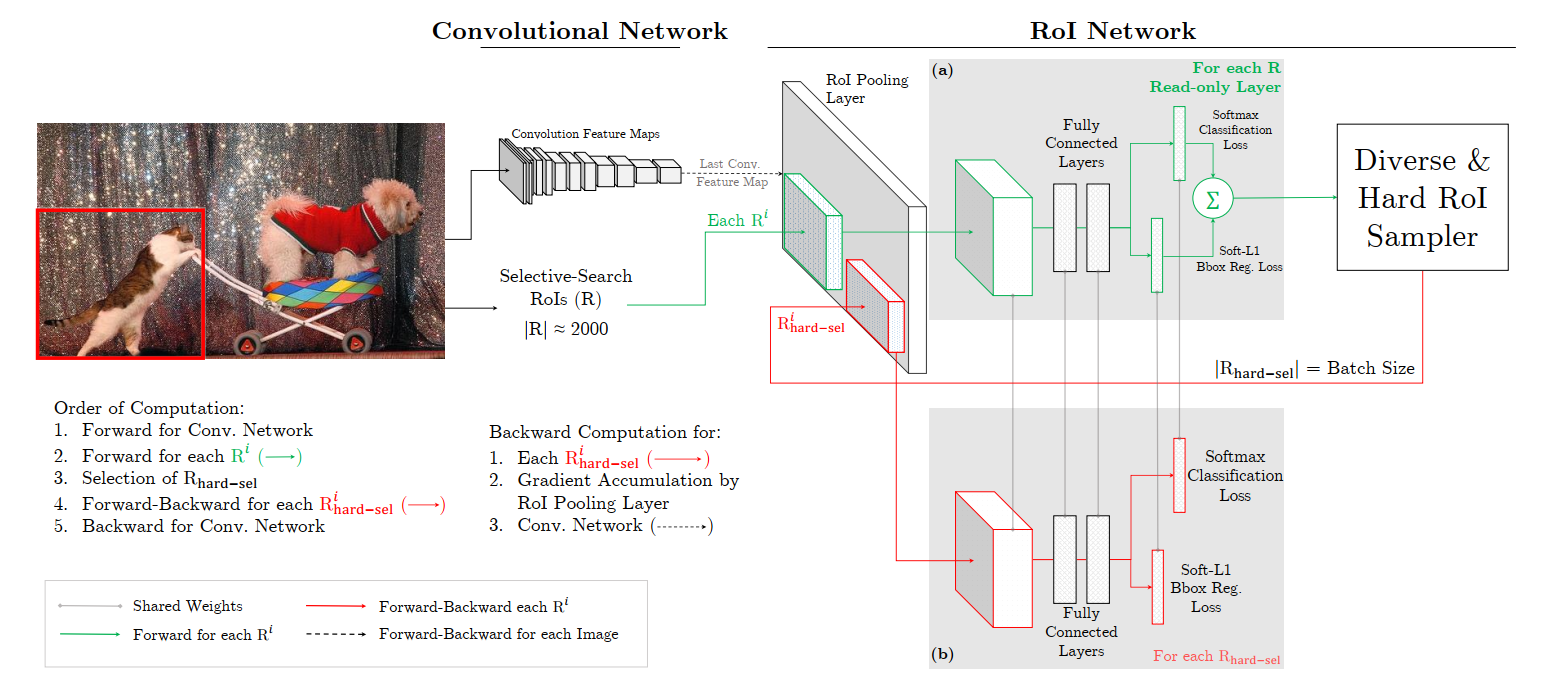
对于方法 1 的缺点很明显,我们还有更好的一种实现方式。作者提出了上面这样的架构。这个架构有两个相同的 RoI 网络,不同的是其中一个只可读,另一个可读可写。我们看到(a) 是只可读的,只对所有 RoI 做前向计算,所以只需分配内存给前向计算 操作,(b) 既可读也可写,对被选择的 hard RoIs 不仅做前向计算也做反向传播计算。
对于一次 SGD 迭代,计算过程如下:先计算出特征图,可读 RoI 网络对所有 RoI 执行前向计算并计算每个 RoI 的损失,然后选择 hard RoIs。把这些 hard RoIs 输入到可读可写的 RoI 网络中执行前向前向计算和反向传播更新网络,并把可读可写的 RoI 网络的参数赋值给只可读的网络,一次迭代就完成了。
这个方式和第一种方式在内存空间是差不多的,但第二种方式的速度快 了两倍。
参考链接:
https://arxiv.org/pdf/1604.03540.pdf
https://zhuanlan.zhihu.com/p/58162337
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/139111.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
