大家好,又见面了,我是你们的朋友全栈君。
卷积神经网络是除了全连接神经网络以外另一个常用的网络结果,其在图像识别方面表现十分突出。本文结合Tensorflow:实战Google深度学习框架,讲述卷积神经网络常用数据集,介绍卷积网络的结构思想,以及通过TensorFlow实现其设计。
1 图像识别数据集
MNIST手写体识别数据集解决是一个相对简单的问题,而对于更加复杂的类别,可以用到CIFAR数据集。比如CIFAR10数据集收集了来自10个不同种类的6万张图片,每张图片像素为32×32,如下图

CIFAR10数据集与MNIST相似之处在于,其每张图片大小都是一定的,每张图片中都只包含一个类别。区别在于CIFAR10中的图片都是彩色的,而且分类难度也比MNIST高,人工标注的正确率约为94%。
在现实生活中,图片的格式不一定都是恒定的,类别也远超出10种,每张图片也会包含多个元素,因此需要有更强大的数据集。
由斯坦福大学的李飞飞开发的ImageNet,有近1500万张图片,关联了大概20000个类别。
ImageNet每年都会举办图像识别竞赛ILSVRC(现已停办),每年的比赛都提供不同的数据集。下图给出不同算法在ImageNet图像分类上的top-5正确率,ton-N表示算法给出的前N个答案中有一个是正确的,2013年之后基本上所有的研究都集中在卷积神经网络上。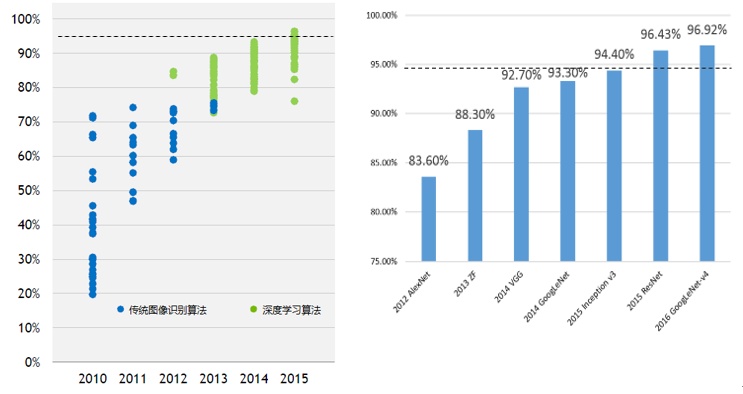
2 卷积神经网络简介
深度神经网络有多种,主要有全连接层神经网络,卷积神经网络和循环神经网络。其中全连接层神经网络之前已有介绍,其相邻层的节点之间都会相连。循环神经网络将会在后续的章节介绍,以下简单说一下卷积神经网络。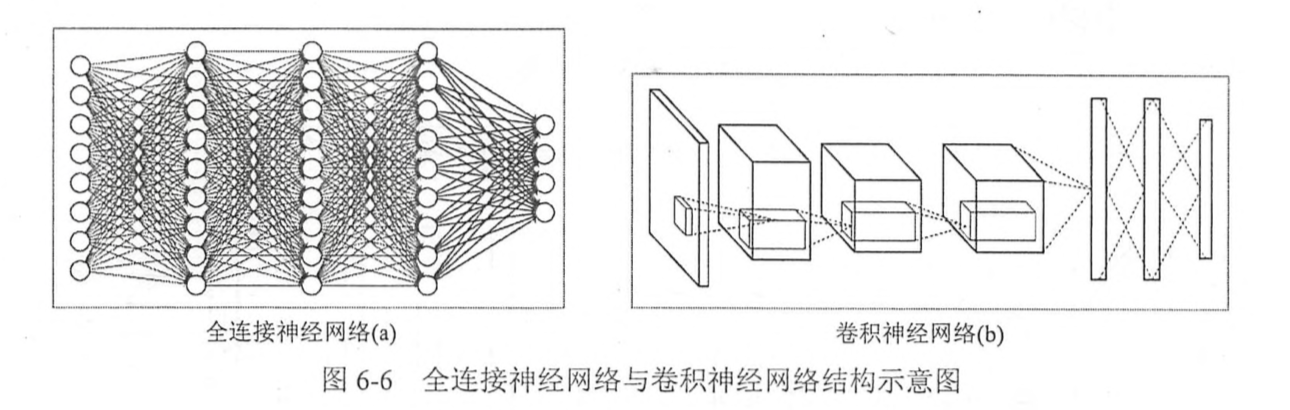
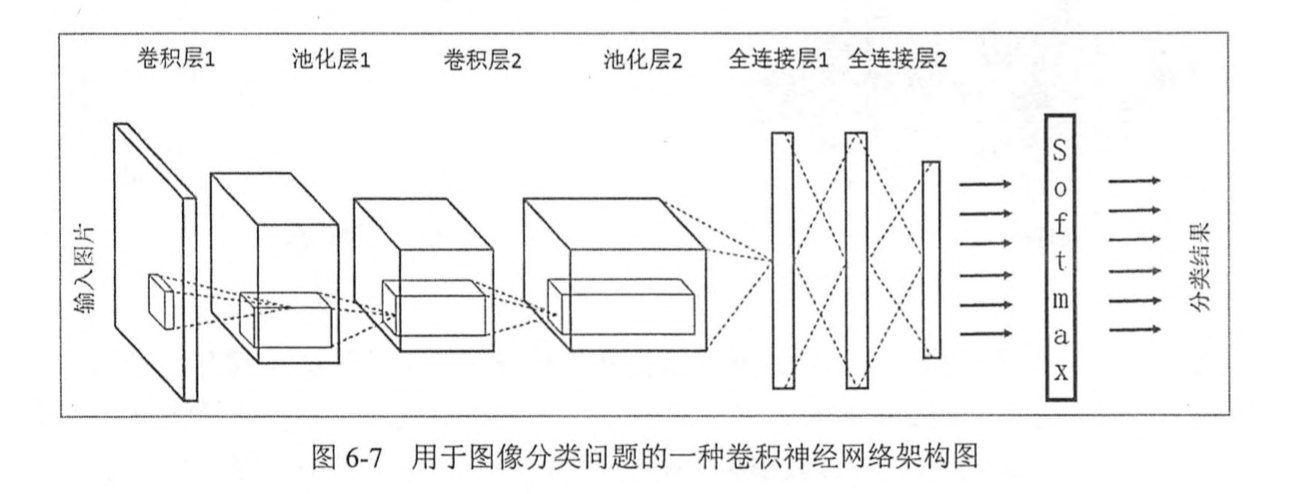
上图是卷积神经网络的架构图,输入的图片一般会经过多个卷积层和池化层后,再接上数个全连接层后,通过softmax输出结果。下边着重介绍输入图片格式、卷积层和池化层的概念。
输入图片
输入的图片一般为其像素矩阵,如果图片为黑白,则其只有1个通道,其像素矩阵为长X宽。如果图片为彩色,则一般表示为RGB格式,因此有3个通道,其像素矩阵是一个三维矩阵,大小为长X宽X3。
卷积层
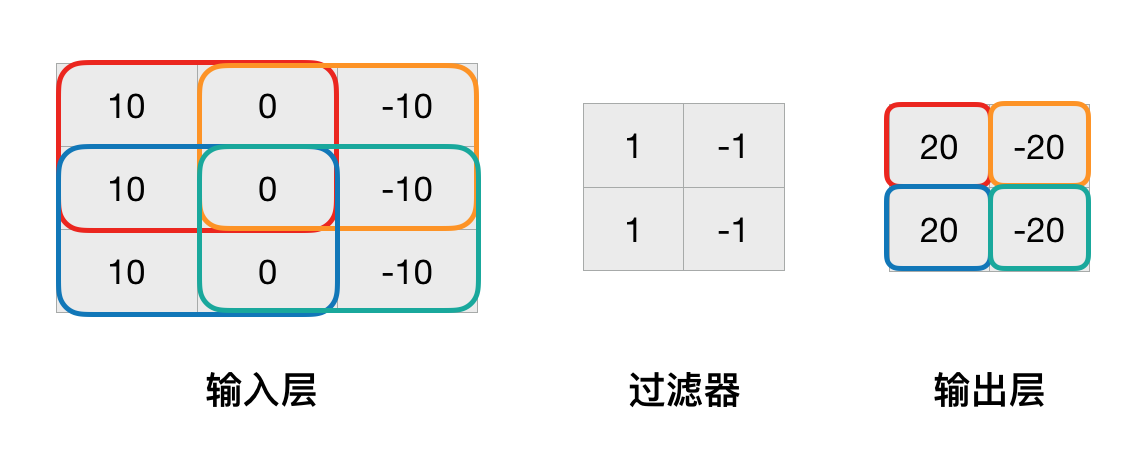
在上图中,输入层是一个3X3矩阵。中间的过滤器是卷积过程中最重要的部分。在构建卷积神经网络时,过滤器的尺寸大小需要手动指定,而过滤器中的值则是需要优化的部分。此处我们指定了过滤器大小为2X2,其中的4个值分别为1,1,-1,-1。
接下来我们来看看卷积如何进行的,首先将过滤器放置在输入层的左上角,也就是红色的2X2方框中。之后将输入层的2X2共四个数字与过滤器中的四个数字分别对应相乘,然后相加,得到的输出层的第一个输出结果:1×10+0x(-1)+1×10+0x(-1)=20。之后将过滤器向右平移一个元素,再次计算得到第二个结果:0x10+10x(-1)+0x10+10x(-1)=-20。
然后分别将过滤器分别放在输入层的左下角和右下角,得到剩下的两个结果。
以上就是卷积神经网络网络的核心过程。但是依然有几个地方需要说明。
过滤器的尺寸一般为3×3或5×5,这个是人工指定的。对于RGB图像,因为其像素矩阵是三维的,因此过滤器也是三维的,也就是3x3x3或5x5x3。每个过滤器还可以添加一个偏置项,因此对于RGB图像,每个过滤器的参数为3x3x3+1=28个或5x5x3+1=76个。
除了过滤器的长宽,需要手动指定的另一个参数是输出节点的深度。如上图所示每一个过滤器都只会输出一层二维的节点。因此指定过滤器的层数就是指定了输出的层数。
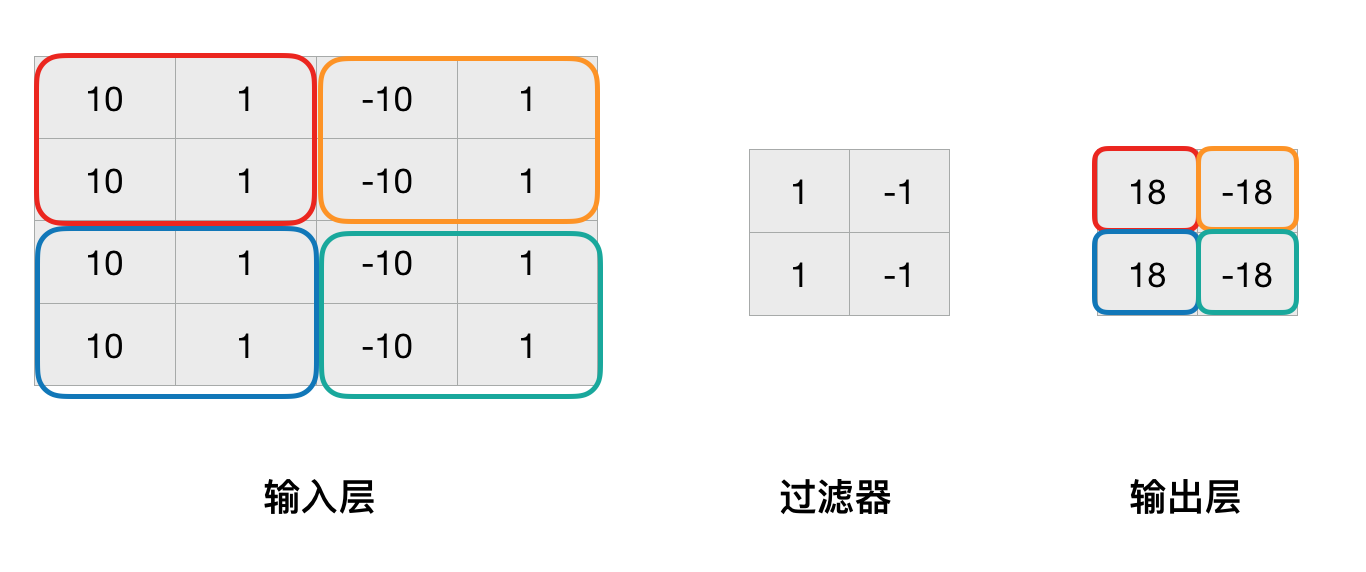
另一个可以手动设置的参数是过滤器的步长stride。在最开始的图中,过滤器设定的步长是1。而在上图中,设定的步长是2。
由以上分析可以看到,输出层的尺寸是比输入层要少的。当卷积的层数越来越多,输出的尺寸就会越来越少,这样对我们的结果是不利的。我们希望的是输出的尺寸不会随着卷积的层数的增加而变化。因此我们可以想法增大输入层的尺寸,其中一种方法就是用0来填充输入层的边界。
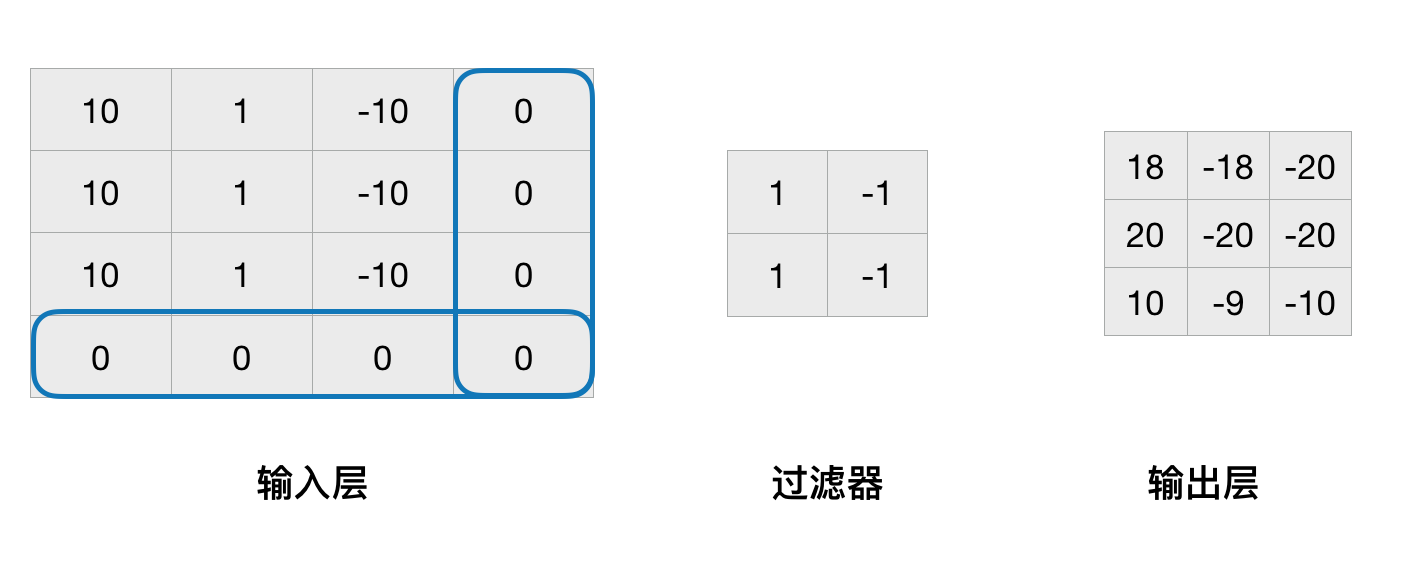
如上图,当3×3的输入层添加了一层0(zero padding)后,再用过滤器卷积后,输出层和输入层已经保持一致。
下边的公式给出了输出层的尺寸和输入层尺寸、过滤器尺寸、步长的关系:
o u t p u t = [ ( i n p u t − f i l t e r + 1 ) / s t r i d e ] output = [(input – filter+1)/stride] output=[(input−filter+1)/stride]
过滤器的作用
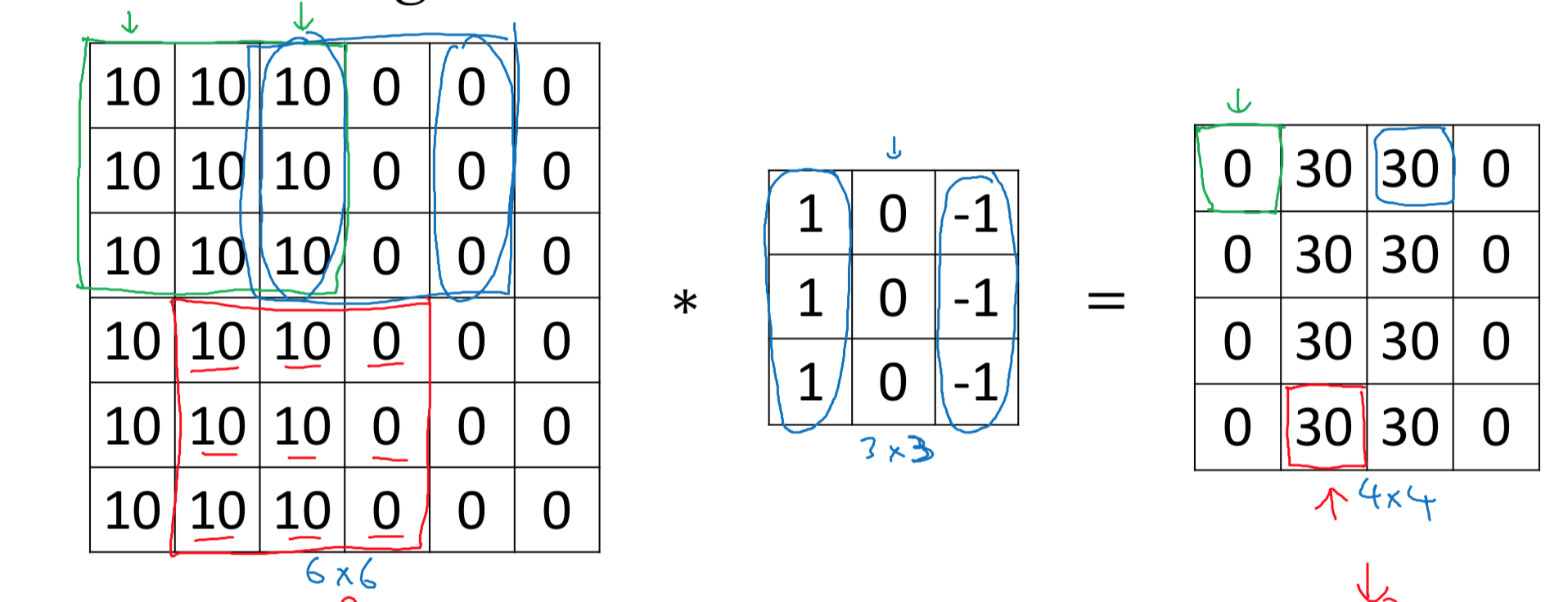
不难发现,图像识别的第一步就是识别边缘。所谓边缘就是图片的像素值发生变化的地方,如果整张图片的像素值没什么变化,那就只不过是一张纯色图片而已。
图片来自https://mooc.study.163.com/learn/2001281004?tid=2001392030&_trace_c_p_k2_=96de2913028e4fceb899982a5d8212c4#/learn/content?type=detail&id=2001729323&cid=2001725119
上图显示了一个过滤器如何在扫描图片之后获得图片的边缘。根据图片的像素值可以看到中央有一条垂直的边界。当用对应的过滤器对图片进行卷积操作后,输出层中央对应位置的矩阵数值会增大,数值大的矩阵值在经过激活函数后将更大可能得到保存,因此过滤器能够识别图像的特征。
池化层
除了卷积层,另外一个在卷积神经网络里常用的是池化层。池化层的作用主要是缩小矩阵尺寸,以及有效防止网络过拟合。
池化层的计算比卷积要简单,主要是获得某几个节点的最大值(最大池化层 max pooling)或平均值(平均池化层 average pooling)。
池化层的一些参数,如尺寸,步长,以及是否使用全0填充等于卷积层是一致的。不同之处在于,其一般是二维矩阵,除了在长宽两个节点中移动外,池化过滤器还需要在深度这个维度上移动。以下是池化的计算例子。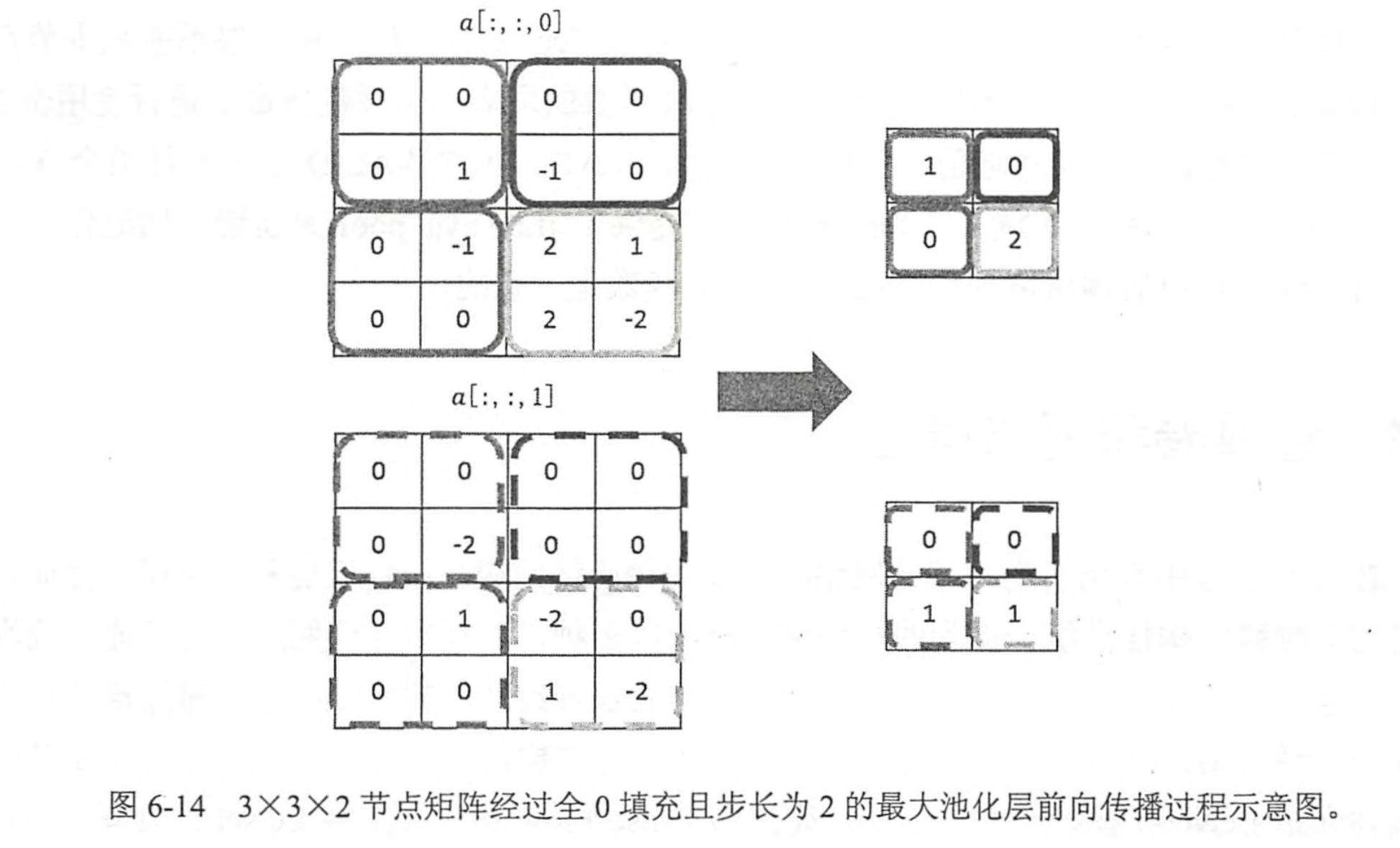
以下是一个利用tensorflow使用卷积层和池化层的简单例子:
import tensorflow as tf
import numpy as np
M = np.array([
[[1],[-1],[0]],
[[-1],[2],[1]],
[[0],[2],[-2]]
])
M = np.asarray(M,dtype='float32')
M = M.reshape(1,3,3,1)
x = tf.placeholder('float32',[1,None,None,1])
filter_weight = tf.get_variable('weights',[2,2,1,1],initializer=tf.constant_initializer([[1,-1],[0,2]]))
biases = tf.get_variable('bias',[1],initializer=tf.constant_initializer(1))
#当padding设置为VALID时,输入矩阵是保持原样的,因此输出矩阵尺寸比输入矩阵小
#当padding设置为SAME时,输入矩阵会进行0填充,使输出矩阵尺寸与输入矩阵保持一致。
conv = tf.nn.conv2d(x,filter_weight,strides=[1,1,1,1,],padding="SAME")
bias = tf.nn.bias_add(conv,biases)
pool = tf.nn.max_pool(bias,ksize=[1,2,2,1],strides=[1,1,1,1],padding="SAME")
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
conv_result = sess.run(conv,feed_dict={
x:M})
pool_result = sess.run(pool,feed_dict={
x:M})
print(conv_result.reshape(3,3))
print(pool_result.reshape(3,3))
经典卷积神经网络模型:LeNet-5
LeNet-5是第一个成功应用于数字识别的神经网络,在MNIST数据集上,LeNet-5可以达到99.2%的正确率。模型共有7层,下边介绍一下每层结构。
1.卷积层
第一层的输入就是图像的像素矩阵,为32x32x1。第一层过滤器尺寸为5×5,深度为6,不使用0填充,步长为1。因此输出的长宽为32-5+1=28。输出的尺寸为28x28x6。每一个过滤器有5×5+1个参数,其中1为偏置项,因此此层参数共有(5×5+1)x6=156个参数。
2.池化层
这一层的输入为上一层的输出:28x28x6。过滤器大小为2×2,长宽步长均为2,所以输出矩阵为14x14x6。
3.卷积层
本层输入矩阵为14x14x6,过滤器大小为5×5,深度为16。不使用全0填充,步长为1。因此输出为10x10x16。参数个数为(5x5x6+1)x16=2416个。
4.池化层
本层输入矩阵为10x10x16。过滤器大小为2×2,步长为2。输出为5x5x16。
5.全连接层
本层输入矩阵大小为5x5x16,在输入时会被组合成1列向量,输出节点为120个。因此参数个数为5x5x16x120+120=48120个参数。
6.全连接层
本层输入节点个数120,输出节点84个,参数总数为120×84+84=10164
7.全连接层
本层输入节点个数为84,输出节点为10个,参数为84×10+10=850个。
以下是Le-Net5的实现代码:
import tensorflow as tf
import numpy as np
INPUT_NODE = 784
OUTPUT_NODE = 10
IMAGE_SIZE = 28
NUM_CHANNELS = 1
NUM_LABELS = 10
CONV1_DEEP = 32
CONV1_SIZE = 5
CONV2_DEEP = 64
CONV2_SIZE = 5
FC_SIZE = 512
REGULARIZATION_RATE = 0.0001
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.01
LEARNING_RATE_DECAY = 0.99
REGULARIZATION_RATE = 0.0001
TRAINING_STEPS = 6000
def inference(input_tensor):#Le-Net5的结构
with tf.variable_scope("layer1-conv"):
conv1_weight = tf.get_variable('weight',[CONV1_SIZE,CONV1_SIZE,NUM_CHANNELS,CONV1_DEEP],
initializer = tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable("bias",CONV1_DEEP,initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(input_tensor,conv1_weight,strides=[1,1,1,1],padding="SAME")
relu1 = tf.nn.relu(tf.nn.bias_add(conv1,conv1_biases))
with tf.variable_scope("layer2-pool"):
pool1 = tf.nn.max_pool(relu1,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME")
with tf.variable_scope("layer3-conv"):
conv2_weight = tf.get_variable('weight',[CONV2_SIZE,CONV2_SIZE,CONV1_DEEP,CONV2_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable('bias',CONV2_DEEP,initializer=tf.constant_initializer(0))
conv2 = tf.nn.conv2d(pool1,conv2_weight,strides=[1,1,1,1],padding="SAME")
relu2 = tf.nn.relu(tf.nn.bias_add(conv2,conv2_biases))
with tf.variable_scope("layer4-pool"):
pool2 = tf.nn.max_pool(relu2,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME")
pool2_shape = pool2.get_shape().as_list()
node = pool2_shape[1] * pool2_shape[2] * pool2_shape[3]
reshape = tf.reshape(pool2,[pool2_shape[0],node])
with tf.variable_scope("layer5-fc1"):
fc1_weights = tf.get_variable("weight",[node,FC_SIZE],initializer=tf.truncated_normal_initializer(stddev=0.1))
tf.add_to_collection('losses',tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)(fc1_weights))
fc1_biases = tf.get_variable("bias",[FC_SIZE],initializer=tf.constant_initializer(0.1))
fc1 = tf.nn.relu(tf.matmul(reshape,fc1_weights) + fc1_biases)
fc1 = tf.nn.dropout(fc1,0.5)
with tf.variable_scope("layer6-fc2"):
fc2_weights = tf.get_variable("weight",[FC_SIZE,NUM_LABELS],initializer=tf.truncated_normal_initializer(stddev=0.1))
tf.add_to_collection("losses",tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)(fc2_weights))
fc2_biases = tf.get_variable("bias",[NUM_LABELS],initializer=tf.constant_initializer(0.1))
logit = tf.nn.relu(tf.matmul(fc1,fc2_weights) + fc2_biases)
return logit
def train(mnist):
x = tf.placeholder(tf.float32,[BATCH_SIZE,IMAGE_SIZE,IMAGE_SIZE,NUM_CHANNELS],name='x-input')
y_= tf.placeholder(tf.float32,[None,OUTPUT_NODE],name='y-input')
y = inference(x)
global_step = tf.Variable(0,trainable=False)
cross_entropy_mean = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(y_,1)))
loss = cross_entropy_mean + tf.add_n(tf.get_collection("losses"))
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,mnist.train.num_examples/BATCH_SIZE,
LEARNING_RATE_DECAY,staircase = False)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step)
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
xs,ys = mnist.train.next_batch(BATCH_SIZE)
reshape = np.reshape(xs,[BATCH_SIZE,IMAGE_SIZE,IMAGE_SIZE,NUM_CHANNELS])
test_reshape = np.reshape(mnist.test.images,[10000,IMAGE_SIZE,IMAGE_SIZE,NUM_CHANNELS])
test_feed = {
x:test_reshape,y_:mnist.test.labels}
for i in range(TRAINING_STEPS):
losses = sess.run(loss,feed_dict={
x:reshape,y_:ys})
if i%1000==0:
print("accruacy after %d step is %f"%(i,losses))
总结
本文主要介绍了卷积神经网络的基本知识,包括其结构,在tensorflow中的用法,还展示了一个用tensorflow搭建的基本模型Le-Net5。
近几年卷积神经网络在图片识别中大展拳脚,然而这些网络与Le-Net5相比层数更多,参数更多,需要更多的图片来训练,训练的时长也需要数天至数周不等。因此如果要利用这些模型来解决自己的问题,就要利用迁移学习,迁移学习的用法将会在以后介绍。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/138881.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
