大家好,又见面了,我是你们的朋友全栈君。
Training Region-based Object Detectors with Online Hard Example Mining
00 Astract
摘要主要讲了四点:
(1) 训练过程需要进行参数的空间搜索
(2) 简单样本与难分辨样本之间的类别不平衡是亟需解决的问题
(3) 自动地选择难分辨样本来进行训练不仅效率高而且性能好
(4) 提出了OHEM算法,不仅效率高而且性能好,在各种数据集上表现优越
01 Introduction
(1) 分类器
由于目标检测套用图像分类的分类思想,但图像分类的数据集和目标检测的 数据集存在天然的差距,目标检测的目标框和背景框之间存在严重的不平衡
在滑动窗口检测器尤为严重,在DPM中甚至达到1:100,000,虽然在其他 检测器中有所减缓,但依然高达1:70
(2) hard negative mining
当然,这个类别不平衡问题并不是新问题,之前有个hard nagetive mining的 算法是解决这个类别不平衡问题的,它的关键思想是逐渐地增加分辨错误的样本。这个算法需要迭代地交替训练,用样本集更新模型,然后再固定模型 来选择分辨错的目标框并加入到样本集中在传统目标检测中,用SVM做分 类器也用到hard negative mining这个算法来训练;在一些浅层的神经网络和 提升决策树中也用hard negative mining来进行训练。除此之外,使用深度学习的目标检测算法也用到了hard negative mining
(3) why current state-of-the-art object detectors do not use hard negative mining?
那为什么不用hard negative mining,这主要是技术上的难度,hard negative mining需要交替地训练,而这对于使用线上优化的算法来说是不可能的,例如SGD(随机梯度下降算法)。使用SGD来训练网络需要上万次更新网络,如果每迭代几次就固定模型一次,这样的速度会慢得不可想象
(4) online hard example mining(OHEM)
那OHEM是怎样解决类别不平衡的呢,OHEM是选择损失较大的候选ROI, 具体为什么选择损失较大的候选ROI,这个后面再仔细说
作者总结了一下,使用了OHEM之后,不仅避免了启发式搜索超参数,而且 提高了mAP。作者发现,训练集越大越困难,OHEM的效果就越好
02 Related work
我们来回顾一下相关的工作
(1) Hard example mining
a. SVMs
优化SVMs时,维持一个工作样本集。交替训练,先训练模型收敛于当前的 工作集,然后固定模型,去除简单样本(能够轻易区分的),添加困难样本(不 能够区分的),这样的训练方式 能使模型达到全局最优
b. non-SVMs
除了优化SVMs类的模型,也优化非SVMs类的模型,例如浅层神经网络和提升决策树
(2) ConvNet-based object detection
基于卷积网络的检测模型已经得到了很大的发展,例如R-CNN、OverFeat。 OverFeat是基于滑动窗口的检测模型,R-CNN是基于选择性搜索的检测模型。 除此之外,还有Fast R-CNN,作者的研究工作就是在Fast R-CNN上展开的
(3) Hard example selection in deep learning
在深度学习方面相关的研究工作有三篇论文,这三篇论文的关注点在于图像分类或者图像识别,而OHEM关注点在目标检测
03 Overview of Fast R-CNN
我们回顾一下Fast R-CNN网络框架,如下图
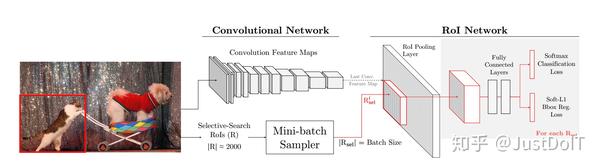

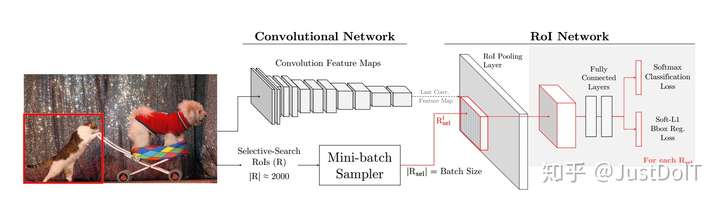
(1) framework
图片和候选框做为Fast R-CNN的输入,Fast R-CNN分为两部分,一部分是卷 积网络,包括卷积和池化层,另一部分是RoI网路,包括RoI池化层、全连接层和两个损失层(一个是分类,一个检测框回归)
(2) inference
在测试的时候,图片输入到卷积网络得到特征层,选择性搜索算法得到RoIs, 对于每个RoI,得到其对应的特征向量,然后每个特征向量输入到全连接层 并得到两个输出,一个是概率,一个检测框的坐标
(3) 那为什么选择Fast R-CNN做为基础的目标检测器呢?
作者给出了几点原因:
a. more broadly applicable
Fast R-CNN由两部分组成,一是卷积网络,二是RoI网络,而这种结构也 被其他的检测模型沿用,例如SPPnet 和 MR-CNN
b. allow for training the entire conv network
虽然Fast R-CNN和SPPnet、MR-CNN在结构上相似,但Fast R-CNN允许 更新整个卷积网络,而SPPnet、MR-CNN却固定住卷积网络
c. SVM or not
SPPnet、MR-CNN使用SVM做分类器,Fast R-CNN不使用SVM
(4) How it trains
Fast R-CNN是使用SGD来优化模型的,每个RoI的损失包括分类损失和回归 损失,其中不断降低分类损失使得模型分类更准确,不断降低回归损失使得 预测标注框更准确。
SGD是以mini-batch为单位来更新模型的。对于每个mini-batch,先从数据 集中取N张,然后每张图片采样B/N个RoIs
a. Foreground RoIs
一个RoIs怎样才算作一个目标RoI(也就是含有目标的RoI)呢,在R-CNN, SPPnet, and MR-CNN等把RoI与真实框的交叉比(IOU)大于等于0.5即判定 为目标RoI,在本文中也是这样的设置
b. Background RoIs
而如果要被判定为背景RoI,则要求该RoI与真实框的交叉比大于等于 bg_lo这个阈值并且小于0.5。虽然这样的设置能加快收敛和检测准确度, 但这样的设置会忽略不怎么出现但又十分重要的比较难分辨的背景。因 此,在本文的OHTM方法中,作者去掉了这样的设置。
c. Balancing fg-bg RoIs
为了解决目标框和背景框之间的不平衡,Fast R-CNN设置在一个 mini-batch中,它们之间的比例是1:3。作者发现,这样的一个比例对 于Fast R-CNN的性能是十分重要的,增大或者减小这个比例,都会使模 型的性能有所下降,但使用OHEM便可以把这个比例值去掉。
04 Our approach
作者认为Fast R-CNN之前选择RoI的方法不仅效率低而且也不是最优的,于是作者提出了OHEM,OHEM不仅效率高而且性能也更优
(1) Online hard example mining
我们知道,基于SVM的检测器,在训练时,使用hard example mining来选 择样本需要交替训练,先固定模型,选择样本,然后再用样本集更新模型, 这样反复交替训练直到模型收敛
a. main observation
作者认为可以把交替训练的步骤和SGD结合起来。之所以可以这样,作 者认为虽然SGD每迭代一次只用到少量的图片,但每张图片都包含上千 个RoI,可以从中选择hard examples,这样的策略可以只在一个mini-batch
中固定模型,因此模型参数是一直在更新的。
更具体的,在第t次迭代时,输入图片到卷积网络中得到特征图,然后 把特征图和所有的RoIs输入到RoI网络中并计算所有RoIs的损失,把损 失从高到低排序,然后选择B/N个RoIs。这里有个小问题,位置上相邻 的RoIs通过RoI网络后会输出相近的损失,这样损失就翻倍。作者为了 解决这个问题,使用了NMS(非最大值抑制)算法,先把损失按高到低排 序,然后选择最高的损失,并计算其他RoI这个RoI的IoU(交叉比),移 除IoU大于一定阈值的RoI,然后反复上述流程直到选择了B/N个RoIs。
(2) Implementation details
how to implement OHEM in the FRCN detector
主要有两种方法
a. An obvious way
直接修改损失层,然后直接进行hard example selection。损失层计算所 有的RoIs,然后按损失从大到小排序,当然这里有个NMS(非最大值抑制) 操作,选择hard RoIs并non-hard RoIs的损失置0。虽然这方法很直接,
但效率是低下的,不仅要为所有RoI分配内存,还要对所有RoI进行反向 传播,即使有些RoI损失为0。
b. A better way
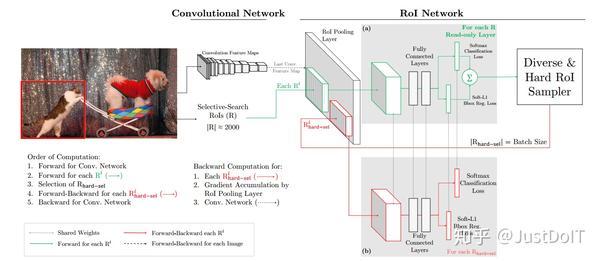
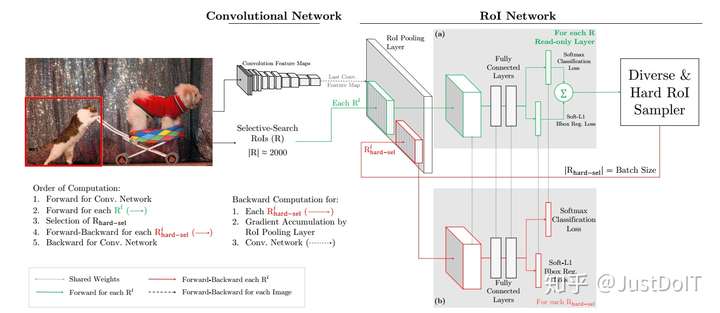
为了解决这个问题,作者提出了上面这样的架构。这个架构有两个相同 的RoI网络,不同的是其中一个只可读,另一个可读可写。我们看到(a) 是只可读的,只对所有RoI做前向计算,所以只需分配内存给前向计算 操作,(b)既可读也可写,对被选择的hard RoIs不仅做前向计算也做反向 传播计算。
对于一次SGD迭代,计算过程如下:先计算出特征图,可读RoI网络对所 有RoI执行前向计算并计算每个RoI的损失,然后选择hard RoIs。把这 些hard RoIs输入到可读可写的RoI网络中执行前向前向计算和反向传播更新网络,并把可读可写的RoI网络的参数赋值给只可读的网络,一次 迭代就完成了。
这个方式和第一种方式在内存空间是差不多的,但第二种方式的速度快 了两倍。
05 Analyzing online hard example mining
(1) Experimental setup
在本文的实验中使用两种标准的卷积网络,一种是VGG_CNN_M_1024,另一 种是VGG16。论文实验使用的超参数沿用Fast R-CNN的默认设置。
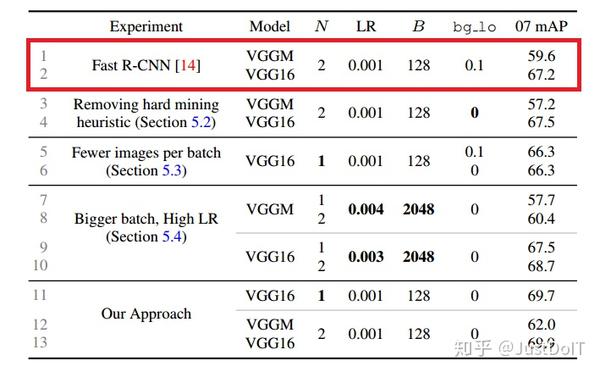
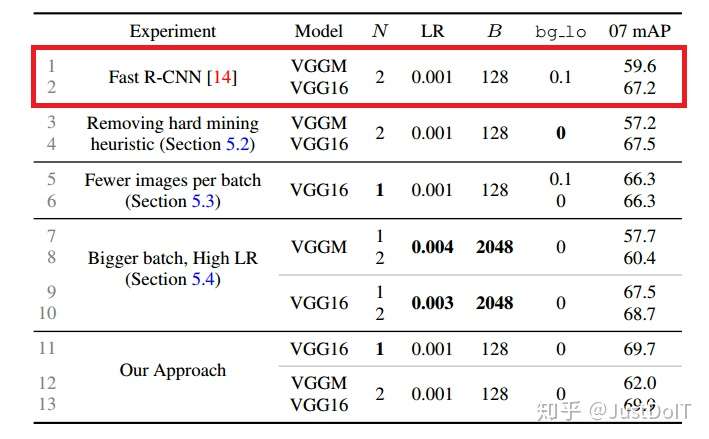
(2) OHEM vs. heuristic sampling
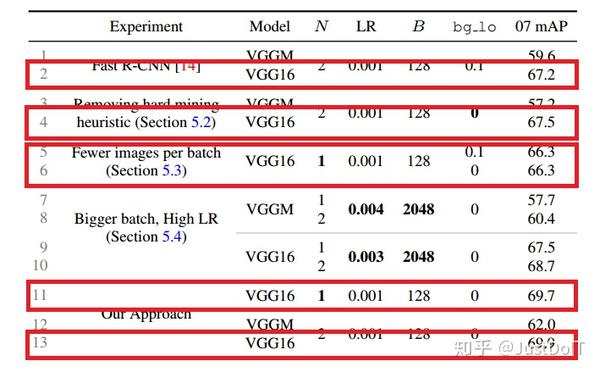
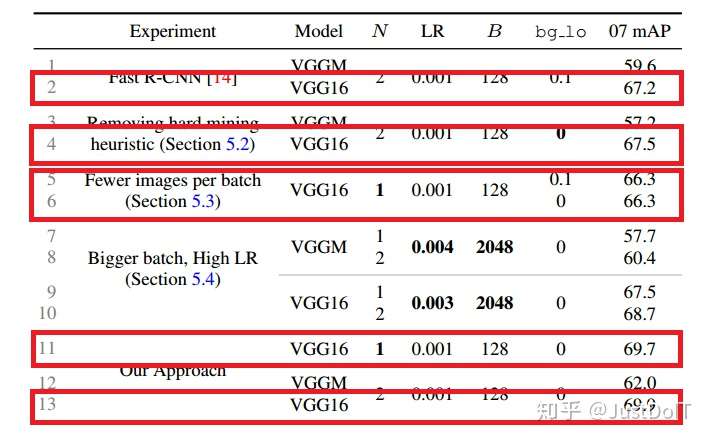
为了检验hard example mining的重要性,我们做了两组实验,一组Fast R-CNN 带有hard example mining,bg_lo=0.1,另一组没有hard example mining,即 bg_lo=0。我们发现,对于VGGM网络,mAP降低2.4点,VGG16基本没变 化。而使用OHEM,相对于使用了hard example mining的Fast R-CNN,mAP 提高了2.4点,相对于没有使用hard example mining的Fast R-CNN,mAP提 高了4.8点。
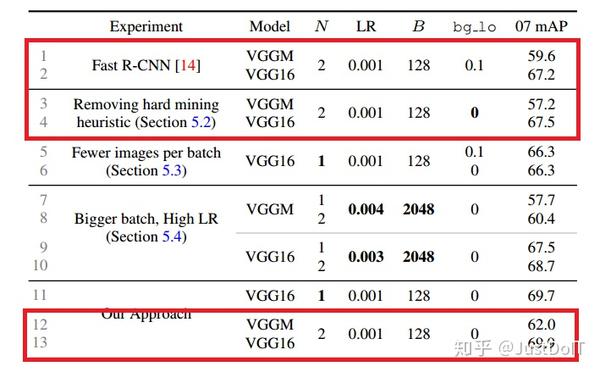
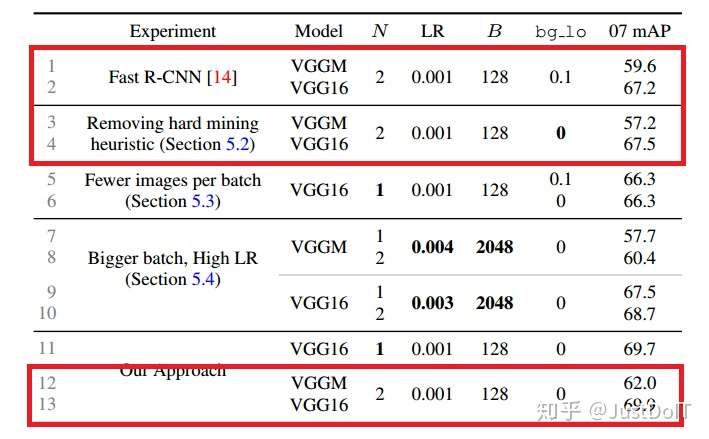
(3) Robust gradient estimates
而在实验中,存在一个这样的疑虑,每个mini-batch只取两张图片会不会造 成梯度不稳定和收敛慢,因为在一张图片中选择RoI会使RoIs之间的相关性 很大。Fast R-CNN的作者认为在训练过程不存在这样的问题,而在OHEM中,
由于是在一张图片中选择损失大的RoI,这样可能造成RoIs之间的相关性更 大。为了解答这个疑虑,我们把N设置为1,通过做实验发现,传统的Fast R-CNN大概降低一个点,而OHEM却没有太大变化,这说明使用了OHEM的
Fast R-CNN是鲁棒的。
(4) Why just hard examples, when you can use all?
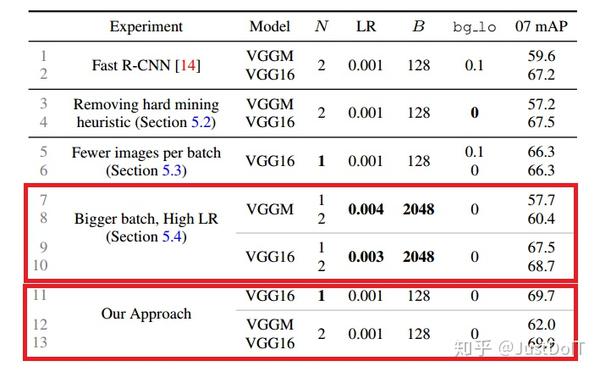
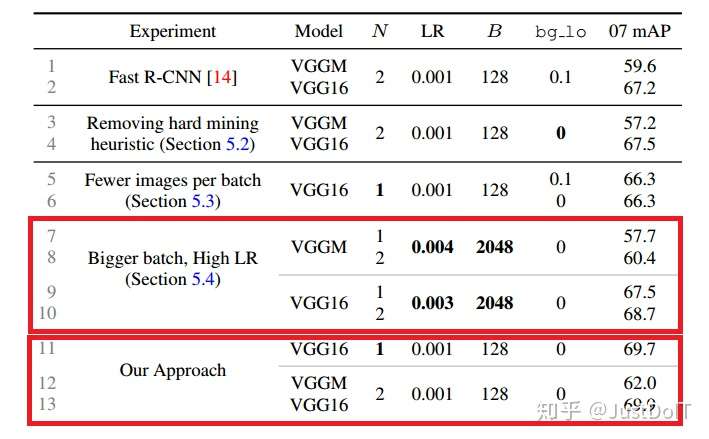
那为什么只选择hard examples呢,因为easy examples的损失很小,对梯度 影响很小。为了用事实说话,作者做了一个这样的实验,把mini-batch的B 分别设置为128和2048,结果表明,B为2048的相对于128的,mAP提高 了一个点。不过,这提高的一个点对于使用了OHEM的Fast R-CNN来说是无 关紧要的,因为OHEM的mAP提高更大,并且用更小的mini-batch收敛速 度会更快。
(5) Better optimization
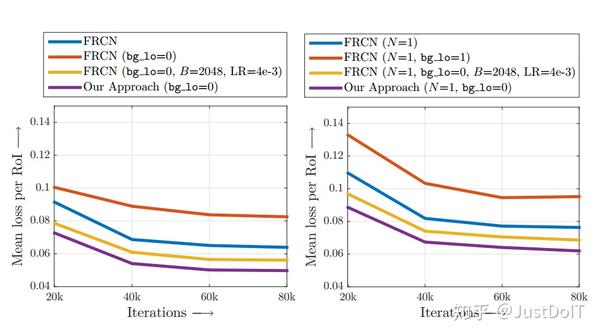
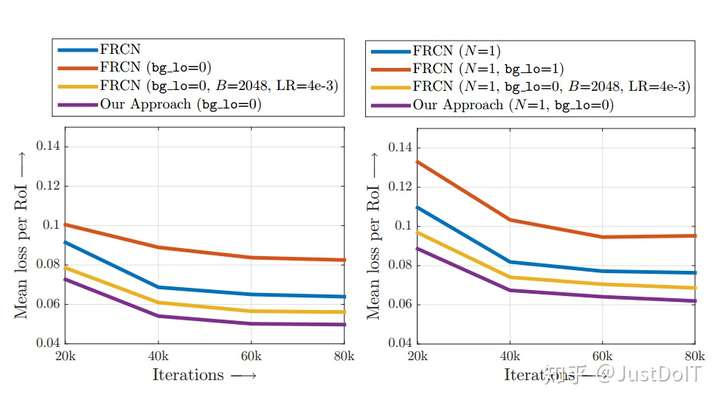
作者为了分析使用了不同训练方法的Fast R-CNN的训练损失的情况,做了这 样的实验,每优化20K步就记录一下所有RoIs的平均损失,结果显示, bg_lo=0(即没有使用hard example mining)的训练损失最高,bg_lo=0.1(使用 hard example mining)的损失有所降低,增大mini-batch(即设置bg_lo=0, B=2048),损失更低,最后,使用了OHEM的Fast R-CNN损失最低,这表明 Fast R-CNN使用了OHEM会训练得更好。
(6) Computational cost
使用了OHEM的Fast R-CNN相对于没有使用OHEM的Fast R-CNN在内存和每 迭代一次所花的时间都有所增加,不过,作者认为这一点增加影响不大。
06 Conclusion
(1) 简化训练过程
(2) 更好的训练收敛和检测准确度的提高
转载于:https://www.cnblogs.com/leebxo/p/10834995.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/139007.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
