大家好,又见面了,我是你们的朋友全栈君。
大家好,我是辣条。
上次整理的爬虫教程反响不错,但是还是有小伙伴表示不够细致,今天带来了升级版,全文很长,建议先收藏下来。
目录
scrapy_redis原理分析并实现断点续爬以及分布式爬虫


一、爬虫基础
爬虫概述
知识点:
-
了解 爬虫的概念
-
了解 爬虫的作用
-
了解 爬虫的分类
-
掌握 爬虫的流程
1. 爬虫的概念
模拟浏览器,发送请求,获取响应
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟客户端(主要指浏览器)发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
-
原则上,只要是客户端(浏览器)能做的事情,爬虫都能够做
-
爬虫也只能获取客户端(浏览器)所展示出来的数据
知识点:了解爬虫的概念
2. 爬虫的作用
爬虫在互联网世界中有很多的作用,一句话总结就是抓取网站上的信息。
知识点:了解 爬虫的作用
3. 爬虫的分类
3.1 根据被爬取网站的数量不同,可以分为:
-
通用爬虫,如 搜索引擎
-
聚焦爬虫,如12306抢票,或专门抓取某一个(某一类)网站数据
3.2 根据是否以获取数据为目的,可以分为:
-
功能性爬虫,给你喜欢的明星投票、点赞
-
数据增量爬虫,比如招聘信息
3.3 根据url地址和对应的页面内容是否改变,数据增量爬虫可以分为:
-
基于url地址变化、内容也随之变化的数据增量爬虫
-
url地址不变、内容变化的数据增量爬虫
知识点:了解 爬虫的分类
4. 爬虫的流程
爬虫的基本流程如下所示
-
获取一个url
-
向url发送请求,并获取响应(需要http协议)
-
如果从响应中提取url,则继续发送请求获取响应
-
如果从响应中提取数据,则将数据进行保存
知识点:掌握 爬虫的流程
http协议复习
知识点
-
掌握 http以及https的概念和默认端口
-
掌握 爬虫关注的请求头和响应头
-
了解 常见的响应状态码
-
理解 浏览器和爬虫爬取的区别
1. http以及https的概念和区别
HTTPS比HTTP更安全,但是性能更低
-
HTTP:超文本传输协议,默认端口号是80
-
超文本:是指超过文本,不仅限于文本;还包括图片、音频、视频等文件
-
传输协议:是指使用共用约定的固定格式来传递转换成字符串的超文本内容
-
-
HTTPS:HTTP + SSL(安全套接字层),即带有安全套接字层的超本文传输协,默认端口号:443
-
SSL对传输的内容(超文本,也就是请求体或响应体)进行加密
-
-
可以打开浏览器访问一个url,右键检查,点击net work,点选一个url,查看http协议的形式
知识点:掌握 http以及https的概念和默认端口
2. 爬虫特别关注的请求头和响应头
2.1 特别关注的请求头字段
爬虫特别关注以下几个请求头字段
-
Content-Type
-
Host (主机和端口号)
-
Connection (链接类型)
-
Upgrade-Insecure-Requests (升级为HTTPS请求)
-
User-Agent (浏览器名称)
-
Referer (页面跳转处)
-
Cookie (Cookie)
-
Authorization(用于表示HTTP协议中需要认证资源的认证信息,如前边web课程中用于jwt认证)
加粗的请求头为常用请求头,在服务器被用来进行爬虫识别的频率最高,相较于其余的请求头更为重要,但是这里需要注意的是并不意味这其余的不重要,因为有的网站的运维或者开发人员可能剑走偏锋,会使用一些比较不常见的请求头来进行爬虫的甄别
2.2 特别关注的响应头字段
爬虫只关注一个响应头字段
-
Set-Cookie (对方服务器设置cookie到用户浏览器的缓存)
知识点:掌握 爬虫关注的请求头和响应头
3. 常见的响应状态码
-
200:成功
-
302:跳转,新的url在响应的Location头中给出
-
303:浏览器对于POST的响应进行重定向至新的url
-
307:浏览器对于GET的响应重定向至新的url
-
403:资源不可用;服务器理解客户的请求,但拒绝处理它(没有权限)
-
404:找不到该页面
-
500:服务器内部错误
-
503:服务器由于维护或者负载过重未能应答,在响应中可能可能会携带Retry-After响应头;有可能是因为爬虫频繁访问url,使服务器忽视爬虫的请求,最终返回503响应状态码
学习web知识的时候就已经学过了状态码的相关知识,我们知道这是服务器给我的相关反馈,我们在学习的时候就被教育说应该将真实情况反馈给客户端,但是在爬虫中,可能该站点的开发人员或者运维人员为了阻止数据被爬虫轻易获取,可能在状态码上做手脚,也就是说返回的状态码并不一定就是真实情况,比如:服务器已经识别出你是爬虫,但是为了让你疏忽大意,所以照样返回状态码200,但是响应体重并没有数据。
所有的状态码都不可信,一切以是否从抓包得到的响应中获取到数据为准
知识点:了解 常见的响应状态码
4. 浏览器的运行过程
在回顾完http协议后,我们来了解以下浏览器发送http请求的过程
4.1 http请求的过程
-
浏览器在拿到域名对应的ip后,先向地址栏中的url发起请求,并获取响应
-
在返回的响应内容(html)中,会带有css、js、图片等url地址,以及ajax代码,浏览器按照响应内容中的顺序依次发送其他的请求,并获取相应的响应
-
浏览器每获取一个响应就对展示出的结果进行添加(加载),js,css等内容会修改页面的内容,js也可以重新发送请求,获取响应
-
从获取第一个响应并在浏览器中展示,直到最终获取全部响应,并在展示的结果中添加内容或修改————这个过程叫做浏览器的渲染
4.2 注意:
但是在爬虫中,爬虫只会请求url地址,对应的拿到url地址对应的响应(该响应的内容可以是html,css,js,图片等)
浏览器渲染出来的页面和爬虫请求的页面很多时候并不一样,是因为爬虫不具备渲染的能力(当然后续课程中我们会借助其它工具或包来帮助爬虫对响应内容进行渲染)
-
浏览器最终展示的结果是由多个url地址分别发送的多次请求对应的多次响应共同渲染的结果
-
所以在爬虫中,需要以发送请求的一个url地址对应的响应为准来进行数据的提取
知识点:理解 浏览器展示的结果可以由多次请求对应的多次响应共同渲染出来,而爬虫是一次请求对应一个响应


二、requests模块
requests模块
知识点:
-
掌握 headers参数的使用
-
掌握 发送带参数的请求
-
掌握 headers中携带cookie
-
掌握 cookies参数的使用
-
掌握 cookieJar的转换方法
-
掌握 超时参数timeout的使用
-
掌握 代理ip参数proxies的使用
-
掌握 使用verify参数忽略CA证书
-
掌握 requests模块发送post请求
-
掌握 利用requests.session进行状态保持
前面我们了解了爬虫的基础知识,接下来我们来学习如何在代码中实现我们的爬虫
1. requests模块介绍
1.1 requests模块的作用:
-
发送http请求,获取响应数据
1.2 requests模块是一个第三方模块,需要在你的python(虚拟)环境中额外安装
-
pip/pip3 install requests
1.3 requests模块发送get请求
需求:通过requests向百度首页发送请求,获取该页面的源码
运行下面的代码,观察打印输出的结果
# 1.2.1-简单的代码实现 import requests # 目标url url = 'https://www.baidu.com' # 向目标url发送get请求 response = requests.get(url) # 打印响应内容 print(response.text)
知识点:掌握 requests模块发送get请求
2. response响应对象
观察上边代码运行结果发现,有好多乱码;这是因为编解码使用的字符集不同早造成的;我们尝试使用下边的办法来解决中文乱码问题
# 1.2.2-response.content import requests # 目标url url = 'https://www.baidu.com' # 向目标url发送get请求 response = requests.get(url) # 打印响应内容 # print(response.text) print(response.content.decode()) # 注意这里!
-
response.text是requests模块按照chardet模块推测出的编码字符集进行解码的结果
-
网络传输的字符串都是bytes类型的,所以response.text = response.content.decode(‘推测出的编码字符集’)
-
我们可以在网页源码中搜索
charset,尝试参考该编码字符集,注意存在不准确的情况
2.1 response.text 和response.content的区别:
-
response.text
-
类型:str
-
解码类型: requests模块自动根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
-
-
response.content
-
类型:bytes
-
解码类型: 没有指定
-
知识点:掌握 response.text和response.content的区别
2.2 通过对response.content进行decode,来解决中文乱码
-
response.content.decode()默认utf-8 -
response.content.decode("GBK") -
常见的编码字符集
-
utf-8
-
gbk
-
gb2312
-
ascii (读音:阿斯克码)
-
iso-8859-1
-
知识点:掌握 利用decode函数对requests.content解决中文乱码
2.3 response响应对象的其它常用属性或方法
response = requests.get(url)中response是发送请求获取的响应对象;response响应对象中除了text、content获取响应内容以外还有其它常用的属性或方法:
-
response.url响应的url;有时候响应的url和请求的url并不一致 -
response.status_code响应状态码 -
response.request.headers响应对应的请求头 -
response.headers响应头 -
response.request._cookies响应对应请求的cookie;返回cookieJar类型 -
response.cookies响应的cookie(经过了set-cookie动作;返回cookieJar类型 -
response.json()自动将json字符串类型的响应内容转换为python对象(dict or list)
# 1.2.3-response其它常用属性 import requests # 目标url url = 'https://www.baidu.com' # 向目标url发送get请求 response = requests.get(url) # 打印响应内容 # print(response.text) # print(response.content.decode()) # 注意这里! print(response.url) # 打印响应的url print(response.status_code) # 打印响应的状态码 print(response.request.headers) # 打印响应对象的请求头 print(response.headers) # 打印响应头 print(response.request._cookies) # 打印请求携带的cookies print(response.cookies) # 打印响应中携带的cookies
知识点:掌握 response响应对象的其它常用属性
3. requests模块发送请求
3.1 发送带header的请求
我们先写一个获取百度首页的代码
import requests url = 'https://www.baidu.com' response = requests.get(url) print(response.content.decode()) # 打印响应对应请求的请求头信息 print(response.request.headers)
3.1.1 思考
-
对比浏览器上百度首页的网页源码和代码中的百度首页的源码,有什么不同?
-
查看网页源码的方法:
-
右键-查看网页源代码 或
-
右键-检查
-
-
-
对比对应url的响应内容和代码中的百度首页的源码,有什么不同?
-
查看对应url的响应内容的方法:
-
右键-检查
-
点击
Net work -
勾选
Preserve log -
刷新页面
-
查看
Name一栏下和浏览器地址栏相同的url的Response
-
-
-
代码中的百度首页的源码非常少,为什么?
-
需要我们带上请求头信息
回顾爬虫的概念,模拟浏览器,欺骗服务器,获取和浏览器一致的内容
-
请求头中有很多字段,其中User-Agent字段必不可少,表示客户端的操作系统以及浏览器的信息
-
3.1.2 携带请求头发送请求的方法
requests.get(url, headers=headers)
-
headers参数接收字典形式的请求头
-
请求头字段名作为key,字段对应的值作为value
3.1.3 完成代码实现
从浏览器中复制User-Agent,构造headers字典;完成下面的代码后,运行代码查看结果
import requests
url = 'https://www.baidu.com'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 在请求头中带上User-Agent,模拟浏览器发送请求
response = requests.get(url, headers=headers)
print(response.content)
# 打印请求头信息
print(response.request.headers)
知识点:掌握 headers参数的使用
3.2 发送带参数的请求
我们在使用百度搜索的时候经常发现url地址中会有一个
?,那么该问号后边的就是请求参数,又叫做查询字符串
3.2.1 在url携带参数
直接对含有参数的url发起请求
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
url = 'https://www.baidu.com/s?wd=python'
response = requests.get(url, headers=headers)
3.2.2 通过params携带参数字典
1.构建请求参数字典
2.向接口发送请求的时候带上参数字典,参数字典设置给params
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 这是目标url
# url = 'https://www.baidu.com/s?wd=python'
# 最后有没有问号结果都一样
url = 'https://www.baidu.com/s?'
# 请求参数是一个字典 即wd=python
kw = {'wd': 'python'}
# 带上请求参数发起请求,获取响应
response = requests.get(url, headers=headers, params=kw)
print(response.content)
知识点:掌握发送带参数的请求的方法
3.3 在headers参数中携带cookie
网站经常利用请求头中的Cookie字段来做用户访问状态的保持,那么我们可以在headers参数中添加Cookie,模拟普通用户的请求。我们以github登陆为例:
3.3.1 github登陆抓包分析
-
打开浏览器,右键-检查,点击Net work,勾选Preserve log
-
访问github登陆的url地址
https://github.com/login -
输入账号密码点击登陆后,访问一个需要登陆后才能获取正确内容的url,比如点击右上角的Your profile访问
https://github.com/USER_NAME -
确定url之后,再确定发送该请求所需要的请求头信息中的User-Agent和Cookie
3.3.2 完成代码
-
从浏览器中复制User-Agent和Cookie
-
浏览器中的请求头字段和值与headers参数中必须一致
-
headers请求参数字典中的Cookie键对应的值是字符串
import requests
url = 'https://github.com/USER_NAME'
# 构造请求头字典
headers = {
# 从浏览器中复制过来的User-Agent
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36',
# 从浏览器中复制过来的Cookie
'Cookie': 'xxx这里是复制过来的cookie字符串'
}
# 请求头参数字典中携带cookie字符串
resp = requests.get(url, headers=headers)
print(resp.text)
3.3.3 运行代码验证结果
在打印的输出结果中搜索title,html中的标题文本内容如果是你的github账号,则成功利用headers参数携带cookie,获取登陆后才能访问的页面
知识点:掌握 headers中携带cookie
3.4 cookies参数的使用
上一小节我们在headers参数中携带cookie,也可以使用专门的cookies参数
-
cookies参数的形式:字典
cookies = {"cookie的name":"cookie的value"}-
该字典对应请求头中Cookie字符串,以分号、空格分割每一对字典键值对
-
等号左边的是一个cookie的name,对应cookies字典的key
-
等号右边对应cookies字典的value
-
-
cookies参数的使用方法
response = requests.get(url, cookies) -
将cookie字符串转换为cookies参数所需的字典:
cookies_dict = {cookie.split('=')[0]:cookie.split('=')[-1] for cookie in cookies_str.split('; ')} -
注意:cookie一般是有过期时间的,一旦过期需要重新获取
import requests
url = 'https://github.com/USER_NAME'
# 构造请求头字典
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'
}
# 构造cookies字典
cookies_str = '从浏览器中copy过来的cookies字符串'
cookies_dict = {cookie.split('=')[0]:cookie.split('=')[-1] for cookie in cookies_str.split('; ')}
# 请求头参数字典中携带cookie字符串
resp = requests.get(url, headers=headers, cookies=cookies_dict)
print(resp.text)
知识点:掌握 cookies参数的使用
3.5 cookieJar对象转换为cookies字典的方法
使用requests获取的resposne对象,具有cookies属性。该属性值是一个cookieJar类型,包含了对方服务器设置在本地的cookie。我们如何将其转换为cookies字典呢?
-
转换方法
cookies_dict = requests.utils.dict_from_cookiejar(response.cookies) -
其中response.cookies返回的就是cookieJar类型的对象
-
requests.utils.dict_from_cookiejar函数返回cookies字典
知识点:掌握 cookieJar的转换方法
3.6 超时参数timeout的使用
在平时网上冲浪的过程中,我们经常会遇到网络波动,这个时候,一个请求等了很久可能任然没有结果。
在爬虫中,一个请求很久没有结果,就会让整个项目的效率变得非常低,这个时候我们就需要对请求进行强制要求,让他必须在特定的时间内返回结果,否则就报错。
-
超时参数timeout的使用方法
response = requests.get(url, timeout=3) -
timeout=3表示:发送请求后,3秒钟内返回响应,否则就抛出异常
import requests url = 'https://twitter.com' response = requests.get(url, timeout=3) # 设置超时时间
知识点:掌握 超时参数timeout的使用
3.7 了解代理以及proxy代理参数的使用
proxy代理参数通过指定代理ip,让代理ip对应的正向代理服务器转发我们发送的请求,那么我们首先来了解一下代理ip以及代理服务器
3.7.1 理解使用代理的过程
-
代理ip是一个ip,指向的是一个代理服务器
-
代理服务器能够帮我们向目标服务器转发请求
3.7.2 正向代理和反向代理的区别
前边提到proxy参数指定的代理ip指向的是正向的代理服务器,那么相应的就有反向服务器;现在来了解一下正向代理服务器和反向代理服务器的区别
-
从发送请求的一方的角度,来区分正向或反向代理
-
为浏览器或客户端(发送请求的一方)转发请求的,叫做正向代理
-
浏览器知道最终处理请求的服务器的真实ip地址,例如VPN
-
-
不为浏览器或客户端(发送请求的一方)转发请求、而是为最终处理请求的服务器转发请求的,叫做反向代理
-
浏览器不知道服务器的真实地址,例如nginx
-
3.7.3 代理ip(代理服务器)的分类
-
根据代理ip的匿名程度,代理IP可以分为下面三类:
-
透明代理(Transparent Proxy):透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以查到你是谁。目标服务器接收到的请求头如下:
REMOTE_ADDR = Proxy IP HTTP_VIA = Proxy IP HTTP_X_FORWARDED_FOR = Your IP
-
匿名代理(Anonymous Proxy):使用匿名代理,别人只能知道你用了代理,无法知道你是谁。目标服务器接收到的请求头如下:
REMOTE_ADDR = proxy IP HTTP_VIA = proxy IP HTTP_X_FORWARDED_FOR = proxy IP
-
高匿代理(Elite proxy或High Anonymity Proxy):高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。毫无疑问使用高匿代理效果最好。目标服务器接收到的请求头如下:
REMOTE_ADDR = Proxy IP HTTP_VIA = not determined HTTP_X_FORWARDED_FOR = not determined
-
-
根据网站所使用的协议不同,需要使用相应协议的代理服务。从代理服务请求使用的协议可以分为:
-
http代理:目标url为http协议
-
https代理:目标url为https协议
-
socks隧道代理(例如socks5代理)等:
-
socks 代理只是简单地传递数据包,不关心是何种应用协议(FTP、HTTP和HTTPS等)。
-
socks 代理比http、https代理耗时少。
-
socks 代理可以转发http和https的请求
-
-
3.7.4 proxies代理参数的使用
为了让服务器以为不是同一个客户端在请求;为了防止频繁向一个域名发送请求被封ip,所以我们需要使用代理ip;那么我们接下来要学习requests模块是如何使用代理ip的
-
用法:
response = requests.get(url, proxies=proxies)
-
proxies的形式:字典
-
例如:
proxies = { "http": "http://12.34.56.79:9527", "https": "https://12.34.56.79:9527", } -
注意:如果proxies字典中包含有多个键值对,发送请求时将按照url地址的协议来选择使用相应的代理ip
知识点:掌握 代理ip参数proxies的使用
4. requests模块发送post请求
思考:哪些地方我们会用到POST请求?
登录注册( 在web工程师看来POST 比 GET 更安全,url地址中不会暴露用户的账号密码等信息)
需要传输大文本内容的时候( POST 请求对数据长度没有要求)
所以同样的,我们的爬虫也需要在这两个地方回去模拟浏览器发送post请求
4.1 requests发送post请求的方法
-
response = requests.post(url, data) -
data参数接收一个字典 -
requests模块发送post请求函数的其它参数和发送get请求的参数完全一致
4.2 POST请求练习
下面面我们通过金山翻译的例子看看post请求如何使用:
思路分析
-
抓包确定请求的url地址
-
确定请求的参数
-
确定返回数据的位置
-
模拟浏览器获取数据
4.2.3 抓包分析的结论
-
url地址:
http://fy.iciba.com/ -
请求方法:POST
-
请求所需参数:
data = { 'f': 'auto', # 表示被翻译的语言是自动识别 't': 'auto', # 表示翻译后的语言是自动识别 'w': '人生苦短' # 要翻译的中文字符串 } -
pc端User-Agent:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
4.2.4 代码实现
了解requests模块发送post请求的方法,以及分析过移动端的百度翻译之后,我们来完成代码
import requests
import json
class King(object):
def __init__(self, word):
self.url = "http://fy.iciba.com/ajax.php?a=fy"
self.word = word
self.headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"
}
self.post_data = {
"f": "auto",
"t": "auto",
"w": self.word
}
def get_data(self):
response = requests.post(self.url, headers=self.headers, data=self.post_data)
# 默认返回bytes类型,除非确定外部调用使用str才进行解码操作
return response.content
def parse_data(self, data):
# 将json数据转换成python字典
dict_data = json.loads(data)
# 从字典中抽取翻译结果
try:
print(dict_data['content']['out'])
except:
print(dict_data['content']['word_mean'][0])
def run(self):
# url
# headers
# post——data
# 发送请求
data = self.get_data()
# 解析
self.parse_data(data)
if __name__ == '__main__':
# king = King("人生苦短,及时行乐")
king = King("China")
king.run()
# python标准库有很多有用的方法,每天看一个标准库的使用
知识点:掌握 requests模块发送post请求
5. 利用requests.session进行状态保持
requests模块中的Session类能够自动处理发送请求获取响应过程中产生的cookie,进而达到状态保持的目的。接下来我们就来学习它
5.1 requests.session的作用以及应用场景
-
requests.session的作用
-
自动处理cookie,即 下一次请求会带上前一次的cookie
-
-
requests.session的应用场景
-
自动处理连续的多次请求过程中产生的cookie
-
5.2 requests.session使用方法
session实例在请求了一个网站后,对方服务器设置在本地的cookie会保存在session中,下一次再使用session请求对方服务器的时候,会带上前一次的cookie
session = requests.session() # 实例化session对象 response = session.get(url, headers, ...) response = session.post(url, data, ...)
-
session对象发送get或post请求的参数,与requests模块发送请求的参数完全一致
5.3 测试
使用requests.session来完成github登陆,并获取需要登陆后才能访问的页面
5.3.1 提示
-
对github登陆以及访问登陆后才能访问的页面的整个完成过程进行抓包
-
确定登陆请求的url地址、请求方法和所需的请求参数
-
部分请求参数在别的url对应的响应内容中,可以使用re模块获取
-
-
确定登陆后才能访问的页面的的url地址和请求方法
-
利用requests.session完成代码
5.3.2 参考代码
import requests
import re
# 构造请求头字典
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36',
}
# 实例化session对象
session = requests.session()
# 访问登陆页获取登陆请求所需参数
response = session.get('https://github.com/login', headers=headers)
authenticity_token = re.search('name="authenticity_token" value="(.*?)" />', response.text).group(1) # 使用正则获取登陆请求所需参数
# 构造登陆请求参数字典
data = {
'commit': 'Sign in', # 固定值
'utf8': '✓', # 固定值
'authenticity_token': authenticity_token, # 该参数在登陆页的响应内容中
'login': input('输入github账号:'),
'password': input('输入github账号:')
}
# 发送登陆请求(无需关注本次请求的响应)
session.post('https://github.com/session', headers=headers, data=data)
# 打印需要登陆后才能访问的页面
response = session.get('https://github.com/1596930226', headers=headers)
print(response.text)
知识点:掌握 利用requests.session进行状态保持

三、数据提取
数据提取概述
知识点
-
了解 响应内容的分类
-
了解 xml和html的区别
1. 响应内容的分类
在发送请求获取响应之后,可能存在多种不同类型的响应内容;而且很多时候,我们只需要响应内容中的一部分数据
-
结构化的响应内容
-
json字符串
-
可以使用re、json等模块来提取特定数据
-
-
xml字符串
-
可以使用re、lxml等模块来提取特定数据
-
xml字符串的例子如下
<bookstore> <book category="COOKING"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore>
-
-
-
非结构化的响应内容
-
html字符串
-
可以使用re、lxml等模块来提取特定数据
-
-
知识点:了解 响应内容的分类
2. 认识xml以及和html的区别
要搞清楚html和xml的区别,首先需要我们来认识xml
2.1 认识xml
xml是一种可扩展标记语言,样子和html很像,功能更专注于对传输和存储数据
<bookstore> <book category="COOKING"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore>
2.2 xml和html的区别
二者区别如下
-
html:
-
超文本标记语言
-
为了更好的显示数据,侧重点是为了显示
-
-
xml:
-
可扩展标记语言
-
为了传输和存储数据,侧重点是在于数据内容本身
-
知识点:了解 xml和html的区别
2.3 常用数据解析方法
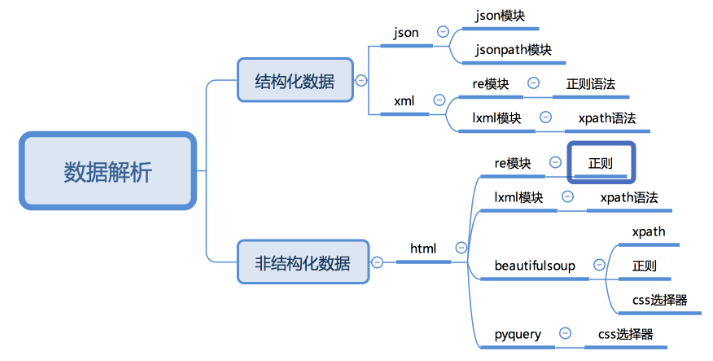
数据提取-jsonpath模块
知识点
-
了解 jsonpath模块的使用场景
-
掌握 jsonpath模块的使用
1. jsonpath模块的使用场景
如果有一个多层嵌套的复杂字典,想要根据key和下标来批量提取value,这是比较困难的。jsonpath模块就能解决这个痛点,接下来我们就来学习jsonpath模块
jsonpath可以按照key对python字典进行批量数据提取
知识点:了解 jsonpath模块的使用场景
2. jsonpath模块的使用方法
2.1 jsonpath模块的安装
jsonpath是第三方模块,需要额外安装
pip install jsonpath
2.2 jsonpath模块提取数据的方法
from jsonpath import jsonpath ret = jsonpath(a, 'jsonpath语法规则字符串')
2.4 jsonpath使用示例
book_dict = {
"store": {
"book": [
{ "category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{ "category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{ "category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
from jsonpath import jsonpath
print(jsonpath(book_dict, '$..author')) # 如果取不到将返回False # 返回列表,如果取不到将返回False
知识点:掌握 jsonpath模块的使用
数据提取-lxml模块
知识点
-
了解 lxml模块和xpath语法的关系
-
了解 lxml模块的使用场景
-
了解 lxml模块的安装
-
了解 谷歌浏览器xpath helper插件的安装和使用
-
掌握 xpath语法-基础节点选择语法
-
掌握 xpath语法-节点修饰语法
-
掌握 xpath语法-其他常用语法
-
掌握 lxml模块中使用xpath语法定位元素提取属性值或文本内容
-
掌握 lxml模块中etree.tostring函数的使用
1. 了解 lxml模块和xpath语法
对html或xml形式的文本提取特定的内容,就需要我们掌握lxml模块的使用和xpath语法。
-
lxml模块可以利用XPath规则语法,来快速的定位HTML\XML 文档中特定元素以及获取节点信息(文本内容、属性值)
-
XPath (XML Path Language) 是一门在 HTML\XML 文档中查找信息的语言,可用来在 HTML\XML 文档中对元素和属性进行遍历
-
提取xml、html中的数据需要lxml模块和xpath语法配合使用
知识点:了解 lxml模块和xpath语法
2. 谷歌浏览器xpath helper插件的安装和使用
要想利用lxml模块提取数据,需要我们掌握xpath语法规则。接下来我们就来了解一下xpath helper插件,它可以帮助我们练习xpath语法
2.1 谷歌浏览器xpath helper插件的作用
在谷歌浏览器中对当前页面测试xpath语法规则
2.2 谷歌浏览器xpath helper插件的安装和使用
我们以windos为例进行xpath helper的安装
2.2.1 xpath helper插件的安装
-
下载Chrome插件 XPath Helper
-
可以在chrome应用商城进行下载,如果无法下载,也可以从下面的链接进行下载
-
-
把文件的后缀名crx改为rar,然后解压到同名文件夹中
-
把解压后的文件夹拖入到已经开启开发者模式的chrome浏览器扩展程序界面
-
重启浏览器后,访问url之后在页面中点击xpath图标,就可以使用了
-
如果是linux或macOS操作系统,无需操作上述的步骤2,直接将crx文件拖入已经开启开发者模式的chrome浏览器扩展程序界面
知识点:了解 谷歌浏览器xpath helper插件的安装和使用
3. xpath的节点关系
学习xpath语法需要先了解xpath中的节点关系
3.1 xpath中的节点是什么
每个html、xml的标签我们都称之为节点,其中最顶层的节点称为根节点。我们以xml为例,html也是一样的
4. xpath语法-基础节点选择语法
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。
这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
使用chrome插件选择标签时候,选中时,选中的标签会添加属性class=”xh-highlight”
4.1 xpath定位节点以及提取属性或文本内容的语法
| 表达式 | 描述 |
|---|---|
| nodename | 选中该元素。 |
| / | 从根节点选取、或者是元素和元素间的过渡。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
| text() | 选取文本。 |
4.2 语法练习
-
选择所有的h2下的文本
-
//h2/text()
-
-
获取所有的a标签的href
-
//a/@href
-
-
获取html下的head下的title的文本
-
/html/head/title/text()
-
-
获取html下的head下的link标签的href
-
/html/head/link/@href
-
知识点:掌握 xpath语法-选取节点以及提取属性或文本内容的语法
5. xpath语法-节点修饰语法
可以根据标签的属性值、下标等来获取特定的节点
5.1 节点修饰语法
| 路径表达式 | 结果 |
|---|---|
| //title[@lang=”eng”] | 选择lang属性值为eng的所有title元素 |
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()>1] | 选择bookstore下面的book元素,从第二个开始选择 |
| //book/title[text()=’Harry Potter’] | 选择所有book下的title元素,仅仅选择文本为Harry Potter的title元素 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
5.2 关于xpath的下标
-
在xpath中,第一个元素的位置是1
-
最后一个元素的位置是last()
-
倒数第二个是last()-1
5.3 语法练习
-
所有的学科的名称
-
//div[@class="nav_txt"]//a[@class="a_gd"]
-
-
第一个学科的链接
-
//div[@class="nav_txt"]/ul/li[1]/a/@href
-
-
最后一个学科的链接
-
//div[@class="nav_txt"]/ul/li[last()]/a/@href
-
知识点:掌握 xpath语法-选取特定节点的语法
6. xpath语法-其他常用节点选择语法
可以通过通配符来选取未知的html、xml的元素
6.1 选取未知节点的语法
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| node() | 匹配任何类型的节点。 |
6.2 语法练习
-
全部的标签
-
//*
-
-
全部的属性
-
//node()
-
知识点:掌握 xpath语法-选取位置节点的语法
7. lxml模块的安装与使用示例
lxml模块是一个第三方模块,安装之后使用
7.1 lxml模块的安装
对发送请求获取的xml或html形式的响应内容进行提取
pip/pip3 install lxml
知识点:了解 lxml模块的安装
7.2 爬虫对html提取的内容
-
提取标签中的文本内容
-
提取标签中的属性的值
-
比如,提取a标签中href属性的值,获取url,进而继续发起请求
-
7.3 lxml模块的使用
-
导入lxml 的 etree 库
from lxml import etree -
利用etree.HTML,将html字符串(bytes类型或str类型)转化为Element对象,Element对象具有xpath的方法,返回结果的列表
html = etree.HTML(text) ret_list = html.xpath("xpath语法规则字符串") -
xpath方法返回列表的三种情况
-
返回空列表:根据xpath语法规则字符串,没有定位到任何元素
-
返回由字符串构成的列表:xpath字符串规则匹配的一定是文本内容或某属性的值
-
返回由Element对象构成的列表:xpath规则字符串匹配的是标签,列表中的Element对象可以继续进行xpath
-
7.4 lxml模块使用示例
运行下面的代码,查看打印的结果
from lxml import etree
text = '''
<div>
<ul>
<li class="item-1">
<a href="link1.html">first item</a>
</li>
<li class="item-1">
<a href="link2.html">second item</a>
</li>
<li class="item-inactive">
<a href="link3.html">third item</a>
</li>
<li class="item-1">
<a href="link4.html">fourth item</a>
</li>
<li class="item-0">
a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
#获取href的列表和title的列表
href_list = html.xpath("//li[@class='item-1']/a/@href")
title_list = html.xpath("//li[@class='item-1']/a/text()")
#组装成字典
for href in href_list:
item = {}
item["href"] = href
item["title"] = title_list[href_list.index(href)]
print(item)
8 练习
将下面的html文档字符串中,将每个class为item-1的li标签作为1条新闻数据。提取a标签的文本内容以及链接,组装成一个字典。
text = ''' <div> <ul> <li class="item-1"><a>first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> </ul> </div> '''
-
注意:
-
先分组,再提取数据,可以避免数据的错乱
-
对于空值要进行判断
-
知识点:掌握 lxml模块中etree.tostring函数的使用

四、selenium的使用
selenium的介绍
知识点:
-
了解 selenium的工作原理
-
了解 selenium以及chromedriver的安装
-
掌握 标签对象click点击以及send_keys输入
1. selenium运行效果展示
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,Selenium 可以直接调用浏览器,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器),可以接收指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏等。我们可以使用selenium很容易完成之前编写的爬虫,接下来我们就来看一下selenium的运行效果
1.1 chrome浏览器的运行效果
在下载好chromedriver以及安装好selenium模块后,执行下列代码并观察运行的过程
from selenium import webdriver
# 如果driver没有添加到了环境变量,则需要将driver的绝对路径赋值给executable_path参数
# driver = webdriver.Chrome(executable_path='/home/worker/Desktop/driver/chromedriver')
# 如果driver添加了环境变量则不需要设置executable_path
driver = webdriver.Chrome()
# 向一个url发起请求
driver.get("http://www.itcast.cn/")
# 把网页保存为图片,69版本以上的谷歌浏览器将无法使用截图功能
# driver.save_screenshot("itcast.png")
print(driver.title) # 打印页面的标题
# 退出模拟浏览器
driver.quit() # 一定要退出!不退出会有残留进程!
1.2 phantomjs无界面浏览器的运行效果
PhantomJS 是一个基于Webkit的“无界面”(headless)浏览器,它会把网站加载到内存并执行页面上的 JavaScript。
from selenium import webdriver
# 指定driver的绝对路径
driver = webdriver.PhantomJS(executable_path='/home/worker/Desktop/driver/phantomjs')
# driver = webdriver.Chrome(executable_path='/home/worker/Desktop/driver/chromedriver')
# 向一个url发起请求
driver.get("http://www.itcast.cn/")
# 把网页保存为图片
driver.save_screenshot("itcast.png")
# 退出模拟浏览器
driver.quit() # 一定要退出!不退出会有残留进程!
1.3 观察运行效果
-
python代码能够自动的调用谷歌浏览或phantomjs无界面浏览器,控制其自动访问网站
1.4 无头浏览器与有头浏览器的使用场景
-
通常在开发过程中我们需要查看运行过程中的各种情况所以通常使用有头浏览器
-
在项目完成进行部署的时候,通常平台采用的系统都是服务器版的操作系统,服务器版的操作系统必须使用无头浏览器才能正常运行
2. selenium的作用和工作原理
利用浏览器原生的API,封装成一套更加面向对象的Selenium WebDriver API,直接操作浏览器页面里的元素,甚至操作浏览器本身(截屏,窗口大小,启动,关闭,安装插件,配置证书之类的)
-
webdriver本质是一个web-server,对外提供webapi,其中封装了浏览器的各种功能
-
不同的浏览器使用各自不同的webdriver
知识点:了解 selenium的工作原理
3. selenium的安装以及简单使用
我们以谷歌浏览器的chromedriver为例
3.1 在python虚拟环境中安装selenium模块
pip/pip3 install selenium
3.2 下载版本符合的webdriver
知识点:了解 selenium以及chromedriver的安装
4. selenium的简单使用
接下来我们就通过代码来模拟百度搜索
import time
from selenium import webdriver
# 通过指定chromedriver的路径来实例化driver对象,chromedriver放在当前目录。
# driver = webdriver.Chrome(executable_path='./chromedriver')
# chromedriver已经添加环境变量
driver = webdriver.Chrome()
# 控制浏览器访问url地址
driver.get("https://www.baidu.com/")
# 在百度搜索框中搜索'python'
driver.find_element_by_id('kw').send_keys('python')
# 点击'百度搜索'
driver.find_element_by_id('su').click()
time.sleep(6)
# 退出浏览器
driver.quit()
-
webdriver.Chrome(executable_path='./chromedriver')中executable参数指定的是下载好的chromedriver文件的路径 -
driver.find_element_by_id('kw').send_keys('python')定位id属性值是’kw’的标签,并向其中输入字符串’python’ -
driver.find_element_by_id('su').click()定位id属性值是su的标签,并点击-
click函数作用是:触发标签的js的click事件
-
知识点:掌握 标签对象click点击以及send_keys输入

selenium提取数据
知识点:
-
了解 driver对象的常用属性和方法
-
掌握 driver对象定位标签元素获取标签对象的方法
-
掌握 标签对象提取文本和属性值的方法
1. driver对象的常用属性和方法
在使用selenium过程中,实例化driver对象后,driver对象有一些常用的属性和方法
-
driver.page_source当前标签页浏览器渲染之后的网页源代码 -
driver.current_url当前标签页的url -
driver.close()关闭当前标签页,如果只有一个标签页则关闭整个浏览器 -
driver.quit()关闭浏览器 -
driver.forward()页面前进 -
driver.back()页面后退 -
driver.screen_shot(img_name)页面截图
知识点:了解 driver对象的常用属性和方法
2. driver对象定位标签元素获取标签对象的方法
在selenium中可以通过多种方式来定位标签,返回标签元素对象
find_element_by_id (返回一个元素) find_element(s)_by_class_name (根据类名获取元素列表) find_element(s)_by_name (根据标签的name属性值返回包含标签对象元素的列表) find_element(s)_by_xpath (返回一个包含元素的列表) find_element(s)_by_link_text (根据连接文本获取元素列表) find_element(s)_by_partial_link_text (根据链接包含的文本获取元素列表) find_element(s)_by_tag_name (根据标签名获取元素列表) find_element(s)_by_css_selector (根据css选择器来获取元素列表)
-
注意:
-
find_element和find_elements的区别:
-
多了个s就返回列表,没有s就返回匹配到的第一个标签对象
-
find_element匹配不到就抛出异常,find_elements匹配不到就返回空列表
-
-
by_link_text和by_partial_link_tex的区别:全部文本和包含某个文本
-
以上函数的使用方法
-
driver.find_element_by_id('id_str')
-
-
知识点:掌握 driver对象定位标签元素获取标签对象的方法
3. 标签对象提取文本内容和属性值
find_element仅仅能够获取元素,不能够直接获取其中的数据,如果需要获取数据需要使用以下方法
-
对元素执行点击操作
element.click()-
对定位到的标签对象进行点击操作
-
-
向输入框输入数据
element.send_keys(data)-
对定位到的标签对象输入数据
-
-
获取文本
element.text-
通过定位获取的标签对象的
text属性,获取文本内容
-
-
获取属性值
element.get_attribute("属性名")-
通过定位获取的标签对象的
get_attribute函数,传入属性名,来获取属性的值
-
-
代码实现,如下:
from selenium import webdriver driver = webdriver.Chrome() driver.get('http://www.itcast.cn/') ret = driver.find_elements_by_tag_name('h2') print(ret[0].text) # ret = driver.find_elements_by_link_text('黑马程序员') print(ret[0].get_attribute('href')) driver.quit()
知识点:掌握 元素对象的操作方法

selenium的其它使用方法
知识点:
-
掌握 selenium控制标签页的切换
-
掌握 selenium控制iframe的切换
-
掌握 利用selenium获取cookie的方法
-
掌握 手动实现页面等待
-
掌握 selenium控制浏览器执行js代码的方法
-
掌握 selenium开启无界面模式
-
了解 selenium使用代理ip
-
了解 selenium替换user-agent
1. selenium标签页的切换
当selenium控制浏览器打开多个标签页时,如何控制浏览器在不同的标签页中进行切换呢?需要我们做以下两步:
-
获取所有标签页的窗口句柄
-
利用窗口句柄字切换到句柄指向的标签页
-
这里的窗口句柄是指:指向标签页对象的标识
-
-
具体的方法
# 1. 获取当前所有的标签页的句柄构成的列表 current_windows = driver.window_handles # 2. 根据标签页句柄列表索引下标进行切换 driver.switch_to.window(current_windows[0])
-
参考代码示例:
import time from selenium import webdriver driver = webdriver.Chrome() driver.get("https://www.baidu.com/") time.sleep(1) driver.find_element_by_id('kw').send_keys('python') time.sleep(1) driver.find_element_by_id('su').click() time.sleep(1) # 通过执行js来新开一个标签页 js = 'window.open("https://www.sogou.com");' driver.execute_script(js) time.sleep(1) # 1. 获取当前所有的窗口 windows = driver.window_handles time.sleep(2) # 2. 根据窗口索引进行切换 driver.switch_to.window(windows[0]) time.sleep(2) driver.switch_to.window(windows[1]) time.sleep(6) driver.quit()
知识点:掌握 selenium控制标签页的切换
2. switch_to切换frame标签
iframe是html中常用的一种技术,即一个页面中嵌套了另一个网页,selenium默认是访问不了frame中的内容的,对应的解决思路是
driver.switch_to.frame(frame_element)。接下来我们通过qq邮箱模拟登陆来学习这个知识点
-
参考代码:
import time from selenium import webdriver driver = webdriver.Chrome() url = 'https://mail.qq.com/cgi-bin/loginpage' driver.get(url) time.sleep(2) login_frame = driver.find_element_by_id('login_frame') # 根据id定位 frame元素 driver.switch_to.frame(login_frame) # 转向到该frame中 driver.find_element_by_xpath('//*[@id="u"]').send_keys('1596930226@qq.com') time.sleep(2) driver.find_element_by_xpath('//*[@id="p"]').send_keys('hahamimashicuode') time.sleep(2) driver.find_element_by_xpath('//*[@id="login_button"]').click() time.sleep(2) """操作frame外边的元素需要切换出去""" windows = driver.window_handles driver.switch_to.window(windows[0]) content = driver.find_element_by_class_name('login_pictures_title').text print(content) driver.quit()
-
总结:
-
切换到定位的frame标签嵌套的页面中
-
driver.switch_to.frame(通过find_element_by函数定位的frame、iframe标签对象)
-
-
利用切换标签页的方式切出frame标签
-
windows = driver.window_handles driver.switch_to.window(windows[0])
-
-
知识点:掌握 selenium控制frame标签的切换
3. selenium对cookie的处理
selenium能够帮助我们处理页面中的cookie,比如获取、删除,接下来我们就学习这部分知识
3.1 获取cookie
driver.get_cookies()返回列表,其中包含的是完整的cookie信息!不光有name、value,还有domain等cookie其他维度的信息。所以如果想要把获取的cookie信息和requests模块配合使用的话,需要转换为name、value作为键值对的cookie字典
# 获取当前标签页的全部cookie信息
print(driver.get_cookies())
# 把cookie转化为字典
cookies_dict = {cookie[‘name’]: cookie[‘value’] for cookie in driver.get_cookies()}
3.2 删除cookie
#删除一条cookie
driver.delete_cookie("CookieName")
# 删除所有的cookie
driver.delete_all_cookies()
知识点:掌握 利用selenium获取cookie的方法
4. selenium控制浏览器执行js代码
selenium可以让浏览器执行我们规定的js代码,运行下列代码查看运行效果
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.itcast.cn/")
time.sleep(1)
js = 'window.scrollTo(0,document.body.scrollHeight)' # js语句
driver.execute_script(js) # 执行js的方法
time.sleep(5)
driver.quit()
-
执行js的方法:
driver.execute_script(js)
知识点:掌握 selenium控制浏览器执行js代码的方法
5. 页面等待
页面在加载的过程中需要花费时间等待网站服务器的响应,在这个过程中标签元素有可能还没有加载出来,是不可见的,如何处理这种情况呢?
-
页面等待分类
-
强制等待介绍
-
显式等待介绍
-
隐式等待介绍
-
手动实现页面等待
5.1 页面等待的分类
首先我们就来了解以下selenium页面等待的分类
-
强制等待
-
隐式等待
-
显式等待
5.2 强制等待(了解)
-
其实就是time.sleep()
-
缺点时不智能,设置的时间太短,元素还没有加载出来;设置的时间太长,则会浪费时间
5.3 隐式等待
-
隐式等待针对的是元素定位,隐式等待设置了一个时间,在一段时间内判断元素是否定位成功,如果完成了,就进行下一步
-
在设置的时间内没有定位成功,则会报超时加载
-
示例代码
from selenium import webdriver driver = webdriver.Chrome() driver.implicitly_wait(10) # 隐式等待,最长等20秒 driver.get('https://www.baidu.com') driver.find_element_by_xpath()
5.4 显式等待(了解)
-
每经过多少秒就查看一次等待条件是否达成,如果达成就停止等待,继续执行后续代码
-
如果没有达成就继续等待直到超过规定的时间后,报超时异常
-
示例代码
from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('https://www.baidu.com') # 显式等待 WebDriverWait(driver, 20, 0.5).until( EC.presence_of_element_located((By.LINK_TEXT, '好123'))) # 参数20表示最长等待20秒 # 参数0.5表示0.5秒检查一次规定的标签是否存在 # EC.presence_of_element_located((By.LINK_TEXT, '好123')) 表示通过链接文本内容定位标签 # 每0.5秒一次检查,通过链接文本内容定位标签是否存在,如果存在就向下继续执行;如果不存在,直到20秒上限就抛出异常 print(driver.find_element_by_link_text('好123').get_attribute('href')) driver.quit()
5.5 手动实现页面等待
在了解了隐式等待和显式等待以及强制等待后,我们发现并没有一种通用的方法来解决页面等待的问题,比如“页面需要滑动才能触发ajax异步加载”的场景,那么接下来我们就以淘宝首页网为例,手动实现页面等待。
-
原理:
-
利用强制等待和显式等待的思路来手动实现
-
不停的判断或有次数限制的判断某一个标签对象是否加载完毕(是否存在)
-
-
实现代码如下:
import time
from selenium import webdriver
driver = webdriver.Chrome('/home/worker/Desktop/driver/chromedriver')
driver.get('https://www.taobao.com/')
time.sleep(1)
# i = 0
# while True:
for i in range(10):
i += 1
try:
time.sleep(3)
element = driver.find_element_by_xpath('//div[@class="shop-inner"]/h3[1]/a')
print(element.get_attribute('href'))
break
except:
js = 'window.scrollTo(0, {})'.format(i*500) # js语句
driver.execute_script(js) # 执行js的方法
driver.quit()
知识点:掌握 手动实现页面等待
6. selenium开启无界面模式
绝大多数服务器是没有界面的,selenium控制谷歌浏览器也是存在无界面模式的,这一小节我们就来学习如何开启无界面模式(又称之为无头模式)
-
开启无界面模式的方法
-
实例化配置对象
-
options = webdriver.ChromeOptions()
-
-
配置对象添加开启无界面模式的命令
-
options.add_argument("--headless")
-
-
配置对象添加禁用gpu的命令
-
options.add_argument("--disable-gpu")
-
-
实例化带有配置对象的driver对象
-
driver = webdriver.Chrome(chrome_options=options)
-
-
-
注意:macos中chrome浏览器59+版本,Linux中57+版本才能使用无界面模式!
-
参考代码如下:
from selenium import webdriver
options = webdriver.ChromeOptions() # 创建一个配置对象
options.add_argument("--headless") # 开启无界面模式
options.add_argument("--disable-gpu") # 禁用gpu
# options.set_headles() # 无界面模式的另外一种开启方式
driver = webdriver.Chrome(chrome_options=options) # 实例化带有配置的driver对象
driver.get('http://www.itcast.cn')
print(driver.title)
driver.quit()
知识点:掌握 selenium开启无界面模式
7. selenium使用代理ip
selenium控制浏览器也是可以使用代理ip的!
-
使用代理ip的方法
-
实例化配置对象
-
options = webdriver.ChromeOptions()
-
-
配置对象添加使用代理ip的命令
-
options.add_argument('--proxy-server=http://202.20.16.82:9527')
-
-
实例化带有配置对象的driver对象
-
driver = webdriver.Chrome('./chromedriver', chrome_options=options)
-
-
-
参考代码如下:
from selenium import webdriver options = webdriver.ChromeOptions() # 创建一个配置对象 options.add_argument('--proxy-server=http://202.20.16.82:9527') # 使用代理ip driver = webdriver.Chrome(chrome_options=options) # 实例化带有配置的driver对象 driver.get('http://www.itcast.cn') print(driver.title) driver.quit()
知识点:了解 selenium使用代理ip
8. selenium替换user-agent
selenium控制谷歌浏览器时,User-Agent默认是谷歌浏览器的,这一小节我们就来学习使用不同的User-Agent
-
替换user-agent的方法
-
实例化配置对象
-
options = webdriver.ChromeOptions()
-
-
配置对象添加替换UA的命令
-
options.add_argument('--user-agent=Mozilla/5.0 HAHA')
-
-
实例化带有配置对象的driver对象
-
driver = webdriver.Chrome('./chromedriver', chrome_options=options)
-
-
-
参考代码如下:
from selenium import webdriver options = webdriver.ChromeOptions() # 创建一个配置对象 options.add_argument('--user-agent=Mozilla/5.0 HAHA') # 替换User-Agent driver = webdriver.Chrome('./chromedriver', chrome_options=options) driver.get('http://www.itcast.cn') print(driver.title) driver.quit()
知识点:了解 selenium替换user-agent

五、抓包与反爬与反爬解决方案
常见的反爬手段和解决思路
学习目标
-
了解 服务器反爬的原因
-
了解 服务器常反什么样的爬虫
-
了解 反爬虫领域常见的一些概念
-
了解 反爬的三个方向
-
了解 常见基于身份识别进行反爬
-
了解 常见基于爬虫行为进行反爬
-
了解 常见基于数据加密进行反爬
1 服务器反爬的原因
-
爬虫占总PV(PV是指页面的访问次数,每打开或刷新一次页面,就算做一个pv)比例较高,这样浪费钱(尤其是三月份爬虫)。
三月份爬虫是个什么概念呢?每年的三月份我们会迎接一次爬虫高峰期,有大量的硕士在写论文的时候会选择爬取一些往网站,并进行舆情分析。因为五月份交论文,所以嘛,大家都是读过书的,你们懂的,前期各种DotA,LOL,到了三月份了,来不及了,赶紧抓数据,四月份分析一下,五月份交论文,就是这么个节奏。
-
公司可免费查询的资源被批量抓走,丧失竞争力,这样少赚钱。
数据可以在非登录状态下直接被查询。如果强制登陆,那么可以通过封杀账号的方式让对方付出代价,这也是很多网站的做法。但是不强制对方登录。那么如果没有反爬虫,对方就可以批量复制的信息,公司竞争力就会大大减少。竞争对手可以抓到数据,时间长了用户就会知道,只需要去竞争对手那里就可以了,没必要来我们网站,这对我们是不利的。
-
状告爬虫成功的几率小
爬虫在国内还是个擦边球,就是有可能可以起诉成功,也可能完全无效。所以还是需要用技术手段来做最后的保障。
2 服务器常反什么样的爬虫
-
十分低级的应届毕业生
应届毕业生的爬虫通常简单粗暴,根本不管服务器压力,加上人数不可预测,很容易把站点弄挂。
-
十分低级的创业小公司
现在的创业公司越来越多,也不知道是被谁忽悠的然后大家创业了发现不知道干什么好,觉得大数据比较热,就开始做大数据。分析程序全写差不多了,发现自己手头没有数据。怎么办?写爬虫爬啊。于是就有了不计其数的小爬虫,出于公司生死存亡的考虑,不断爬取数据。
-
不小心写错了没人去停止的失控小爬虫
有些网站已经做了相应的反爬,但是爬虫依然孜孜不倦地爬取。什么意思呢?就是说,他们根本爬不到任何数据,除了httpcode是200以外,一切都是不对的,可是爬虫依然不停止这个很可能就是一些托管在某些服务器上的小爬虫,已经无人认领了,依然在辛勤地工作着。
-
成型的商业对手
这个是最大的对手,他们有技术,有钱,要什么有什么,如果和你死磕,你就只能硬着头皮和他死磕。
-
抽风的搜索引擎
大家不要以为搜索引擎都是好人,他们也有抽风的时候,而且一抽风就会导致服务器性能下降,请求量跟网络攻击没什么区别。
3 反爬虫领域常见的一些概念
因为反爬虫暂时是个较新的领域,因此有些定义要自己下:
-
爬虫:使用任何技术手段,批量获取网站信息的一种方式。关键在于批量。
-
反爬虫:使用任何技术手段,阻止别人批量获取自己网站信息的一种方式。关键也在于批量。
-
误伤:在反爬虫的过程中,错误的将普通用户识别为爬虫。误伤率高的反爬虫策略,效果再好也不能用。
-
拦截:成功地阻止爬虫访问。这里会有拦截率的概念。通常来说,拦截率越高的反爬虫策略,误伤的可能性就越高。因此需要做个权衡。
-
资源:机器成本与人力成本的总和。
这里要切记,人力成本也是资源,而且比机器更重要。因为,根据摩尔定律,机器越来越便宜。而根据IT行业的发展趋势,程序员工资越来越贵。因此,通常服务器反爬就是让爬虫工程师加班才是王道,机器成本并不是特别值钱。
4 反爬的三个方向
-
基于身份识别进行反爬
-
基于爬虫行为进行反爬
-
基于数据加密进行反爬
5 常见基于身份识别进行反爬
1 通过headers字段来反爬
headers中有很多字段,这些字段都有可能会被对方服务器拿过来进行判断是否为爬虫
1.1 通过headers中的User-Agent字段来反爬
-
反爬原理:爬虫默认情况下没有User-Agent,而是使用模块默认设置
-
解决方法:请求之前添加User-Agent即可;更好的方式是使用User-Agent池来解决(收集一堆User-Agent的方式,或者是随机生成User-Agent)
1.2 通过referer字段或者是其他字段来反爬
-
反爬原理:爬虫默认情况下不会带上referer字段,服务器端通过判断请求发起的源头,以此判断请求是否合法
-
解决方法:添加referer字段
1.3 通过cookie来反爬
-
反爬原因:通过检查cookies来查看发起请求的用户是否具备相应权限,以此来进行反爬
-
解决方案:进行模拟登陆,成功获取cookies之后在进行数据爬取
2 通过请求参数来反爬
请求参数的获取方法有很多,向服务器发送请求,很多时候需要携带请求参数,通常服务器端可以通过检查请求参数是否正确来判断是否为爬虫
2.1 通过从html静态文件中获取请求数据(github登录数据)
-
反爬原因:通过增加获取请求参数的难度进行反爬
-
解决方案:仔细分析抓包得到的每一个包,搞清楚请求之间的联系
2.2 通过发送请求获取请求数据
-
反爬原因:通过增加获取请求参数的难度进行反爬
-
解决方案:仔细分析抓包得到的每一个包,搞清楚请求之间的联系,搞清楚请求参数的来源
2.3 通过js生成请求参数
-
反爬原理:js生成了请求参数
-
解决方法:分析js,观察加密的实现过程,通过js2py获取js的执行结果,或者使用selenium来实现
2.4 通过验证码来反爬
-
反爬原理:对方服务器通过弹出验证码强制验证用户浏览行为
-
解决方法:打码平台或者是机器学习的方法识别验证码,其中打码平台廉价易用,更值得推荐
6 常见基于爬虫行为进行反爬
1 基于请求频率或总请求数量
爬虫的行为与普通用户有着明显的区别,爬虫的请求频率与请求次数要远高于普通用户
1.1 通过请求ip/账号单位时间内总请求数量进行反爬
-
反爬原理:正常浏览器请求网站,速度不会太快,同一个ip/账号大量请求了对方服务器,有更大的可能性会被识别为爬虫
-
解决方法:对应的通过购买高质量的ip的方式能够解决问题/购买个多账号
1.2 通过同一ip/账号请求之间的间隔进行反爬
-
反爬原理:正常人操作浏览器浏览网站,请求之间的时间间隔是随机的,而爬虫前后两个请求之间时间间隔通常比较固定同时时间间隔较短,因此可以用来做反爬
-
解决方法:请求之间进行随机等待,模拟真实用户操作,在添加时间间隔后,为了能够高速获取数据,尽量使用代理池,如果是账号,则将账号请求之间设置随机休眠
1.3 通过对请求ip/账号每天请求次数设置阈值进行反爬
-
反爬原理:正常的浏览行为,其一天的请求次数是有限的,通常超过某一个值,服务器就会拒绝响应
-
解决方法:对应的通过购买高质量的ip的方法/多账号,同时设置请求间随机休眠
2 根据爬取行为进行反爬,通常在爬取步骤上做分析
2.1 通过js实现跳转来反爬
-
反爬原理:js实现页面跳转,无法在源码中获取下一页url
-
解决方法: 多次抓包获取条状url,分析规律
2.2 通过蜜罐(陷阱)获取爬虫ip(或者代理ip),进行反爬
-
反爬原理:在爬虫获取链接进行请求的过程中,爬虫会根据正则,xpath,css等方式进行后续链接的提取,此时服务器端可以设置一个陷阱url,会被提取规则获取,但是正常用户无法获取,这样就能有效的区分爬虫和正常用户
-
解决方法: 完成爬虫的编写之后,使用代理批量爬取测试/仔细分析响应内容结构,找出页面中存在的陷阱
2.3 通过假数据反爬
-
反爬原理:向返回的响应中添加假数据污染数据库,通常家属剧不会被正常用户看到
-
解决方法: 长期运行,核对数据库中数据同实际页面中数据对应情况,如果存在问题/仔细分析响应内容
2.4 阻塞任务队列
-
反爬原理:通过生成大量垃圾url,从而阻塞任务队列,降低爬虫的实际工作效率
-
解决方法: 观察运行过程中请求响应状态/仔细分析源码获取垃圾url生成规则,对URL进行过滤
2.5 阻塞网络IO
-
反爬原理:发送请求获取响应的过程实际上就是下载的过程,在任务队列中混入一个大文件的url,当爬虫在进行该请求时将会占用网络io,如果是有多线程则会占用线程
-
解决方法: 观察爬虫运行状态/多线程对请求线程计时/发送请求钱
2.6 运维平台综合审计
-
反爬原理:通过运维平台进行综合管理,通常采用复合型反爬虫策略,多种手段同时使用
-
解决方法: 仔细观察分析,长期运行测试目标网站,检查数据采集速度,多方面处理
7 常见基于数据加密进行反爬
1 对响应中含有的数据进行特殊化处理
通常的特殊化处理主要指的就是css数据偏移/自定义字体/数据加密/数据图片/特殊编码格式等
1.1 通过自定义字体来反爬 下图来自汽车之家论坛
-
反爬思路: 使用自有字体文件
-
解决思路:切换到手机版/解析字体文件进行翻译
1.3 通过js动态生成数据进行反爬
-
反爬原理:通过js动态生成
-
解决思路:解析关键js,获得数据生成流程,模拟生成数据
1.4 通过数据图片化反爬
-
58同城短租
-
解决思路:通过使用图片解析引擎从图片中解析数据
1.5 通过编码格式进行反爬
-
反爬原理: 不适用默认编码格式,在获取响应之后通常爬虫使用utf-8格式进行解码,此时解码结果将会是乱码或者报错
-
解决思路:根据源码进行多格式解码,或者真正的解码格式
小结
-
掌握 常见的反爬手段、原理以及应对思路

验证码处理
学习目标
-
了解 验证码的相关知识
-
掌握 图片识别引擎的使用
-
了解 常见的打码平台
-
掌握 通过打码平台处理验证码的方法
1.图片验证码
1.1 什么是图片验证码
-
验证码(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart”(全自动区分计算机和人类的图灵测试)的缩写,是一种区分用户是计算机还是人的公共全自动程序。
1.2 验证码的作用
-
防止恶意破解密码、刷票、论坛灌水、刷页。有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登录尝试,实际上使用验证码是现在很多网站通行的方式(比如招商银行的网上个人银行,百度社区),我们利用比较简易的方式实现了这个功能。虽然登录麻烦一点,但是对网友的密码安全来说这个功能还是很有必要,也很重要。
1.3 图片验证码在爬虫中的使用场景
-
注册
-
登录
-
频繁发送请求时,服务器弹出验证码进行验证
1.4 图片验证码的处理方案
-
手动输入(input) 这种方法仅限于登录一次就可持续使用的情况
-
图像识别引擎解析 使用光学识别引擎处理图片中的数据,目前常用于图片数据提取,较少用于验证码处理
-
打码平台 爬虫常用的验证码解决方案
2.图片识别引擎
OCR(Optical Character Recognition)是指使用扫描仪或数码相机对文本资料进行扫描成图像文件,然后对图像文件进行分析处理,自动识别获取文字信息及版面信息的软件。
2.1 什么是tesseract
-
Tesseract,一款由HP实验室开发由Google维护的开源OCR引擎,特点是开源,免费,支持多语言,多平台。
2.2 图片识别引擎环境的安装
1 引擎的安装
-
mac环境下直接执行命令
brew install --with-training-tools tesseract
-
windows环境下的安装 可以通过exe安装包安装,下载地址可以从GitHub项目中的wiki找到。安装完成后记得将Tesseract 执行文件的目录加入到PATH中,方便后续调用。
-
linux环境下的安装
sudo apt-get install tesseract-ocr
2 Python库的安装
# PIL用于打开图片文件 pip/pip3 install pillow # pytesseract模块用于从图片中解析数据 pip/pip3 install pytesseract
2.3 图片识别引擎的使用
-
通过pytesseract模块的 image_to_string 方法就能将打开的图片文件中的数据提取成字符串数据,具体方法如下
from PIL import Image import pytesseract im = Image.open() result = pytesseract.image_to_string(im) print(result)
2.4 图片识别引擎的使用扩展
-
其他ocr平台
微软Azure 图像识别:https://azure.microsoft.com/zh-cn/services/cognitive-services/computer-vision/ 有道智云文字识别:http://aidemo.youdao.com/ocrdemo 阿里云图文识别:https://www.aliyun.com/product/cdi/ 腾讯OCR文字识别:https://cloud.tencent.com/product/ocr

3 打码平台
1.为什么需要了解打码平台的使用
现在很多网站都会使用验证码来进行反爬,所以为了能够更好的获取数据,需要了解如何使用打码平台爬虫中的验证码
2 常见的打码平台
-
能够解决通用的验证码识别
-
极验验证码智能识别辅助:http://jiyandoc.c2567.com/
能够解决复杂验证码的识别
3 云打码的使用
下面以云打码为例,了解打码平台如何使用
3.1 云打码官方接口
下面代码是云打码平台提供,做了个简单修改,实现了两个方法:
-
indetify:传入图片的响应二进制数即可
-
indetify_by_filepath:传入图片的路径即可识别
其中需要自己配置的地方是:
username = 'whoarewe' # 用户名 password = '***' # 密码 appid = 4283 # appid appkey = '02074c64f0d0bb9efb2df455537b01c3' # appkey codetype = 1004 # 验证码类型
云打码官方提供的api如下:
#yundama.py
import requests
import json
import time
class YDMHttp:
apiurl = 'http://api.yundama.com/api.php'
username = ''
password = ''
appid = ''
appkey = ''
def __init__(self, username, password, appid, appkey):
self.username = username
self.password = password
self.appid = str(appid)
self.appkey = appkey
def request(self, fields, files=[]):
response = self.post_url(self.apiurl, fields, files)
response = json.loads(response)
return response
def balance(self):
data = {'method': 'balance', 'username': self.username, 'password': self.password, 'appid': self.appid,
'appkey': self.appkey}
response = self.request(data)
if (response):
if (response['ret'] and response['ret'] < 0):
return response['ret']
else:
return response['balance']
else:
return -9001
def login(self):
data = {'method': 'login', 'username': self.username, 'password': self.password, 'appid': self.appid,
'appkey': self.appkey}
response = self.request(data)
if (response):
if (response['ret'] and response['ret'] < 0):
return response['ret']
else:
return response['uid']
else:
return -9001
def upload(self, filename, codetype, timeout):
data = {'method': 'upload', 'username': self.username, 'password': self.password, 'appid': self.appid,
'appkey': self.appkey, 'codetype': str(codetype), 'timeout': str(timeout)}
file = {'file': filename}
response = self.request(data, file)
if (response):
if (response['ret'] and response['ret'] < 0):
return response['ret']
else:
return response['cid']
else:
return -9001
def result(self, cid):
data = {'method': 'result', 'username': self.username, 'password': self.password, 'appid': self.appid,
'appkey': self.appkey, 'cid': str(cid)}
response = self.request(data)
return response and response['text'] or ''
def decode(self, filename, codetype, timeout):
cid = self.upload(filename, codetype, timeout)
if (cid > 0):
for i in range(0, timeout):
result = self.result(cid)
if (result != ''):
return cid, result
else:
time.sleep(1)
return -3003, ''
else:
return cid, ''
def post_url(self, url, fields, files=[]):
# for key in files:
# files[key] = open(files[key], 'rb');
res = requests.post(url, files=files, data=fields)
return res.text
username = 'whoarewe' # 用户名
password = '***' # 密码
appid = 4283 # appid
appkey = '02074c64f0d0bb9efb2df455537b01c3' # appkey
filename = 'getimage.jpg' # 文件位置
codetype = 1004 # 验证码类型
# 超时
timeout = 60
def indetify(response_content):
if (username == 'username'):
print('请设置好相关参数再测试')
else:
# 初始化
yundama = YDMHttp(username, password, appid, appkey)
# 登陆云打码
uid = yundama.login();
print('uid: %s' % uid)
# 查询余额
balance = yundama.balance();
print('balance: %s' % balance)
# 开始识别,图片路径,验证码类型ID,超时时间(秒),识别结果
cid, result = yundama.decode(response_content, codetype, timeout)
print('cid: %s, result: %s' % (cid, result))
return result
def indetify_by_filepath(file_path):
if (username == 'username'):
print('请设置好相关参数再测试')
else:
# 初始化
yundama = YDMHttp(username, password, appid, appkey)
# 登陆云打码
uid = yundama.login();
print('uid: %s' % uid)
# 查询余额
balance = yundama.balance();
print('balance: %s' % balance)
# 开始识别,图片路径,验证码类型ID,超时时间(秒),识别结果
cid, result = yundama.decode(file_path, codetype, timeout)
print('cid: %s, result: %s' % (cid, result))
return result
if __name__ == '__main__':
pass
4 常见的验证码的种类
4.1 url地址不变,验证码不变
这是验证码里面非常简单的一种类型,对应的只需要获取验证码的地址,然后请求,通过打码平台识别即可
4.2 url地址不变,验证码变化
这种验证码的类型是更加常见的一种类型,对于这种验证码,大家需要思考:
在登录的过程中,假设我输入的验证码是对的,对方服务器是如何判断当前我输入的验证码是显示在我屏幕上的验证码,而不是其他的验证码呢?
在获取网页的时候,请求验证码,以及提交验证码的时候,对方服务器肯定通过了某种手段验证我之前获取的验证码和最后提交的验证码是同一个验证码,那这个手段是什么手段呢?
很明显,就是通过cookie来实现的,所以对应的,在请求页面,请求验证码,提交验证码的到时候需要保证cookie的一致性,对此可以使用requests.session来解决
小结
-
了解 验证码的相关知识
-
掌握 图片识别引擎的使用
-
了解 常见的打码平台
-
掌握 通过打码平台处理验证码的方法

chrome浏览器使用方法介绍
学习目标
-
了解 新建隐身窗口的目的
-
了解 chrome中network的使用
-
了解 寻找登录接口的方法
1 新建隐身窗口
浏览器中直接打开网站,会自动带上之前网站时保存的cookie,但是在爬虫中首次获取页面是没有携带cookie的,这种情况如何解决呢?
使用隐身窗口,首次打开网站,不会带上cookie,能够观察页面的获取情况,包括对方服务器如何设置cookie在本地
2 chrome中network的更多功能
2.1 Perserve log
默认情况下,页面发生跳转之后,之前的请求url地址等信息都会消失,勾选perserve log后之前的请求都会被保留
2.2 filter过滤
在url地址很多的时候,可以在filter中输入部分url地址,对所有的url地址起到一定的过滤效果,具体位置在上面第二幅图中的2的位置
2.3 观察特定种类的请求
在上面第二幅图中的3的位置,有很多选项,默认是选择的all,即会观察到所有种类的请求
很多时候处于自己的目的可以选择all右边的其他选项,比如常见的选项:
-
XHR:大部分情况表示ajax请求
-
JS:js请求
-
CSS:css请求
但是很多时候我们并不能保证我们需要的请求是什么类型,特别是我们不清楚一个请求是否为ajax请求的时候,直接选择all,从前往后观察即可,其中js,css,图片等不去观察即可
不要被浏览器中的一堆请求吓到了,这些请求中除了js,css,图片的请求外,其他的请求并没有多少个
3 寻找登录接口
回顾之前人人网的爬虫我们找到了一个登陆接口,那么这个接口从哪里找到的呢?
3.1 寻找action对的url地址
可以发现,这个地址就是在登录的form表单中action对应的url地址,回顾前端的知识点,可以发现就是进行表单提交的地址,对应的,提交的数据,仅仅需要:用户名的input标签中,name的值作为键,用户名作为值,密码的input标签中,name的值作为键,密码作为值即可
思考:
如果action对应的没有url地址的时候可以怎么做?
3.2 通过抓包寻找登录的url地址
通过抓包可以发现,在这个url地址和请求体中均有参数,比如uniqueTimestamp和rkey以及加密之后的password
这个时候我们可以观察手机版的登录接口,是否也是一样的
可以发现在手机版中,依然有参数,但是参数的个数少一些,这个时候,我们可以使用手机版作为参考,下一节来学习如何分析js
小结
-
使用隐身窗口的主要目的是为了避免首次打开网站携带cookie的问题
-
chrome的network中,perserve log选项能够在页面发生跳转之后任然能够观察之前的请求
-
确定登录的地址有两种方法:
-
寻找from表单action的url地址
-
通过抓包获取
-
JS的解析
学习目标:
-
了解 定位js的方法
-
了解 添加断点观察js的执行过程的方法
-
应用 js2py获取js的方法
1 确定js的位置
对于前面人人网的案例,我们知道了url地址中有部分参数,但是参数是如何生成的呢?
毫无疑问,参数肯定是js生成的,那么如何获取这些参数的规律呢?通过下面的学习来了解
1.1 观察按钮的绑定js事件
通过点击按钮,然后点击Event Listener,部分网站可以找到绑定的事件,对应的,只需要点击即可跳转到js的位置
1.2 通过search all file 来搜索
部分网站的按钮可能并没有绑定js事件监听,那么这个时候可以通过搜索请求中的关键字来找到js的位置,比如livecell
点击美化输出选项
可以继续在其中搜索关键字
2 观察js的执行过程
找到js的位置之后,我们可以来通过观察js的位置,找到js具体在如何执行,后续我们可以通过python程序来模拟js的执行,或者是使用类似js2py直接把js代码转化为python程序去执行
观察js的执行过程最简单的方式是添加断点
添加断点的方式:在左边行号点击即可添加,对应的右边BreakPoints中会出现现有的所有断点
添加断点之后继续点击登录,每次程序在断点位置都会停止,通过如果该行有变量产生,都会把变量的结果展示在Scoope中
在上图的右上角有1,2,3三个功能,分别表示: – 1:继续执行到下一个断点 – 2:进入调用的函数中 – 3:从调用的函数中跳出来
3 js2py的使用
在知道了js如何生成我们想要的数据之后,那么接下来我们就需要使用程序获取js执行之后的结果了
3.1 js2py的介绍
js2py是一个js的翻译工具,也是一个通过纯python实现的js的解释器。
3.2 js的执行思路
js的执行方式大致分为两种:
-
在了解了js内容和执行顺序之后,通过python来完成js的执行过程,得到结果
-
在了解了js内容和执行顺序之后,使用类似js2py的模块来执js代码,得到结果
但是在使用python程序实现js的执行时候,需要观察的js的每一个步骤,非常麻烦,所以更多的时候我们会选择使用类似js2py的模块去执行js,接下来我们来使用js2py实现人人网登录参数的获取
3.3 具体的实现
定位进行登录js代码
formSubmit: function() {
var e, t = {};
$(".login").addEventListener("click", function() {
t.phoneNum = $(".phonenum").value,
t.password = $(".password").value,
e = loginValidate(t),
t.c1 = c1 || 0,
e.flag ? ajaxFunc("get", "http://activity.renren.com/livecell/rKey", "", function(e) {
var n = JSON.parse(e).data;
if (0 == n.code) {
t.password = t.password.split("").reverse().join(""),
setMaxDigits(130);
var o = new RSAKeyPair(n.e,"",n.n)
, r = encryptedString(o, t.password);
t.password = r,
t.rKey = n.rkey
} else
toast("公钥获取失败"),
t.rKey = "";
ajaxFunc("post", "http://activity.renren.com/livecell/ajax/clog", t, function(e) {
var e = JSON.parse(e).logInfo;
0 == e.code ? location.href = localStorage.getItem("url") || "" : toast(e.msg || "登录出错")
})
}) : toast(e.msg)
})
}
从代码中我们知道:
-
我们要登录需要对密码进行加密和获取rkey字段的值
-
rkey字段的值我们直接发送请求rkey请求就可以获得
-
密码是先反转然后使用RSA进行加密, js代码很复杂, 我们希望能通过在python中执行js来实现
实现思路:
-
使用session发送rKey获取登录需要信息
-
url
-
方法: get
-
-
根据获取信息对密码进行加密 2.1 准备用户名和密码
2.2 使用js2py生成js的执行环境:context
2.3 拷贝使用到js文件的内容到本项目中
2.4 读取js文件的内容,使用context来执行它们
2.5 向context环境中添加需要数据
2.6 使用context执行加密密码的js字符串
2.7 通过context获取加密后密码信息
-
使用session发送登录请求
-
URL
-
请求方法: POST
-
数据:
phoneNum: xxxxxxx password: (加密后生产的) c1: 0 rKey: rkey请求获取的
-
具体代码
需要提前下载几个js文件到本地:
BigInt.js
RSA.js
Barrett.js
import requests
import json
import js2py
# - 实现思路:
# - 使用session发送rKey获取登录需要信息
# - url: http://activity.renren.com/livecell/rKey
# - 方法: get
# 获取session对象
session = requests.session()
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36",
"X-Requested-With": "XMLHttpRequest",
"Content-Type":"application/x-www-form-urlencoded"
}
# 设置session的请求头信息
session.headers = headers
response = session.get("http://activity.renren.com/livecell/rKey")
# print(response.content.decode())
n = json.loads(response.content)['data']
# - 根据获取信息对密码进行加密
# - 准备用户名和密码
phoneNum = "131..."
password = "****"
# - 使用js2py生成js的执行环境:context
context = js2py.EvalJs()
# - 拷贝使用到js文件的内容到本项目中
# - 读取js文件的内容,使用context来执行它们
with open("BigInt.js", 'r', encoding='utf8') as f:
context.execute(f.read())
with open("RSA.js", 'r', encoding='utf8') as f:
context.execute(f.read())
with open("Barrett.js", 'r', encoding='utf8') as f:
context.execute(f.read())
# - 向context环境中添加需要数据
context.t = {'password': password}
context.n = n
# - 执行加密密码的js字符
js = '''
t.password = t.password.split("").reverse().join(""),
setMaxDigits(130);
var o = new RSAKeyPair(n.e,"",n.n)
, r = encryptedString(o, t.password);
'''
context.execute(js)
# - 通过context获取加密后密码信息
# print(context.r)
password = context.r
# - 使用session发送登录请求
# - URL: http://activity.renren.com/livecell/ajax/clog
# - 请求方法: POST
# - 数据:
# - phoneNum: 15565280933
# - password: (加密后生产的)
# - c1: 0
# - rKey: rkey请求获取的
data = {
'phoneNum': '131....',
'password': password,
'c1':0,
'rKey':n['rkey']
}
# print(session.headers)
response = session.post("http://activity.renren.com/livecell/ajax/clog", data=data)
print(response.content.decode())
# 访问登录的资源
response = session.get("http://activity.renren.com/home#profile")
print(response.content.decode())
小结
-
通过在chrome中观察元素的绑定事件可以确定js
-
通过在chrome中search all file 搜索关键字可以确定js的位置
-
观察js的数据生成过程可以使用添加断点的方式观察
-
js2py的使用
-
需要准备js的内容
-
生成js的执行环境
-
在执行环境中执行js的字符串,传入数据,获取结果
-
大家好,我是辣条。
今天给大家带来下部分的教程,全文比较长,可以先收藏在慢慢看。
六、mongodb数据库
Mongodb的介绍和安装
学习目标
-
了解 非关系型数据库的优势
-
了解 mongodb的安装
1. mongodb的介绍
1.1 什么是mongodb
-
mongodb 是一个功能最丰富的NoSQL非关系数据库。由 C++ 语言编写。
-
mongodb 本身提供S端存储数据,即server;也提供C端操作处理(如查询等)数据,即client。
1.2 SQL和NoSQL的主要区别
-
在SQL中层级关系: 数据库>表>数据
-
而在NoSQL中则是: 数据库>集合>文档
1.2.1 数据之间无关联性
-
SQL中如何需要增加外部关联数据的话,规范化做法是在原表中增加一个外键,关联外部数据表。
-
NoSQL则可以把外部数据直接放到原数据集中,以提高查询效率。缺点也比较明显,对关联数据做更新时会比较麻烦。
-
SQL中在一个表中的每条数据的字段是固定的。而NoSQL中的一个集合(表)中的每条文档(数据)的key(字段)可以是互不相同的。
1.3 mongodb作为非关系型数据库相较于关系型数据库的优势
易扩展: NoSQL数据库种类繁多, 但是一个共同的特点都是去掉关系数据库的关系型特性。 数据之间无关系, 这样就非常容易扩展
大数据量,高性能: NoSQL数据库都具有非常高的读写性能, 尤其在大数据量下表现优秀。 这得益于它的非关系性,数据库的结构简单
灵活的数据模型: NoSQL无需事先为要存储的数据建立字段, 随时可以存储自定义的数据格式。 而在关系数据库中, 增删字段是一件非常麻烦的事情。 如果是非常大数据量的表, 增加字段简直就是一个噩梦
2. mongodb的安装
以ubuntu18.04为例
mongodb具有两种安装方式:命令安装 或 源码安装
2.1 命令安装
在ubuntu中使用apt-get工具安装
sudo apt-get install -y mongodb-org
或参考官方文档 Install MongoDB Community Edition on Ubuntu — MongoDB Manual
2.2 源码安装
2.2.1 选择相应版本和操作系统并下载
2.2.2 解压
tar -zxvf mongodb-linux-x86_64-ubuntu1804-4.0.3.tgz
2.2.3 移动到/usr/local/目录下
sudo mv -r mongodb-linux-x86_64-ubuntu1804-4.0.3/ /usr/local/mongodb
2.2.4 在shell的初始化脚本.bashrc中添加mongodb可执行文件到环境变量PATH中
a. 进入.bashrc文件中
cd ~ sudo vi .bashrc
b. 在.bashrc文件的最后添加:
export PATH=/usr/local/mongodb/bin:$PATH
3. mongodb的官方文档
小结
-
了解 非关系型数据库的优势
-
易扩展
-
高性能
-
灵活的数据字段
-
-
了解 mongodb的安装
-
sudo apt-get install -y mongodb-org
-
mongodb的简单使用
学习目标
-
掌握 服务端的启动
-
掌握 客户端的使用
-
掌握 mongodb的数据库和集合命令
-
了解 文档中的_id字段
1. mongodb服务端的启动
-
默认端口:27017
-
默认配置文件的位置:/etc/mongod.conf
-
默认日志的位置:/var/log/mongodb/mongod.log
mongodb服务端启动分别两种方式:
-
本地测试方式的启动(只具有本地数据增删改查的功能)
-
生产环境启动(具有完整的全部功能)
1.1 测试方式启动
-
启动: sudo service mongod start (sudo service mongod start)
-
停止: sudo service mongod stop
-
重启: sudo service mongod restart
1.2 生产环境正式的启动方式
启动: sudo mongod [–auth –dbpath=dbpath –logpath=logpath –append –fork] [-–f logfile ]
-
只以 sudo mongod 命令启动时,默认将数据存放在了 /data/db 目录下,需要手动创建
-
–dbpath: 指定数据库的存放路径
-
–logpath: 指定日志的存放路径
-
–append: 或–logappend 设置日志的写入形式为追加模式
-
–fork: 或-fork 开启新的进程运行mongodb服务
-
–f: 或-f 配置文件路径(可以将上述配置信息写入文件然后通过该文件中的参数进行加载启动)
-
–auth: 以权限认证的方式启动,我们会在后边的课程中学习该内容
1.3 查看是否启动成功
ps aux | grep mongod
2. 启动mongodb的客户端:进入mongo shell
-
启动本地客户端: mongo
-
查看帮助:mongo –help
-
退出:exit或者ctrl+c
3. mongodb的简单使用
开启mongodb server的情况下,在进入mongo shell后,就可以做简单的使用了
3.1 mongodb数据库的命令
-
查看当前的数据库:db(没有切换数据库的情况下默认使用test数据库)
-
查看所有的数据库:show dbs /show databases
-
切换数据库:use db_name
-
db_name为show dbs后返回的数据库名
-
-
删除当前的数据库:db.dropDatabase()
3.2 mongodb集合的命令
-
无需手动创建集合: 向不存在的集合中第一次添加数据时,集合会自动被创建出来
-
手动创建集合:
-
db.createCollection(name,options)
-
db.createCollection(“stu”)
-
db.createCollection(“sub”, { capped : true, size : 10 } )
-
参数capped:默认值为false表示不设置上限,值为true表示设置上限
-
参数size:集合所占用的字节数。 当capped值为true时,需要指定此参数,表示上限大小,当文档达到上限时, 会将之前的数据覆盖,单位为字节
-
-
查看集合:show collections
-
删除集合:db.集合名称.drop()
-
检查集合是否设定上限: db.集合名.isCapped()
3.3 简单练习
在mongo shell中输入下列命令,查看结果
show dbs
use test
show collections
db
db.stu.insert({'name':'郭靖', 'age':22})
show dbs
show collections
db.stu.find()
db.stu.drop()
show collections
db.dropDatabase()
show dbs
exit
3.3 mongodb中常见的数据类型(了解)
3.3.1 常见类型
-
Object ID: 文档ID/数据的ID,数据的主键
-
String: 字符串,最常用,必须是有效的UTF-8
-
Boolean: 存储一个布尔值,true或false
-
Integer: 整数可以是32位或64位,这取决于服务器
-
Double: 浮点数
-
Arrays: 数组/列表
-
Object: mongodb中的一条数据/文档,即文档嵌套文档
-
Null: 存储null值
-
Timestamp: 时间戳,表示从1970-1-1到现在的总秒数
-
Date: 存储当前日期或时间的UNIX时间格式
3.3.2 注意点
-
每个文档都有一个属性,为id,保证每个文档的唯一性,mongodb默认使用id作为主键
-
可以手动设置id的值,如果没有提供,那么MongoDB为每个文档提供了一个独特的id, 类型为objectID
-
-
objectID是一个12字节的十六进制数,每个字节两位,一共是24位的字符串:
-
前4个字节为当前时间戳
-
接下来3个字节的机器ID
-
接下来的2个字节中MongoDB的服务进程id
-
最后3个字节是简单的增量值
-
小结
-
服务端的启动
-
sudo mongod –dbpath=数据库路径
-
-
进入mongo shell客户端
-
mongo
-
-
mongodb的数据库和集合命令
-
show dbs
-
use db_name
-
show collections
-
db
-
db.集合名.drop()
-
db.dropDatabase()
-
exit
-
-
了解文档中的_id字段
Mongodb的的增删改查
1. mongodb插入数据
命令:db.集合名称.insert(document)
db.stu.insert({name:'gj', gender:1})
db.stu.insert({_id:"20170101", name:'gj', gender:1})
插文档时,如果不指定_id参数,MongoDB会为文档自动分配一个唯一的ObjectId
2. mongodb的保存
命令:db.集合名称.save(document)
db.stu.save({_id:'20170101', name:'gj', gender:2})
db.stu.save({name:'gj', gender:2})
db.stu.find()
如果文档的id已经存在则修改,如果id不存在则添加
3 mongodb的查询
命令:db.集合名称.find()
可以使用以下数据进行练习
db.stu.insert([{"name" : "郭靖", "hometown" : "蒙古", "age" : 20, "gender" : true },
{"name" : "黄蓉", "hometown" : "桃花岛", "age" : 18, "gender" : false },
{"name" : "华筝", "hometown" : "蒙古", "age" : 18, "gender" : false },
{"name" : "黄药师", "hometown" : "桃花岛", "age" : 40, "gender" : true },
{"name" : "段誉", "hometown" : "大理", "age" : 16, "gender" : true },
{"name" : "段王爷", "hometown" : "大理", "age" : 45, "gender" : true },
{"name" : "洪七公", "hometown" : "华筝", "age" : 18, "gender" : true }])
3.1 简单查询
-
方法find(): 查询
db.集合名称.find({条件文档}) -
方法findOne():查询,只返回第一个
db.集合名称.findOne({条件文档}) -
方法pretty(): 将结果格式化;不能和findOne()一起使用!
db.集合名称.find({条件文档}).pretty()
3.2 比较运算符
-
等于: 默认是等于判断, 没有运算符
-
小于:
$lt (less than) -
小于等于:
$lte (less than equal) -
大于:
$gt (greater than) -
大于等于:
$gte -
不等于:
$ne
查询年龄大于18的所有学生
db.stu.find({age:{$gte:18}})
3.3 逻辑运算符
逻辑运算符主要指与、或逻辑
-
and:在json中写多个条件即可
查询年龄大于或等于18, 并且性别为true的学生
db.stu.find({age:{$gte:18},gender:true})
-
or:使用$or, 值为数组, 数组中每个元素为json
查询年龄大于18, 或性别为false的学生
db.stu.find({$or:[{age:{$gt:18}},{gender:false}]})
查询年龄大于18或性别为男生, 并且姓名是郭靖
db.stu.find({$or:[{age:{$gte:18}},{gender:true}],name:'gj'})
3.4 范围运算符
使用$in, $nin 判断数据是否在某个数组内
查询年龄为18、 28的学生
db.stu.find({age:{$in:[18,28,38]}})
3.5 支持正则表达式
使用$regex编写正则表达式
查询name以'黄'开头的数据
db.stu.find({name:{$regex:'^黄'}})
3.6 自定义查询
mongo shell 是一个js的执行环境 使用$where 写一个函数, 返回满足条件的数据
查询年龄大于30的学生
db.stu.find({
$where:function() {
return this.age>30;}
})
3.7 skip和limit
-
方法limit(): 用于读取指定数量的文档
db.集合名称.find().limit(NUMBER) 查询2条学生信息 db.stu.find().limit(2)
-
方法skip(): 用于跳过指定数量的⽂档
db.集合名称.find().skip(NUMBER) db.stu.find().skip(2)
-
同时使用
db.stu.find().limit(4).skip(5) db.stu.find().skip(5).limit(4)
注意:先使用skip在使用limit的效率要高于前者
3.8 投影
在查询到的返回结果中, 只选择必要的字段
命令:db.集合名称.find({},{字段名称:1,...})
参数为字段与值, 值为1表示显示, 值为0不显 特别注意:
-
对于_id列默认是显示的, 如果不显示需要明确设置为0
-
对于其他不显示的字段不能设置为0
db.stu.find({},{_id:0,name:1,gender:1})
3.9 排序
方法sort(), 用于对查询结果按照指定的字段进行排序
命令:db.集合名称.find().sort({字段:1,...})
参数1为升序排列 参数-1为降序排列
根据性别降序, 再根据年龄升序
db.stu.find().sort({gender:-1,age:1})
3.10 统计个数
方法count()用于统计结果集中文档条数
命令:db.集合名称.find({条件}).count() 命令:db.集合名称.count({条件})
db.stu.find({gender:true}).count()
db.stu.count({age:{$gt:20},gender:true})
4 mongodb的更新
db.集合名称.update({query}, {update}, {multi: boolean})
-
参数query:查询条件
-
参数update:更新操作符
-
参数multi:可选,默认是false,表示只更新找到的第一条数据,值为true表示把满足条件的数据全部更新
db.stu.update({name:'hr'},{name:'mnc'}) # 全文档进行覆盖更新
db.stu.update({name:'hr'},{$set:{name:'hys'}}) # 指定键值更新操作
db.stu.update({},{$set:{gender:0}},{multi:true}) # 更新全部
注意:”multi update only works with $ operators”
-
multi参数必须和$set一起使用!
5 mongodb的删除
db.集合名称.remove({query}, {justOne: boolean})
- 参数query:可选,删除的⽂档的条件 - 参数justOne:可选, 如果设为true或1,则只删除一条,默认false,表示删除全部
mongodb的聚合操作
1 mongodb的聚合是什么
聚合(aggregate)是基于数据处理的聚合管道,每个文档通过一个由多个阶段(stage)组成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理,输出相应的结果。
语法:db.集合名称.aggregate({管道:{表达式}})
2 mongodb的常用管道和表达式
知识点:
-
掌握mongodb中管道的语法
-
掌握mongodb中管道命令
2.1 常用管道命令
在mongodb中,⽂档处理完毕后, 通过管道进⾏下⼀次处理 常用管道命令如下:
-
$group: 将集合中的⽂档分组, 可⽤于统计结果 -
$match: 过滤数据, 只输出符合条件的⽂档 -
$project: 修改输⼊⽂档的结构, 如重命名、 增加、 删除字段、 创建计算结果 -
$sort: 将输⼊⽂档排序后输出 -
$limit: 限制聚合管道返回的⽂档数 -
$skip: 跳过指定数量的⽂档, 并返回余下的⽂档
2.2 常用表达式
表达式:处理输⼊⽂档并输出 语法:表达式:'$列名' 常⽤表达式:
-
$sum: 计算总和, $sum:1 表示以⼀倍计数 -
$avg: 计算平均值 -
$min: 获取最⼩值 -
$max: 获取最⼤值 -
$push: 在结果⽂档中插⼊值到⼀个数组中
3 管道命令之$group
3.1 按照某个字段进行分组
$group是所有聚合命令中用的最多的一个命令,用来将集合中的文档分组,可用于统计结果
使用示例如下
db.stu.aggregate(
{$group:
{
_id:"$gender",
counter:{$sum:1}
}
}
)
其中注意点:
-
db.db_name.aggregate是语法,所有的管道命令都需要写在其中 -
_id表示分组的依据,按照哪个字段进行分组,需要使用$gender表示选择这个字段进行分组 -
$sum:1表示把每条数据作为1进行统计,统计的是该分组下面数据的条数
3.2 group by null
当我们需要统计整个文档的时候,$group 的另一种用途就是把整个文档分为一组进行统计
使用实例如下:
db.stu.aggregate(
{$group:
{
_id:null,
counter:{$sum:1}
}
}
)
其中注意点:
-
_id:null表示不指定分组的字段,即统计整个文档,此时获取的counter表示整个文档的个数
3.3 数据透视
正常情况在统计的不同性别的数据的时候,需要知道所有的name,需要逐条观察,如果通过某种方式把所有的name放到一起,那么此时就可以理解为数据透视
使用示例如下:
-
统计不同性别的学生
db.stu.aggregate( {$group: { _id:null, name:{$push:"$name"} } } ) -
使用
$$ROOT可以将整个文档放入数组中db.stu.aggregate( {$group: { _id:null, name:{$push:"$$ROOT"} } } )
3.4 动手
对于如下数据,需要统计出每个country/province下的userid的数量(同一个userid只统计一次)
{ "country" : "china", "province" : "sh", "userid" : "a" }
{ "country" : "china", "province" : "sh", "userid" : "b" }
{ "country" : "china", "province" : "sh", "userid" : "a" }
{ "country" : "china", "province" : "sh", "userid" : "c" }
{ "country" : "china", "province" : "bj", "userid" : "da" }
{ "country" : "china", "province" : "bj", "userid" : "fa" }
参考答案
db.tv3.aggregate(
{$group:{_id:{country:'$country',province:'$province',userid:'$userid'}}},
{$group:{_id:{country:'$_id.country',province:'$_id.province'},count:{$sum:1}}}
4 管道命令之$match
$match用于进行数据的过滤,是在能够在聚合操作中使用的命令,和find区别在于$match 操作可以把结果交给下一个管道处理,而find不行
5 管道命令之$project
$project用于修改文档的输入输出结构,例如重命名,增加,删除字段
6 管道命令之$sort
$sort用于将输入的文档排序后输出
7 管道命令之$skip 和 $limit
-
$limit限制返回数据的条数 -
$skip跳过指定的文档数,并返回剩下的文档数 -
同时使用时先使用skip在使用limit
1. 为什么mongdb需要创建索引
-
加快查询速度
-
进行数据的去重
2. mongodb创建简单的索引方法
-
语法:
db.集合名.ensureIndex({属性:1}),1表示升序, -1表示降序
3. 创建索引前后查询速度对比
测试:插入10万条数据到数据库中
插入数据:
for(i=0;i<100000;i++){db.t1.insert({name:'test'+i,age:i})}
创建索引前:
db.t1.find({name:'test10000'})
db.t1.find({name:'test10000'}).explain('executionStats') # 显示查询操作的详细信息
创建索引:
db.t1.ensureIndex({name:1})
创建索引后:
db.t1.find({name:'test10000'}).explain('executionStats')
前后速度对比
4. 索引的查看
默认情况下_id是集合的索引 查看方式:db.集合名.getIndexes()
5. 删除索引
语法:db.集合名.dropIndex({'索引名称':1})
db.t1.dropIndex({name:1})
db.t1.getIndexes()
6. mongodb创建唯一索引
在默认情况下mongdb的索引域的值是可以相同的,创建唯一索引之后,数据库会在插入数据的时候检查创建索引域的值是否存在,如果存在则不会插入该条数据,但是创建索引仅仅能够提高查询速度,同时降低数据库的插入速度。
6.1 添加唯一索引的语法:
db.集合名.ensureIndex({"字段名":1}, {"unique":true})
6.2 利用唯一索引进行数据去重
根据唯一索引指定的字段的值,如果相同,则无法插入数据
db.t1.ensureIndex({"name":1}, {"unique":true})
db.t1.insert({name: 'test10000'})
7. 建立复合索引
在进行数据去重的时候,可能用一个域来保证数据的唯一性,这个时候可以考虑建立复合索引来实现。
例如:抓全贴吧信息,如果把帖子的名字作为唯一索引对数据进行去重是不可取的,因为可能有很多帖子名字相同
建立复合索引的语法:db.collection_name.ensureIndex({字段1:1,字段2:1})
8. 建立索引注意点
-
根据需要选择是否需要建立唯一索引
-
索引字段是升序还是降序在单个索引的情况下不影响查询效率,但是带复合索引的条件下会有影响
-
数据量巨大并且数据库的读出操作非常频繁的时候才需要创建索引,如果写入操作非常频繁,创建索引会影响写入速度
例如:在进行查询的时候如果字段1需要升序的方式排序输出,字段2需要降序的方式排序输出,那么此时复合索引的建立需要把字段1设置为1,字段2设置为-1
Mongodb的权限管理
1. 为什么要进行权限管理的设置
刚安装完毕的mongodb默认不使用权限认证方式启动,与MySQL不同,mongodb在安装的时候并没有设置权限,然而公网运行系统需要设置权限以保证数据安全,所以我们要学习mongodb的权限管理
2. mongodb的权限管理方案
-
MongoDB是没有默认管理员账号,所以要先添加管理员账号,并且mongodb服务器需要在运行的时候开启验证模式
-
用户只能在用户所在数据库登录(创建用户的数据库),包括管理员账号。
-
管理员可以管理所有数据库,但是不能直接管理其他数据库,要先认证后才可以。
-
3. mongodb超级管理员账号的创建
3.1 创建超级用户
进入mongo shell
sudo mongod
使用admin数据库(超级管理员账号必须创建在该数据库上)
use admin
创建超级用户
db.createUser({"user":"python","pwd":"python","roles":["root"]})
创建成功会显示如下信息
Successfully added user: { "user" : "python", "roles" : [ "root" ] }
退出mongo shell
exit
3.2 以权限认证的方式启动mongodb数据库
sudo mongod --auth
启动之后在启动信息中会有如下信息,说明mongodb以权限认证的方式启动成功
[initandlisten] options: { security: { authorization: "enabled" } }
3.3 登录验证
此时再使用数据库各命令的时候会报权限错误,需要认证才能执行相应操作、
use admin
db.auth('python','python')
-
python用户是创建在admin数据库上的所以必须来到admin数据库上进行认证
-
认证成功会返回1,失败返回0
4. 创建普通用户
4.1 在使用的数据库上创建普通用户
1.选择需要创建用户的数据库
use test1
-
创建用户
db.createUser("user":"user1", "pwd":"pwd1", roles:["read"])
创建普通用户user1,该用户在test1上的权限是只读
db.createUser("user":"user1", "pwd":"pwd1", roles:["readWrite"])
创建普通用户user1,该用户在test1上的权限是读写
4.2 在admin用户数据库上创建普通用户
use admin
db.createUser({"user":"python1", "pwd":"python1", roles:[{"role":"read","db":"dbname1"},{"role":"readWrite","db":"dbname2"}
]})
在admin上创建python1用户,python1用户的权限有两个,一个再dbname1上的只读,另一个是在dbname2上的读写
5. 查看创建的用户
show users
{
"_id" : "admin.python",
"user" : "python",
"db" : "admin",
"roles" : [
{
"role" : "root",
"db" : "admin"
}
]
}
6. 删除用户
6.1 进入账号数据所在的数据库
use db_name
6.2 删除用户
db.dropUser('python')
mongodb和python交互
1. mongdb和python交互的模块
pymongo 提供了mongdb和python交互的所有方法 安装方式: pip install pymongo
2. 使用pymongo
2.1 导入pymongo并选择要操作的集合
数据库和集合能够自动创建
2.1.1 无需权限认证的方式创建连接对象以及集合操作对象
from pymongo import MongoClient client = MongoClient(host,port) # 如果是本地连接host,port参数可以省略 collection = client[db名][集合名] # collection = client.db名.集合名 # 与上边用法相同
2.1.2 需要权限认证的方式创建连接对象以及集合操作对象
from pymongo import MongoClient from urllib.parse import quote_plus user = 'python' # 账号 password = 'python' # 密码 host = '127.0.0.1' # host port = 27017 # port uri = "mongodb://%s:%s@%s" % (quote_plus(user), quote_plus(password), host) # quote_plus函数:对url进行编码 # uri = mongodb://python:python@127.0.0.1 client = MongoClient(uri, port=port) collection = client.db名.集合名
2.2 insert()添加数据
insert可以批量的插入数据列表,也可以插入一条数据
collection.insert({一条数据})
collection.insert([{数据一},{数据二}])
2.2.1 添加一条数据
返回插入数据的_id
ret = collection.insert({"name":"test10010","age":33})
print(ret)
2.2.2 添加多条数据
返回ObjectId对象构成的列表
item_list = [{"name":"test1000{}".format(i)} for i in range(10)]
rets = collection.insert(item_list)
print(rets)
for ret in rets:
print(ret)
2.3 find_one()查找一条数据
接收一个字典形式的条件,返回字典形式的整条数据 如果条件为空,则返回第一条
ret = client.test.test.find_one({'name': 'test10001'})
print(ret) # 包含mongodb的ObjectId对象的字典
_ = ret.pop('_id') # 清除mongodb的ObjectId对象的k,v
print(ret)
2.4 find()查找全部数据
返回所有满足条件的结果,如果条件为空,则返回全部 结果是一个Cursor游标对象,是一个可迭代对象,可以类似读文件的指针,但是只能够进行一次读取
rets = collection.find({"name":"test10005"}),
for ret in rets:
print(ret)
for ret in rets: #此时rets中没有内容
print(ret)
2.5 update()更新数据(全文档覆盖或指定键值,更新一条或多条)
-
语法:collection.update({条件}, {‘$set’:{指定的kv或完整的一条数据}}, multi=False/True, upsert=False/True)
-
multi参数:默认为False,表示更新一条; multi=True则更新多条; multi参数必须和$set一起使用
-
upsert参数:默认为False; upsert=True则先查询是否存在,存在则更新;不存在就插入
-
$set表示指定字段进行更新
2.5.1 更新一条数据;全文档覆盖;存在就更新,不存在就插入
data = {'msg':'这是一条完整的数据1','name':'哈哈'}
client.test.test.update({'haha': 'heihei'}, {'$set':data}, upsert=True)
2.5.2 更新多条数据;全文档覆盖;存在就更新,不存在就插入
data = {'msg':'这是一条完整的数据2','name':'哈哈'} # 该完整数据是先查询后获取的
client.test.test.update({}, {'$set':data}, multi=True, upsert=True)
2.5.3 更新一条数据;指定键值;存在就更新,不存在就插入
data = {'msg':'指定只更新msg___1'}
client.test.test.update({}, {'$set':data}, upsert=True)
2.5.4 更新多条数据;指定键值;存在就更新,不存在就插入
data = {'msg':'指定只更新msg___2'}
client.test.test.update({}, {'$set':data}, multi=True, upsert=True)
2.6 delete_one()删除一条数据
collection.delete_one({"name":"test10010"})
2.7 delete_many()删除全部数据
collection.delete_many({"name":"test10010"})
3. pymongo模块其他api
查看pymongo官方文档或源代码 http://api.mongodb.com/python/current/
七、scrapy爬虫框架
scrapy的概念和流程
学习目标:
-
了解 scrapy的概念
-
了解 scrapy框架的作用
-
掌握 scrapy框架的运行流程
-
掌握 scrapy中每个模块的作用
1. scrapy的概念
Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。
Scrapy 使用了Twisted[‘twɪstɪd]异步网络框架,可以加快我们的下载速度。
2. scrapy框架的作用
少量的代码,就能够快速的抓取
3. scrapy的工作流程
其流程可以描述如下:
-
爬虫中起始的url构造成request对象–>爬虫中间件–>引擎–>调度器
-
调度器把request–>引擎–>下载中间件—>下载器
-
下载器发送请求,获取response响应—->下载中间件—->引擎—>爬虫中间件—>爬虫
-
爬虫提取url地址,组装成request对象—->爬虫中间件—>引擎—>调度器,重复步骤2
-
爬虫提取数据—>引擎—>管道处理和保存数据
注意:
-
图中中文是为了方便理解后加上去的
-
图中绿色线条的表示数据的传递
-
注意图中中间件的位置,决定了其作用
-
注意其中引擎的位置,所有的模块之前相互独立,只和引擎进行交互
3.4 scrapy的三个内置对象
-
request请求对象:由url method post_data headers等构成
-
response响应对象:由url body status headers等构成
-
item数据对象:本质是个字典
注意:
-
爬虫中间件和下载中间件只是运行逻辑的位置不同,作用是重复的:如替换UA等
小结
-
scrapy的概念:Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架
-
scrapy框架的运行流程以及数据传递过程:
-
爬虫中起始的url构造成request对象–>爬虫中间件–>引擎–>调度器
-
调度器把request–>引擎–>下载中间件—>下载器
-
下载器发送请求,获取response响应—->下载中间件—->引擎—>爬虫中间件—>爬虫
-
爬虫提取url地址,组装成request对象—->爬虫中间件—>引擎—>调度器,重复步骤2
-
爬虫提取数据—>引擎—>管道处理和保存数据
-
-
scrapy框架的作用:通过少量代码实现快速抓取
-
掌握scrapy中每个模块的作用: 引擎(engine):负责数据和信号在不腰痛模块间的传递 调度器(scheduler):实现一个队列,存放引擎发过来的request请求对象 下载器(downloader):发送引擎发过来的request请求,获取响应,并将响应交给引擎 爬虫(spider):处理引擎发过来的response,提取数据,提取url,并交给引擎 管道(pipeline):处理引擎传递过来的数据,比如存储 下载中间件(downloader middleware):可以自定义的下载扩展,比如设置代理ip 爬虫中间件(spider middleware):可以自定义request请求和进行response过滤,与下载中间件作用重复
scrapy的入门使用
学习目标:
-
掌握 scrapy的安装
-
应用 创建scrapy的项目
-
应用 创建scrapy爬虫
-
应用 运行scrapy爬虫
-
应用 scrapy定位以及提取数据或属性值的方法
-
掌握 response响应对象的常用属性
1 安装scrapy
命令: sudo apt-get install scrapy 或者: pip/pip3 install scrapy
2 scrapy项目开发流程
-
创建项目: scrapy startproject mySpider
-
生成一个爬虫: scrapy genspider itcast itcast.cn
-
提取数据: 根据网站结构在spider中实现数据采集相关内容
-
保存数据: 使用pipeline进行数据后续处理和保存
4. 创建爬虫
通过命令创建出爬虫文件,爬虫文件为主要的代码作业文件,通常一个网站的爬取动作都会在爬虫文件中进行编写。
命令: 在项目路径下执行: scrapy genspider <爬虫名字> <允许爬取的域名>
爬虫名字: 作为爬虫运行时的参数 允许爬取的域名: 为对于爬虫设置的爬取范围,设置之后用于过滤要爬取的url,如果爬取的url与允许的域不通则被过滤掉。
示例:
cd myspider scrapy genspider itcast itcast.cn
生成的目录和文件结果如下:
5. 完善爬虫
在上一步生成出来的爬虫文件中编写指定网站的数据采集操作,实现数据提取
5.1 在/myspider/myspider/spiders/itcast.py中修改内容如下:
import scrapy
class ItcastSpider(scrapy.Spider): # 继承scrapy.spider
# 爬虫名字
name = 'itcast'
# 允许爬取的范围
allowed_domains = ['itcast.cn']
# 开始爬取的url地址
start_urls = ['http://www.itcast.cn/channel/teacher.shtml']
# 数据提取的方法,接受下载中间件传过来的response
def parse(self, response):
# scrapy的response对象可以直接进行xpath
names = response.xpath('//div[@class="tea_con"]//li/div/h3/text()')
print(names)
# 获取具体数据文本的方式如下
# 分组
li_list = response.xpath('//div[@class="tea_con"]//li')
for li in li_list:
# 创建一个数据字典
item = {}
# 利用scrapy封装好的xpath选择器定位元素,并通过extract()或extract_first()来获取结果
item['name'] = li.xpath('.//h3/text()').extract_first() # 老师的名字
item['level'] = li.xpath('.//h4/text()').extract_first() # 老师的级别
item['text'] = li.xpath('.//p/text()').extract_first() # 老师的介绍
print(item)
注意:
-
scrapy.Spider爬虫类中必须有名为parse的解析
-
如果网站结构层次比较复杂,也可以自定义其他解析函数
-
在解析函数中提取的url地址如果要发送请求,则必须属于allowed_domains范围内,但是start_urls中的url地址不受这个限制,我们会在后续的课程中学习如何在解析函数中构造发送请求
-
启动爬虫的时候注意启动的位置,是在项目路径下启动
-
parse()函数中使用yield返回数据,注意:解析函数中的yield能够传递的对象只能是:BaseItem, Request, dict, None
5.2 定位元素以及提取数据、属性值的方法
解析并获取scrapy爬虫中的数据: 利用xpath规则字符串进行定位和提取
-
response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法
-
额外方法extract():返回一个包含有字符串的列表
-
额外方法extract_first():返回列表中的第一个字符串,列表为空没有返回None
5.3 response响应对象的常用属性
-
response.url:当前响应的url地址
-
response.request.url:当前响应对应的请求的url地址
-
response.headers:响应头
-
response.requests.headers:当前响应的请求头
-
response.body:响应体,也就是html代码,byte类型
-
response.status:响应状态码
6 保存数据
利用管道pipeline来处理(保存)数据
6.1 在pipelines.py文件中定义对数据的操作
-
定义一个管道类
-
重写管道类的process_item方法
-
process_item方法处理完item之后必须返回给引擎
import json class ItcastPipeline(): # 爬虫文件中提取数据的方法每yield一次item,就会运行一次 # 该方法为固定名称函数 def process_item(self, item, spider): print(item) return item
6.2 在settings.py配置启用管道
ITEM_PIPELINES = {
'myspider.pipelines.ItcastPipeline': 400
}
配置项中键为使用的管道类,管道类使用.进行分割,第一个为项目目录,第二个为文件,第三个为定义的管道类。 配置项中值为管道的使用顺序,设置的数值约小越优先执行,该值一般设置为1000以内。
7. 运行scrapy
命令:在项目目录下执行scrapy crawl <爬虫名字>
示例:scrapy crawl itcast
小结
-
scrapy的安装:pip install scrapy
-
创建scrapy的项目: scrapy startproject myspider
-
创建scrapy爬虫:在项目目录下执行 scrapy genspider itcast itcast.cn
-
运行scrapy爬虫:在项目目录下执行 scrapy crawl itcast
-
解析并获取scrapy爬虫中的数据:
-
response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法
-
extract() 返回一个包含有字符串的列表
-
extract_first() 返回列表中的第一个字符串,列表为空没有返回None
-
-
scrapy管道的基本使用:
-
完善pipelines.py中的process_item函数
-
在settings.py中设置开启pipeline
-
-
response响应对象的常用属性
-
response.url:当前响应的url地址
-
response.request.url:当前响应对应的请求的url地址
-
response.headers:响应头
-
response.requests.headers:当前响应的请求头
-
response.body:响应体,也就是html代码,byte类型
-
response.status:响应状态码
-
scrapy数据建模与请求
学习目标:
-
应用 在scrapy项目中进行建模
-
应用 构造Request对象,并发送请求
-
应用 利用meta参数在不同的解析函数中传递数据
1. 数据建模
通常在做项目的过程中,在items.py中进行数据建模
1.1 为什么建模
-
定义item即提前规划好哪些字段需要抓,防止手误,因为定义好之后,在运行过程中,系统会自动检查
-
配合注释一起可以清晰的知道要抓取哪些字段,没有定义的字段不能抓取,在目标字段少的时候可以使用字典代替
-
使用scrapy的一些特定组件需要Item做支持,如scrapy的ImagesPipeline管道类,百度搜索了解更多
1.2 如何建模
在items.py文件中定义要提取的字段:
class MyspiderItem(scrapy.Item): name = scrapy.Field() # 讲师的名字 title = scrapy.Field() # 讲师的职称 desc = scrapy.Field() # 讲师的介绍
1.3 如何使用模板类
模板类定义以后需要在爬虫中导入并且实例化,之后的使用方法和使用字典相同
job.py:
from myspider.items import MyspiderItem # 导入Item,注意路径
...
def parse(self, response)
item = MyspiderItem() # 实例化后可直接使用
item['name'] = node.xpath('./h3/text()').extract_first()
item['title'] = node.xpath('./h4/text()').extract_first()
item['desc'] = node.xpath('./p/text()').extract_first()
print(item)
注意:
-
from myspider.items import MyspiderItem这一行代码中 注意item的正确导入路径,忽略pycharm标记的错误
-
python中的导入路径要诀:从哪里开始运行,就从哪里开始导入
1.4 开发流程总结
-
创建项目 scrapy startproject 项目名
-
明确目标 在items.py文件中进行建模
-
创建爬虫 3.1 创建爬虫 scrapy genspider 爬虫名 允许的域 3.2 完成爬虫 修改start_urls 检查修改allowed_domains 编写解析方法
-
保存数据 在pipelines.py文件中定义对数据处理的管道 在settings.py文件中注册启用管道
2. 翻页请求的思路
对于要提取如下图中所有页面上的数据该怎么办?
回顾requests模块是如何实现翻页请求的:
-
找到下一页的URL地址
-
调用requests.get(url)
scrapy实现翻页的思路:
-
找到下一页的url地址
-
构造url地址的请求对象,传递给引擎
3. 构造Request对象,并发送请求
3.1 实现方法
-
确定url地址
-
构造请求,scrapy.Request(url,callback)
-
callback:指定解析函数名称,表示该请求返回的响应使用哪一个函数进行解析
-
-
把请求交给引擎:yield scrapy.Request(url,callback)
3.2 网易招聘爬虫
通过爬取网易招聘的页面的招聘信息,学习如何实现翻页请求
思路分析:
-
获取首页的数据
-
寻找下一页的地址,进行翻页,获取数据
注意:
-
可以在settings中设置ROBOTS协议
# False表示忽略网站的robots.txt协议,默认为True ROBOTSTXT_OBEY = False
-
可以在settings中设置User-Agent:
# scrapy发送的每一个请求的默认UA都是设置的这个User-Agent USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
3.3 代码实现
在爬虫文件的parse方法中:
......
# 提取下一页的href
next_url = response.xpath('//a[contains(text(),">")]/@href').extract_first()
# 判断是否是最后一页
if next_url != 'javascript:void(0)':
# 构造完整url
url = 'https://hr.163.com/position/list.do' + next_url
# 构造scrapy.Request对象,并yield给引擎
# 利用callback参数指定该Request对象之后获取的响应用哪个函数进行解析
yield scrapy.Request(url, callback=self.parse)
......
3.4 scrapy.Request的更多参数
scrapy.Request(url[,callback,method="GET",headers,body,cookies,meta,dont_filter=False])
参数解释
-
中括号里的参数为可选参数
-
callback:表示当前的url的响应交给哪个函数去处理
-
meta:实现数据在不同的解析函数中传递,meta默认带有部分数据,比如下载延迟,请求深度等
-
dont_filter:默认为False,会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为Ture,比如贴吧的翻页请求,页面的数据总是在变化;start_urls中的地址会被反复请求,否则程序不会启动
-
method:指定POST或GET请求
-
headers:接收一个字典,其中不包括cookies
-
cookies:接收一个字典,专门放置cookies
-
body:接收json字符串,为POST的数据,发送payload_post请求时使用(在下一章节中会介绍post请求)
4. meta参数的使用
meta的作用:meta可以实现数据在不同的解析函数中的传递
在爬虫文件的parse方法中,提取详情页增加之前callback指定的parse_detail函数:
def parse(self,response):
...
yield scrapy.Request(detail_url, callback=self.parse_detail,meta={"item":item})
...
def parse_detail(self,response):
#获取之前传入的item
item = resposne.meta["item"]
特别注意
-
meta参数是一个字典
-
meta字典中有一个固定的键
proxy,表示代理ip,关于代理ip的使用我们将在scrapy的下载中间件的学习中进行介绍
小结
-
完善并使用Item数据类:
-
在items.py中完善要爬取的字段
-
在爬虫文件中先导入Item
-
实力化Item对象后,像字典一样直接使用
-
构造Request对象,并发送请求:
-
导入scrapy.Request类
-
在解析函数中提取url
-
yield scrapy.Request(url, callback=self.parse_detail, meta={})
-
利用meta参数在不同的解析函数中传递数据:
-
通过前一个解析函数 yield scrapy.Request(url, callback=self.xxx, meta={}) 来传递meta
-
在self.xxx函数中 response.meta.get(‘key’, ”) 或 response.meta[‘key’] 的方式取出传递的数据
参考代码
wangyi/spiders/job.py
import scrapy
class JobSpider(scrapy.Spider):
name = 'job'
# 2.检查允许的域名
allowed_domains = ['163.com']
# 1 设置起始的url
start_urls = ['https://hr.163.com/position/list.do']
def parse(self, response):
# 获取所有的职位节点列表
node_list = response.xpath('//*[@class="position-tb"]/tbody/tr')
# print(len(node_list))
# 遍历所有的职位节点列表
for num, node in enumerate(node_list):
# 索引为值除2取余为0的才是含有数据的节点,通过判断进行筛选
if num % 2 == 0:
item = {}
item['name'] = node.xpath('./td[1]/a/text()').extract_first()
item['link'] = node.xpath('./td[1]/a/@href').extract_first()
item['depart'] = node.xpath('./td[2]/text()').extract_first()
item['category'] = node.xpath('./td[3]/text()').extract_first()
item['type'] = node.xpath('./td[4]/text()').extract_first()
item['address'] = node.xpath('./td[5]/text()').extract_first()
item['num'] = node.xpath('./td[6]/text()').extract_first().strip()
item['date'] = node.xpath('./td[7]/text()').extract_first()
yield item
# 翻页处理
# 获取翻页url
part_url = response.xpath('//a[contains(text(),">")]/@href').extract_first()
# 判断是否为最后一页,如果不是最后一页则进行翻页操作
if part_url != 'javascript:void(0)':
# 拼接完整翻页url
next_url = 'https://hr.163.com/position/list.do' + part_url
yield scrapy.Request(
url=next_url,
callback=self.parse
)
wangyi/items.py
class WangyiItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
link = scrapy.Field()
depart = scrapy.Field()
category = scrapy.Field()
type = scrapy.Field()
address = scrapy.Field()
num = scrapy.Field()
date = scrapy.Field()
scrapy模拟登陆
学习目标:
-
应用 请求对象cookies参数的使用
-
了解 start_requests函数的作用
-
应用 构造并发送post请求
1. 回顾之前的模拟登陆的方法
1.1 requests模块是如何实现模拟登陆的?
-
直接携带cookies请求页面
-
找url地址,发送post请求存储cookie
1.2 selenium是如何模拟登陆的?
-
找到对应的input标签,输入文本点击登陆
1.3 scrapy的模拟登陆
-
直接携带cookies
-
找url地址,发送post请求存储cookie
2. scrapy携带cookies直接获取需要登陆后的页面
应用场景
-
cookie过期时间很长,常见于一些不规范的网站
-
能在cookie过期之前把所有的数据拿到
-
配合其他程序使用,比如其使用selenium把登陆之后的cookie获取到保存到本地,scrapy发送请求之前先读取本地cookie
2.1 实现:重构scrapy的starte_rquests方法
scrapy中start_url是通过start_requests来进行处理的,其实现代码如下
# 这是源代码 def start_requests(self): cls = self.__class__ if method_is_overridden(cls, Spider, 'make_requests_from_url'): warnings.warn( "Spider.make_requests_from_url method is deprecated; it " "won't be called in future Scrapy releases. Please " "override Spider.start_requests method instead (see %s.%s)." % ( cls.__module__, cls.__name__ ), ) for url in self.start_urls: yield self.make_requests_from_url(url) else: for url in self.start_urls: yield Request(url, dont_filter=True)
所以对应的,如果start_url地址中的url是需要登录后才能访问的url地址,则需要重写start_request方法并在其中手动添加上cookie
2.2 携带cookies登陆github
测试账号 noobpythoner zhoudawei123
import scrapy
import re
class Login1Spider(scrapy.Spider):
name = 'login1'
allowed_domains = ['github.com']
start_urls = ['https://github.com/NoobPythoner'] # 这是一个需要登陆以后才能访问的页面
def start_requests(self): # 重构start_requests方法
# 这个cookies_str是抓包获取的
cookies_str = '...' # 抓包获取
# 将cookies_str转换为cookies_dict
cookies_dict = {i.split('=')[0]:i.split('=')[1] for i in cookies_str.split('; ')}
yield scrapy.Request(
self.start_urls[0],
callback=self.parse,
cookies=cookies_dict
)
def parse(self, response): # 通过正则表达式匹配用户名来验证是否登陆成功
# 正则匹配的是github的用户名
result_list = re.findall(r'noobpythoner|NoobPythoner', response.body.decode())
print(result_list)
pass
注意:
-
scrapy中cookie不能够放在headers中,在构造请求的时候有专门的cookies参数,能够接受字典形式的coookie
-
在setting中设置ROBOTS协议、USER_AGENT
3. scrapy.Request发送post请求
我们知道可以通过scrapy.Request()指定method、body参数来发送post请求;但是通常使用scrapy.FormRequest()来发送post请求
3.1 发送post请求
注意:scrapy.FormRequest()能够发送表单和ajax请求
3.1.1 思路分析
-
找到post的url地址:点击登录按钮进行抓包,然后定位url地址为
-
找到请求体的规律:分析post请求的请求体,其中包含的参数均在前一次的响应中
-
否登录成功:通过请求个人主页,观察是否包含用户名
3.1.2 代码实现如下:
import scrapy
import re
class Login2Spider(scrapy.Spider):
name = 'login2'
allowed_domains = ['github.com']
start_urls = ['https://github.com/login']
def parse(self, response):
authenticity_token = response.xpath("//input[@name='authenticity_token']/@value").extract_first()
utf8 = response.xpath("//input[@name='utf8']/@value").extract_first()
commit = response.xpath("//input[@name='commit']/@value").extract_first()
#构造POST请求,传递给引擎
yield scrapy.FormRequest(
"https://github.com/session",
formdata={
"authenticity_token":authenticity_token,
"utf8":utf8,
"commit":commit,
"login":"noobpythoner",
"password":"***"
},
callback=self.parse_login
)
def parse_login(self,response):
ret = re.findall(r"noobpythoner|NoobPythoner",response.text)
print(ret)
小技巧
在settings.py中通过设置COOKIES_DEBUG=TRUE 能够在终端看到cookie的传递传递过程
小结
-
start_urls中的url地址是交给start_request处理的,如有必要,可以重写start_request函数
-
直接携带cookie登陆:cookie只能传递给cookies参数接收
-
scrapy.Request()发送post请求
scrapy管道的使用
学习目标:
-
掌握 scrapy管道(pipelines.py)的使用
之前我们在scrapy入门使用一节中学习了管道的基本使用,接下来我们深入的学习scrapy管道的使用
1. pipeline中常用的方法:
-
process_item(self,item,spider):
-
管道类中必须有的函数
-
实现对item数据的处理
-
必须return item
-
-
open_spider(self, spider): 在爬虫开启的时候仅执行一次
-
close_spider(self, spider): 在爬虫关闭的时候仅执行一次
2. 管道文件的修改
继续完善wangyi爬虫,在pipelines.py代码中完善
import json
from pymongo import MongoClient
class WangyiFilePipeline(object):
def open_spider(self, spider): # 在爬虫开启的时候仅执行一次
if spider.name == 'itcast':
self.f = open('json.txt', 'a', encoding='utf-8')
def close_spider(self, spider): # 在爬虫关闭的时候仅执行一次
if spider.name == 'itcast':
self.f.close()
def process_item(self, item, spider):
if spider.name == 'itcast':
self.f.write(json.dumps(dict(item), ensure_ascii=False, indent=2) + ',\n')
# 不return的情况下,另一个权重较低的pipeline将不会获得item
return item
class WangyiMongoPipeline(object):
def open_spider(self, spider): # 在爬虫开启的时候仅执行一次
if spider.name == 'itcast':
# 也可以使用isinstanc函数来区分爬虫类:
con = MongoClient(host='127.0.0.1', port=27017) # 实例化mongoclient
self.collection = con.itcast.teachers # 创建数据库名为itcast,集合名为teachers的集合操作对象
def process_item(self, item, spider):
if spider.name == 'itcast':
self.collection.insert(item)
# 此时item对象必须是一个字典,再插入
# 如果此时item是BaseItem则需要先转换为字典:dict(BaseItem)
# 不return的情况下,另一个权重较低的pipeline将不会获得item
return item
3. 开启管道
在settings.py设置开启pipeline
......
ITEM_PIPELINES = {
'myspider.pipelines.ItcastFilePipeline': 400, # 400表示权重
'myspider.pipelines.ItcastMongoPipeline': 500, # 权重值越小,越优先执行!
}
......
别忘了开启mongodb数据库 sudo service mongodb start 并在mongodb数据库中查看 mongo
思考:在settings中能够开启多个管道,为什么需要开启多个?
-
不同的pipeline可以处理不同爬虫的数据,通过spider.name属性来区分
-
不同的pipeline能够对一个或多个爬虫进行不同的数据处理的操作,比如一个进行数据清洗,一个进行数据的保存
-
同一个管道类也可以处理不同爬虫的数据,通过spider.name属性来区分
4. pipeline使用注意点
-
使用之前需要在settings中开启
-
pipeline在setting中键表示位置(即pipeline在项目中的位置可以自定义),值表示距离引擎的远近,越近数据会越先经过:权重值小的优先执行
-
有多个pipeline的时候,process_item的方法必须return item,否则后一个pipeline取到的数据为None值
-
pipeline中process_item的方法必须有,否则item没有办法接受和处理
-
process_item方法接受item和spider,其中spider表示当前传递item过来的spider
-
open_spider(spider) :能够在爬虫开启的时候执行一次
-
close_spider(spider) :能够在爬虫关闭的时候执行一次
-
上述俩个方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立和数据库的连接,在爬虫关闭的时候断开和数据库的连接
小结
-
管道能够实现数据的清洗和保存,能够定义多个管道实现不同的功能,其中有个三个方法
-
process_item(self,item,spider):实现对item数据的处理
-
open_spider(self, spider): 在爬虫开启的时候仅执行一次
-
close_spider(self, spider): 在爬虫关闭的时候仅执行一次
-
scrapy中间件的使用
学习目标:
-
应用 scrapy中使用间件使用随机UA的方法
-
应用 scrapy中使用代理ip的的方法
-
应用 scrapy与selenium配合使用
1. scrapy中间件的分类和作用
1.1 scrapy中间件的分类
根据scrapy运行流程中所在位置不同分为:
-
下载中间件
-
爬虫中间件
1.2 scrapy中间的作用:预处理request和response对象
-
对header以及cookie进行更换和处理
-
使用代理ip等
-
对请求进行定制化操作,
但在scrapy默认的情况下 两种中间件都在middlewares.py一个文件中
爬虫中间件使用方法和下载中间件相同,且功能重复,通常使用下载中间件
2. 下载中间件的使用方法:
接下来我们对腾讯招聘爬虫进行修改完善,通过下载中间件来学习如何使用中间件 编写一个Downloader Middlewares和我们编写一个pipeline一样,定义一个类,然后在setting中开启
Downloader Middlewares默认的方法:
-
process_request(self, request, spider):
-
当每个request通过下载中间件时,该方法被调用。
-
返回None值:没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法
-
返回Response对象:不再请求,把response返回给引擎
-
返回Request对象:把request对象通过引擎交给调度器,此时将不通过其他权重低的process_request方法
-
-
-
process_response(self, request, response, spider):
-
当下载器完成http请求,传递响应给引擎的时候调用
-
返回Resposne:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法
-
返回Request对象:通过引擎交给调取器继续请求,此时将不通过其他权重低的process_request方法
-
-
-
在settings.py中配置开启中间件,权重值越小越优先执行
3. 定义实现随机User-Agent的下载中间件
3.1 在middlewares.py中完善代码
import random from Tencent.settings import USER_AGENTS_LIST # 注意导入路径,请忽视pycharm的错误提示 class UserAgentMiddleware(object): def process_request(self, request, spider): user_agent = random.choice(USER_AGENTS_LIST) request.headers['User-Agent'] = user_agent # 不写return class CheckUA: def process_response(self,request,response,spider): print(request.headers['User-Agent']) return response # 不能少!
3.2 在settings中设置开启自定义的下载中间件,设置方法同管道
DOWNLOADER_MIDDLEWARES = {
'Tencent.middlewares.UserAgentMiddleware': 543, # 543是权重值
'Tencent.middlewares.CheckUA': 600, # 先执行543权重的中间件,再执行600的中间件
}
3.3 在settings中添加UA的列表
USER_AGENTS_LIST = [ "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5" ]
运行爬虫观察现象
4. 代理ip的使用
4.1 思路分析
-
代理添加的位置:request.meta中增加
proxy字段 -
获取一个代理ip,赋值给
request.meta['proxy']-
代理池中随机选择代理ip
-
代理ip的webapi发送请求获取一个代理ip
-
4.2 具体实现
免费代理ip:
class ProxyMiddleware(object): def process_request(self,request,spider): # proxies可以在settings.py中,也可以来源于代理ip的webapi # proxy = random.choice(proxies) # 免费的会失效,报 111 connection refused 信息!重找一个代理ip再试 proxy = 'https://1.71.188.37:3128' request.meta['proxy'] = proxy return None # 可以不写return
收费代理ip:
# 人民币玩家的代码(使用abuyun提供的代理ip) import base64 # 代理隧道验证信息 这个是在那个网站上申请的 proxyServer = 'http://proxy.abuyun.com:9010' # 收费的代理ip服务器地址,这里是abuyun proxyUser = 用户名 proxyPass = 密码 proxyAuth = "Basic " + base64.b64encode(proxyUser + ":" + proxyPass) class ProxyMiddleware(object): def process_request(self, request, spider): # 设置代理 request.meta["proxy"] = proxyServer # 设置认证 request.headers["Proxy-Authorization"] = proxyAuth
4.3 检测代理ip是否可用
在使用了代理ip的情况下可以在下载中间件的process_response()方法中处理代理ip的使用情况,如果该代理ip不能使用可以替换其他代理ip
class ProxyMiddleware(object): ...... def process_response(self, request, response, spider): if response.status != '200': request.dont_filter = True # 重新发送的请求对象能够再次进入队列 return requst
在settings.py中开启该中间件
5. 在中间件中使用selenium
以github登陆为例
5.1 完成爬虫代码
import scrapy
class Login4Spider(scrapy.Spider):
name = 'login4'
allowed_domains = ['github.com']
start_urls = ['https://github.com/1596930226'] # 直接对验证的url发送请求
def parse(self, response):
with open('check.html', 'w') as f:
f.write(response.body.decode())
5.2 在middlewares.py中使用selenium
import time
from selenium import webdriver
def getCookies():
# 使用selenium模拟登陆,获取并返回cookie
username = input('输入github账号:')
password = input('输入github密码:')
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
driver = webdriver.Chrome('/home/worker/Desktop/driver/chromedriver',
chrome_options=options)
driver.get('https://github.com/login')
time.sleep(1)
driver.find_element_by_xpath('//*[@id="login_field"]').send_keys(username)
time.sleep(1)
driver.find_element_by_xpath('//*[@id="password"]').send_keys(password)
time.sleep(1)
driver.find_element_by_xpath('//*[@id="login"]/form/div[3]/input[3]').click()
time.sleep(2)
cookies_dict = {cookie['name']: cookie['value'] for cookie in driver.get_cookies()}
driver.quit()
return cookies_dict
class LoginDownloaderMiddleware(object):
def process_request(self, request, spider):
cookies_dict = getCookies()
print(cookies_dict)
request.cookies = cookies_dict # 对请求对象的cookies属性进行替换
配置文件中设置开启该中间件后,运行爬虫可以在日志信息中看到selenium相关内容
小结
中间件的使用:
-
完善中间件代码:
-
process_request(self, request, spider):
-
当每个request通过下载中间件时,该方法被调用。
-
返回None值:没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法
-
返回Response对象:不再请求,把response返回给引擎
-
返回Request对象:把request对象通过引擎交给调度器,此时将不通过其他权重低的process_request方法
-
-
process_response(self, request, response, spider):
-
当下载器完成http请求,传递响应给引擎的时候调用
-
返回Resposne:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法
-
返回Request对象:通过引擎交给调取器继续请求,此时将不通过其他权重低的process_request方法
-
-
需要在settings.py中开启中间件 DOWNLOADER_MIDDLEWARES = { ‘myspider.middlewares.UserAgentMiddleware’: 543, }
scrapy_redis概念作用和流程
学习目标
-
了解 分布式的概念及特点
-
了解 scarpy_redis的概念
-
了解 scrapy_redis的作用
-
了解 scrapy_redis的工作流程
在前面scrapy框架中我们已经能够使用框架实现爬虫爬取网站数据,如果当前网站的数据比较庞大, 我们就需要使用分布式来更快的爬取数据
1. 分布式是什么
简单的说 分布式就是不同的节点(服务器,ip不同)共同完成一个任务
2. scrapy_redis的概念
scrapy_redis是scrapy框架的基于redis的分布式组件
3. scrapy_redis的作用
Scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:
通过持久化请求队列和请求的指纹集合来实现:
-
断点续爬
-
分布式快速抓取
4. scrapy_redis的工作流程
思考:那么,在这个基础上,如果需要实现分布式,即多台服务器同时完成一个爬虫,需要怎么做呢?
4.2 scrapy_redis的流程
-
在scrapy_redis中,所有的待抓取的request对象和去重的request对象指纹都存在所有的服务器公用的redis中
-
所有的服务器中的scrapy进程公用同一个redis中的request对象的队列
-
所有的request对象存入redis前,都会通过该redis中的request指纹集合进行判断,之前是否已经存入过
-
在默认情况下所有的数据会保存在redis中
小结
scarpy_redis的分布式工作原理
-
在scrapy_redis中,所有的待抓取的对象和去重的指纹都存在公用的redis中
-
所有的服务器公用同一redis中的请求对象的队列
-
所有的request对象存入redis前,都会通过请求对象的指纹进行判断,之前是否已经存入过
scrapy_redis原理分析并实现断点续爬以及分布式爬虫
学习目标
-
了解 scrapy实现去重的原理
-
了解 scrapy中请求入队的条件
-
掌握 scrapy_redis基于url地址的增量式单机爬虫
-
掌握 scrapy_redis分布式爬虫
1. 下载github的demo代码
-
clone github scrapy-redis源码文件
git clone https://github.com/rolando/scrapy-redis.git -
研究项目自带的demo
mv scrapy-redis/example-project ~/scrapyredis-project
2. 观察dmoz文件
在domz爬虫文件中,实现方式就是之前的crawlspider类型的爬虫
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class DmozSpider(CrawlSpider):
"""Follow categories and extract links."""
name = 'dmoz'
allowed_domains = ['dmoztools.net']
start_urls = ['http://dmoztools.net/'] # 这里修改了url
# 定义数据提取规则,使用了css选择器
rules = [
Rule(LinkExtractor(
restrict_css=('.top-cat', '.sub-cat', '.cat-item')
), callback='parse_directory', follow=True),
]
def parse_directory(self, response):
for div in response.css('.title-and-desc'):
yield {
'name': div.css('.site-title::text').extract_first(),
'description': div.css('.site-descr::text').extract_first().strip(),
'link': div.css('a::attr(href)').extract_first(),
}
但是在settings.py中多了以下内容,这几行表示scrapy_redis中重新实现的了去重的类,以及调度器,并且使用RedisPipeline管道类
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400,
}
3. 运行dmoz爬虫,观察现象
-
首先我们需要添加redis的地址,程序才能够使用redis
REDIS_URL = "redis://127.0.0.1:6379" #或者使用下面的方式 # REDIS_HOST = "127.0.0.1" # REDIS_PORT = 6379
-
我们执行domz的爬虫,会发现redis中多了一下三个键:
-
中止进程后再次运行dmoz爬虫
继续执行程序,会发现程序在前一次的基础之上继续往后执行,所以domz爬虫是一个基于url地址的增量式的爬虫
4. scrapy_redis的原理分析
我们从settings.py中的三个配置来进行分析 分别是:
-
RedisPipeline # 管道类
-
RFPDupeFilter # 指纹去重类
-
Scheduler # 调度器类
-
SCHEDULER_PERSIST # 是否持久化请求队列和指纹集合
4.1 Scrapy_redis之RedisPipeline
RedisPipeline中观察process_item,进行数据的保存,存入了redis中
4.2 Scrapy_redis之RFPDupeFilter
RFPDupeFilter 实现了对request对象的加密
4.3 Scrapy_redis之Scheduler
scrapy_redis调度器的实现了决定什么时候把request对象加入带抓取的队列,同时把请求过的request对象过滤掉
4.4 由此可以总结出request对象入队的条件
-
request的指纹不在集合中
-
request的dont_filter为True,即不过滤
-
start_urls中的url地址会入队,因为他们默认是不过滤
-
4.5 实现单机断点续爬
改写网易招聘爬虫,该爬虫就是一个经典的基于url地址的增量式爬虫
5. 实现分布式爬虫
5.1 分析demo中代码
打开example-project项目中的myspider_redis.py文件
通过观察代码:
-
继承自父类为RedisSpider
-
增加了一个redis_key的键,没有start_urls,因为分布式中,如果每台电脑都请求一次start_url就会重复
-
多了
__init__方法,该方法不是必须的,可以手动指定allow_domains -
启动方法:
-
在每个节点正确的目录下执行
scrapy crawl 爬虫名,使该节点的scrapy_redis爬虫程序就位 -
在共用的redis中
lpush redis_key 'start_url',使全部节点真正的开始运行
-
-
settings.py中关键的配置
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400,
}
REDIS_URL = "redis://127.0.0.1:6379"
5.2 动手实现分布式爬虫
改写tencent爬虫为分布式爬虫
注意:启动方式发生改变
小结
-
scrapy_redis的含义和能够实现的功能
-
scrapy是框架
-
scrapy_redis是scrapy的组件
-
scrapy_redis能够实现断点续爬和分布式爬虫
-
-
scrapy_redis流程和实现原理
-
在scrapy框架流程的基础上,把存储request对象放到了redis的有序集合中,利用该有序集合实现了请求队列
-
并对request对象生成指纹对象,也存储到同一redis的集合中,利用request指纹避免发送重复的请求
-
-
request对象进入队列的条件
-
request的指纹不在集合中
-
request的dont_filter为True,即不过滤
-
-
request指纹的实现
-
请求方法
-
排序后的请求地址
-
排序并处理过的请求体或空字符串
-
用hashlib.sha1()对以上内容进行加密
-
-
scarpy_redis实现增量式爬虫、布式爬虫
-
对setting进行如下设置
-
DUPEFILTER_CLASS = “scrapy_redis.dupefilter.RFPDupeFilter”
-
SCHEDULER = “scrapy_redis.scheduler.Scheduler”
-
SCHEDULER_PERSIST = True
-
ITEM_PIPELINES = {‘scrapy_redis.pipelines.RedisPipeline’: 400,}
-
REDIS_URL = “redis://127.0.0.1:6379” # 请正确配置REDIS_URL
-
-
爬虫文件中的爬虫类继承RedisSpider类
-
爬虫类中redis_key替代了start_urls
-
启动方式不同
-
通过
scrapy crawl spider启动爬虫后,向redis_key放入一个或多个起始url(lpush或rpush都可以),才能够让scrapy_redis爬虫运行
-
-
除了以上差异点以外,scrapy_redis爬虫和scrapy爬虫的使用方法都是一样的
-
scrapy_splash组件的使用
学习目标
-
了解 scrapy_splash组件的作用
-
了解 scrapy_splash组件的使用
1. 什么是scrapy_splash?
scrapy_splash是scrapy的一个组件
-
scrapy-splash加载js数据是基于Splash来实现的。
-
Splash是一个Javascript渲染服务。它是一个实现了HTTP API的轻量级浏览器,Splash是用Python和Lua语言实现的,基于Twisted和QT等模块构建。
-
使用scrapy-splash最终拿到的response相当于是在浏览器全部渲染完成以后的网页源代码。
splash官方文档 Splash – A javascript rendering service — Splash 3.5 documentation
2. scrapy_splash的作用
scrapy-splash能够模拟浏览器加载js,并返回js运行后的数据
3. scrapy_splash的环境安装
3.1 使用splash的docker镜像
splash的dockerfile https://github.com/scrapinghub/splash/blob/master/Dockerfile
观察发现splash依赖环境略微复杂,所以我们可以直接使用splash的docker镜像
如果不使用docker镜像请参考 splash官方文档 安装相应的依赖环境
3.1.1 安装并启动docker服务
3.1.2 获取splash的镜像
在正确安装docker的基础上pull取splash的镜像
sudo docker pull scrapinghub/splash
3.1.3 验证是否安装成功
运行splash的docker服务,并通过浏览器访问8050端口验证安装是否成功
-
前台运行
sudo docker run -p 8050:8050 scrapinghub/splash -
后台运行
sudo docker run -d -p 8050:8050 scrapinghub/splash
访问 http://127.0.0.1:8050 看到如下截图内容则表示成功
3.1.4 解决获取镜像超时:修改docker的镜像源
以ubuntu18.04为例
-
创建并编辑docker的配置文件
sudo vi /etc/docker/daemon.json
-
写入国内docker-cn.com的镜像地址配置后保存退出
{
"registry-mirrors": ["https://registry.docker-cn.com"]
}
-
重启电脑或docker服务后重新获取splash镜像
-
这时如果还慢,请使用手机热点(流量orz)
3.1.5 关闭splash服务
需要先关闭容器后,再删除容器
sudo docker ps -a sudo docker stop CONTAINER_ID sudo docker rm CONTAINER_ID
3.2 在python虚拟环境中安装scrapy-splash包
pip install scrapy-splash
4. 在scrapy中使用splash
以baidu为例
4.1 创建项目创建爬虫
scrapy startproject test_splash cd test_splash scrapy genspider no_splash baidu.com scrapy genspider with_splash baidu.com
4.2 完善settings.py配置文件
在settings.py文件中添加splash的配置以及修改robots协议
# 渲染服务的url
SPLASH_URL = 'http://127.0.0.1:8050'
# 下载器中间件
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
4.3 不使用splash
在spiders/no_splash.py中完善
import scrapy
class NoSplashSpider(scrapy.Spider):
name = 'no_splash'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/s?wd=13161933309']
def parse(self, response):
with open('no_splash.html', 'w') as f:
f.write(response.body.decode())
4.4 使用splash
import scrapy
from scrapy_splash import SplashRequest # 使用scrapy_splash包提供的request对象
class WithSplashSpider(scrapy.Spider):
name = 'with_splash'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/s?wd=13161933309']
def start_requests(self):
yield SplashRequest(self.start_urls[0],
callback=self.parse_splash,
args={'wait': 10}, # 最大超时时间,单位:秒
endpoint='render.html') # 使用splash服务的固定参数
def parse_splash(self, response):
with open('with_splash.html', 'w') as f:
f.write(response.body.decode())
4.5 分别运行俩个爬虫,并观察现象
4.5.1 分别运行俩个爬虫
scrapy crawl no_splash scrapy crawl with_splash
4.6 结论
-
splash类似selenium,能够像浏览器一样访问请求对象中的url地址
-
能够按照该url对应的响应内容依次发送请求
-
并将多次请求对应的多次响应内容进行渲染
-
最终返回渲染后的response响应对象
小结
-
scrapy_splash组件的作用
-
splash类似selenium,能够像浏览器一样访问请求对象中的url地址
-
能够按照该url对应的响应内容依次发送请求
-
并将多次请求对应的多次响应内容进行渲染
-
最终返回渲染后的response响应对象
-
-
scrapy_splash组件的使用
-
需要splash服务作为支撑
-
构造的request对象变为splash.SplashRequest
-
以下载中间件的形式使用
-
需要scrapy_splash特定配置
-
-
scrapy_splash的特定配置
SPLASH_URL = 'http://127.0.0.1:8050' DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, } DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter' HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
scrapy的日志信息与配置
学习目标:
-
了解 scrapy的日志信息
-
掌握 scrapy的常用配置
-
掌握 scrapy_redis配置
-
了解scrapy_splash配置
-
了解scrapy_redis和scrapy_splash配合使用的配置
1. 了解scrapy的日志信息
2. scrapy的常用配置
-
ROBOTSTXT_OBEY 是否遵守robots协议,默认是遵守
-
关于robots协议
-
在百度搜索中,不能搜索到淘宝网中某一个具体的商品的详情页面,这就是robots协议在起作用
-
Robots协议:网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,但它仅仅是互联网中的一般约定
-
例如:淘宝的robots协议
-
-
-
USER_AGENT 设置ua
-
DEFAULT_REQUEST_HEADERS 设置默认请求头,这里加入了USER_AGENT将不起作用
-
ITEM_PIPELINES 管道,左位置右权重:权重值越小,越优先执行
-
SPIDER_MIDDLEWARES 爬虫中间件,设置过程和管道相同
-
DOWNLOADER_MIDDLEWARES 下载中间件
-
COOKIES_ENABLED 默认为True表示开启cookie传递功能,即每次请求带上前一次的cookie,做状态保持
-
COOKIES_DEBUG 默认为False表示日志中不显示cookie的传递过程
-
LOG_LEVEL 默认为DEBUG,控制日志的等级
-
LOG_LEVEL = “WARNING”
-
-
LOG_FILE 设置log日志文件的保存路径,如果设置该参数,日志信息将写入文件,终端将不再显示,且受到LOG_LEVEL日志等级的限制
-
LOG_FILE = “./test.log”
-
3. scrapy_redis配置
-
DUPEFILTER_CLASS = “scrapy_redis.dupefilter.RFPDupeFilter” # 指纹生成以及去重类
-
SCHEDULER = “scrapy_redis.scheduler.Scheduler” # 调度器类
-
SCHEDULER_PERSIST = True # 持久化请求队列和指纹集合
-
ITEM_PIPELINES = {‘scrapy_redis.pipelines.RedisPipeline’: 400} # 数据存入redis的管道
-
REDIS_URL = “redis://host:port” # redis的url
4. scrapy_splash配置
SPLASH_URL = 'http://127.0.0.1:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
5. scrapy_redis和scrapy_splash配合使用的配置
5.1 原理
-
scrapy-redis中配置了”DUPEFILTER_CLASS” : “scrapy_redis.dupefilter.RFPDupeFilter”,与scrapy-splash配置的DUPEFILTER_CLASS = ‘scrapy_splash.SplashAwareDupeFilter’ 相冲突!
-
查看了scrapy_splash.SplashAwareDupeFilter源码后,发现他继承了scrapy.dupefilter.RFPDupeFilter,并重写了request_fingerprint()方法。
-
比较scrapy.dupefilter.RFPDupeFilter和scrapy_redis.dupefilter.RFPDupeFilter中的request_fingerprint()方法后,发现是一样的,因此重写了一个SplashAwareDupeFilter,继承scrapy_redis.dupefilter.RFPDupeFilter,其他代码不变。
5.2 重写dupefilter去重类,并在settings.py中使用
5.2.1 重写去重类
from __future__ import absolute_import
from copy import deepcopy
from scrapy.utils.request import request_fingerprint
from scrapy.utils.url import canonicalize_url
from scrapy_splash.utils import dict_hash
from scrapy_redis.dupefilter import RFPDupeFilter
def splash_request_fingerprint(request, include_headers=None):
""" Request fingerprint which takes 'splash' meta key into account """
fp = request_fingerprint(request, include_headers=include_headers)
if 'splash' not in request.meta:
return fp
splash_options = deepcopy(request.meta['splash'])
args = splash_options.setdefault('args', {})
if 'url' in args:
args['url'] = canonicalize_url(args['url'], keep_fragments=True)
return dict_hash(splash_options, fp)
class SplashAwareDupeFilter(RFPDupeFilter):
"""
DupeFilter that takes 'splash' meta key in account.
It should be used with SplashMiddleware.
"""
def request_fingerprint(self, request):
return splash_request_fingerprint(request)
"""以上为重写的去重类,下边为爬虫代码"""
from scrapy_redis.spiders import RedisSpider
from scrapy_splash import SplashRequest
class SplashAndRedisSpider(RedisSpider):
name = 'splash_and_redis'
allowed_domains = ['baidu.com']
# start_urls = ['https://www.baidu.com/s?wd=13161933309']
redis_key = 'splash_and_redis'
# lpush splash_and_redis 'https://www.baidu.com'
# 分布式的起始的url不能使用splash服务!
# 需要重写dupefilter去重类!
def parse(self, response):
yield SplashRequest('https://www.baidu.com/s?wd=13161933309',
callback=self.parse_splash,
args={'wait': 10}, # 最大超时时间,单位:秒
endpoint='render.html') # 使用splash服务的固定参数
def parse_splash(self, response):
with open('splash_and_redis.html', 'w') as f:
f.write(response.body.decode())
5.2.2 scrapy_redis和scrapy_splash配合使用的配置
# 渲染服务的url
SPLASH_URL = 'http://127.0.0.1:8050'
# 下载器中间件
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
# 去重过滤器
# DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 指纹生成以及去重类
DUPEFILTER_CLASS = 'test_splash.spiders.splash_and_redis.SplashAwareDupeFilter' # 混合去重类的位置
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 调度器类
SCHEDULER_PERSIST = True # 持久化请求队列和指纹集合, scrapy_redis和scrapy_splash混用使用splash的DupeFilter!
ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 400} # 数据存入redis的管道
REDIS_URL = "redis://127.0.0.1:6379" # redis的url
注意:
-
scrapy_redis分布式爬虫在业务逻辑结束后并不能够自动退出
-
重写的dupefilter去重类可以自定义位置,也须在配置文件中写入相应的路径
6. 了解scrapy的其他配置
-
CONCURRENT_REQUESTS 设置并发请求的数量,默认是16个
-
DOWNLOAD_DELAY 下载延迟,默认无延迟,单位为秒
小结
-
了解scrapy的日志信息
-
掌握scrapy的常用配置
-
掌握scrapy_redis配置
-
了解scrapy_splash配置
-
了解scrapy_redis和scrapy_splash配合使用的配置
scrapyd部署scrapy项目
学习目标
-
了解 scrapyd的使用流程
1. scrapyd的介绍
scrapyd是一个用于部署和运行scrapy爬虫的程序,它允许你通过JSON API来部署爬虫项目和控制爬虫运行,scrapyd是一个守护进程,监听爬虫的运行和请求,然后启动进程来执行它们
所谓json api本质就是post请求的webapi
2. scrapyd的安装
scrapyd服务: pip install scrapyd
scrapyd客户端: pip install scrapyd-client
3. 启动scrapyd服务
-
在scrapy项目路径下 启动scrapyd的命令:
sudo scrapyd或scrapyd -
启动之后就可以打开本地运行的scrapyd,浏览器中访问本地6800端口可以查看scrapyd的监控界面
-
点击job可以查看任务监控界面
4. scrapy项目部署
4.1 配置需要部署的项目
编辑需要部署的项目的scrapy.cfg文件(需要将哪一个爬虫部署到scrapyd中,就配置该项目的该文件)
[deploy:部署名(部署名可以自行定义)] url = http://localhost:6800/ project = 项目名(创建爬虫项目时使用的名称)
4.2 部署项目到scrapyd
同样在scrapy项目路径下执行:
scrapyd-deploy 部署名(配置文件中设置的名称) -p 项目名称
部署成功之后就可以看到部署的项目
4.3 管理scrapy项目
-
启动项目:
curl http://localhost:6800/schedule.json -d project=project_name -d spider=spider_name
-
关闭爬虫:
curl http://localhost:6800/cancel.json -d project=project_name -d job=jobid
注意;curl是命令行工具,如果没有则需要额外安装
4.4 使用requests模块控制scrapy项目
import requests
# 启动爬虫
url = 'http://localhost:6800/schedule.json'
data = {
'project': 项目名,
'spider': 爬虫名,
}
resp = requests.post(url, data=data)
# 停止爬虫
url = 'http://localhost:6800/cancel.json'
data = {
'project': 项目名,
'job': 启动爬虫时返回的jobid,
}
resp = requests.post(url, data=data)
小结
-
在scrapy项目路径下执行
sudo scrapyd或scrapyd,启动scrapyd服务;或以后台进程方式启动nohup scrapyd > scrapyd.log 2>&1 & -
部署scrapy爬虫项目
scrapyd-deploy -p myspider -
启动爬虫项目中的一个爬虫
curl http://localhost:6800/schedule.json -d project=myspider -d spider=tencent
13.Gerapy
学习目标
-
了解 什么是Gerapy
-
掌握 Gerapy的安装
-
掌握 Gerapy配置启动
-
掌握 通过Gerapy配置管理scrapy项目
1.Gerapy介绍:
Gerapy 是一款 分布式爬虫管理框架,支持 Python 3,基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 开发,Gerapy 可以帮助我们:
-
更方便地控制爬虫运行
-
更直观地查看爬虫状态
-
更实时地查看爬取结果
-
更简单地实现项目部署
-
更统一地实现主机管理
2.Gerapy的安装
1.执行如下命令,等待安装完毕
pip3 install gerapy
2.验证gerapy是否安装成功
在终端中执行 gerapy 会出现如下信息
“”” Usage: gerapy init [–folder=<folder>] gerapy migrate gerapy createsuperuser gerapy runserver [host:port] “””
3.Gerapy配置启动
1.新建一个项目
gerapy init
执行完该命令之后会在当前目录下生成一个gerapy文件夹,进入该文件夹,会找到一个名为projects的文件夹
2.对数据库进行初始化(在gerapy目录中操作),执行如下命令
gerapy migrate
对数据库初始化之后会生成一个SQLite数据库,数据库保存主机配置信息和部署版本等
3.启动 gerapy服务
gerapy runserver
此时启动gerapy服务的这台机器的8000端口上开启了Gerapy服务,在浏览器中输入http://localhost:8000就能进入Gerapy管理界面,在管理界面就可以进行主机管理和界面管理
4.通过Gerapy配置管理scrapy项目
-
配置主机 1.添加scrapyd主机
需要添加 IP、端口,以及名称,点击创建即可完成添加,点击返回即可看到当前添加的 Scrapyd 服务列表,创建成功后,我们可以在列表中查看已经添加的服务
2.执行爬虫,就点击调度.然后运行. (前提是: 我们配置的scrapyd中,已经发布了爬虫.)
-
配置Projects 1.我们可以将scarpy项目直接放到 /gerapy/projects下.
2.可以在gerapy后台看到有个项目
3.点击部署点击部署按钮进行打包和部署,在右下角我们可以输入打包时的描述信息,类似于 Git 的 commit 信息,然后点击打包按钮,即可发现 Gerapy 会提示打包成功,同时在左侧显示打包的结果和打包名称。
4.选择一个站点,点击右侧部署,将该项目部署到该站点上
5.成功部署之后会显示描述和部署时间
6.来到clients界面,找到部署该项目的节点,点击调度
7.在该节点中的项目列表中找到项目,点击右侧run运行项目
补充:
1.Gerapy 与 scrapyd 有什么关联吗?
我们仅仅使用scrapyd是可以调用scrapy进行爬虫. 只是需要使用命令行开启爬虫 curl http://127.0.0.1:6800/schedule.json -d project=工程名 -d spider=爬虫名 使用Greapy就是为了将使用命令行开启爬虫变成 “小手一点”. 我们在gerapy中配置了scrapyd后,不需要使用命令行,可以通过图形化界面直接开启爬虫.
小结
-
了解 什么是Gerapy
-
掌握 Gerapy的安装
-
掌握 Gerapy配置启动
-
掌握 通过Gerapy配置管理scrapy项目
## scrapy的crawlspider爬虫
学习目标:
-
了解 crawlspider的作用
-
应用 crawlspider爬虫创建的方法
-
应用 crawlspider中rules的使用
1 crawlspider是什么
回顾之前的代码中,我们有很大一部分时间在寻找下一页的url地址或者是内容的url地址上面,这个过程能更简单一些么?
思路:
-
从response中提取所有的满足规则的url地址
-
自动的构造自己requests请求,发送给引擎
对应的crawlspider就可以实现上述需求,能够匹配满足条件的url地址,组装成Reuqest对象后自动发送给引擎,同时能够指定callback函数
即:crawlspider爬虫可以按照规则自动获取连接
2 创建crawlspider爬虫并观察爬虫内的默认内容
2.1 创建crawlspider爬虫:
scrapy genspider -t crawl job 163.com
2.2 spider中默认生成的内容如下:
class JobSpider(CrawlSpider):
name = 'job'
allowed_domains = ['163.com']
start_urls = ['https://hr.163.com/position/list.do']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = {}
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
2.3 观察跟普通的scrapy.spider的区别
在crawlspider爬虫中,没有parse函数
重点在rules中:
-
rules是一个元组或者是列表,包含的是Rule对象
-
Rule表示规则,其中包含LinkExtractor,callback和follow等参数
-
LinkExtractor:连接提取器,可以通过正则或者是xpath来进行url地址的匹配
-
callback :表示经过连接提取器提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调函数的处理
-
follow:连接提取器提取的url地址对应的响应是否还会继续被rules中的规则进行提取,True表示会,Flase表示不会
3. crawlspider网易招聘爬虫
通过crawlspider爬取网易招聘的详情页的招聘信息
url:职位搜索
思路分析:
-
定义一个规则,来进行列表页翻页,follow需要设置为True
-
定义一个规则,实现从列表页进入详情页,并且指定回调函数
-
在详情页提取数据
注意:连接提取器LinkExtractor中的allow对应的正则表达式匹配的是href属性的值
4 crawlspider使用的注意点:
-
除了用命令
scrapy genspider -t crawl <爬虫名> <allowed_domail>创建一个crawlspider的模板,页可以手动创建 -
crawlspider中不能再有以parse为名的数据提取方法,该方法被crawlspider用来实现基础url提取等功能
-
Rule对象中LinkExtractor为固定参数,其他callback、follow为可选参数
-
不指定callback且follow为True的情况下,满足rules中规则的url还会被继续提取和请求
-
如果一个被提取的url满足多个Rule,那么会从rules中选择一个满足匹配条件的Rule执行
5 了解crawlspider其他知识点
-
链接提取器LinkExtractor的更多常见参数
-
allow: 满足括号中的’re’表达式的url会被提取,如果为空,则全部匹配
-
deny: 满足括号中的’re’表达式的url不会被提取,优先级高于allow
-
allow_domains: 会被提取的链接的domains(url范围),如:
['hr.tencent.com', 'baidu.com'] -
deny_domains: 不会被提取的链接的domains(url范围)
-
restrict_xpaths: 使用xpath规则进行匹配,和allow共同过滤url,即xpath满足的范围内的url地址会被提取,如:
restrict_xpaths='//div[@class="pagenav"]'
-
-
Rule常见参数
-
LinkExtractor: 链接提取器,可以通过正则或者是xpath来进行url地址的匹配
-
callback: 表示经过连接提取器提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调函数的处理
-
follow: 连接提取器提取的url地址对应的响应是否还会继续被rules中的规则进行提取,默认True表示会,Flase表示不会
-
process_links: 当链接提取器LinkExtractor获取到链接列表的时候调用该参数指定的方法,这个自定义方法可以用来过滤url,且这个方法执行后才会执行callback指定的方法
-
总结
-
crawlspider的作用:crawlspider可以按照规则自动获取连接
-
crawlspider爬虫的创建:scrapy genspider -t crawl tencent hr.tencent.com
-
crawlspider中rules的使用:
-
rules是一个元组或者是列表,包含的是Rule对象
-
Rule表示规则,其中包含LinkExtractor,callback和follow等参数
-
LinkExtractor:连接提取器,可以通过正则或者是xpath来进行url地址的匹配
-
callback :表示经过连接提取器提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调函数的处理
-
follow:连接提取器提取的url地址对应的响应是否还会继续被rules中的规则进行提取,True表示会,Flase表示不会
-
完成网易招聘爬虫crawlspider版本
八、appium的使用
利用appium自动控制移动设备并提取数据
学习目标
-
了解 appium-python-client模块定位元素以及提取其文本内容的方法
-
了解 appium-python-client模块控制滑动动作的方法
以控制抖音app滑动并获取抖音短视频发布者昵称和点赞数等信息为例
2.1 安装appium-python-client模块并启动已安装好的环境
2.1.1 安装appium-python-client模块
在window的虚拟环境下执行pip install appium-python-client
2.1.2 启动夜神模拟器,进入夜神模拟器所在的安装路径的bin目录下,进入cmd终端,使用adb命令建立adb server和模拟器的连接
-
adb devices
C:\Program Files (x86)\Nox\bin>adb devices List of devices attached * daemon not running; starting now at tcp:5037 * daemon started successfully
-
nox_adb.exe connect 127.0.0.1:62001
C:\Program Files (x86)\Nox\bin>nox_adb.exe connect 127.0.0.1:62001 already connected to 127.0.0.1:62001
-
adb devices
C:\Program Files (x86)\Nox\bin>adb devices List of devices attached 127.0.0.1:62001 device
2.1.3 启动appium-desktop,点击start server启动appium服务
[Appium] Welcome to Appium v1.10.0 [Appium] Appium REST http interface listener started on 0.0.0.0:4723
2.1.4 利用上一小节所学习的内容获取Desired Capabilities参数
-
获取模拟设备的型号
-
打开设置——关于平板电脑
-
查看型号,获取模拟设备的型号
-
-
获取app包名称 以及 app进程名
-
打开模拟器中的抖音短视频app
-
在adb连接正确的情况下,在夜神模拟器安装目录的bin目录下的cmd中输入
adb shell -
进入adb shell后输入
dumpsys activity | grep mFocusedActivity -
`com.ss.android.ugc.aweme就是app包名 -
.main.MainActivity就是进程名 注意前边有个点.
-
2.2 初始化以及获取移动设备分辨率
完成代码如下,并运行代码查看效果:如果模拟器中抖音app被启动,并打印出模拟设备的分辨率则成功
from appium import webdriver
# 初始化配置,设置Desired Capabilities参数
desired_caps = {
'platformName': 'Android',
'deviceName': 'SM-G955F',
'appPackage': 'com.ss.android.ugc.aweme',
'appActivity': '.main.MainActivity'
}
# 指定Appium Server
server = 'http://localhost:4723/wd/hub'
# 新建一个driver
driver = webdriver.Remote(server, desired_caps)
# 获取模拟器/手机的分辨率(px)
width = driver.get_window_size()['width']
height = driver.get_window_size()['height']
print(width, height)
-
移动设备分辨率
-
driver.get_window_size()[‘width’]
-
driver.get_window_size()[‘height’]
-
2.3 定位元素以及提取文本的方法
2.3.1 点击appium desktop右上角的放大镜图标
如图填写配置,并点击start session
2.3.2 定位界面的使用方法如下图所示
2.3.3 点击短视频的作者名字,查看并获取该元素的id
2.3.4 在python使用代码通过元素id获取该元素的文本内容
实例化appium driver对象后添加如下代码,运行并查看效果
# 获取视频的各种信息:使用appium desktop定位元素
print(driver.find_element_by_id('bc').text) # 发布者名字
print(driver.find_element_by_id('al9').text) # 点赞数
print(driver.find_element_by_id('al_').text) # 留言数
print(driver.find_element_by_id('a23').text) # 视频名字,可能不存在,报错
-
定位元素及获取其文本内容的方法
-
driver.find_element_by_id(元素的id).text
-
driver.find_element_by_xpath(定位元素的xpath规则).text
-
2.4 控制抖音app滑动
2.4.1 appium滑动的函数
从(start_x, start_y)滑动到(end_x, end_y)
-
driver.swipe(start_x, start_y, end_x, end_y)
2.4.2 控制抖音app滑动的代码实现
start_x = width // 2 # 滑动的起始点的x坐标,屏幕宽度中心点 start_y = height // 3 * 2 # 滑动的起始点的y坐标,屏幕高度从上开始到下三分之二处 distance = height // 2 # y轴滑动距离:屏幕高度一半的距离 end_x = start_x # 滑动的终点的x坐标 end_y = start_y-distance # 滑动的终点的y坐标 # 滑动 driver.swipe(start_x, start_y, end_x, end_y)
2.5 整理并完成自动滑动的代码
import time
from appium import webdriver
class DouyinAction():
"""自动滑动,并获取抖音短视频发布者的id"""
def __init__(self, nums:int=None):
# 初始化配置,设置Desired Capabilities参数
self.desired_caps = {
'platformName': 'Android',
'deviceName': 'SM-G955F',
'appPackage': 'com.ss.android.ugc.aweme',
'appActivity': '.main.MainActivity'
}
# 指定Appium Server
self.server = 'http://localhost:4723/wd/hub'
# 新建一个driver
self.driver = webdriver.Remote(self.server, self.desired_caps)
# 获取模拟器/手机的分辨率(px)
width = self.driver.get_window_size()['width']
height = self.driver.get_window_size()['height']
print(width, height)
# 设置滑动初始坐标和滑动距离
self.start_x = width//2 # 屏幕宽度中心点
self.start_y = height//3*2 # 屏幕高度从上开始到下三分之二处
self.distance = height//2 # 滑动距离:屏幕高度一半的距离
# 设置滑动次数
self.nums = nums
def comments(self):
# app开启之后点击一次屏幕,确保页面的展示
time.sleep(2)
self.driver.tap([(500, 1200)], 500)
def scroll(self):
# 无限滑动
i = 0
while True:
# 模拟滑动
print('滑动ing...')
self.driver.swipe(self.start_x, self.start_y,
self.start_x, self.start_y-self.distance)
time.sleep(1)
self.get_infos() # 获取视频发布者的名字
# 设置延时等待
time.sleep(4)
# 判断是否退出
if self.nums is not None and self.nums == i:
break
i += 1
def get_infos(self):
# 获取视频的各种信息:使用appium desktop定位元素
print(self.driver.find_element_by_id('bc').text) # 发布者名字
print(self.driver.find_element_by_id('al9').text) # 点赞数
print(self.driver.find_element_by_id('al_').text) # 留言数
print(self.driver.find_element_by_id('a23').text) # 视频名字,可能不存在,报错
# # 点击【分享】坐标位置 671,1058
# self.driver.tap([(671, 1058)])
# time.sleep(2)
# # 向左滑动露出 【复制链接】 580,1100 --> 200, 1100
# self.driver.swipe(580,1100, 20, 200, 1100)
# # self.driver.get_screenshot_as_file('./a.png') # 截图
# # 点击【复制链接】 距离右边60 距离底边170 720-60,1280-170
# self.driver.tap([(660, 1110)])
# # self.driver.get_screenshot_as_file('./b.png') # 截图
def main(self):
self.comments() # 点击一次屏幕,确保页面的展示
time.sleep(2)
self.scroll() # 滑动
if __name__ == '__main__':
action = DouyinAction(nums=5)
action.main()
小结
-
了解 appium-python-client模块定位元素以及提取其文本内容的方法
-
了解 appium-python-client模块控制滑动动作的方法
?? 疑难解答可通过搜索下方 ??
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/138875.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...