大家好,又见面了,我是你们的朋友全栈君。
文章目录
各位读者朋友们大家好!我是爬虫领域的职业段子手。这篇文章今天在CSDN首发,后续我会持续维护更新。希望能帮助每一位读者减少掉坑的机率,也祝愿每位读者都能拿到心仪的offer!
由于时间原因还有很多实战资源题目及问题未能写完,后续会陆续更新上来
另外,大家有任何在面试中遇到的有趣的问题及疑问都可以骚扰我!或者在下方评论区留言,之后也都会添加到本文章中分享给读者去参考
这篇文章看完如果对你有所帮助的话,希望能给作者点个赞。感谢!
我为何写这篇文章
我为什么会写一篇这样的文章呢?我记得我以前刚开始面试的时候也会很好奇人家公司面试官会问一些什么样的问题?会出一些什么样的笔试题?而我个人的话又该准备哪些知识点呢?我也会在网上搜,一搜出来一大片,但是仔细翻阅发现大部分是一些比较基础的Python题目。每一个岗位面试的体验都是不一样的,所有公司的Feature也是不一样的,甚至是每一个面试官带给你的Freestyle也是不一样的!
这些问题都来自哪
以下所有涉及到的题目及问题大部分均来自第三方公司面经高频总结,其中包括不限于个人面经、朋友分享、热门话题。内容涉及创业公司到一线大厂均有!在这里为了保证第三方隐私性,就不按企业名称来划分问题了。但是我还是想跟大家说一句:
看完这篇文章,掌握其中要领,一定会让你受益匪浅
1. 笔试
笔试在很多互联网公司中都会出现,尤其是一些较大的公司中。大家都能看到身边很多的小伙伴都在讨论刷一些算法题,为了下一次面试努力刷题。这些笔试的题目都是由谁出的呢?我可以很明确的告诉大家,大部分都是相关的开发人员所出。他们会在网上搜一搜相关题材、然后自己再改一改。很多都没有经过长期的信效度考验,缺少难度控制,笔试题目我个人觉得根本没法真实考核出面试者的个人能力。何况还有漏题的风险
之所以会有笔试这个环节,真实目的就是能够快速把不合格的人和运气不够好的人快速过滤掉。从海量合格人选,注意!是合格人选中,相当粗糙但远优于随机地,挑选出一小批合格可能性非常非常高的p<0.01的面试集合,让面试官接触。这才是互联网企业的招聘核心成本:人力成本
你没有听错!运气!所有的面试中成功与否不光取决于你的能力还有你的运气
1.1 简答题
高频题(面试常问)|Python 的 yield 关键字有什么作用?
- 保存当前运行状态,然后暂停执行,即将函数挂起。yield关键字后面表达式的值作为返回值返回。当使用next()、send()函数从断点处继续执行
Python中【args】【kwargs】 是什么?
- 可变参数的处理
- args 打包成 tuple
- kwargs 被打包成 dict
Python的列表和元组有什么区别?
- 可变与不可变(列表是可变的而元组是不可变的)
- 速度(元组比列表更快)
并发与并行的区别?
- 并发不是并行,但看起来像是同时运行的,单个cpu和多道技术就可以实现并发。并行也属于并发,指的是同时运行,只有具备多个cpu才能实现并行
下面代码会输出什么?
list = ['1','2','3','4','5']
print(list[10:])
''' 这是一个坑!很e心的操作,代码将输出[],它并不会产生我们脑海中预期的IndexError错误'''
处理一个大小为8G的文件,但是内存只有4G!如何实现以及需要考虑的问题?
from mmap import mmap
def get_lines(f_p):
with open(f_p,"r+") as f:
m = mmap(f.fileno(), 0)
tmp = 0
for i, char in enumerate(m):
if char==b"\n":
yield m[tmp:i+1].decode()
tmp = i+1
if __name__=="__main__":
for i in get_lines("file/path"):
print(i)
内存只有4G无法一次性读入8G文件,需要分批读入数据且记录每次读入数据的位置。分批每次读取数据的大小,太小的话会在读取操作花费过多时间
请按value值进行排序: d= {‘a’:30,‘g’:50,‘i’:12,‘k’:23}
sorted(d.items(),key=lambda x:x[1])
介绍一下进程同步锁的概念
- 进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件或者打印终端是可以的。共享带来了竞争,竞争的结果就是混乱。解决办法就是加锁处理。加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,没错,速度是慢了,但牺牲了速度却保证了数据安全
python是如何进行内存管理的?
- python采用的是基于值的内存管理方式,如果为不同变量赋值相同值,则在内存中只有一份该值,多个变量指向同一块内存地址
高频题(面试常问)|Python中的深拷贝和浅拷贝有什么区别?
- copy.copy(浅拷贝) 只拷贝父对象,不会拷贝对象的内部的子对象
- copy.deepcopy( 深拷贝) 拷贝对象及其子对象
- 【不懂的读者可以自行在ipython中验证一下查看效果】
高频题(面试常问)|Python垃圾回收机制
- PyObject是每个对象必有的内容,其中ob_refcnt就是做为引用计数。当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除,它的ob_refcnt就会减少。引用计数为0时,该对象生命就结束了
- 优点:【简单、实时性】
- 缺点:【维护引用计数消耗资源、循环引用】
- 【标记-清除机制】基本思路是先按需分配,等到没有空闲内存的时候从寄存器和程序栈上的引用出发,遍历以对象为节点、以引用为边构成的图,把所有可以访问到的对象打上标记,然后清扫一遍内存空间,把所有没标记的对象释放
- 【分代技术】分代回收的整体思想是:将系统中的所有内存块根据其存活时间划分为不同的集合,每个集合就成为一个“代”,垃圾收集频率随着“代”的存活时间的增大而减小,存活时间通常利用经过几次垃圾回收来度量
Python支持多少种序列?
- Python是支持7种序列类型的分别是:str,list,tuple,unicode,byte array,xrange和buffer。其中xrange在python 3.5.X中已被弃用
当Python退出时,为什么不是所有的内存都被解除分配?
- 当python退出时,尤其是那些对其他对象具有循环引用的Python模块或者从全局名称空间引用的对象并不总是被解除分配或释放。由于python拥有自己的高效清理机制,无法解除分配保留的那些内存部分会在退出时尝试取消分配/销毁其他所有对象
Python2/3的差异点?
- print 成为函数
- 编码问题3不再有Unicode对象,默认str就是Unicode
- Python3除法返回浮点数
- 类型注解
def Test(name: str) -> str:
return 'Test' + name
- 优化的super()方便调用父类函数
- 高级解包操作: a, b, *res = range(10)
- 限定关键词参数
- Python3重新抛出异常不会丢失栈信息(raise from)
- 一切返回迭代器:range, zip, map, dict.values
- yield form 链接子生成器
- asyncio内置库,asyn/await 原生协程支持异步编程
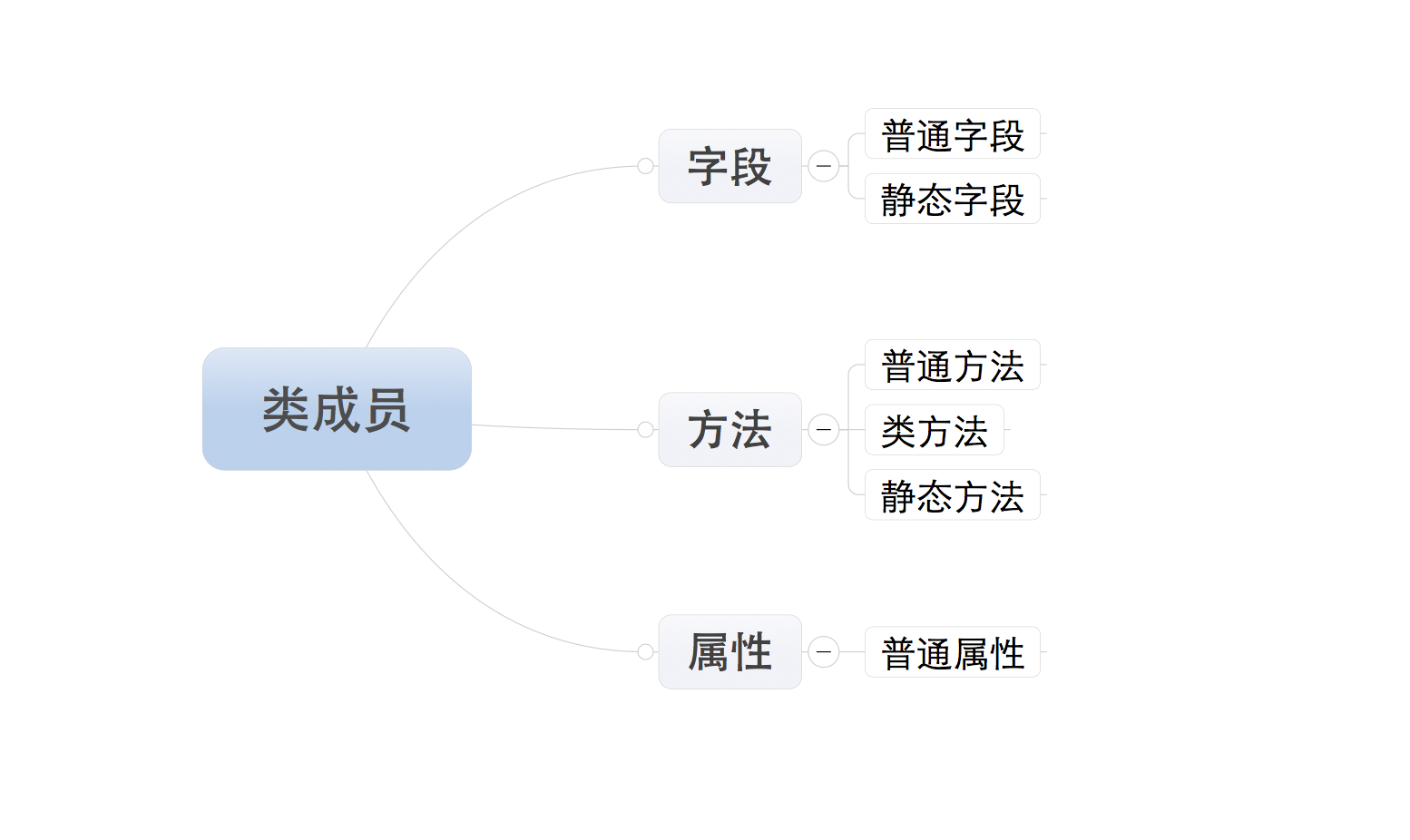
Python中静态方法、类方法、成员函数作用是什么?
- 静态方法是一种普通函数,就位于类定义的命名空间中,它不会对任何实例类型进行操作。使用装饰器@staticmethod定义静态方法。类对象和实例都可以调用静态方法
- 类方法是将类本身作为对象进行操作的方法。类方法使用@classmethod装饰器定义,其第一个参数是类,约定写为cls

生成器、迭代器的区别?
- 生成器能做到迭代器能做的所有事,而且因为自动创建了 iter()和 next()方法,生成器显得特别简洁,而且生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态的自动方法,当发生器终结时,还会自动抛出 StopIteration 异常
什么是匿名函数,匿名函数有什么局限性
- 就是lambda函数,通常用在函数体比较简单的函数上。匿名函数顾名思义就是函数没有名字,因此不用担心函数名冲突。不过Python对匿名函数的支持有限,只有一些简单的情况下可以使用匿名函数
高频题(面试常问)|函数装饰器有什么作用
- 装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。有了装饰器,就可以抽离出大量与函数功能本身无关的雷同代码并继续重用
高频题(面试常问)|什么是协程?
- 大家可以自行在网上搜索,属于一个高频题。
简述一下僵尸进程和孤儿进程?
- 孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作
- 僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程
SQL基础题|in与not in,exists与not exists的区别?
- exist会针对子查询的表使用索引
- not exist会对主子查询都会使用索引
- in与子查询一起使用的时候,只针对主查询使用索引
- not in则不会使用任何索引
- 如果查询的两个表大小相当,那么用in和exists差别不大;如果两个表中一个较小一个较大,则子查询表大的用exists,子查询表小的用in,所以无论哪个表大,用not exists都比not in 要快
SQL基础题|drop、delete 与 truncate 三者的区别?
- delete 用来删除表的全部或者一部分数据行,执行delete 之后,用户需要提交 (commmit) 或者回滚(rollback) 来执行删除或者撤销删除, delete 命令会触发这个表上所有delete 触发器
- truncate 删除表中的所有数据,这个操作不能回滚,也不会触发这个表上的触发器,truncate 比 delete 更快,占用的空间更小
- drop 命令从数据库中删除表,所有的数据行,索引和权限也会被删除,所有的 DML 触发器也不会被触发,这个命令也不能回滚
- 因此,在不再需要一张表的时候,用 drop。在想删除部分数据行时候,用 delete。在保留表而删除所有数据的时候用 truncate
1.2 基础题
基础爬虫题|使用多线程生产者消费者模式完成网站爬虫
- 代码就不贴了,大家可以去了解一下。自己针对简单的网站写一个Demo,这个题目不光考察面试者的编码能力还有就是设计能力
- 作者在面试爬虫岗遇到过好像有两次吧
笔试高频题|使用python实现单例模式
#__new__方法实现
#实现方法比较多、大家可以自行看看其它实现方法
class SingleTon(object):
def __new__(cls,*args,**kwargs):
#判断该类是否有实例化对象
if not hasattr(cls,'_instance'):
cls._instance = object.__new__(cls,*args,**kwargs)
#将实例对象返回
return cls._instance
class HelloClass(SingleTon):
a = 1
A = HelloClass()
B = HelloClass()
print A.a,B.a
A.a=2
print A.a,B.a
print id(A),id(B)
实现一个简单的栈结构(stack)
class Stack(object):
def __init__(self):
self.value = []
def push(self,x):
self.value.append(x)
def pop(self):
self.value.pop()
stack = Stack()
stack.push(1)
stack.push(2)
stack.push(3)
print(stack.value)
stack.pop()
print(stack.value)
Python反向迭代一个序列如何操作?
- 假设是一个list,最快的方法使用reverse
Test_List = [1,2,3...]
Test_List.reverse()
for i in Test_List:
print i
- 假设不是list,需要手动重排
Test_List = (1,2,3...)
for i in range(len(Test_List)-1,-1,-1):
print Test_List[i]
合并以下两个列表并去重
A = ['a','b','c','d','e','f']
B = ['e','a','x','c','z']
def merge_list(*args):
l = set()
for i in args:
l = l.union(i)
print(l)
return l
merge_list(A,B)
以下两段代码输出一样吗?占用系统资源一样吗?为什么要用xrange代替range?
for i in range(1):
print(i)
for i in xrange(1):
print(i)
''' 结果一样,但是占用系统资源不一样,range与xrange均属于可迭代对象,通过循环迭代可以取出其中的值,但是xrange属于惰性可迭代对象,虽然不是迭代器,没有next方法,但是有迭代器一样的性质,不会一次性将数据加载到内存,而是通过延迟加载的方式生成数据,取一个生成一个,节省内存资源,与python3中的range相同 '''
正则表达式操作
'''其中2020-04-20和zhangsan为变量,使用正则表达式捕获这个url,要求尽量精准'''
import re
wiste_url = "csdnbot/detail/2020-04-20/zhangsan"
r = re.compile('^footbar/homework/(?P<date>[0-9]{4}-[0-9]{2}-[0-9]{2})/(?P<name>w+)$')
url = r.findall()
1.3 算法题
各位读者记得有事没事都可以多刷刷LeetCode上面的题或者看看剑指Offer。我身边的大佬跟我自己所遇到过的面试题基本上99%的公司算法题真的都在这两大神器上出现过,不看你不知道看了是真香啊!
栈在O(1)时间内求min
- 这道题有两个朋友碰到过,大家可以在网上围观一下这道经典的题目
二叉搜索树中第 K 小的元素
- 这道题目某大厂常考!大家可以自行网上搜索围观
按照题目指引给的输入和输出实现一个程序
- 一般就包括排序、树、图等相关题
链表算法
- 输出/删除 单链表倒数第 K 个节点
class Solution:
def removeNthFromEnd(self, head: ListNode, n: int) -> ListNode:
second = fist = head
for i in range(n): # 第一个指针先走 n 步
fist = fist.next
if fist == None: # 如果现在第一个指针已经到头了,那么第一个结点就是要删除的结点。
return second.next
while fist.next: # 然后同时走,直到第一个指针走到头
fist = fist.next
second = second.next
second.next = second.next.next # 删除相应的结点
return head
- 删除链表中节点,要求时间复杂度为O(1)
class Solution:
def deleteNode(self, node):
next_node=node.next
next_nextnode=next_node.next
node.val=next_node.val
node.next=next_nextnode
- 反转链表
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
pre=None
# 不断取出和向后移动头节点,并将头节点连接到新头节点后面
while head:
next_node=head.next
head.next=pre
pre=head
head=next_node
return pre
二叉树的层次遍历
class Node(object):
def __init__(self, data, left=None, right=None):
self.data = data
self.left = left
self.right = right
tree = Node(1, Node(3, Node(7, Node(0)), Node(6)), Node(2, Node(5), Node(4)))
def lookup(root):
stack = [root]
while stack:
current = stack.pop(0)
print current.data
if current.left:
stack.append(current.left)
if current.right:
stack.append(current.right)
def deep(root):
if not root:
return
print root.data
deep(root.left)
deep(root.right)
if __name__ == '__main__':
lookup(tree)
判断一棵二叉树是否为另一棵二叉树的子树
class Solution(object):
def isSubtree(self, s, t): #用于判断的主函数,递归得遍历s的每一个结点,并将其作为新的根节点,再与t进行比较
if not s:
return False
return self.isEqual(s,t) or self.isSubtree(s.left,t) or self.isSubtree(s.right,t)
#使用or相连,即其中只要有一个s的子树与t相同,则返回True
def isEqual(self,S,T): #以S为根节点,判断S和T是否相等
if not S and not T:
return True
if S and T:
if S.val!=T.val:
return False
return self.isEqual(S.left,T.left) and self.isEqual(S.right,T.right)
else:
return False
高频算法题|实现一个二分查找的函数
二分查找是一种在有序数组中查找某一特定元素的搜索算法。搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半
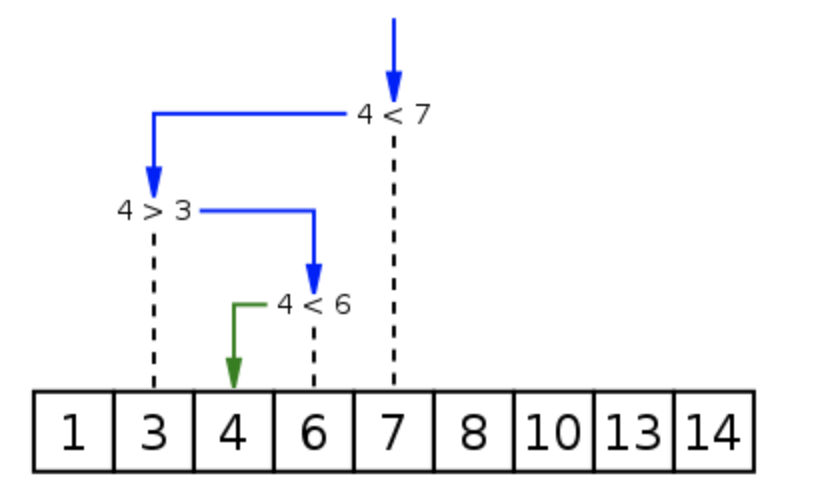
# 返回 x 在 arr 中的索引,如果不存在返回 -1
def binarySearch (arr, l, r, x):
# 基本判断
if r >= l:
mid = int(l + (r - l)/2)
# 元素整好的中间位置
if arr[mid] == x:
return mid
# 元素小于中间位置的元素,只需要再比较左边的元素
elif arr[mid] > x:
return binarySearch(arr, l, mid-1, x)
# 元素大于中间位置的元素,只需要再比较右边的元素
else:
return binarySearch(arr, mid+1, r, x)
else:
# 不存在
return -1
# 测试数组
arr = [ 2, 3, 4, 10, 40 ]
x = 10
# 函数调用
result = binarySearch(arr, 0, len(arr)-1, x)
if result != -1:
print ("元素在数组中的索引为 %d" % result )
else:
print ("元素不在数组中")
高频手撕|手写冒泡排序
冒泡排序是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素如果它们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到最后没有再需要交换也就是说该数列已经排序完成
# -*- coding:utf-8 -*-
import random
def bubbleSort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1] :
arr[j], arr[j+1] = arr[j+1], arr[j]
arr=[random.randint(1,100) for _ in range(10)]
print ("排序前:")
print(arr)
bubbleSort(arr)
print ("排序后:")
for i in range(len(arr)):
print ("%d" %arr[i])
高频手撕|手写选择排序
选择排序是一种简单直观的排序算法。它的工作原理是我们依次拿数组里的元素和它后面的元素进行比较大小,找到最小的元素并和该元素交换位置。然后继续拿第二、第三…第N个元素,这样小的数字最终就会排在前面
# -*- coding:utf-8 -*-
import random
def selectSort(lists):
lengh = len(lists)
for i in range(0, lengh-1):
key = i
for j in range(i+1, lengh):
if lists[key] > lists[j]:
lists[key], lists[j] = lists[j], lists[key]
alist = [random.randint(1,100) for _ in range(10)]
print("排序前:")
print(alist)
selectSort(alist)
print("排序后:")
print(alist)
高频手撕|手写快排
先从数据序列中选一个元素,并将序列中所有比该元素小的元素都放到它的右边或左边,再对左右两边分别用同样的方法处之直到每一个待处理的序列的长度为1,处理结束

def partition(arr,low,high):
i = ( low-1 )# 最小元素索引
pivot = arr[high]
for j in range(low , high):
# 当前元素小于或等于 pivot
if arr[j] <= pivot:
i = i+1
arr[i],arr[j] = arr[j],arr[i]
arr[i+1],arr[high] = arr[high],arr[i+1]
return ( i+1 )
def quickSort(arr,low,high):
if low < high:
pi = partition(arr,low,high)
quickSort(arr, low, pi-1)
quickSort(arr, pi+1, high)
alist = [random.randint(1,100) for _ in range(10)]
n = len(alist)
quickSort(alist,0,n-1)
print ("排序后的数组:")
for i in range(n):
print ("%d" %alist[i]),
高频手撕|使用Python实现一个斐波那契数列
nterms = 10
n1 = 0
n2 = 1
count = 2
while count < nterms:
nth = n1 + n2
print(nth,end=" , ")
# 更新值
n1 = n2
n2 = nth
count += 1
2. 面试技巧(必看)
这个环节主要通过包含电话、视频、面对面等交流的方式去考察应试者的技术能力、技术深度、表达能力、解决问题的能力等等。有时候看到很多同学说紧张。在这里我想告诉大家的是这个表现很正常,我们保持平常心就好。面试就是交流并没有多么恐怖!我第一次面试的时候也是慌得一皮。完全丝毫不夸张的说在面试官问的问题内我都知道,但是由于过度紧张甚至连说话都带着那么一丝丝颤音。这种表现最终是非常糟糕的可能会导致你错失offer
当你觉得自己充分的准备好了面试之后,你应该先找几个感觉对自己会有一定技术挑战的公司,但是并不是强制要求自己特别意向想要去的公司去投递简历面试一下,这个阶段一般会暴露出来很多问题。只要面试官的技术实力比你强,那么在面试的过程中,一定会问到你一些问题,是你之前没注意以及没准备好的。此时你很可能会发现,刚开始面试的头三四家公司,每家公司聊的都不太顺畅,每家公司总有那么几个问题没回答好,最后可能都没拿到offer。但是这个阶段的好处是,你在这个过程中发现了自己很多技术薄弱点,这个时候应该尽快通过上网查资料的方式填补好自己对一些薄弱问题的弱项,迅速总结、消化。
经过了之前多次被虐以后,个人的面试能力慢慢变强起来,而且你会发现自己找到了一些面试的感觉,总结过自己的一套经验,对面试的节奏、交流都有了很好的把控。这个时候就可以尝试去冲刺一下心仪的大厂了,在这个阶段里,需要全力以赴

来吧! 不断总结、不断归纳!让我们不断学习更多的知识、技术变得自信起来,让我们拥有跟面试官战一百个回合而不落下风的能力
2.1 网络相关(小问题大奥妙)
网络编程的问题基本每一场面试中较为正规的流程都会出现!
- 说说TCP 和 UDP 的区别?
- 什么是粘包? socket 中造成粘包的原因是什么? 哪些情况会发生粘包现象?
- 创建一个TCP服务器的流程?
- GET 和 POST 请求有什么区别?
- HTTP 和 HTTPS 的区别?
经典高频发问:
- 向浏览器发送一个请求到返回中间经历了什么?
- 说说三次握手和四次挥手
- HTTPS 是如何实现安全数据传输的?
2.2 数据库(经典高频)
数据库知识很重要!即使你投递的是开发不是DBA,一般的公司基本都会有关于数据库相关知识的面试问题,不是在笔试环节就是在后续跟面试官切磋的环节。你可以不了解数据库底层的基本原理,但是至少要知道索引原理、MySQL的数据引擎、你所经常使用的数据库优缺点等相关知识
了解数据库索引吗?描述一下它优缺点?
- 优点:
(1)大大加快数据的检索速度,这也是创建索引的最主要的原因
(2)加速表和表之间的连接
(3)在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间
(4)通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性 - 缺点
(1)时间方面:创建索引和维护索引要耗费时间,具体地对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度
(2)空间方面:索引需要占物理空间
MongoDB做爬虫的话应该经常使用吧?你能说说它的优缺点吗?
- 优点:性能优越、快速!它将热数据存储在物理内存中,使得热数据的读写变得十分快速。第三方支持丰富,自身的 Failover 机制!弱一致性(最终一致),更能保证用户的访问速度。支持多种编程语言。文档结构的存储方式,能够更便捷的获取数据— json 的存储格式。支持大容量的存储,内置 GridFS
- 缺点:主要是无事物机制!MongoDB 不支持事务操作(最主要的缺点)。MongoDB 占用空间过大!MongoDB 没有如 MySQL 那样成熟的维护工具,这对于开发和IT运营都是个值得注意的地方
Redis数据类型有哪些?
- string、hash、List、Set、Sorted Set
说说Redis的应用场景?
- 访问热点数据,减少响应时间,提升吞吐量
(1)会话缓存(最常用)
(2)消息队列,比如支付
(3)活动排行榜或计数
(4)发布,订阅消息(消息通知)
(5)商品列表,评论列表等
高并发场景下数据重复插入如何解决?
- 使用关系型数据库的唯一约束
- Redis 实现分布式锁
如果Redis中的某个列表中的数据量非常大,如何实现循环显示每一个值?
#写个生成器实现
def list_iter(key, count=3):
start = 0
while True:
result = conn.lrange(key, start, start+count-1)
start += count
if not result:
break
for item in result:
yield item
for val in list_iter('num_list'):
print(val)
简述Redis有哪几种持久化策略及比较?
RDB:每隔一段时间对Redis进行一次持久化
- 缺点:数据不完整
- 优点:速度快
AOF:把所有命令保存起来,如果想到重新生成到Redis,那么就要把命令重新执行一次
- 缺点:速度慢,文件比较大
- 优点:数据完整
缓存失效的解决办法?
- 可以搜索缓存重建,Redis高频题!
如何基于Redis实现消息队列?
- Redis并不适合用来做消息队列,业务上避免过度复用一个Redis。选择用它做缓存、做计算比较香。消息队列kafka、MQ它们不香吗?但是代码还是要贴出来的
# 发布者:
import redis
conn = redis.Redis(host='192.168.33.16', port=6379)
conn.publish('a', "点赞关注不迷路!")
# 订阅者:
import redis
conn = redis.Redis(host='192.168.33.16', port=6379)
pub = conn.pubsub()
pub.subscribe('a')
while True:
msg= pub.parse_response()
print(msg)
基于redis如何实现商城商品数量计数器?
- 做过电商系统跟抢票系统的同学对库存这块经验想必是很丰富的
import redis
conn = redis.Redis(host='192.168.33.16', port=6379)
conn.set('count',10000)
with conn.pipeline(transaction=True) as pipe:
# 先监视,自己的值没有被修改过
conn.watch('count')
# 事务开始
pipe.multi()
old_count = conn.get('count')
count = int(old_count)
if count > 0: # 有库存
#库存递减
pipe.set('count', count - 1)
# 执行,把所有命令一次性推送过去
pipe.execute()
MySQL常见数据库引擎及比较
InnoDB
支持事务
支持外键
支持表锁、行锁(for update)
表锁:select * from tb for update
行锁:select id,name from tb where id=2 for update
myisam
查询速度快
全文索引
支持表锁
表锁:select * from tb for update
2.3 反爬虫(高能硬核)
爬虫这个领域的反爬虫问题就比较多了,而且很深。但是!任何网站的任何反爬虫机制所保护的数据最终都是要需要呈现给用户去欣赏的,我们反推复现一下它是怎么显示到页面的就能找到解决思路,数据它无非会出现在JS内或者HTML内又或者是JSON文件内的其中之一!只不过中间实现的过程增加了不同的反爬Feature这个是需要爬虫工程师去分析的
-
你可以先看看我之前写的这篇文章一入爬虫深似海,反爬技术你知多少?
-
常见的反爬措施及解决方法?
IP封禁、验证码、US检测、蜜罐数据、JS加密、签名验证、Cookie反爬...
- 网站请求参数加密如何处理?
反向分析JS加载,首先使用搜索大法,找到关键参数加密部分的JS代码,再用断点调试大法最后重写解密。如果发现搜索大法跟断点都无法命中入口的话,很有可能JS部分加密部分的关键代码被删除可以重写HOOK函数配合断点调试拦截加密参数
- 爬虫职业生涯中遇到过最棘手的反爬机制是什么?最后如何解决的?
哈哈!这个问题当初我也是随便说了那么一两个。主要是棘手的套路都差不多,比如ZF相关类型的网站,基本上就是针对IP下手。棘手吗?肯定很棘手!在之前的文章中我说过任何反爬机制都能破解跟绕过,它的实现只不过是时间的问题!但是网站做反爬虫需要做的并不是完全去阻止你的爬虫去爬取数据,而是限制爬虫的很多功能增加爬虫的时间成本、资金成本就够了。某网的反爬机制上午一个Feature,下午一个Feature。这样的谁能受得了吗?当你好不容易分析了一上午的Feature最终完美破解,准备将爬虫投入生产的时候发现新的Feature已经到来
-说说APP爬虫流程?如果抓包抓不到数据如何处理?
这个问题吧!正常的(容易的)网站它基本流程就是使用抓包工具。保证APP走代理以及证书被信任,然后打开目标app查看是否能抓到包。如果抓不到数据,这个原因就多了。SSLPinning证书问题、代码混淆加密、反抓包SDK…
APP抓取没有通用的方法,具体问题还需要具体分析,反抓包的话你可以反编译看看反抓包的实现。因为每种类型的APP的反抓包处理方式都会有差别。有一些APP加密的参数在不能逆向或者能力未达到的情况下也是可以使用自动化测试工具。实在不行的话试试web端或者小程序,功能都一样
点选验证码识别做过吗?成功率高的算法有多高?
- 点选验证码大家可以围观一下GitHub上开源的深度学习算法
- 爬虫往深度学习、神经网络发展的趋势已经不远了
- 随着智能文本抽取(基于符号密度、未来基于视觉提取还会远吗?)
JavaScript 逆向你一般怎么做的?
- 高级爬虫不了解逆向?那肯定不行!现在的招聘职位要求多少都带着点逆向的知识,包括面试也是。JS加密作为爬虫一个绕不过的关卡
- 通过断点调试,虽然可行!但是你会发现,想一步一步深入地搞清楚这整个程序的逻辑,是十分困难的,因为大部分函数之间都是相互调用的关系。可以直接从系统函数入手调试
- 搜索大法、常规断点Debug大法、XHR Debug、行为Debug、各种钩子函数的使用、堆栈Debug
JS逆向主要涉及:JS 基本语法、浏览器渲染知识、代码混淆原理、加密算法理论、开发者工具的使用、代码逆向思路、Hook 和对应的脚本
2.4 爬虫相关(爬虫必会)
你爬过某某站和某某站,期间有没有遇到什么困难,你是如何完成的?
- 该问题一般出现在简历项目内,根据实际情况回答即可
Scrapy框架运行机制?
- 这个大家可以自行在网上搜索,资源太多。
如何提升scrapy的爬取效率?
- 增加并发、降低日志级别、禁止cookie、禁止重试、减少下载超时
- 五大功法,具体配置跟操作大家可以看看官方文档
scrapy及scrapy-redis区别?
- 可以看我之前写的这篇文章以最简单的方式讲Scrapy-redis分布式策略
scrapy及scrapy-redis去重原理?
- 可以看我之前写的这篇文章以最简单的方式讲Scrapy-redis分布式策略
scrapy如何自定义DownloaderMiddleware
需要编写一个下载器中间件类。继承scrapy.downloadermiddlewares.DownloaderMiddleware。然后重写process_request方法,就可以定义一个Downloader Middleware
Reuqest在被Scrapy引擎调度给Downloader之前,process_request方法在这个时候会被调用
简单介绍下 scrapy 的异步处理
- scrapy 框架的异步机制是基于 twisted 异步网络框架处理的,在 settings.py 文件里可以自行设置具体的并发量数值(默认是并发量 16)
写爬虫是用多进程好?还是多线程好? 为什么?
-
IO密集型情况使用多线程;
-
计算密集型情况下使用多进程;
-
IO 密集型代码(文件处理、网络爬虫等),多线程能够有效提升效率(单线程下有 IO 操作会进行 IO 等待,造成不必要的时间浪费,而开启多线程能在线程 A 等待时,自动切换到线程 B,可以不浪费 CPU 的资源,从而能提升程序执行效率)。在实际的数据采集过程中,既考虑网速和响应的问题,也需要考虑自身 机器的硬件情况,来设置多进程或多线程
如何监控一个爬虫的状态?
- 使用Python 的 STMP 包将爬虫的状态信息发送到指定的邮箱
- 虽然Python通过 smtplib 库使得发送email变得很简单,Scrapy仍然提供了自己的实现。 该功能十分易用,同时由于采用了 Twisted非阻塞式(non-blocking)IO ,其避免了对爬虫的非阻塞式IO的影响。 另外,其也提供了简单的API来发送附件。 通过一些 settings 设置,您可以很简单的进行配置
def __init__(self):
""" 监听信号量 """
super(YoutubeapiSpider, self).__init__()# 当收到spider_closed信号的时候,调用下面的close方法来发送通知邮件
dispatcher.connect(self.spider_closed, signals.spider_closed)
def spider_closed(self, spider, reason):
# 上方的信号量触发这个方法
stats_info = self.crawler.stats._stats # 爬虫结束时控制台信息
body = "爬虫[%s]已经关闭,原因是: %s.\n以下为运行信息:\n %s" % (spider.name, reason, stats_info)
subject = "[%s]爬虫关闭提醒" % spider.name
mailers.send(to={
"513720453@qq.com"},
subject=subject,
body=body)
''' 只要满足触发条件,就可以发送指定内容的邮件 '''
分布式爬虫主要解决哪些问题?
- ip、带宽、cpu、io
3. 项目问题(高能场景复现)
任何一个公司的面试,都一定会涉及到作为一个工程师最核心的价值——解决问题的能力,具体来说就是你做过的项目,这块是面试准备时的重中之重,应该作为最高优先级来对待。面试官反复的追问项目的各个地方的技术实现细节,就想看看有没有哪个地方是有一定的技术难度的,可以体现出这个候选人的一些项目上的亮点

在这个环节的话面试官大部分是左手拿着你的简历,右手揣兜,目光时不时望向你
本导演开始现场复现:来!灯光、灯光打过来。再过来些!好!action
面试官:我看你简历上写的这个项目,我很感兴趣,你能详细说一下吗?
你:开始你的表演(别跟我说你自己写得简历却不知从何说起…)面试官:你们这个项目中主要涉及了哪些技术/框架?
你:可以按照项目的基础架构、各个功能模块细分技术栈做一些描述面试官:在这个项目中你遇到过哪些技术难点和问题是如何解决的呢?
作者插嘴:这个问题不太好回答,能得到解决的问题也可以说不叫问题。就好比问你觉得哪家的撸串最好吃!如果你能一下子说出来,那么证明你就撸过那几家的!但是呢?如果你说没遇到过什么问题会显得你的经历不够多,说实在的回头想想看,感觉也没遇到过啥了不起的难题。
作者插嘴:一个优秀的面试官,看到你简历上的XX项目以及用到的技术的时候,他其实大概知道做这个项目会遇到些什么比较难的技术问题,然后直接问你是怎么解决的。
你:所以还是得如实根据自身的实际情况去回答吧!没有最优解!记得不要吹NB,不然一问破绽多了就很尴尬了!你也同样不能反问面试官说:那您觉得您撸过最好吃的串是哪一家呢?哈哈…你是魔鬼吗?
面试官:你在这个项目中承担的角跟主要负责?
你:根据个人实际情况展开回答面试官:你在这个项目中学到了什么?
你:可以说说项目中的令人眼前一亮的技术
在这个环节经常也会引出连环炮!面试官比如会常问:
为什么要用这个不用那个?
这个你了解吗?好的!你了解,那么你能说说它的原理吗?底层怎么实现的?
所以说重要的事情说三遍:基础!基础!基础!如果你能把连环炮抗下来基本证明你的基础能力是很强的,会用跟产生自己的想法跟理解是个分水岭
说到这里我跟大家说个有趣的事,之前有一次电话面试中一个面试官一上来叭叭问了我一堆分布式、反爬虫、爬虫框架相关的问题。我也叭叭回答了他一堆,他的回答基本就是:嗯,好之类的回应。问题问了很多但是都不做评价跟追问。最后说了一句让我彻底懵逼的话:那个我对爬虫也不是很了解。搞得我一脸的黑人问号脸!我在哪?我是谁?
4. Freestyle题
这个环节看这标题能感受到这个语义吗?Do you have a Freestyle?
Oh,Yeah。我为什么取名Freestyle?因为它来自面试官的即兴发挥!
有在项目中用过消息中间件吗,例如 Kafka、MQ 之类的
- 用过!好的。连环炮…
- 没用过?显得太LOW?
说说你擅长哪些方面?
- Freestyle就是Freestyle,问题都是这么的优雅。这个根据自身领域回答即可
你现在技术方面有哪些瓶颈或者觉得可以提升的地方?
- 可以根据自身实际情况述说
这道题为什么这么做,有什么好处?
- 此时此刻面试官正拿着你的笔试题
爬虫究竟是合法还是违法的?你如何看待?
- 爬虫技术本身不违法,关键是看你爬取到的数据用来做什么。所以事情违法,要看如何定性
5. 场景实战题
这个环节我碰到过两次!期间聊得很开心,最后说我这里有一个网站的反爬,你能看看怎么解决吗?其实这种情况很多人会觉得面试公司在套思路套方案之类的。嗯~说实话,世界之大无奇不有。这种公司存在吗?当前存在!但是我还是现场操练起来,一个JS加密比较简单反推一下通过断点找到了加密那块JS,作了一下解密基本就过了。还有一个是一个境外网站要求只能通过Request请求拿到数据,有一个鼠标监测反爬,每一次请求需要提交鼠标坐标参数,问题也不大
像一些后端开发的同学面一些大公司的时候会碰到一些现场设计系统的题。比如电商的秒杀系统、抢红包系统等等。爬虫面试的时候一样会涉及到让你现场设计一个分布式爬虫系统
如何监控网站更新情况?
- Distill Web Monitor等Chrome插件现在能实现这个需求
- 静态网页的话可以拿文件修改时间通过发送 If-Modified-Since请求来比对
- 动态网页的话通过将网页转化成MD5或哈希持久化比对
- 难点其实是主体内容有无更新,很多网站其实是主体内容没更新,但会随机来个列表更新之类的,保持它网页的更新性
通用爬虫可行吗?主要适用于哪些类型的网站?
- 可行!主要可以用于文章类型的网站数据爬取,比如新闻资讯类网站等。通过输入域名,提取字段等参数设置,然后程序会自动一层一层爬取该站点下的全部数据
看你简历做过舆情系统爬虫?如何保证系统数据的实时性?
-
一个优秀的舆情系统都是有实时采集功能的。像新闻、社交类网站,通常是按照最新发布的时间顺序向下展示数据的,较少有时间打乱的展示方式。所以每次对网站检索都可以查看到最新的发布信息。
-
那么对于舆情系统来说,在对社交媒体、新闻网站等进行舆情监控时,可设置定时采集功能。对目标网站进行最短1分钟每次的实时访问,即当第一次数据采集结束,1分钟后可再次访问该网站,获取到最新发布的信息。
6. 致谢
好了,到这里又到了跟大家说再见的时候了。感谢抽出宝贵时间阅读的各位小读者们。创作不易,如果感觉有点东西的话,帮忙点个赞再走吧。你的支持是我创作的动力,希望能带给大家更多优质的文章
如果你想跟作者有点故事,可以通过下方传送门找到我哟!里面有作者收藏的独家学习秘籍及优质大佬群。跟各领域优秀的顶级大佬在一起聊聊技术、学学投资理财…不说了~我要回家吃饭了~~记得来找我哟、风里雨里我会一直在这等你

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/138549.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
