大家好,又见面了,我是你们的朋友全栈君。
摘要
数据分析与建模的时候大部分时间在数据准备上,包括对数据的加载、清理、转换以及重塑。pandas提供了一组高级的、灵活的、高效的核心函数,能够轻松的将数据规整化。这节主要对pandas合并数据集的merge函数进行详解。(用过SQL或其他关系型数据库的可能会对这个方法比较熟悉。)码字不易,喜欢请点赞!!!
1.merge函数的参数一览表
![[Python3]pandas.merge用法详解](https://img-blog.csdnimg.cn/20181202180501231.png)
![[Python3]pandas.merge用法详解](http://javaforall.cn/wp-content/themes/justnews/themer/assets/images/lazy.png)
![[Python3]pandas.merge用法详解](https://img-blog.csdnimg.cn/20181202180517553.png)
2.创建两个DataFrame

3.pd.merge()方法设置连接字段。
默认参数how是inner内连接,并且会按照相同的字段key进行合并,即等价于on=‘key’。
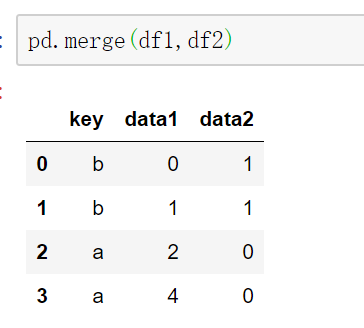
也可以显示的设置on=‘key’,这里也推荐这么做。
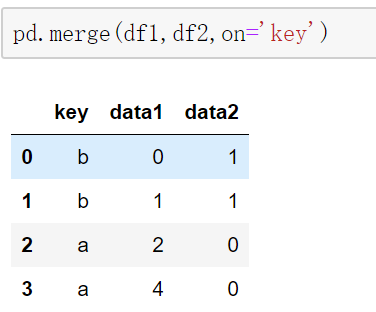
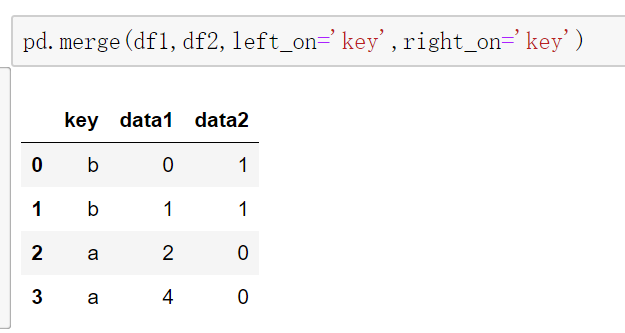
当两边合并字段不同时,可以使用left_on和right_on参数设置合并字段。当然这里合并字段都是key所以left_on和right_on参数值都是key。
4.pd.merge()方法设置连接方法。
主要包括inner(内连接)、outer(外链接)、left(左连接)、right(右连接)。
参数how默认值是inner内连接,上面的都是采用内连接,连接两边都有的值。
当采用outer外连接时,会取并集,并用NaN填充。
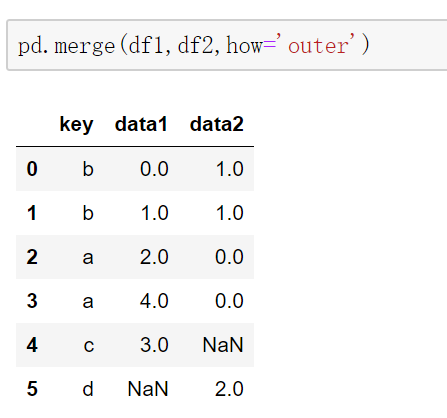
外连接其实左连接和右连接的并集。左连接是左侧DataFrame取全部数据,右侧DataFrame匹配左侧DataFrame。(右连接right和左连接类似)
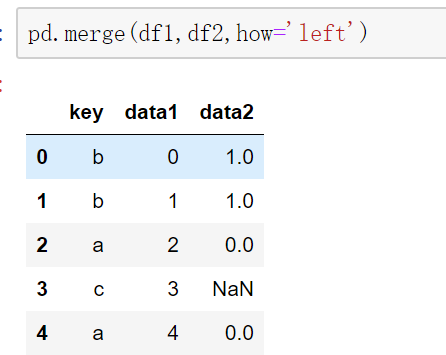
5.pd.merge()方法索引连接,以及重复列名命名。
pd.merge()方法可以通过设置left_index或者right_index的值为True来使用索引连接,例如这里df1使用data1当连接关键字,而df2使用索引当连接关键字。
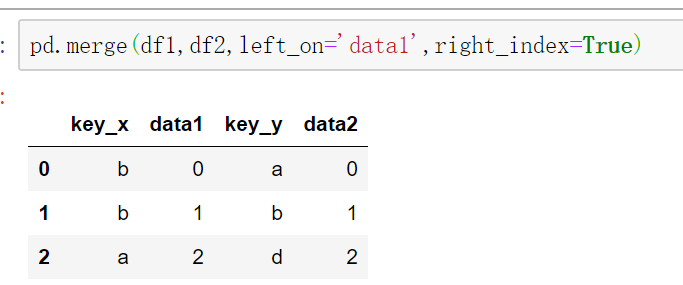
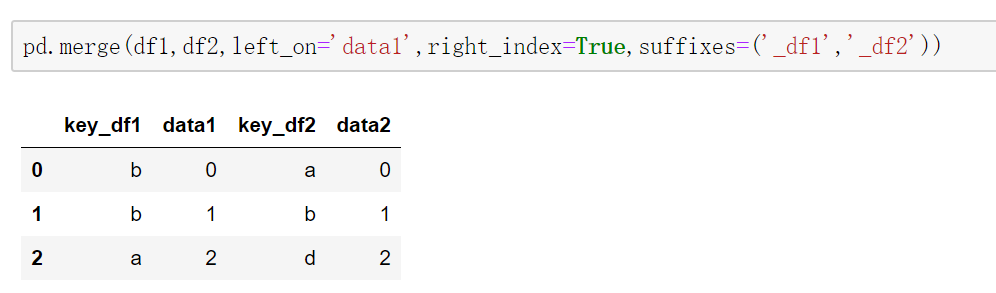
从上面可以发现两个DataFrame中都有key列,merge合并之后,pandas会自动在后面加上(_x,_y)来区分,我们也可以通过设置suffixes来设置名字。
姊妹篇:pandas.concat用法详解!!!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/138653.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
