大家好,又见面了,我是你们的朋友全栈君。
CTR 系列文章:
- 广告点击率(CTR)预测经典模型 GBDT + LR 理解与实践(附数据 + 代码)
- CTR经典模型串讲:FM / FFM / 双线性 FFM 相关推导与理解
- CTR深度学习模型之 DeepFM 模型解读
- 【CTR模型】TensorFlow2.0 的 DeepFM 实现与实战(附代码+数据)
- CTR 模型之 Deep & Cross (DCN) 与 xDeepFM 解读
- 【CTR模型】TensorFlow2.0 的 DCN(Deep & Cross Network) 实现与实战(附代码+数据)
- 【CTR模型】TensorFlow2.0 的 xDeepFM 实现与实战(附代码+数据)
FM
在计算广告领域,因子分解机(Factorization Machines,FM)是很经典的模型,面对量大且稀疏的数据,此算法仍然可以取得比较优秀的效果。
假设有下面的数据:
| Clicked? | Country | Day | Ad_type |
|---|---|---|---|
| 1 | USA | 26/11/15 | Movie |
| 0 | China | 1/7/14 | Game |
| 1 | China | 19/2/15 | Game |
其中,Clicked? 是label,Country、Day、Ad_type是特征。由于三种特征都是类别型的,需要经过独热编码(One-Hot Encoding)转换成数值型特征:
| Clicked? | Country=USA | Country=China | Day=26/11/15 | Day=1/7/14 | Day=19/2/15 | Ad_type=Movie | Ad_type=Game |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 |
经过编码之后,数据变的非常稀疏,在工业界这也是很难避免的一个问题。在这些稀疏的特征中,如果将其中一些特征加以关联,就可能得到与label管理更紧密的特征。例如对于 China 而言,19/2/15(即2015年2月19日)这天是春节,可能存在大量浏览和购买行为,广告点击率自然也会上升。
为了不错过任何有意义的特征组合,我们将所有特征两两组合起来形成新的特征,比较简单直接的实现方法是使用二阶多项式模式进行特征组合。例如将特征 x i , x j x_i,x_j xi,xj 的组合可以用 x i x j x_ix_j xixj 表示,当且仅当 x i , x j x_i,x_j xi,xj都为1时得到的组合特征才有意义。需要注意的是,原本的特征在onehot编码之后已经很稀疏了,再对特征进行两两组合,那么得到的特征就更稀疏了。
在得到特征之后,假设我们用线性模型进行预测,则预测值的表达式可能是这样的:
y ^ = w 0 + ∑ i = 1 n w i x i + ∑ i n ∑ j = i + 1 n w i j x i x j \hat{y}=w_0+\sum_{i=1}^n{w_ix_i}+\sum_i^n{\sum_{j=i+1}^n{w_{ij}x_ix_j}} y^=w0+i=1∑nwixi+i∑nj=i+1∑nwijxixj
式子中 n 代表特征数量, w 0 , w i , w i j w_0, w_{i}, w_{ij} w0,wi,wij 是模型的参数。其中组合特征参数 w i j w_{ij} wij 共有 n ( n − 1 ) 2 \frac{n(n-1)}{2} 2n(n−1)个,需要大量的非零组合特征 x i x j x_ix_j xixj才容易学习到合适的参数值。如何解决二次项参数 w i j w_{ij} wij的学习问题?
矩阵分解提供了一种解决方法,由于特征组合后的系数可以构成对称矩阵 W n × n W_{n \times n} Wn×n,因此可以对矩阵进行分解为 W n × n = V n × k V n × k T W_{n\times n}=V_{n\times k}V_{n\times k}^T Wn×n=Vn×kVn×kT,即 w i , j = < v i , v j > w_{i,j}=<v_i,v_j> wi,j=<vi,vj>,其中 k ≪ n k\ll n k≪n。于是,原本需要训练 n × n n \times n n×n 个特征,现在只需要训练 n × k n \times k n×k个:
y ^ = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n ∑ j = i + 1 n < v i , v j > x i x j < v i , v j > = ∑ f = 1 k v i f v j f \hat{y}=w_0+\sum_{i=1}^n{w_ix_i}+\sum_{i=1}^n{\sum_{j=i+1}^n{<v_i,v_j>x_ix_j}} \\ <v_i,v_j>=\sum_{f=1}^k{v_{if}v_{jf}} y^=w0+i=1∑nwixi+i=1∑nj=i+1∑n<vi,vj>xixj<vi,vj>=f=1∑kvifvjf
次数计算的时间复杂度为 O ( k n 2 ) O(kn^2) O(kn2) ,能不能进一步优化一下?注意到 ∑ i = 1 n ∑ j = i + 1 n < v i , v j > x i x j \sum_{i=1}^n{\sum_{j=i+1}^n{<v_i,v_j>x_ix_j}} ∑i=1n∑j=i+1n<vi,vj>xixj 实际上只是矩阵 W n × n W_{n \times n} Wn×n 中不包含对角线的上三角的部分,可以用 W n × n W_{n \times n} Wn×n 减去对角线元素后再除以2来得到:
∑ i = 1 n ∑ j = i + 1 n < v i , v j > x i x j = 1 2 ∑ i = 1 n ∑ j = 1 n < v i , v j > x i x j − 1 2 ∑ i = 1 n < v i , v i > x i x i = 1 2 ( ∑ i = 1 n ∑ j = 1 n ∑ f = 1 k v i f v j f x i x j − ∑ i = 1 n ∑ f = 1 k v i f v i f x i x i ) = 1 2 ( ∑ f = 1 k ∑ i = 1 n v i f x i ∑ j = 1 n v j f x j − ∑ i = 1 n ∑ f = 1 k v i f v i f x i x i ) = 1 2 ∑ f = 1 k ( ( ∑ i = 1 n v i f x i ) 2 − ∑ i = 1 n v i f 2 x i 2 ) \begin{aligned} & \sum_{i=1}^n{\sum_{j=i+1}^n{<v_i,v_j>x_ix_j}} \\ & = \frac{1}{2}\sum_{i=1}^n{\sum_{j=1}^n{<v_i,v_j>x_ix_j}}-\frac{1}{2}\sum_{i=1}^n{<v_i,v_i>x_ix_i}\\ & = \frac{1}{2}\left(\sum_{i=1}^n{\sum_{j=1}^n{\sum_{f=1}^k{v_{if}v_{jf}x_ix_j}}}-\sum_{i=1}^n{\sum_{f=1}^k{v_{if}v_{if}x_ix_i}}\right) \\ & = \frac{1}{2}\left(\sum_{f=1}^k{\sum_{i=1}^n{v_{if}x_i\sum_{j=1}^n{v_{jf}x_j}}}-\sum_{i=1}^n{\sum_{f=1}^k{v_{if}v_{if}x_ix_i}}\right) \\ &= \frac{1}{2}\sum_{f=1}^k\left(\left(\sum_{i=1}^n{v_{if}x_i}\right)^2-\sum_{i=1}^n{v_{if}^2x_i^2}\right) \end{aligned} i=1∑nj=i+1∑n<vi,vj>xixj=21i=1∑nj=1∑n<vi,vj>xixj−21i=1∑n<vi,vi>xixi=21⎝⎛i=1∑nj=1∑nf=1∑kvifvjfxixj−i=1∑nf=1∑kvifvifxixi⎠⎞=21⎝⎛f=1∑ki=1∑nvifxij=1∑nvjfxj−i=1∑nf=1∑kvifvifxixi⎠⎞=21f=1∑k⎝⎛(i=1∑nvifxi)2−i=1∑nvif2xi2⎠⎞
这样一来,是复杂度就降低为: O ( k n ) O(kn) O(kn)
引入二次项的FM模型,可以采用不同的损失函数用于解决回归、二元分类等问题,比如可以采用MSE(Mean Square Error)损失函数来求解回归问题,也可以采用Hinge/Cross-Entropy损失来求解分类问题。
(1)回归问题loss取最小平方误差
l o s s R ( y ^ , y ) = ( y ^ − y ) 2 loss^R(\hat y,y) = (\hat y – y)^2 lossR(y^,y)=(y^−y)2
所以:
∂ l o s s R ( y ^ , y ) ∂ θ = 2 ( y ^ − y ) ∂ y ^ ∂ θ \frac{\partial loss^R(\hat y,y)}{\partial \theta} = 2 (\hat y – y)\frac{\partial \hat y }{\partial\theta} ∂θ∂lossR(y^,y)=2(y^−y)∂θ∂y^
(2)二分类问题loss取logit函数
l o s s C ( y ^ , y ) = − ln σ ( y ^ y ) loss^C(\hat y ,y) = -\ln \sigma(\hat y y) lossC(y^,y)=−lnσ(y^y)
所以:
∂ l o s s C ( y ^ , y ) ∂ θ = [ ( σ ( y ^ y ) − 1 ] y ∂ y ^ ∂ θ \frac{\partial loss^C(\hat y,y)}{\partial \theta} = [(\sigma(\hat y y) – 1]y \frac{\partial \hat y }{\partial\theta} ∂θ∂lossC(y^,y)=[(σ(y^y)−1]y∂θ∂y^
其中:
∂ ∂ θ y ^ ( x ) = { 1 , if θ is w 0 x i , if θ is w i x i ∑ j = 1 n v j , f x j − v i , f x i 2 , if θ is v i , f \frac{\partial}{\partial\theta} \hat y (\mathbf{x}) = \left\{\begin{array}{ll} 1, & \text{if}\; \theta\; \text{is}\; w_0 \\ \ x_i, & \text{if}\; \theta\; \text{is}\; w_i \\ \ x_i \sum_{j=1}^n v_{j, f} x_j – v_{i, f} x_i^2, & \text{if}\; \theta\; \text{is}\; v_{i, f} \end{array}\right. ∂θ∂y^(x)=⎩⎨⎧1, xi, xi∑j=1nvj,fxj−vi,fxi2,ifθisw0ifθiswiifθisvi,f
为了避免过拟合,也引入正则化。所以,FM的最优化问题就变成了:
θ ∗ = arg min θ ∑ i = 1 N ( l o s s ( y ^ ( x i ) , y i ) + ∑ λ θ θ 2 ) \theta ^* = \mathop{\arg\min}_{\theta} \sum_{i=1}^N\left(loss(\hat y(x_i) ,y_i)+ \sum \lambda_\theta \theta^2\right) θ∗=argminθi=1∑N(loss(y^(xi),yi)+∑λθθ2)
注: λ θ \lambda_\theta λθ是正则化系数。
FFM
在FFM(Field-aware Factorization Machines )中每一维特征(feature)都归属于一个特定的field。对于进行onehot编码后的类别特征都属于同一个field。对于连续特征,一个特征就对应一个Field。例如:


当然也可以对连续特征离散化,一个分箱成为一个特征。例如:

不论是连续特征还是离散特征,它们都有一个共同点:同一个field下只有一个feature的值不是0,其他feature的值都是0。
FFM模型认为 v i v_i vi不仅跟 x i x_i xi有关系,还跟与 x i x_i xi相乘的 x j x_j xj所属的Field有关系。于是FFM模型的公式如下:
y ^ = ∑ i = 1 n ∑ j = i + 1 n v i , f j ⋅ v j , f i x i x j \hat{y}=\sum_{i=1}^n{\sum_{j=i+1}^n{v_{i,f_j}\cdot v_{j,f_i}x_ix_j}} y^=i=1∑nj=i+1∑nvi,fj⋅vj,fixixj
与FM的公式相比,它只保留了二次项。如何理解这种二次项系数的变化?可以通过下面的图片来理解 FM 与 FFM 在计算二次项系数时的区别:
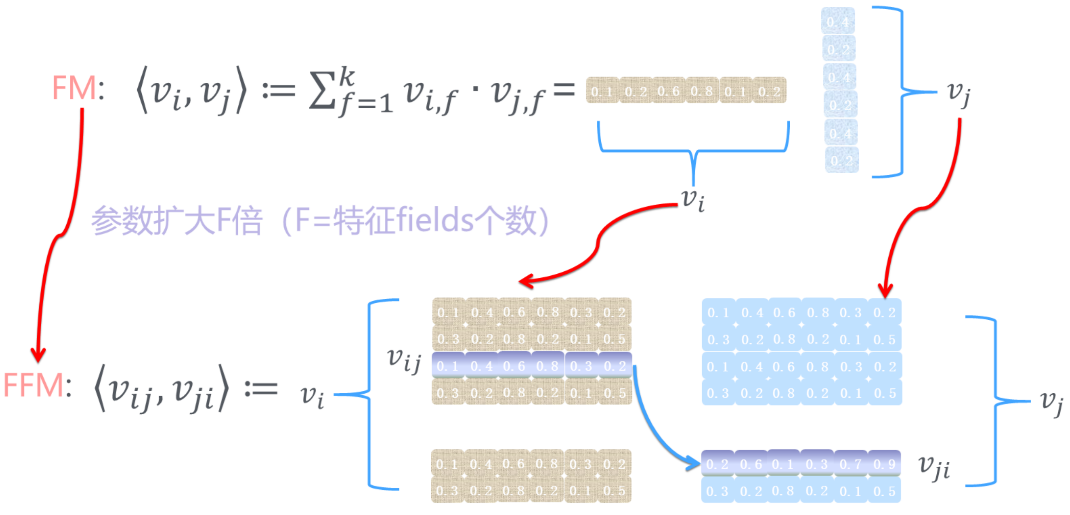
FM 在计算二次项系数的时候,任意两个特征的组合都需要两个一维的隐含向量(分别对应图中上半部分棕色一维向量 v i v_i vi 和蓝色的一维向量 v j v_j vj )的内积来表示。
而在FFM中,计算二次项系数的时候,把一维向量扩充了F倍(F表示所有特征对应了F个field,在本例中F取值为3,即field1年龄、field2城市,field3性别),构成“field隐含矩阵”,即图中下半部分棕色的矩阵 v i j v_{ij} vij 和蓝色的矩阵 v j i v_{ji} vji。当计算 x i , x j x_i, x_j xi,xj这个二次项的系数时,则需要:
1,从 v i j v_{ij} vij 中取出 x j x_j xj 特征对应的field所在的行向量 v i f j v_{if_j} vifj:

2,从 v j i v_{ji} vji 中取出 x i x_i xi 特征对应的field所在的行向量 v j f i v_{jf_i} vjfi:

然后将取出的向量计算内积作为 x i x j x_ix_j xixj系数。
总的来说,这个过程可以描述为:每个特征对应了一组隐向量,当 x i x_i xi 与 x j x_j xj 特征进行组合时, x i x_i xi会从 x i x_i xi那组隐向量中选择出与特征 x j x_j xj的域 f j f_{j} fj对应的隐向量 v i , f j v_{i, f_{j}} vi,fj 进行交叉。同理, x j x_j xj 也会选择与 x i x_i xi 的域 f i f_i fi 对应的隐向量 v j , f i v_{j, f_i} vj,fi 进行交叉。
如果隐向量的长度为 k,那么FFM的二次参数有 n F k nFk nFk 个,远多于FM模型的 nk 个。此外,由于隐向量与field相关,FFM二次项并不能够化简,其预测复杂度是 O ( k n 2 ) O(k n^2) O(kn2)。
以上文的第一个表格数据为例:

计算用户1的 y ^ \hat y y^过程为:
y ^ = ∑ i = 1 n ∑ j = i + 1 n v i , f j ⋅ v j , f i x i x j = v 1 , f 2 ⋅ v 2 , f 1 x 1 x 2 + v 1 , f 2 ⋅ v 3 , f 1 x 1 x 3 + v 1 , f 2 ⋅ v 4 , f 1 x 1 x 4 + ⋯ \begin{aligned} \hat{y}&=\sum_{i=1}^n{\sum_{j=i+1}^n{v_{i,f_j}\cdot v_{j,f_i}x_ix_j}} \\ &=v_{1,f_2}\cdot v_{2,f_1}x_1x_2+v_{1,f_2}\cdot v_{3,f_1}x_1x_3+v_{1,f_2}\cdot v_{4,f_1}x_1x_4+\cdots \end{aligned} y^=i=1∑nj=i+1∑nvi,fj⋅vj,fixixj=v1,f2⋅v2,f1x1x2+v1,f2⋅v3,f1x1x3+v1,f2⋅v4,f1x1x4+⋯
于是 y ^ \hat y y^ 对 v 1 , f 2 v_{1,f2} v1,f2 的偏导为:
∂ y ^ ∂ v 1 , f 2 = v 2 , f 1 x 1 x 2 + v 3 , f 1 x 1 x 3 + v 4 , f 1 x 1 x 4 \frac{\partial{\hat{y}}}{\partial{v_{1,f_2}}}=v_{2,f1}x_1x_2+v_{3,f1}x_1x_3+v_{4,f1}x_1x_4 ∂v1,f2∂y^=v2,f1x1x2+v3,f1x1x3+v4,f1x1x4
注意 x 2 , x 3 , x 4 x_2,x_3,x_4 x2,x3,x4是同一个属性的one-hot表示,即 x 2 , x 3 , x 4 x_2,x_3,x_4 x2,x3,x4中只有一个为1,其他都为0。在本例中 x 3 = x 4 = 0 , x 2 = 1 x_3=x_4=0,x_2=1 x3=x4=0,x2=1,所以:
∂ y ^ ∂ v 1 , f 2 = v 2 , f 1 x 1 x 2 \frac{\partial{\hat{y}}}{\partial{v_{1,f_2}}}=v_{2,f_1}x_1x_2 ∂v1,f2∂y^=v2,f1x1x2
推广到一般情况:
∂ y ^ ∂ v i , f j = v j , f i x i x j \frac{\partial{\hat{y}}}{\partial{v_{i,f_j}}}=v_{j,f_i}x_ix_j ∂vi,fj∂y^=vj,fixixj
实际项目中 x 是非常高维的稀疏向量,求导时只关注那些非0项即可。另外,在执行点击率预测时,会在 y ^ \hat y y^ 外面再套上一层 sigmoid 函数。接下来,我们用 z 来表示 y ^ \hat y y^:
z = y ^ = ∑ i = 1 n ∑ j = i + 1 n v i , f j ⋅ v j , f i x i x j z=\hat y=\sum_{i=1}^n{\sum_{j=i+1}^n{v_{i,f_j}\cdot v_{j,f_i}x_ix_j}} z=y^=i=1∑nj=i+1∑nvi,fj⋅vj,fixixj
用 α 表示对点击率的预测值:
a = σ ( z ) = 1 1 + e − z = 1 1 + e − ϕ ( v , x ) a=\sigma(z)=\frac{1}{1+e^{-z}}=\frac{1}{1+e^{-\phi(v,x)}} a=σ(z)=1+e−z1=1+e−ϕ(v,x)1
二分类问题常用的交叉熵损失函数:
C = − [ y l n a + ( 1 − y ) l n ( 1 − a ) ] , a = σ ( z ) C = -[ylna+(1-y)ln(1-a)], a=\sigma(z) C=−[ylna+(1−y)ln(1−a)],a=σ(z)
其中,σ 为 sigmoid 函数,则有:
∂ C ∂ z = ∂ C ∂ a σ ′ ( z ) = − y a σ ′ ( z ) + 1 − y 1 − a σ ′ ( z ) = a − y a ( 1 − a ) σ ′ ( z ) = a − y \frac{\partial C}{\partial z}=\frac{\partial C}{\partial a}\sigma'(z)=-\frac{y}{a}\sigma'(z)+\frac{1-y}{1-a}\sigma'(z)=\frac{a-y}{a(1-a)}\sigma'(z)=a-y ∂z∂C=∂a∂Cσ′(z)=−ayσ′(z)+1−a1−yσ′(z)=a(1−a)a−yσ′(z)=a−y
进而可以得到:
∂ C ∂ z = a − y = { − 1 1 + e z i f y 是 正 样 本 1 1 + e − z i f y 是 负 样 本 \frac{\partial C}{\partial z}=a-y=\left\{\begin{matrix}-\frac{1}{1+e^z} & if\ y是正样本 \\ \frac{1}{1+e^{-z}} & if\ y是负样本\end{matrix}\right . ∂z∂C=a−y={
−1+ez11+e−z1if y是正样本if y是负样本
结合上面求出的 ∂ y ^ ∂ v i , f j \frac{\partial{\hat{y}}}{\partial{v_{i,f_j}}} ∂vi,fj∂y^ 和 ∂ C ∂ z \frac{\partial C}{\partial z} ∂z∂C,代入下面的公式即可求得梯度值:
∂ C ∂ v i , f j = ∂ C ∂ z ∂ z ∂ v i , f j \\ \frac{\partial C}{\partial{v_{i,f_j}}}=\frac{\partial C}{\partial z}\frac{\partial{z}}{\partial{v_{i,f_j}}} ∂vi,fj∂C=∂z∂C∂vi,fj∂z
然后就可以使用梯度下降算法对参数进行优化了。
双线性 FFM(Bilinear-FFM)
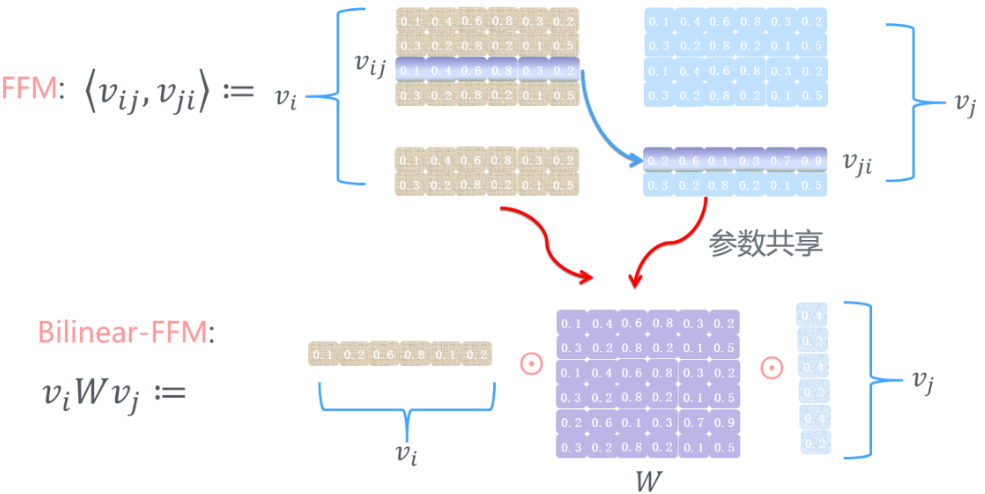
就像前面提到的,FFM 引入了更多的参数,在提升精度的同时也带来了巨大的计算量。国内的微博团队对FFM加以改进,得到了双线性 FFM(Bilinear-FFM)模型。
由于FFM每个特征都需要维护一个 n × F n \times F n×F 大小的矩阵,如果可以使部分特征共享参数,就能大幅度减少参数,这就是双线性 FFM 的核心思想。如下图所示:
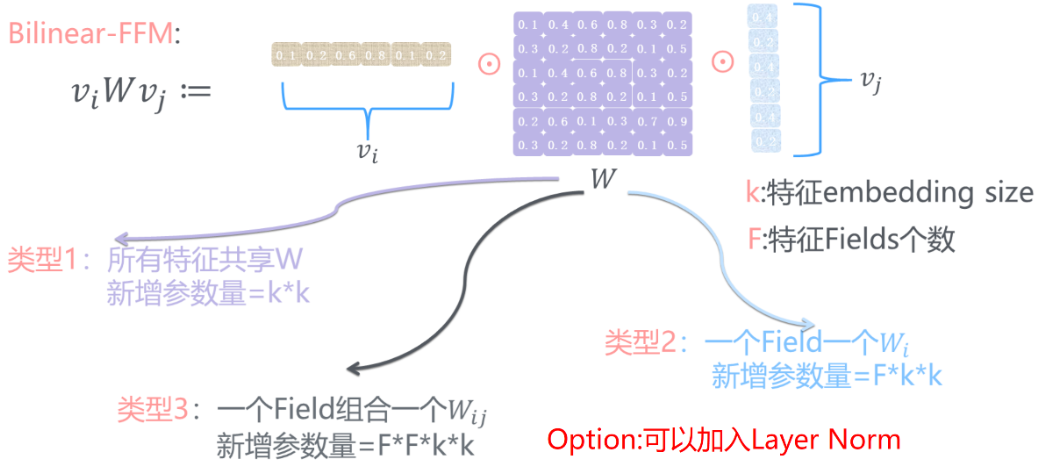
具体的参数共享方法又可以分为下面三种方式:
就结果而言,改进后的 Bi-FFM 与FFM精度差距不大:
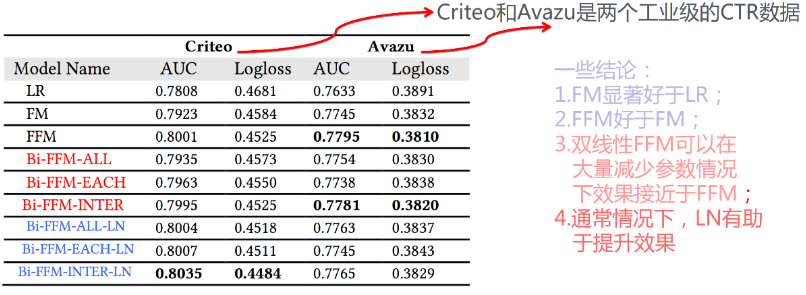
但是参数个数少了很多:

这意味着以更少的计算量得到近似于FFM的效果,优化还是很明显的。
参考文章:
分解机(Factorization Machines)推荐算法原理
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/138616.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
