大家好,又见面了,我是你们的朋友全栈君。
从2010年我来到CSDN,再到2013年我撰写第一篇博客,转眼已经过去十年。590篇原创文章,786万次阅读量,19万位关注博友,这一个个数字的背后,是我3000多天的默默付出,也是我写下近千万文字的心血。
有人说,世间一切,都是遇见,都是机缘。是啊,因为CSDN,我与很多人成为了好朋友,虽未谋面,但这种默默鼓励、相互分享的感觉真好;因为CSDN,我人生进度条八分之一(十年)的许多故事在这里书写,笔耕不辍,也算不得辜负时光吧;因为CSDN,我更珍惜每一位博友、每一位朋友、每一位老师,解答大家的问题,鼓励考研或找工作失败的人继续战斗;因为CSDN,我认识了女神,并分享了许多我们一家的故事。
东西湖的夜很静,博士的征途很辛苦,远方的亲人异常思念。
为什么我要写这样一篇文章呢?一方面,感谢读者这十年的陪伴和包容,不论我分享什么内容,你们给予我的都是鼓励和感动;另一方面,因为改变,接下来我将短暂告别CSDN一段时间(技术更新放缓),好好沉下心来去读论文,去做做科研。
同时,这篇文章非常硬核,会利用Python文本挖掘详细分享这十年的故事,也算是为文本挖掘初学者和写相关论文的读者一些福利。真诚的对所有人说一声感谢,感恩这十年的陪伴,不负遇见,不负时光。请记住一个叫Eastmount的分享者,此生足矣~


文章目录
一.忆往昔分享岁月
关于作者与CSDN这十年的故事,可以阅读这篇文章:
十年,转瞬即逝,我从青葱少年成长为了中年大叔。或许,对其他人来说写博客很平淡,但对我来说,它可能是我这十年最重要的决定和坚守之一。
十年,不负遇见,不负自己,不负时光。感恩所有人的陪伴,因为有你们,人生路上我不孤单。幸好,这十年来,我可以摸着自己的良心说,每一篇博客我都在很认真的撰写,雕琢,都在用万字长文书写下我的满腔热血。
下图是我这十年分享博客按月统计的数量,从2015年找工作分享一次高峰,到如今读博,从零学习安全知识并分享又是一座高峰。

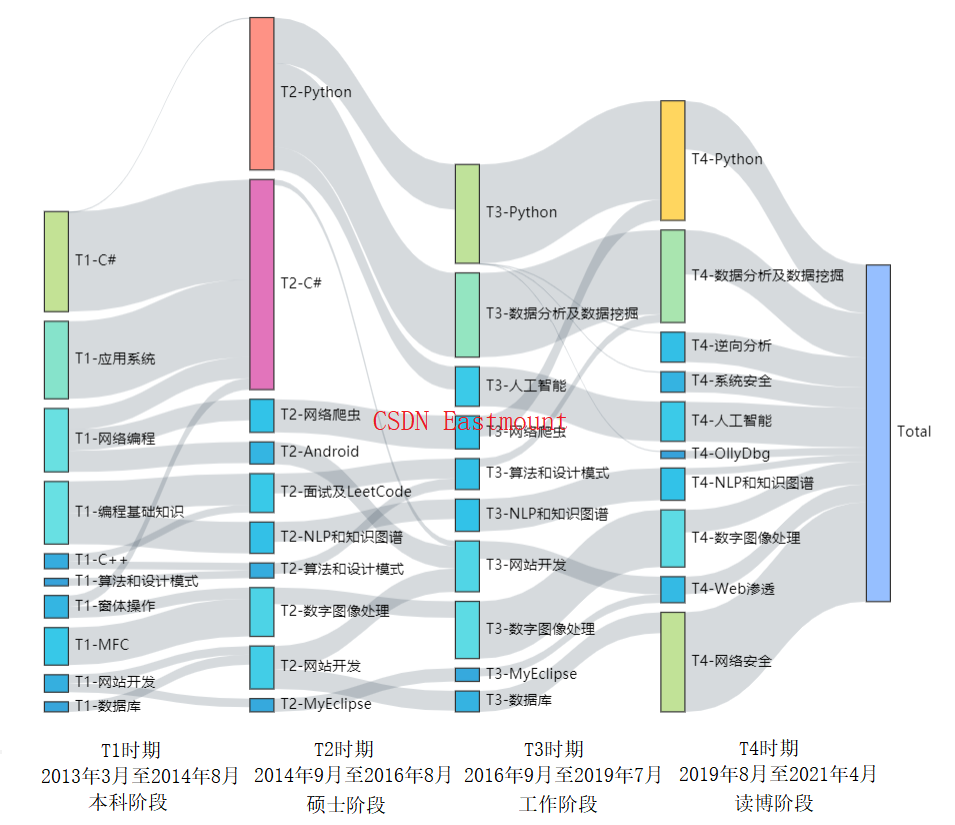
下图是这十年我在CSDN撰写博客的主题演化图,整个十年,我经历了四个阶段。
- 本科阶段:2013年3月至2014年8月
当时以本科课程为主,包括C#、网络开发、课程基础知识等等。 - 硕士阶段:2014年9月至2016年8月
该阶段研究生方向为NLP和知识图谱,因此撰写了大量的Python基础知识,包括Android、C#、面试和LeetCode、网站开发等等。 - 工作阶段:2016年9月至2019年7月
该阶段作者初入职场,选择回到贵州当一名普通的大学教师,并分享了《Python数据挖掘》《网站开发》等课程,撰写《Python人工智能》《Python图像处理》等专栏。 - 博士阶段:2019年9月至2021年4月
该阶段作者再次返回校园,离别家乡亲人选择读博,并换了大方向,转而学习系统安全和网络安全,大量安全知识从零学起,《网络安全自学篇》《网络安全提高班》《系统安全和恶意代码检测》专栏也开启。
有许多人问我,“你分享快乐吗?”
快乐。其实每写一篇博客我的内心都非常喜悦的,每看到读者的一个点赞或评论,我真的开心得像一个小孩。
那为什么还要短暂消失呢?
因为毕业,因为想家,因为想他(她)。我相信,大多数分享者都和我有同样的心情,分享知识的魅力让人久久不能忘怀。但每个阶段都需要做每个阶段的事,远方的亲人尤为思恋,经过我反复思考,所以我决定短暂放下技术博客的撰写,转而选择论文研究。

短暂的消失,并不意味着不分享。
而接下来90%的分享都将与论文和科研技术相关,并且每个月不再PUSH自己写文。我不知道接下来的几年,我究竟能做到什么程度,我也不能保证能否发一篇高质量的论文,但我会去拼搏,会去战斗,会去享受。况且,这十年走来,我从来不认为自己是个聪明的人,比我优秀的人太多太多,我更喜欢的是默默撰写,默默经历,陪着大家一起成长。别人称赞我博客的时候,我更多的回复是“都是时间熬出来的”,也确实是时间熬出来的,只是写了3012天。
但我是真的享受啊,享受在CSDN所分享的一切,享受与每一位博友的相遇相识,享受每一位朋友的祝福与鼓励,我感恩的写下590篇文章,65个专栏,千万文字和代码,也勉强可以说上一句“不负遇见,不负青春,此生足矣”。
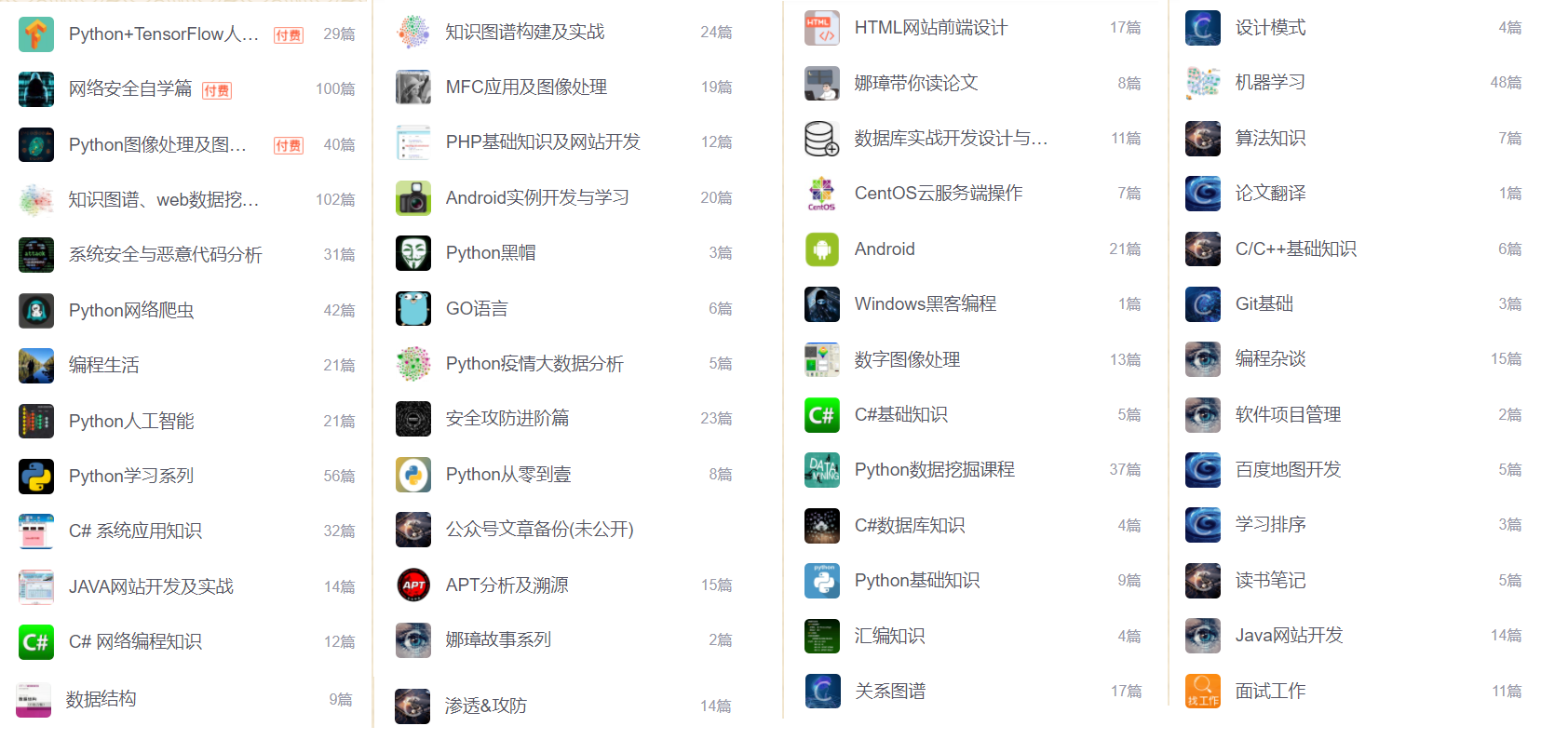
下图展示了这十年我写的博客涉及的各个方向。这些年,我一直都知道学得太杂,而没有深入,就希望博士期间能深入某个领域,博一博二安全基础知识也学了很多,所以接下来是时候进入第五个阶段,开启论文的阅读和撰写以及实验复现。也希望博友们理解,更期待您的陪伴。
沙子是握不住的,时间也是。
但当我付出之后,我可以随手把它扬起,我可以把在时间中发生的点滴记录,比如技术、又如爱情。读博苦吗?苦,无数个寂静的夜都需要我们去熬,去拼,但有的人更苦,比如家里的另一位。接下来三年,我希望自己始终记住,我为什么选择来到这里,选择来到东西湖。也是时候沉下心来去学习论文和做实验了,技术分享该放就放,虽然不舍。握不住的沙,就随手扬了它;即便回到原点,我也没有失去什么,况且这段经历也是人生的谈资啊。也希望每一位博友都珍惜当下,都去做自己喜欢的事情,去经历。
我看着路,梦的入口有点窄,这或许是最美丽的意外。
这篇文章我将使用在CSDN的第一次群发,还请见谅,下一次应该是2024年我博士毕业那天。再次感谢所有人的陪伴,一个好的分享者需要不断去学习新知识,前沿技术再总结给大家,所以我们应该尊重每一位创作者的果实。同时,我在这里向所有读者保证,三年之后,我将带着新的理解,新的感受,去分享更优质的文章,去回馈所有读者,帮助更多初学者入门,或许手痒我也会写一篇非常详细的总结吧。
再次感谢大家,希望大家记住CSDN有一位叫Eastmount的作者,一位叫杨秀璋的博主,如果能记住娜璋和小珞一家就更开心了,哈哈~爱你们喔,困惑或遇到困难的读者,可以加我微信共同前行。

我们的故事都还在续写,你们的陪伴依然继续。
最后,熟悉我的读者知道我开了三个付费专栏。常常有读者因在校读书或经济拮据,因此我在文中多次提到可以私聊我给全文,其实我早已把这些文章开源到了github,我更希望每一位读者都能从文章中学到知识,希望觉得文章好且手里轻松的给个9块打赏,奶粉钱就够了。在此,我也把这三个地址分享给需要的读者吧!且行且珍惜,购买也欢迎喔。
- Python图像处理
https://github.com/eastmountyxz/CSDNBlog-ImageProcessing - 网络安全自学篇
https://github.com/eastmountyxz/CSDNBlog-Security-Based - Python人工智能
https://github.com/eastmountyxz/CSDNBlog-AI-for-Python
给想学技术的说声抱歉,大家记得等我喔!江湖再见,感恩同行。

二.硬核-CSDN博客文本挖掘
之前我给学安全的读者一波福利,告诉大家安全学习路线及CSDN优秀的博主。
这里,我最后再给Python文本挖掘读者一波福利。希望您喜欢~这篇文章思路大家可以借鉴,但不要直接拿去写论文喔!但思路已经非常清晰,大家一定动手撰写代码。
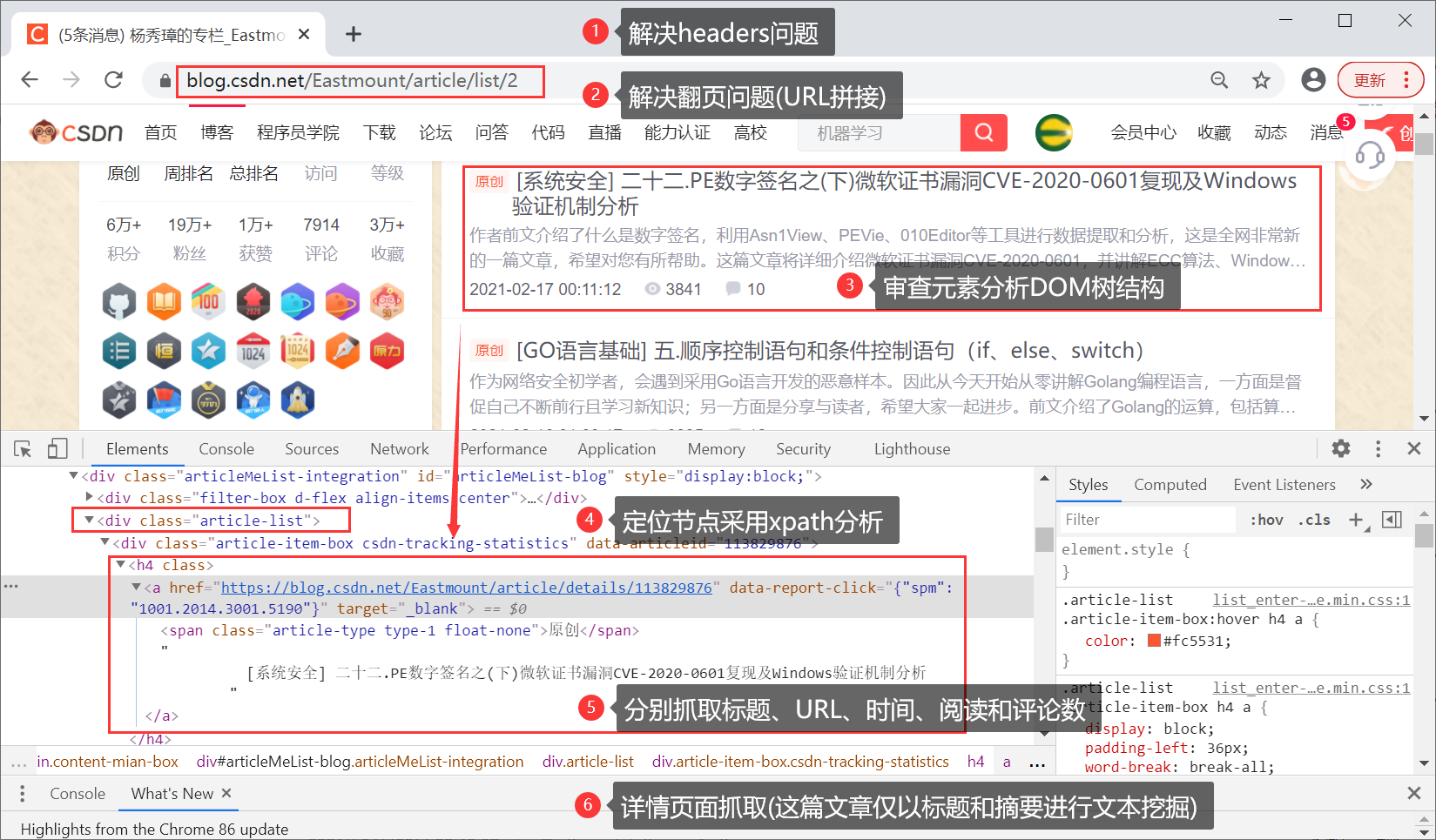
1.数据爬取
这里不介绍具体代码,保护CSDN原创,但会给出对应的核心知识点。建议读者结合自己的方向去抓取文本知识。
核心扩展包:
- import requests
- from lxml import etree
- import csv
核心流程:
- 解决headers问题
- 解决翻页问题
- 审查元素分析DOM树结构
- 定位节点采用Xpath分析
- 分别赚取标题、URL、时间、阅读和评论数量
- 详情页面抓取
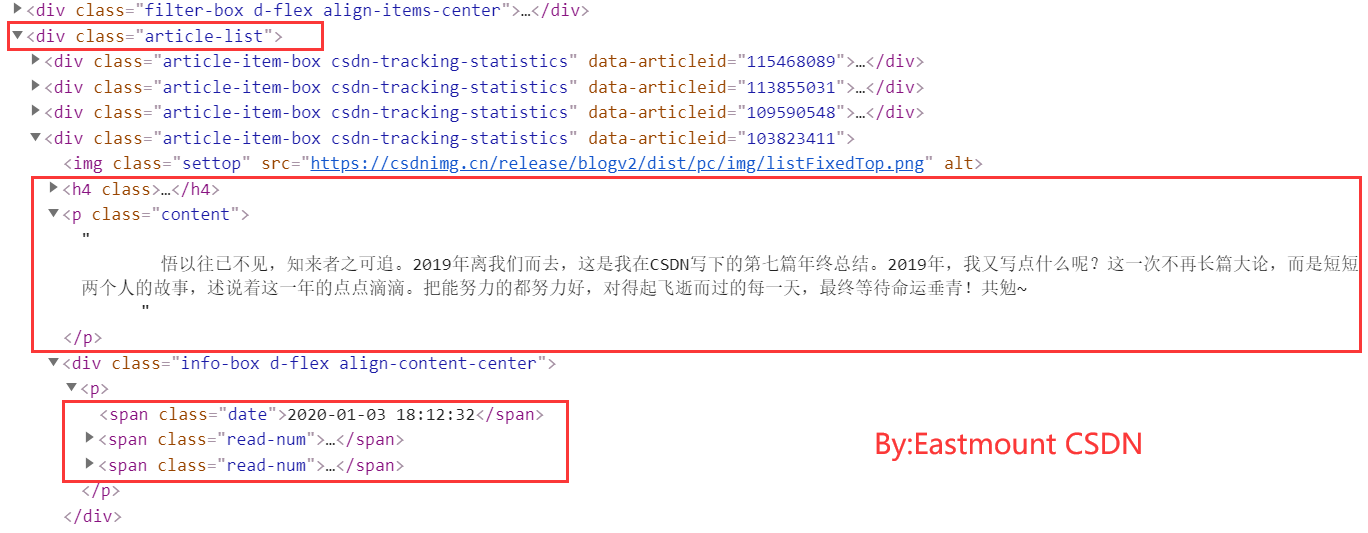
爬虫输出结果,建议学会打桩输出(多用print)。
整理后的结果如下图所示,内容输出到CSV存储。
2.计量统计和可视化分析
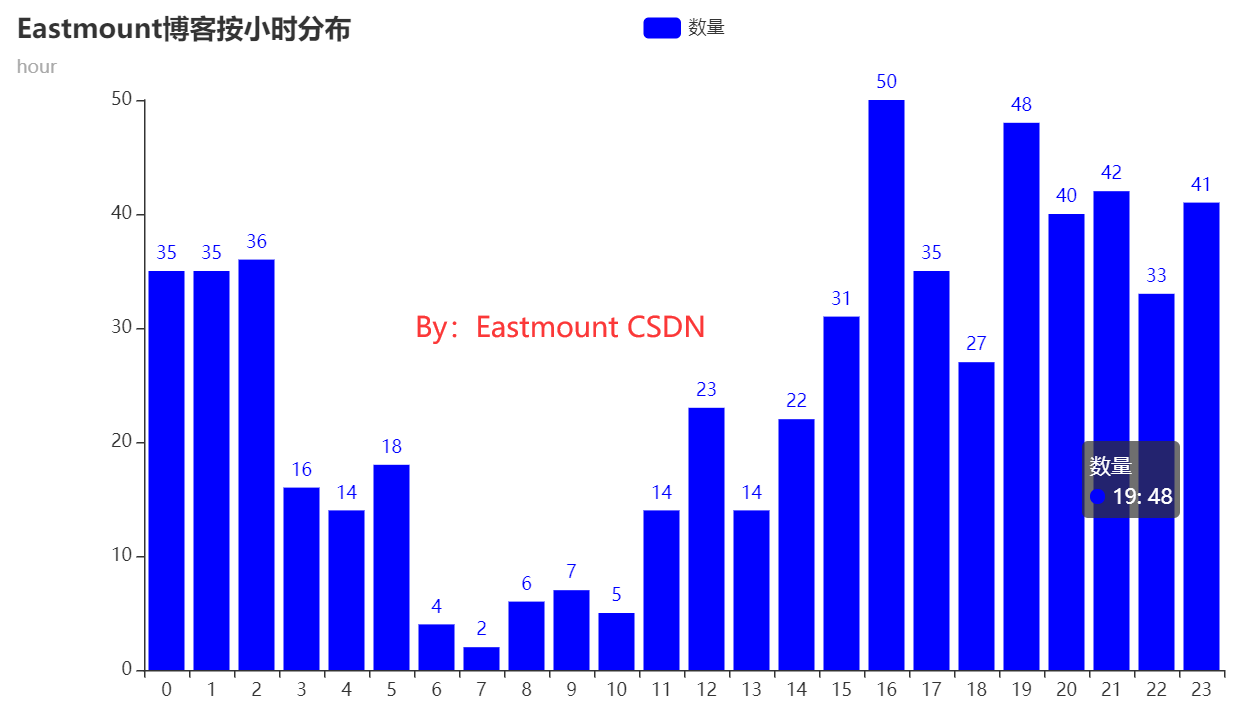
(1) 按小时分析作者撰写习惯
首先,我们来分析作者“Eastmount”的撰写博客习惯,同时利用Matplotlib和PyEcharts绘制图形,发现Echarts绘制的图形更好看。由图可知,该作者长期在深夜和下午撰写博客。
源代码如下:
# encoding:utf-8
""" By:Easmount CSDN 2021-04-19 """
import re
import time
import csv
import pandas as pd
import numpy as np
#------------------------------------------------------------------------------
#第一步 读取数据
dd = [] #日期
tt = [] #时间
with open("data.csv", "r", encoding="utf8") as csvfile:
csv_reader = csv.reader(csvfile)
k = 0
for row in csv_reader:
if k==0: #跳过标题
k = k + 1
continue
#获取数据 2021-04-08 21:52:21
value_date = row[4]
value_time = row[5]
hour = value_time.split(":")[0]
hour = int(hour)
dd.append(row[4])
tt.append(hour)
#print(row[4],row[5])
#print(hour)
k = k + 1
print(len(tt),len(dd))
print(dd)
print(tt)
#------------------------------------------------------------------------------
#第二步 统计不同小时的个数
from collections import Counter
cnt = Counter(tt)
print(cnt.items()) #dict_items
#字典按键排序
list_time = []
list_tnum = []
for i in sorted(cnt):
print(i,cnt[i])
list_time.append(i)
list_tnum.append(cnt[i])
#------------------------------------------------------------------------------
#第三步 绘制柱状图
import matplotlib.pyplot as plt
N = 24
ind = np.arange(N)
width=0.35
plt.bar(ind, list_tnum, width, color='r', label='hour')
plt.xticks(ind+width/2, list_time, rotation=40)
plt.title("The Eastmount's blog is distributed by the hour")
plt.xlabel('hour')
plt.ylabel('numbers')
plt.savefig('Eastmount-01.png',dpi=400)
plt.show()
#------------------------------------------------------------------------------
#第四步 PyEcharts绘制柱状图
from pyecharts import options as opts
from pyecharts.charts import Bar
bar=(
Bar()
.add_xaxis(list_time)
.add_yaxis("数量", list_tnum, color="blue")
.set_global_opts(title_opts=opts.TitleOpts(
title="Eastmount博客按小时分布", subtitle="hour"))
)
bar.render('01-Eastmount博客按小时分布.html')
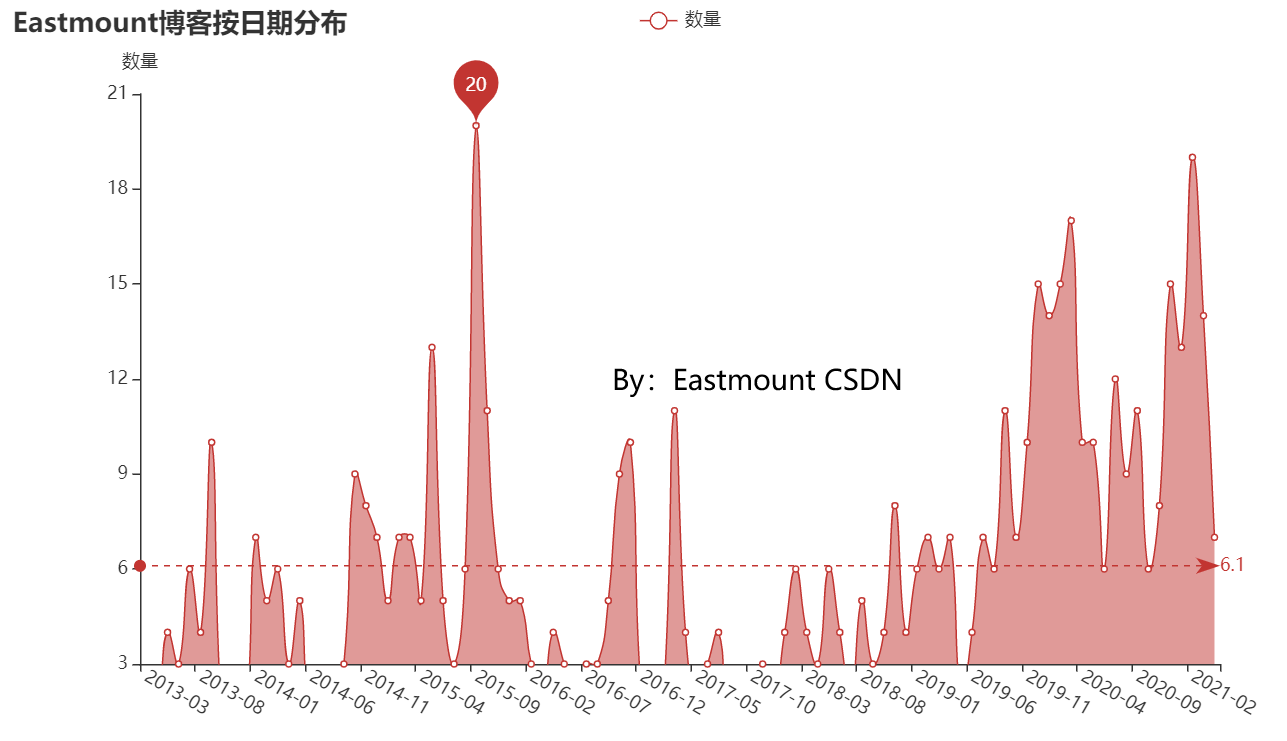
(2) 按月份统计博客
作者按月份撰写博客如下图所示,2015年找工作撰写了大量LeetCode代码,后续是读博期间安全分享较多。
源代码如下:
# encoding:utf-8
""" By:Easmount CSDN 2021-04-19 """
import re
import time
import csv
import pandas as pd
import numpy as np
#------------------------------------------------------------------------------
#第一步 读取数据
dd = [] #日期
tt = [] #时间
with open("data.csv", "r", encoding="utf8") as csvfile:
csv_reader = csv.reader(csvfile)
k = 0
for row in csv_reader:
if k==0: #跳过标题
k = k + 1
continue
#获取数据 2021-04-08 21:52:21
value_date = row[4]
value_time = row[5]
hour = value_time.split(":")[0] #获取小时
hour = int(hour)
month = value_date[:7] #获取月份
dd.append(month)
tt.append(hour)
#print(row[4],row[5])
#print(hour,month)
print(month)
k = k + 1
#break
print(len(tt),len(dd))
print(dd)
print(tt)
#------------------------------------------------------------------------------
#第二步 统计不同日期的个数
from collections import Counter
cnt = Counter(dd)
print(cnt.items()) #dict_items
#字典按键排序
list_date = []
list_dnum = []
for i in sorted(cnt):
print(i,cnt[i])
list_date.append(i)
list_dnum.append(cnt[i])
#------------------------------------------------------------------------------
#第三步 PyEcharts绘制柱状图
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.charts import Line
from pyecharts.commons.utils import JsCode
line = (
Line()
.add_xaxis(list_date)
.add_yaxis('数量', list_dnum, is_smooth=True,
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]),
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max"),
opts.MarkPointItem(type_="min")]))
# 隐藏数字 设置面积
.set_series_opts(
areastyle_opts=opts.AreaStyleOpts(opacity=0.5),
label_opts=opts.LabelOpts(is_show=False))
# 设置x轴标签旋转角度
.set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)),
yaxis_opts=opts.AxisOpts(name='数量', min_=3),
title_opts=opts.TitleOpts(title='Eastmount博客按日期分布'))
)
line.render('02-Eastmount博客按日期分布.html')
(3) 按星期统计博客
按星期统计如下,调用date.weekday()函数可以输出对应的星期。周末作者更新稍微少一些。
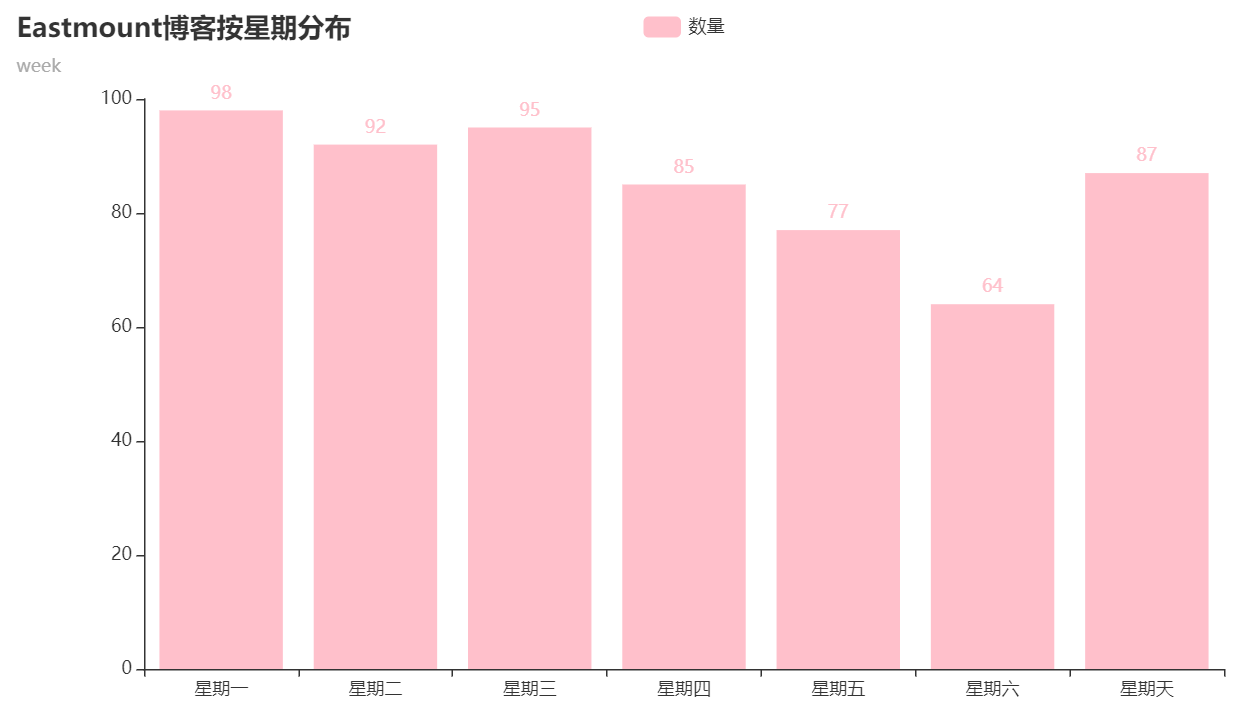
核心代码如下:
# encoding:utf-8
""" By:Easmount CSDN 2021-04-19 """
import re
import time
import csv
import pandas as pd
import numpy as np
import datetime
#定义星期函数
def get_week_day(date):
week_day_dict = {
0 : '星期一',
1 : '星期二',
2 : '星期三',
3 : '星期四',
4 : '星期五',
5 : '星期六',
6 : '星期天'
}
day = date.weekday()
return week_day_dict[day]
#------------------------------------------------------------------------------
#第一步 读取数据
dd = [] #日期
tt = [] #时间
ww = [] #星期
with open("data.csv", "r", encoding="utf8") as csvfile:
csv_reader = csv.reader(csvfile)
k = 0
for row in csv_reader:
if k==0: #跳过标题
k = k + 1
continue
#获取数据 2021-04-08 21:52:21
value_date = row[4]
value_time = row[5]
hour = value_time.split(":")[0] #获取小时
hour = int(hour)
month = value_date[:7] #获取月份
dd.append(month)
tt.append(hour)
#获取星期
date = datetime.datetime.strptime(value_date, '%Y-%m-%d').date()
week = get_week_day(date)
ww.append(week)
#print(date,week)
k = k + 1
print(len(tt),len(dd),len(ww))
print(dd)
print(tt)
print(ww)
#------------------------------------------------------------------------------
#第二步 统计不同日期的个数
from collections import Counter
cnt = Counter(ww)
print(cnt.items()) #dict_items
#字典按键排序
list_date = ['星期一','星期二','星期三','星期四','星期五','星期六','星期天']
list_dnum = [0,0,0,0,0,0,0]
for key,value in cnt.items():
k = 0
while k<len(list_date):
if key==list_date[k]:
list_dnum[k] = value
break
k = k + 1
print(list_date,list_dnum)
#------------------------------------------------------------------------------
#第三步 PyEcharts绘制柱状图
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.charts import Line
from pyecharts.commons.utils import JsCode
bar=(
Bar()
.add_xaxis(list_date)
.add_yaxis("数量", list_dnum, color='pink')
.set_global_opts(title_opts=opts.TitleOpts(
title="Eastmount博客按星期分布", subtitle="week"))
)
bar.render('03-Eastmount博客按星期分布.html')
3.核心词统计及词云分析
词云分析非常适合初学者,这里作者也简单分享核心主题词统计和词云分析的过程。
(1) 统计核心关键词及词频
输出结果如下图所示:

代码如下:
# coding=utf-8
""" By:Easmount CSDN 2021-04-19 """
import jieba
import re
import time
import csv
from collections import Counter
#------------------------------------中文分词----------------------------------
cut_words = ""
all_words = ""
stopwords = ["[", "]", ")", "(", ")", "(", "【", "】",
".", "、", "-", "—", ":", ":", "《", "》",
"的", "和", "之", "及", "“", "”", "?", "?"]
#导入自定义词典
#jieba.load_userdict("dict.txt")
f = open('06-data-fenci.txt', 'w')
with open("data.csv", "r", encoding="utf8") as csvfile:
csv_reader = csv.reader(csvfile)
k = 0
for row in csv_reader:
if k==0: #跳过标题
k = k + 1
continue
#获取数据
title = row[1]
title = title.strip('\n')
#print(title)
#分词
cut_words = ""
seg_list = jieba.cut(title,cut_all=False)
for seg in seg_list:
if seg not in stopwords:
cut_words += seg + " "
#cut_words = (" ".join(seg_list))
f.write(cut_words+"\n")
all_words += cut_words
k = k + 1
f.close()
#输出结果
all_words = all_words.split()
print(all_words)
#------------------------------------词频统计----------------------------------
c = Counter()
for x in all_words:
if len(x)>1 and x != '\r\n':
c[x] += 1
#输出词频最高的前10个词
print('\n词频统计结果:')
for (k,v) in c.most_common(10):
print("%s:%d"%(k,v))
#存储数据
name ="06-data-word.csv"
fw = open(name, 'w', encoding='utf-8')
i = 1
for (k,v) in c.most_common(len(c)):
fw.write(str(i)+','+str(k)+','+str(v)+'\n')
i = i + 1
else:
print("Over write file!")
fw.close()
(2) PyEcharts词云可视化
输出结果如下图所示,出现词频越高的单词显示越大、越鲜艳。

代码如下:
# coding=utf-8
""" By:Easmount CSDN 2021-04-19 """
import jieba
import re
import time
import csv
from collections import Counter
#------------------------------------中文分词----------------------------------
cut_words = ""
all_words = ""
stopwords = ["[", "]", ")", "(", ")", "(", "【", "】",
"01", "02", "03", "04", "05", "06", "07",
"08", "09", "什么"]
f = open('06-data-fenci.txt', 'w')
with open("data.csv", "r", encoding="utf8") as csvfile:
csv_reader = csv.reader(csvfile)
k = 0
for row in csv_reader:
if k==0: #跳过标题
k = k + 1
continue
#获取数据
title = row[1]
title = title.strip('\n')
#print(title)
#分词
cut_words = ""
seg_list = jieba.cut(title,cut_all=False)
for seg in seg_list:
if seg not in stopwords:
cut_words += seg + " "
#cut_words = (" ".join(seg_list))
f.write(cut_words+"\n")
all_words += cut_words
k = k + 1
f.close()
#输出结果
all_words = all_words.split()
print(all_words)
#------------------------------------词频统计----------------------------------
c = Counter()
for x in all_words:
if len(x)>1 and x != '\r\n':
c[x] += 1
#输出词频最高的前10个词
print('\n词频统计结果:')
for (k,v) in c.most_common(10):
print("%s:%d"%(k,v))
#存储数据
name ="06-data-word.csv"
fw = open(name, 'w', encoding='utf-8')
i = 1
for (k,v) in c.most_common(len(c)):
fw.write(str(i)+','+str(k)+','+str(v)+'\n')
i = i + 1
else:
print("Over write file!")
fw.close()
#------------------------------------词云分析----------------------------------
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
# 生成数据 word = [('A',10), ('B',9), ('C',8)] 列表+Tuple
words = []
for (k,v) in c.most_common(200):
# print(k, v)
words.append((k,v))
# 渲染图
def wordcloud_base() -> WordCloud:
c = (
WordCloud()
.add("", words, word_size_range=[20, 40], shape='diamond') #shape=SymbolType.ROUND_RECT
.set_global_opts(title_opts=opts.TitleOpts(title='Eastmount十年博客词云图'))
)
return c
# 生成图
wordcloud_base().render('05-Eastmount十年博客词云图.html')
4.LDA主题挖掘
LDA模型是文本挖掘或主题挖掘中非常经典的算法,读者可以阅读作者之前的文章,详细介绍该模型。这里,我们用它来对作者博客进行主题挖掘,设置的主题数为4,通常需要计算困惑度比较。
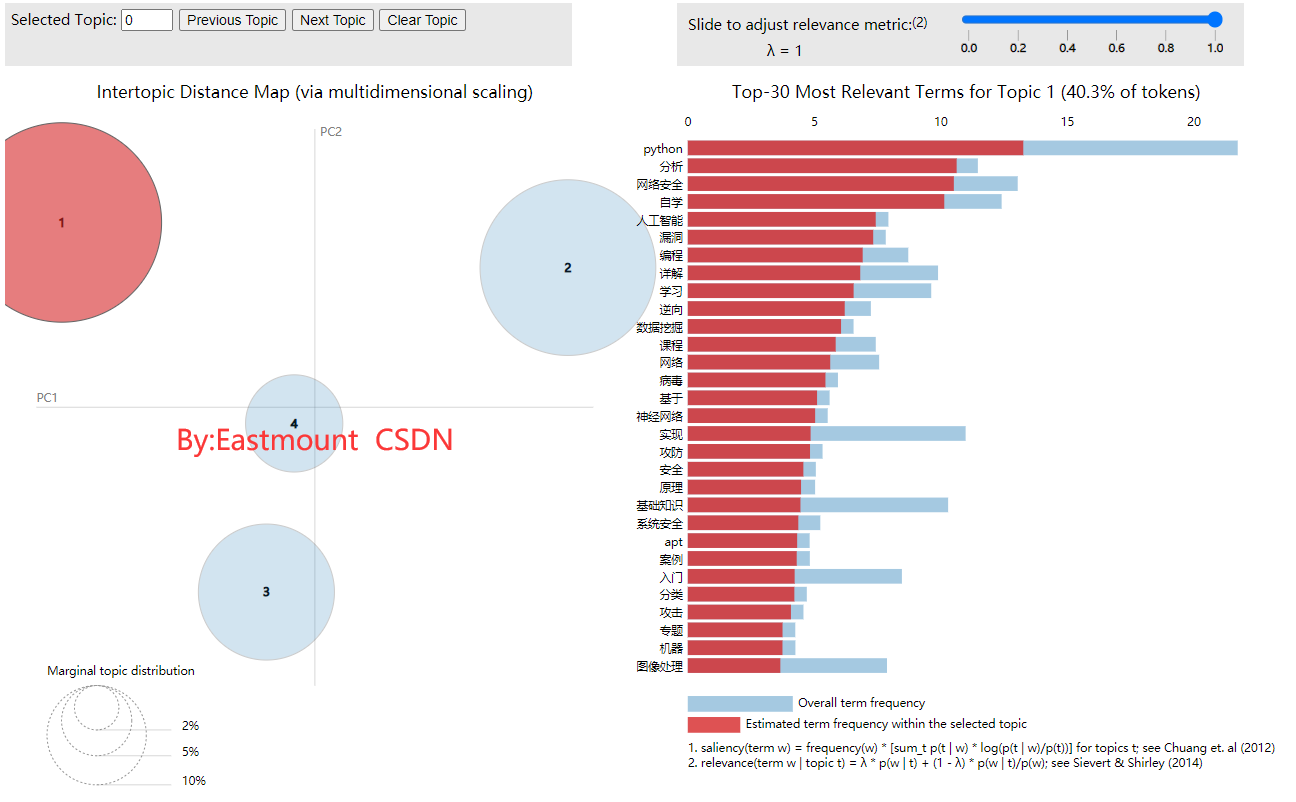
同时计算各个主题对应的主题词,如下所示。注意,建议读者结合自己的文本进行相应的优化,这会得到更符合真实情况的主题词,并且主题之间会存在相互交融的现象,比如安全系列博客,会有Python相关的渗透文章。

完整代码如下:
#coding: utf-8
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
#--------------------- 第一步 读取数据(已分词) ----------------------
corpus = []
# 读取预料 一行预料为一个文档
for line in open('06-data-fenci.txt', 'r').readlines():
corpus.append(line.strip())
#----------------------- 第二步 计算TF-IDF值 -----------------------
# 设置特征数
n_features = 2000
tf_vectorizer = TfidfVectorizer(strip_accents = 'unicode',
max_features=n_features,
stop_words=['的','或','等','是','有','之','与','可以','还是','这里',
'一个','和','也','被','吗','于','中','最','但是','大家',
'一下','几天','200','还有','一看','300','50','哈哈哈哈',
'“','”','。',',','?','、',';','怎么','本来','发现',
'and','in','of','the','我们','一直','真的','18','一次',
'了','有些','已经','不是','这么','一一','一天','这个','这种',
'一种','位于','之一','天空','没有','很多','有点','什么','五个',
'特别'],
max_df = 0.99,
min_df = 0.002) #去除文档内出现几率过大或过小的词汇
tf = tf_vectorizer.fit_transform(corpus)
print(tf.shape)
print(tf)
#------------------------- 第三步 LDA分析 ------------------------
from sklearn.decomposition import LatentDirichletAllocation
# 设置主题数
n_topics = 4
lda = LatentDirichletAllocation(n_components=n_topics,
max_iter=100,
learning_method='online',
learning_offset=50,
random_state=0)
lda.fit(tf)
# 显示主题数 model.topic_word_
print(lda.components_)
# 几个主题就是几行 多少个关键词就是几列
print(lda.components_.shape)
# 计算困惑度
print(u'困惑度:')
print(lda.perplexity(tf,sub_sampling = False))
# 主题-关键词分布
def print_top_words(model, tf_feature_names, n_top_words):
for topic_idx,topic in enumerate(model.components_): # lda.component相当于model.topic_word_
print('Topic #%d:' % topic_idx)
print(' '.join([tf_feature_names[i] for i in topic.argsort()[:-n_top_words-1:-1]]))
print("")
# 定义好函数之后 暂定每个主题输出前20个关键词
n_top_words = 20
tf_feature_names = tf_vectorizer.get_feature_names()
# 调用函数
print_top_words(lda, tf_feature_names, n_top_words)
#------------------------ 第四步 可视化分析 -------------------------
import pyLDAvis
import pyLDAvis.sklearn
#pyLDAvis.enable_notebook()
data = pyLDAvis.sklearn.prepare(lda,tf,tf_vectorizer)
print(data)
#显示图形
pyLDAvis.show(data)
pyLDAvis.save_json(data,' 06-fileobj.html')
5.层次聚类主题树状图
层次聚类绘制的树状图,也是文本挖掘领域常用的技术,它会将各个领域相关的主题以树状的形式进行显示,这里输出结果如下图所示:
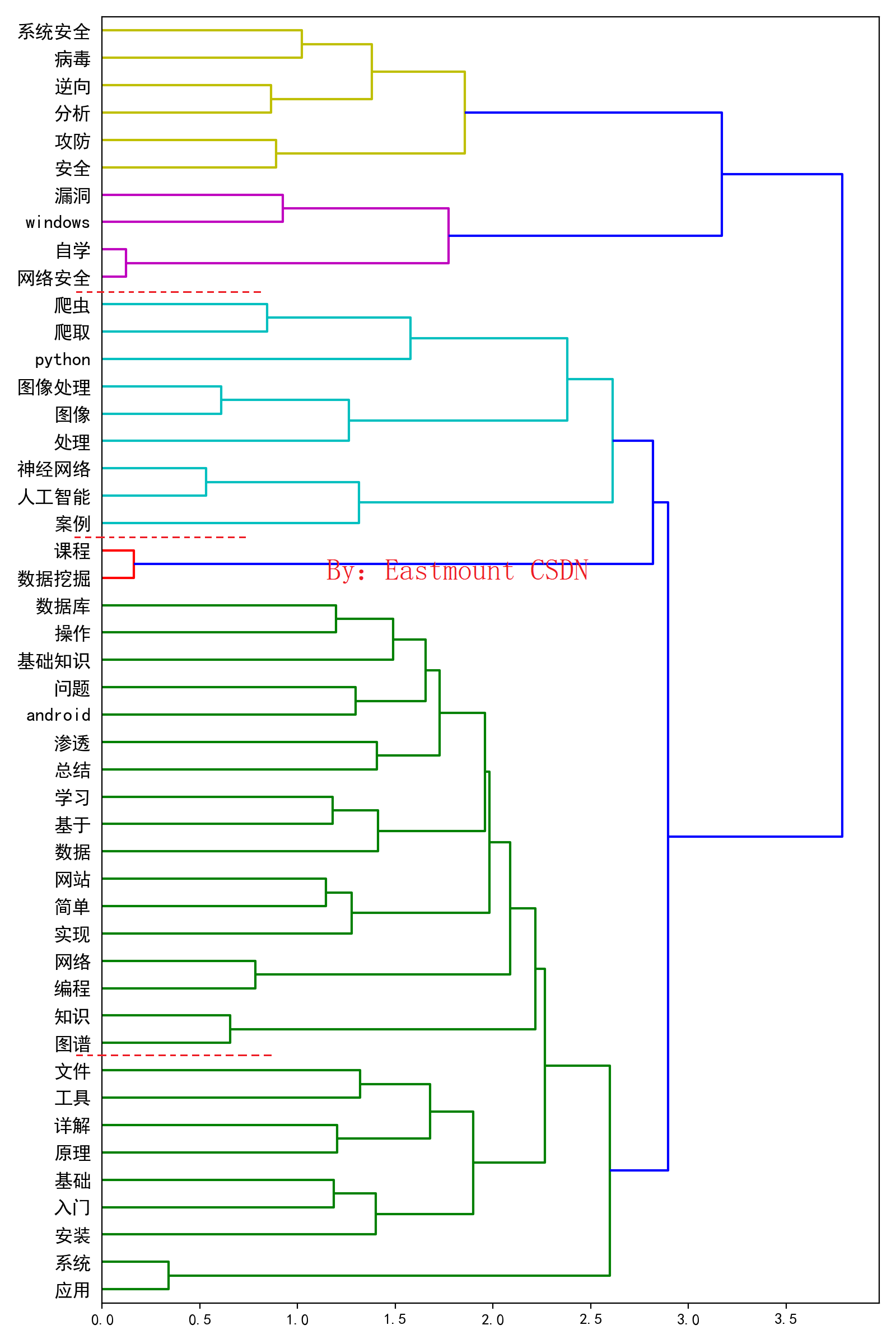
注意,这里作者可以通过设置过滤来显示树状图显示的主题词数量,并进行相关的对比实验,找到最优结果。
# -*- coding: utf-8 -*-
import os
import codecs
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import jieba
from sklearn import metrics
from sklearn.metrics import silhouette_score
from array import array
from numpy import *
from pylab import mpl
from sklearn.metrics.pairwise import cosine_similarity
import matplotlib.pyplot as plt
import matplotlib as mpl
from scipy.cluster.hierarchy import ward, dendrogram
#---------------------------------------加载语料-------------------------------------
text = open('06-data-fenci.txt').read()
print(text)
list1=text.split("\n")
print(list1)
print(list1[0])
print(list1[1])
mytext_list=list1
#控制显示数量
count_vec = CountVectorizer(min_df=20, max_df=1000) #最大值忽略
xx1 = count_vec.fit_transform(list1).toarray()
word=count_vec.get_feature_names()
print("word feature length: {}".format(len(word)))
print(word)
print(xx1)
print(type(xx1))
print(xx1.shape)
print(xx1[0])
#---------------------------------------层次聚类-------------------------------------
titles = word
#dist = cosine_similarity(xx1)
mpl.rcParams['font.sans-serif'] = ['SimHei']
df = pd.DataFrame(xx1)
print(df.corr())
print(df.corr('spearman'))
print(df.corr('kendall'))
dist = df.corr()
print (dist)
print(type(dist))
print(dist.shape)
#define the linkage_matrix using ward clustering pre-computed distances
linkage_matrix = ward(dist)
fig, ax = plt.subplots(figsize=(8, 12)) # set size
ax = dendrogram(linkage_matrix, orientation="right",
p=20, labels=titles, leaf_font_size=12
) #leaf_rotation=90., leaf_font_size=12.
#show plot with tight layout
plt.tight_layout()
#save figure as ward_clusters
plt.savefig('07-KH.png', dpi=200)
plt.show()
6.社交网络分析
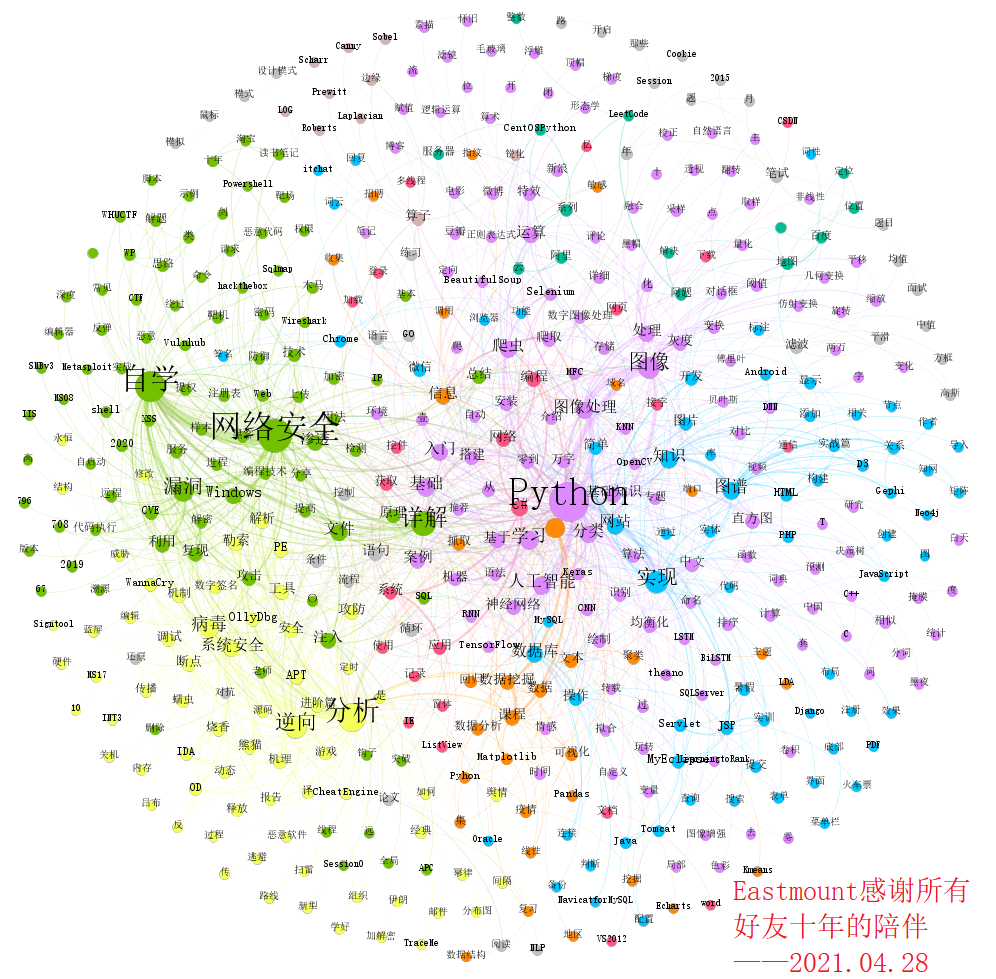
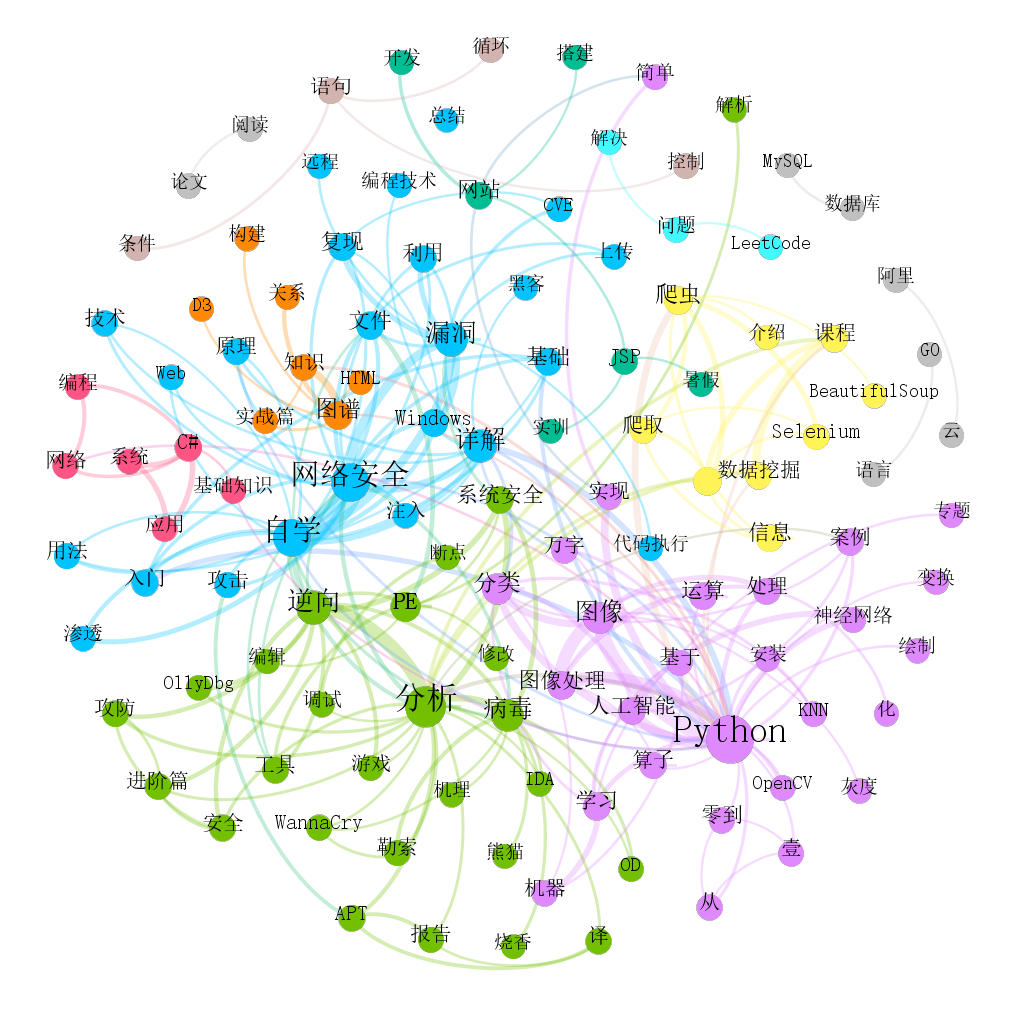
社交网络分析常用于引文分析,文科领域有的成为文献知识图谱(和Google提出的知识图谱或本体有区别),它也是文献挖掘领域常用的技术手段。这里我们绘制社交网络关系图谱如下所示,主要利用Gephi软件,也推荐Neo4j或D3。可以看到作者十年的分享主要集中在四块内容,它们又相互联系,相辅相成。
- 网络安全
- Python
- 逆向分析
- 基础知识或编程技术
推荐文章:
第一步,我们需要计算两两共现矩阵。数据量过大可能会边界溢出。
输出结果如下图所示,此时希望大家进行停用词过滤或将异常关系删除。
# -*- coding: utf-8 -*-
""" @author: eastmount CSDN 2020-04-20 """
import pandas as pd
import numpy as np
import codecs
import networkx as nx
import matplotlib.pyplot as plt
import csv
from scipy.sparse import coo_matrix
#---------------------------第一步:读取数据-------------------------------
word = [] #记录关键词
f = open("06-data-fenci.txt", encoding='gbk')
line = f.readline()
while line:
#print line
line = line.replace("\n", "") #过滤换行
line = line.strip('\n')
for n in line.split(' '):
#print n
if n not in word:
word.append(n)
line = f.readline()
f.close()
print(len(word)) #关键词总数 2913
#--------------------------第二步 计算共现矩阵----------------------------
a = np.zeros([2,3])
print(a)
#共现矩阵
#word_vector = np.zeros([len(word),len(word)], dtype='float16')
#MemoryError:矩阵过大汇报内存错误 采用coo_matrix函数解决该问题
print(len(word))
#类型<type 'numpy.ndarray'> 注意切勿写成int8 范围太小
word_vector = coo_matrix((len(word),len(word)), dtype=np.int32).toarray()
print(word_vector.shape)
f = open("06-data-fenci.txt", encoding='gbk')
line = f.readline()
while line:
line = line.replace("\n", "") #过滤换行
line = line.strip('\n') #过滤换行
nums = line.split(' ')
#循环遍历关键词所在位置 设置word_vector计数
i = 0
j = 0
while i<len(nums): #ABCD共现 AB AC AD BC BD CD加1
j = i + 1
w1 = nums[i] #第一个单词
while j<len(nums):
w2 = nums[j] #第二个单词
#从word数组中找到单词对应的下标
k = 0
n1 = 0
while k<len(word):
if w1==word[k]:
n1 = k
break
k = k +1
#寻找第二个关键字位置
k = 0
n2 = 0
while k<len(word):
if w2==word[k]:
n2 = k
break
k = k +1
#重点: 词频矩阵赋值 只计算上三角
if n1<=n2:
word_vector[n1][n2] = word_vector[n1][n2] + 1
else:
word_vector[n2][n1] = word_vector[n2][n1] + 1
#print(n1, n2, w1, w2)
j = j + 1
i = i + 1
#读取新内容
line = f.readline()
#print("next line")
f.close()
print("over computer")
#--------------------------第三步 CSV文件写入--------------------------
c = open("word-word-weight.csv","w", encoding='utf-8', newline='') #解决空行
#c.write(codecs.BOM_UTF8) #防止乱码
writer = csv.writer(c) #写入对象
writer.writerow(['Word1', 'Word2', 'Weight'])
i = 0
while i<len(word):
w1 = word[i]
j = 0
while j<len(word):
w2 = word[j]
#判断两个词是否共现 共现词频不为0的写入文件
if word_vector[i][j]>0:
#写入文件
templist = []
templist.append(w1)
templist.append(w2)
templist.append(str(int(word_vector[i][j])))
#print templist
writer.writerow(templist)
j = j + 1
i = i + 1
c.close()
第二步,我们需要构建实体(节点)和关系(边)的CSV文件。如下图所示:
- entity-clean.csv
- rela-clean.csv
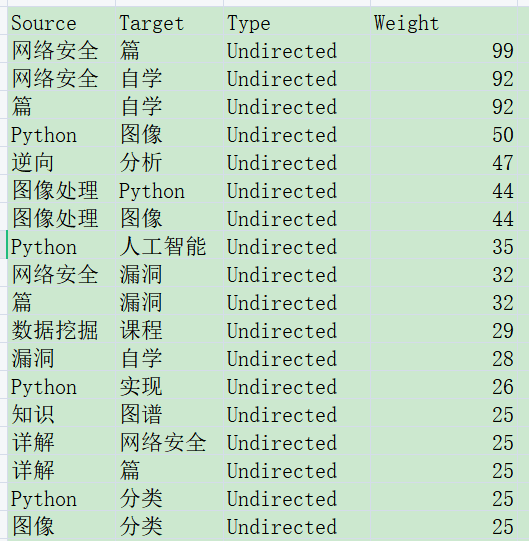
第三步,新建工程,并选择“数据资料”,输入电子表格。导入节点表格,选择entity实体表。
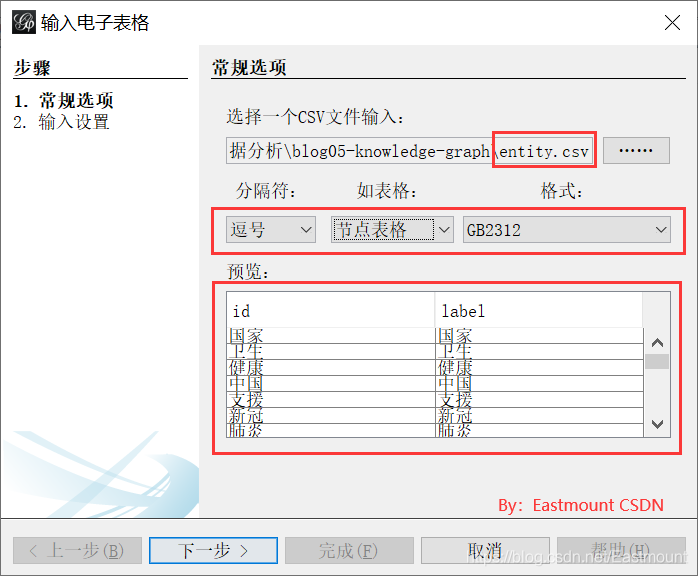
第四步,导入数据,设置为“边表格”,注意CSV表格数据一定设置为 Source(起始点)、Target(目标点)、Weight(权重),这个必须和Gephi格式一致,否则导入数据会提示错误。
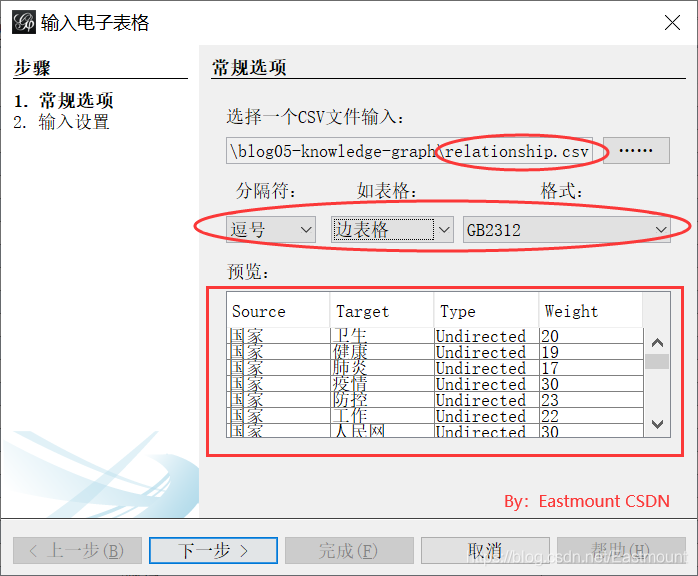
第五步,导入成功后点击“概览”显示如下所示,接着就是调整参数。
第六步,设置模块化,在右边统计中点击“运行”,设置模块性。同时设置平均路径长度,在右边统计中点击“运行”,设置边概述。

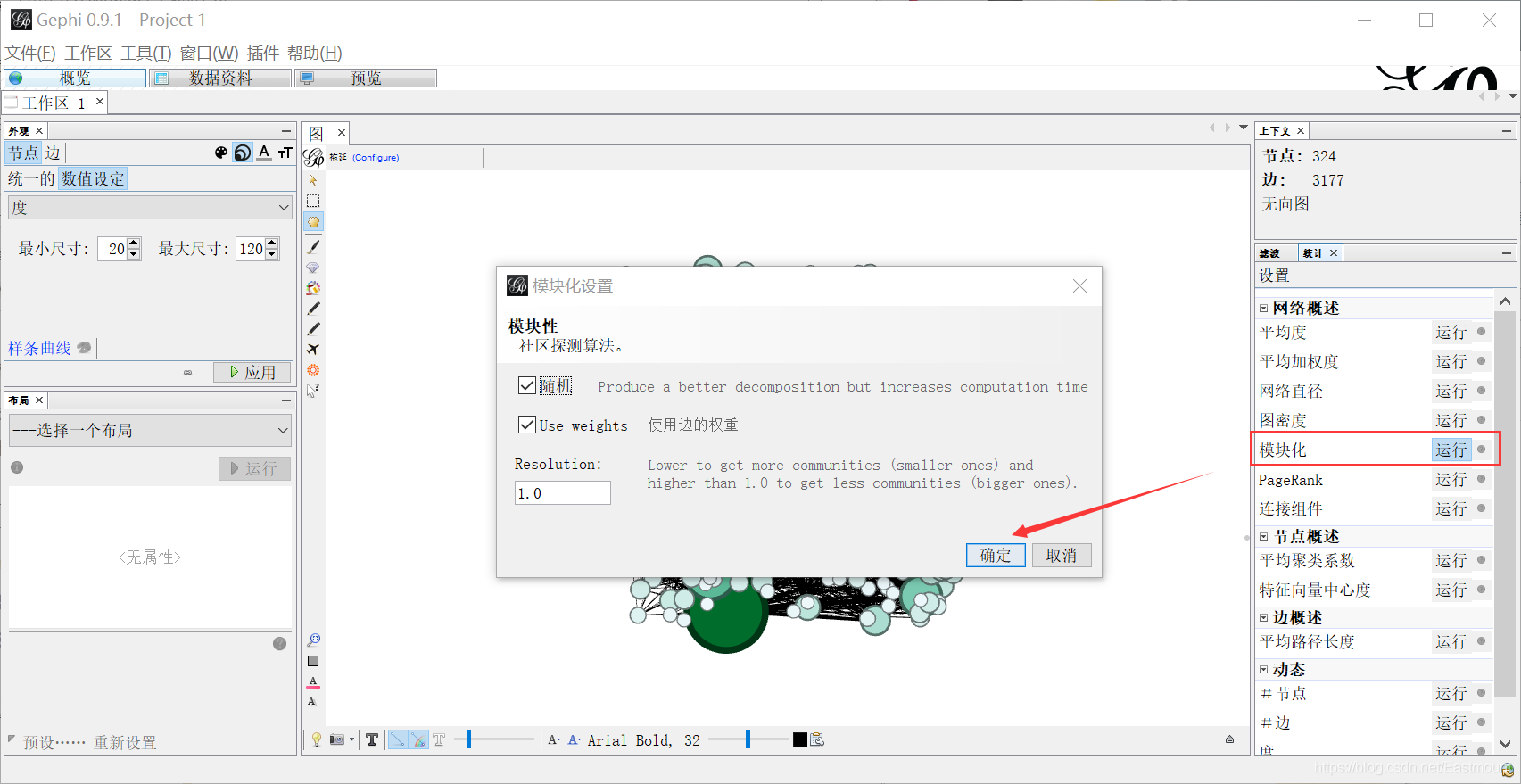
第七步,重新设置节点属性。节点大小数值设定为“度”,最小值还是20,最大值还是120。节点颜色数值设定为“Modularity Class”,表示模块化。
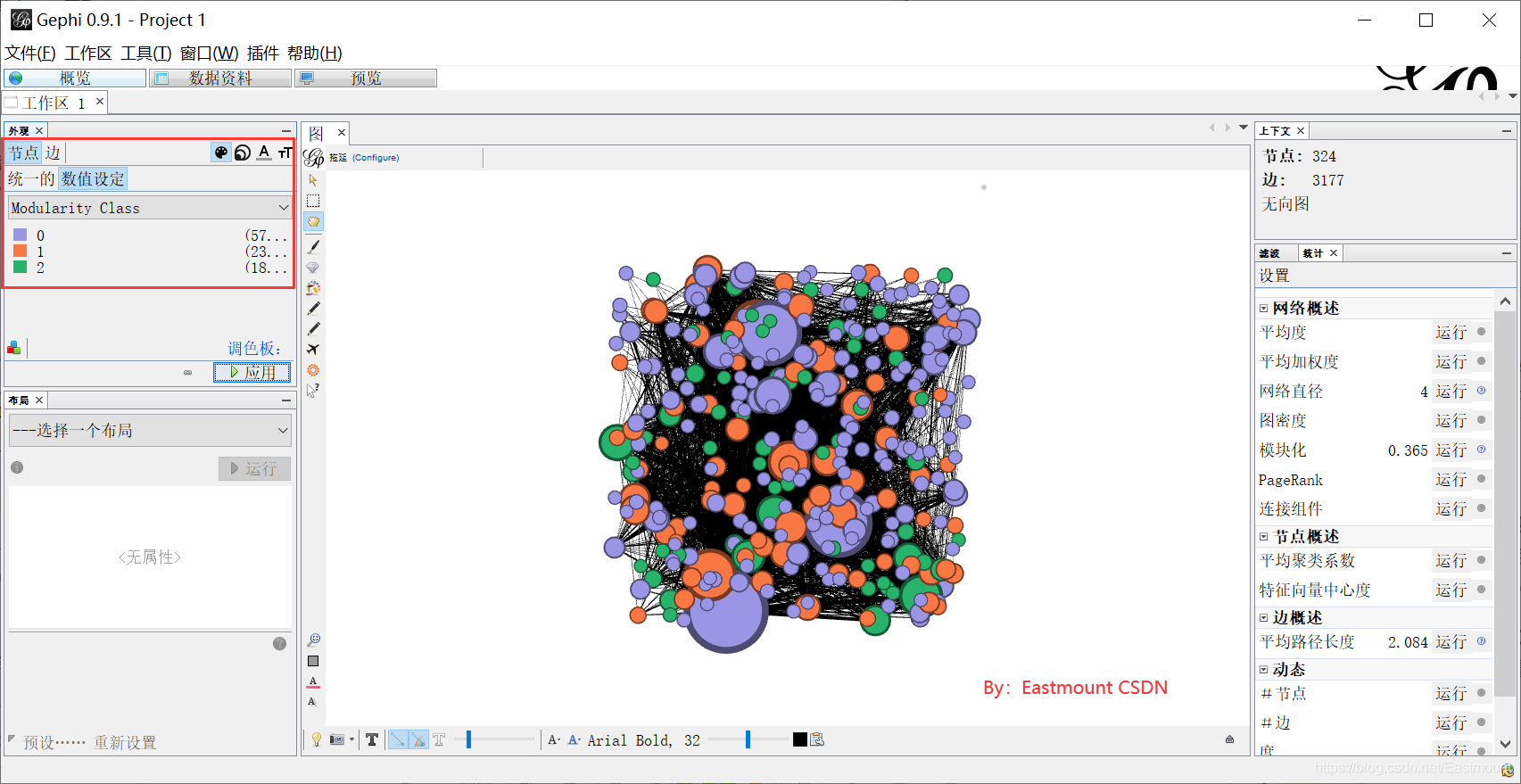
第八步,在布局中选择“Fruchterman Reingold”。调整区、重力和速度。
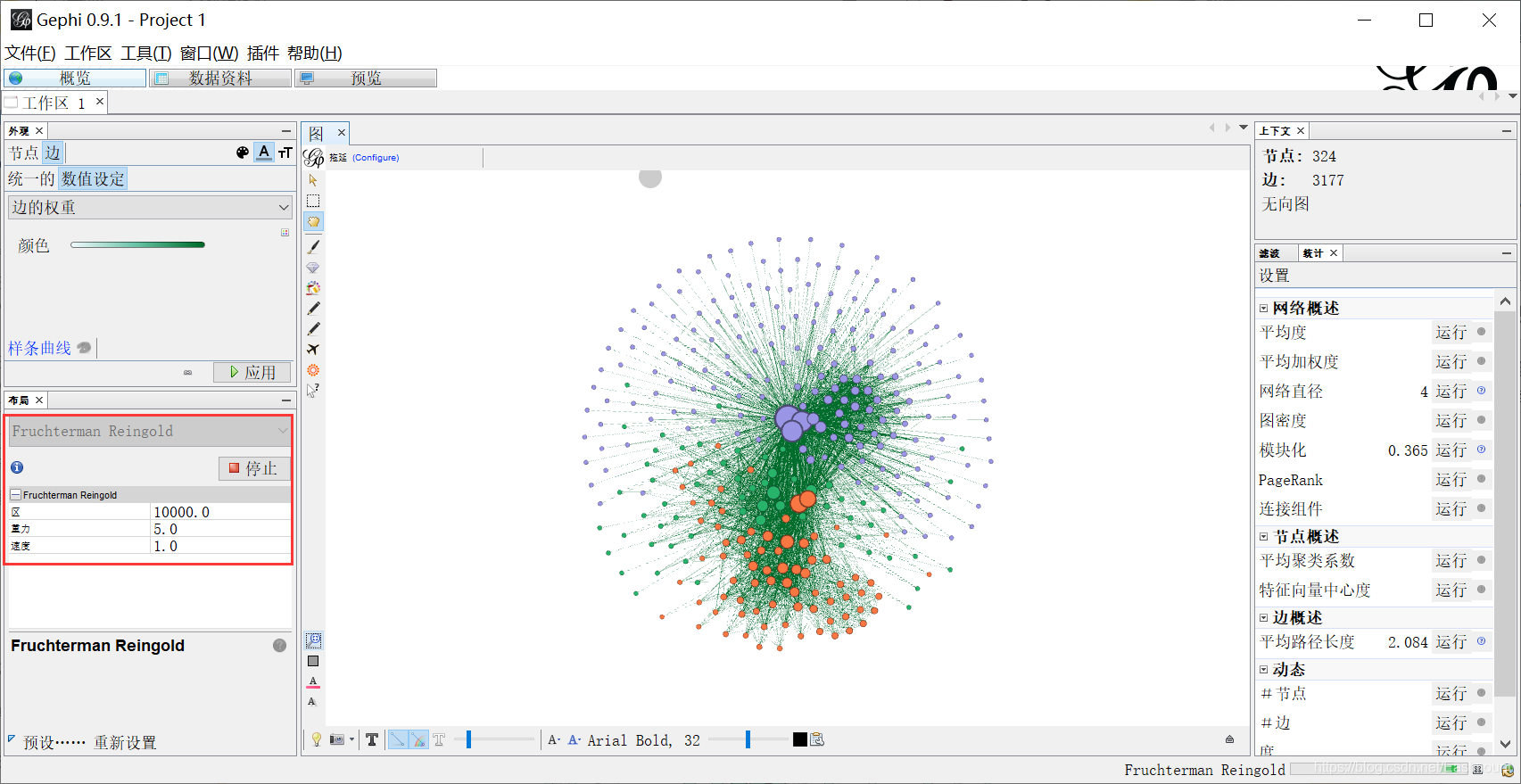
第九步,点击预览。设置宋体字,显示标签,透明度调整为20,如下图所示。
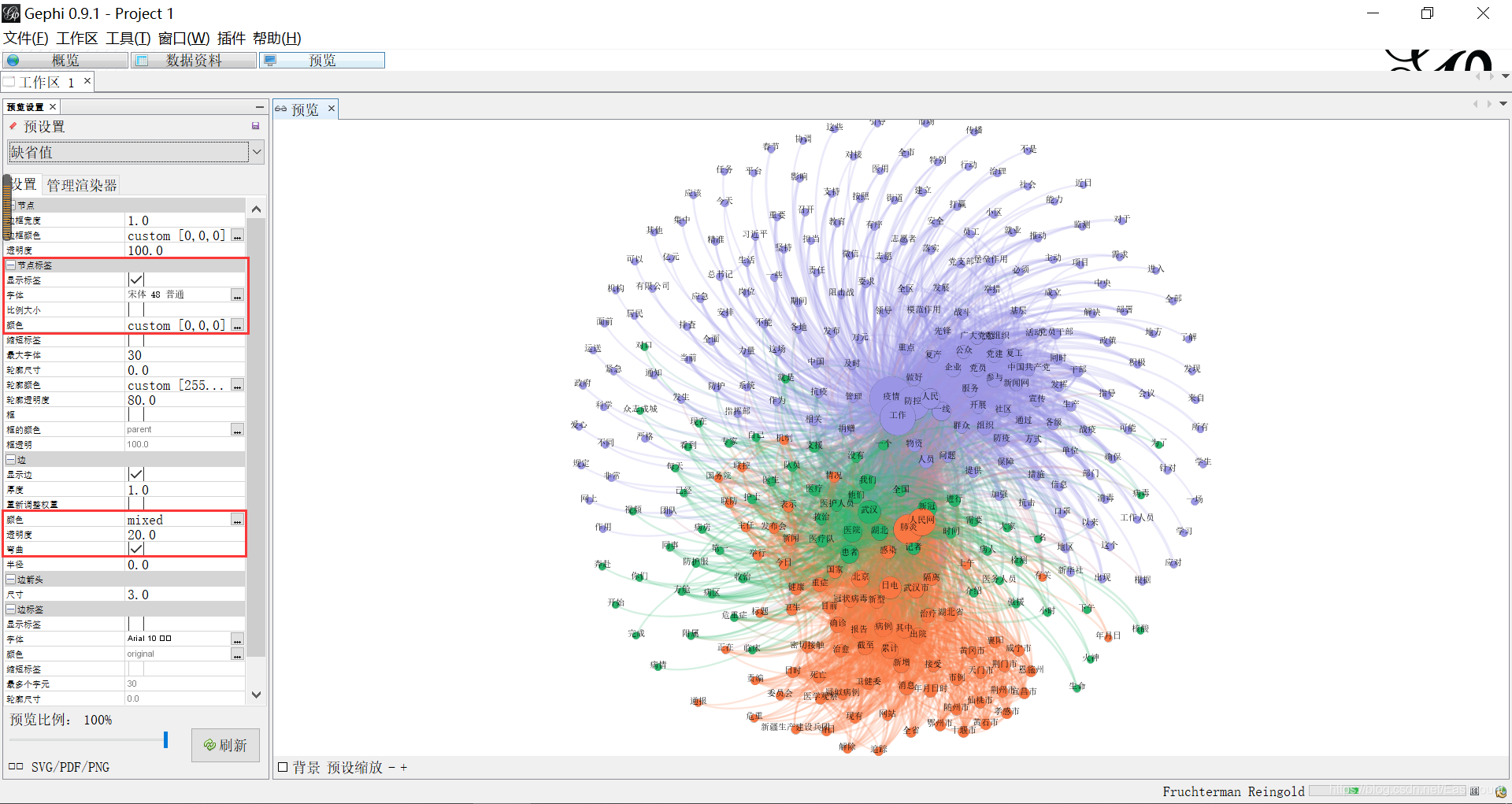
第十步,图谱优化和调整。
同时可以过滤权重或设置颜色模块浅色。比如得到更为精细的关系图谱。
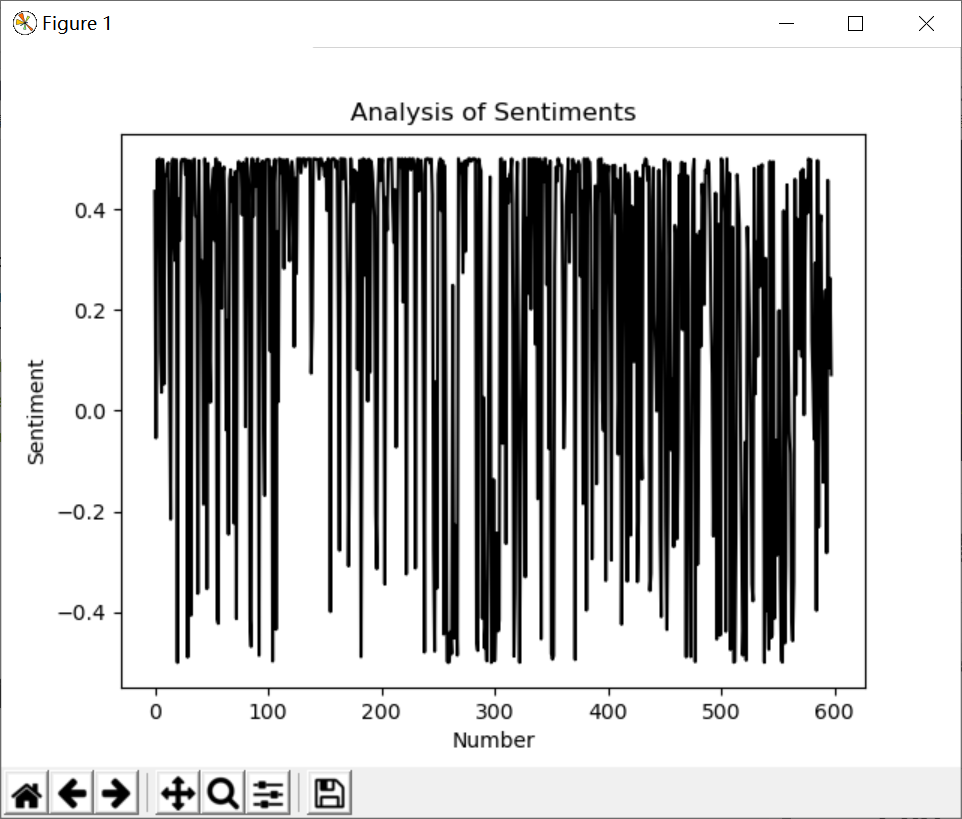
7.博客情感分析
情感分析主要采用SnowNLP实验,也推荐大家使用大连理工大学情感词典进行优化。这里推荐作者之前分析的文章。输出结果如下图所示:
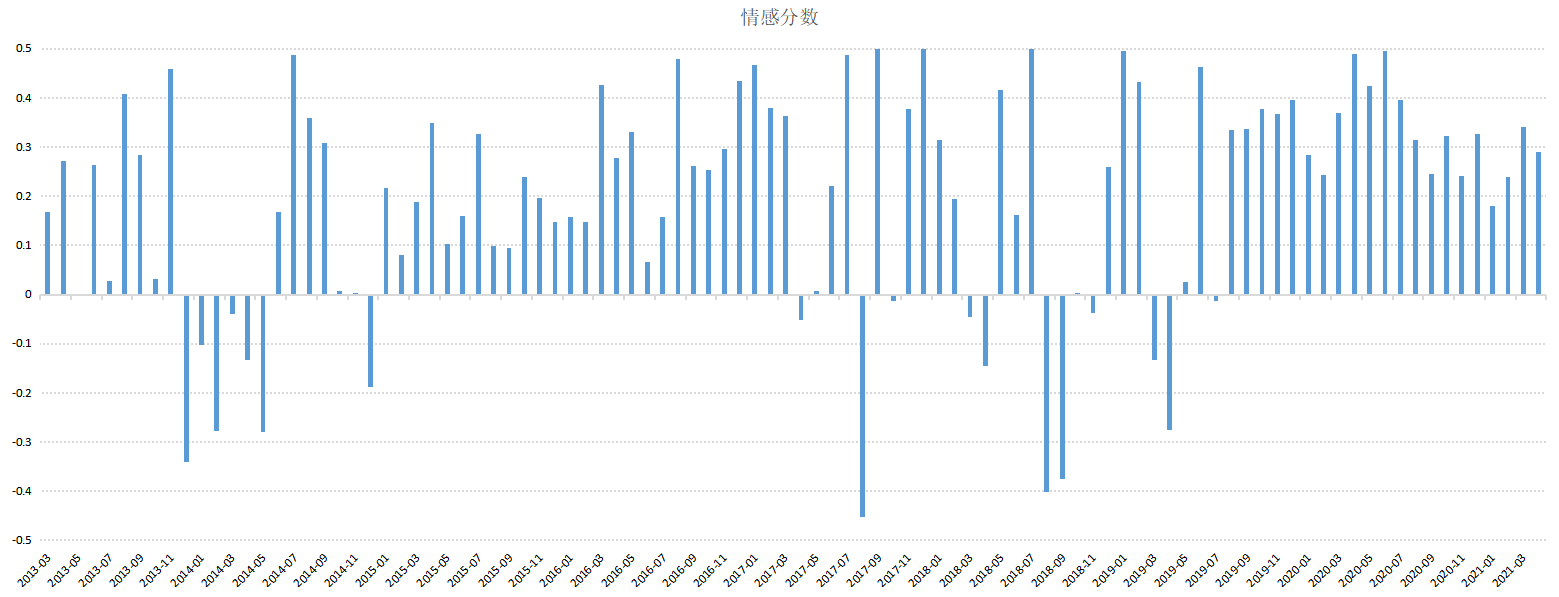
但是如果我们计算每天或每月新闻的总体情感分数,就会达到时间序列的情感分析图,从而更好地对情感趋势进行预测,文本挖掘或图书情报领域中使用得也非常多。
# -*- coding: utf-8 -*-
from snownlp import SnowNLP
import codecs
import os
#获取情感分数
source = open("06-data-fenci.txt", "r", encoding='gbk')
fw = open("09-result.txt", "w", encoding="gbk")
line = source.readlines()
sentimentslist = []
for i in line:
s = SnowNLP(i)
#print(s.sentiments)
sentimentslist.append(s.sentiments)
#区间转换为[-0.5, 0.5]
result = []
i = 0
while i<len(sentimentslist):
result.append(sentimentslist[i]-0.5)
fw.write(str(sentimentslist[i]-0.5)+"\n")
print(sentimentslist[i]-0.5, line[i].strip("\n"))
i = i + 1
fw.close()
#可视化画图
import matplotlib.pyplot as plt
import numpy as np
plt.plot(np.arange(0, 598, 1), result, 'k-')
plt.xlabel('Number')
plt.ylabel('Sentiment')
plt.title('Analysis of Sentiments')
plt.show()
8.博客主题演化分析
最后是主题化验研究,这里推荐大家阅读南大核心相关的论文。其实主题演化通常分为:
- 主题新生
- 主题消亡
- 主题融合
- 主题孤独
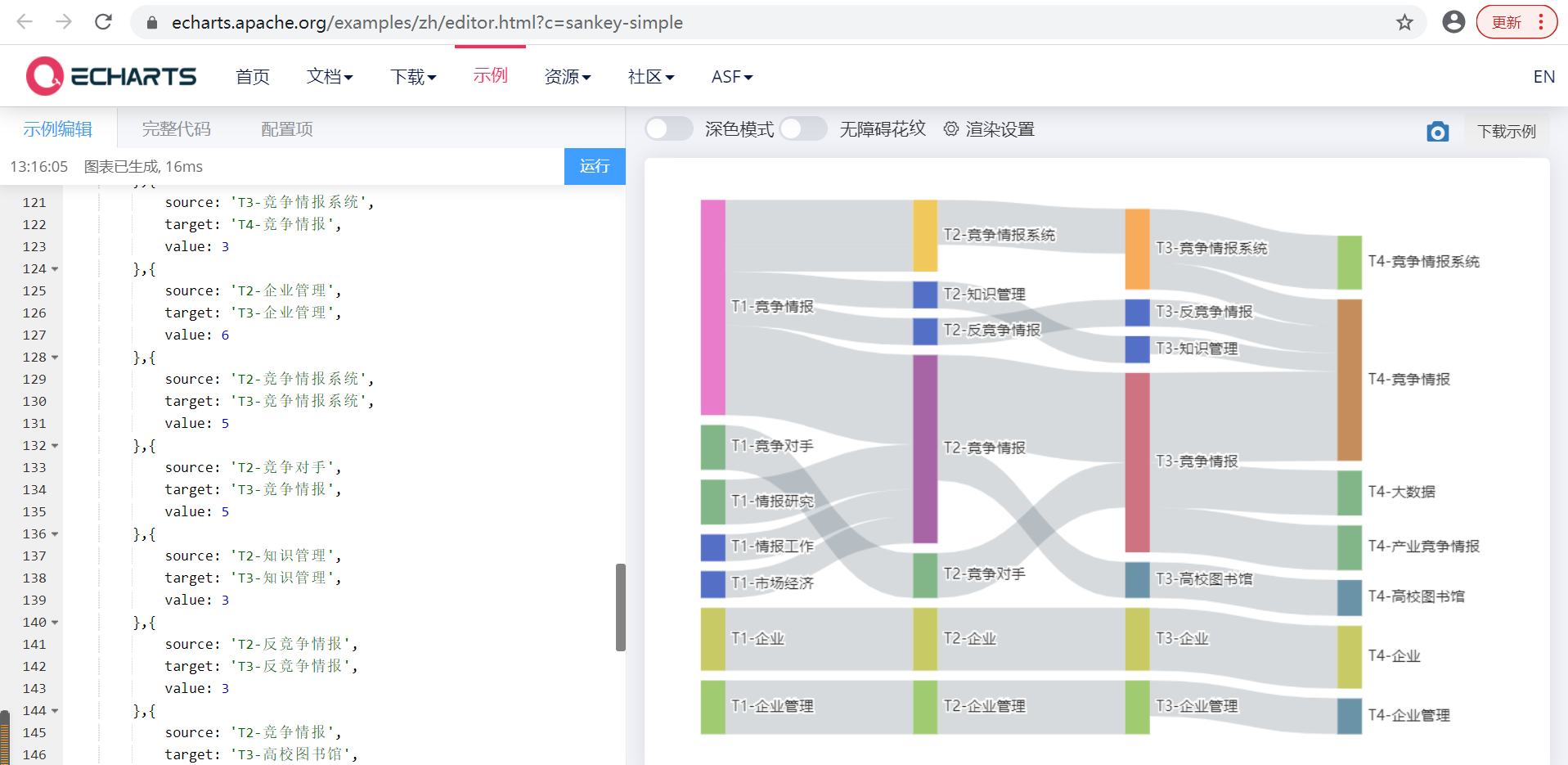
主题融合的计算方法各种各样,大家可以寻找最适合自己论文的方法,比如词频、权重、O系数、关联性分析等等。这里推荐大家使用Echarts绘制,作者的图谱如下图所示:
注意,作者这里给出的代码是另一个案例。但原理一样,仅供参考。真实情况的计算过程更为复杂,计算演化系数通常为小数。
option = {
series: {
type: 'sankey',
layout:'none',
focusNodeAdjacency: 'allEdges',
data: [
{
name: 'T1-竞争情报'
},{
name: 'T1-企业'
},{
name: 'T1-企业管理'
}, {
name: 'T1-情报研究'
},{
name: 'T1-竞争对手'
},{
name: 'T1-情报工作'
},{
name: 'T1-市场经济'
},{
name: 'T2-竞争情报'
},{
name: 'T2-企业'
},{
name: 'T2-企业管理'
},{
name: 'T2-竞争情报系统'
},{
name: 'T2-竞争对手'
},{
name: 'T2-知识管理'
},{
name: 'T2-反竞争情报'
},{
name: 'T3-竞争情报'
},{
name: 'T3-企业'
},{
name: 'T3-竞争情报系统'
},{
name: 'T3-企业管理'
},{
name: 'T3-高校图书馆'
},{
name: 'T3-反竞争情报'
},{
name: 'T3-知识管理'
},{
name: 'T4-竞争情报'
},{
name: 'T4-企业'
},{
name: 'T4-大数据'
},{
name: 'T4-产业竞争情报'
},{
name: 'T4-竞争情报系统'
},{
name: 'T4-高校图书馆'
},{
name: 'T4-企业管理'
}
],
links: [{
source: 'T1-竞争情报',
target: 'T2-竞争情报',
value: 10
}, {
source: 'T1-企业',
target: 'T2-企业',
value: 7
}, {
source: 'T1-企业管理',
target: 'T2-企业管理',
value: 6
},{
source: 'T1-情报研究',
target: 'T2-竞争情报',
value: 5
},{
source: 'T1-竞争对手',
target: 'T2-竞争对手',
value: 5
},{
source: 'T1-情报工作',
target: 'T2-竞争情报',
value: 3
},{
source: 'T1-市场经济',
target: 'T2-竞争情报',
value: 3
},{
source: 'T1-竞争情报',
target: 'T2-竞争情报系统',
value: 5
},{
source: 'T1-竞争情报',
target: 'T2-竞争情报系统',
value: 3
},{
source: 'T1-竞争情报',
target: 'T2-知识管理',
value: 3
},{
source: 'T1-竞争情报',
target: 'T2-反竞争情报',
value: 3
},
{
source: 'T2-竞争情报',
target: 'T3-竞争情报',
value: 10
},{
source: 'T2-企业',
target: 'T3-企业',
value: 7
},{
source: 'T3-竞争情报系统',
target: 'T4-竞争情报',
value: 3
},{
source: 'T2-企业管理',
target: 'T3-企业管理',
value: 6
},{
source: 'T2-竞争情报系统',
target: 'T3-竞争情报系统',
value: 5
},{
source: 'T2-竞争对手',
target: 'T3-竞争情报',
value: 5
},{
source: 'T2-知识管理',
target: 'T3-知识管理',
value: 3
},{
source: 'T2-反竞争情报',
target: 'T3-反竞争情报',
value: 3
},{
source: 'T2-竞争情报',
target: 'T3-高校图书馆',
value: 4
},
{
source: 'T3-竞争情报',
target: 'T4-竞争情报',
value: 10
},{
source: 'T3-企业',
target: 'T4-企业',
value: 7
},{
source: 'T3-竞争情报',
target: 'T4-大数据',
value: 5
},{
source: 'T3-竞争情报',
target: 'T4-产业竞争情报',
value: 5
},{
source: 'T3-竞争情报系统',
target: 'T4-竞争情报系统',
value: 6
},{
source: 'T3-企业管理',
target: 'T4-企业管理',
value: 4
},
{
source: 'T3-高校图书馆',
target: 'T4-高校图书馆',
value: 4
},{
source: 'T3-反竞争情报',
target: 'T4-竞争情报',
value: 3
},{
source: 'T3-知识管理',
target: 'T4-竞争情报',
value: 2
}
]
}
};
运行截图如下所示:
9.拓展知识
读者还可以进行各种各样的文本挖掘,比如:
- 命名实体识别
- 知识图谱构建
- 智能问答处理
- 舆情事件预测
- …
三.总结
最后用我的博客签名结束这篇文章,“无知·乐观·低调·谦逊·生活”,时刻告诉自己:无知的我需要乐观的去求知,低调的底色是谦逊,而谦逊是源于对生活的通透,我们不止有工作、学习、编程,还要学会享受生活,人生何必走得这么匆忙,做几件开心的事,写几篇系统的文,携一位心爱的人,就很好!感恩CSDN,感谢你我的坚守和分享,这又何止是十年。
感恩所有读者十年的陪伴,短暂消失只为更好的遇见。接下来三年,愿接纳真实的自己,不自卑,不自傲;愿踏踏实实努力、认认真真生活,爱我所爱,无怨无悔,江湖再见。欢迎大家留言喔,共勉~

(By:Eastmount 2021-04-28 晚上12点 http://blog.csdn.net/eastmount/ )
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/138730.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
