大家好,又见面了,我是你们的朋友全栈君。
从鸟群觅食行为到粒子群算法

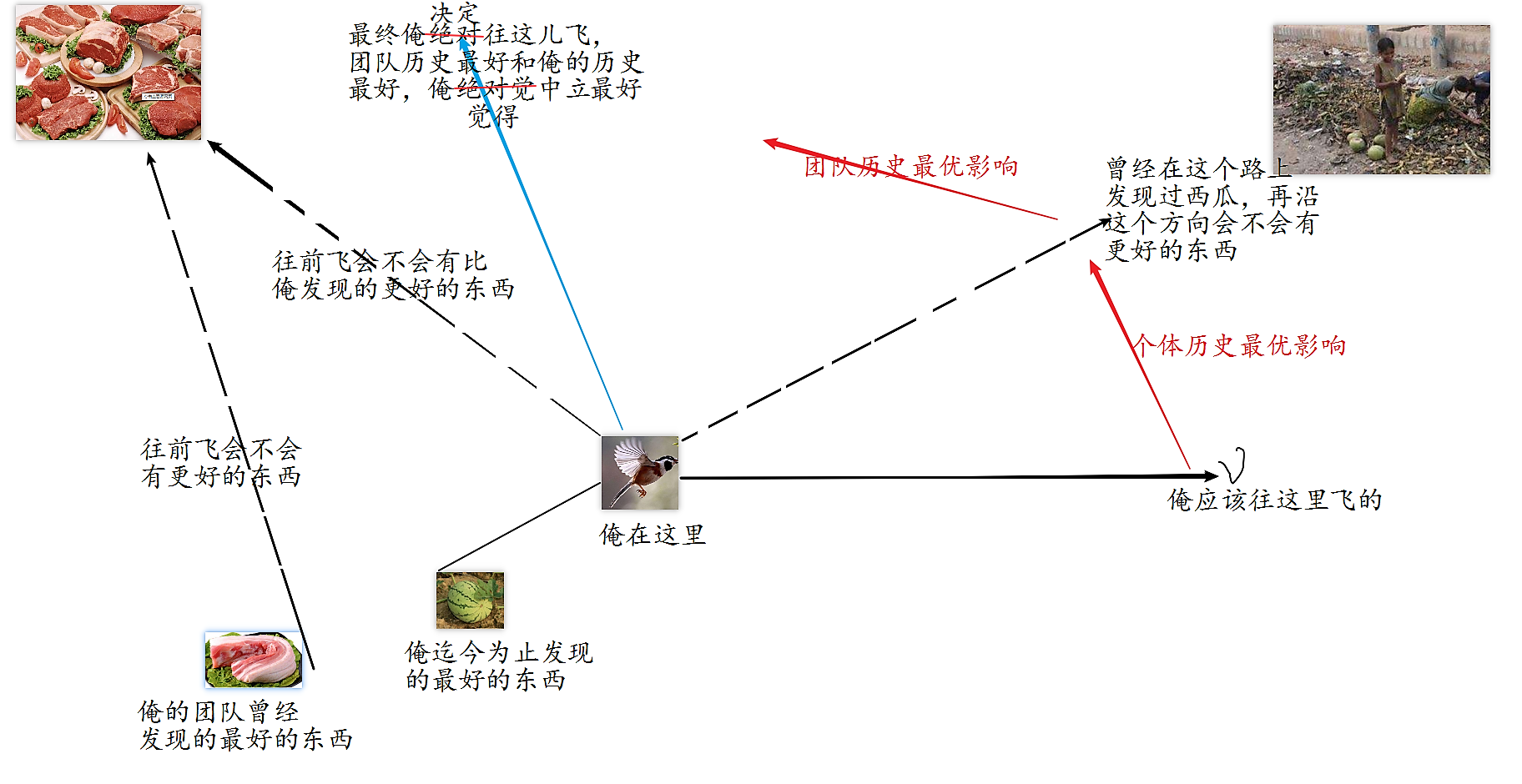
鸟群寻找食物的过程中,鸟与鸟之间存在着信息的交换,每只鸟搜索目前离食物最近的鸟的周围区域是找到食物的最简单有效的办法。
粒子群算法(以下简称PSO)就是模拟鸟群觅食行为的一种彷生算法 。 解=粒子=鸟 (鸟的位置象征着离食物的距离,粒子的位置也象征着离最优解的距离,是评价解质量的唯一标准), 找食物=找最优解,一个西瓜=一个粒子找到的历史最优解,一块肉=整个粒子群找到历史最优解 ,
就像鸟的飞行路线会受到自己曾经寻找到的最优食物和鸟群曾经找到过的最优食物的双重影响一样,算法中,每一次迭代,粒子通过两个”极值”(全局历史最优解gBest和个体历史最优解pBest)来更新自己的速度,该速度又是更新粒子位置的关键,而粒子的位置象征着离最优解的距离,也是评价该粒子(解)的唯一标准 。
粒子群算法的核心
该算法的核心是如何根据pBest与gBest来更新粒子的速度和位置,标准粒子群给出了如下的更新公式:
$ V_{t+1} =w \cdot V_t +c_1r_1\cdot(pBest-X_t) +c_2r_2\cdot(gBest-X_t) $
X t + 1 = X t + V t + 1 X_{t+1} = X_t+V_{t+1} Xt+1=Xt+Vt+1
$其中 , t:代数 , X是位置,V是速度,w是惯性权重,c是学习因子,r是随机数 $
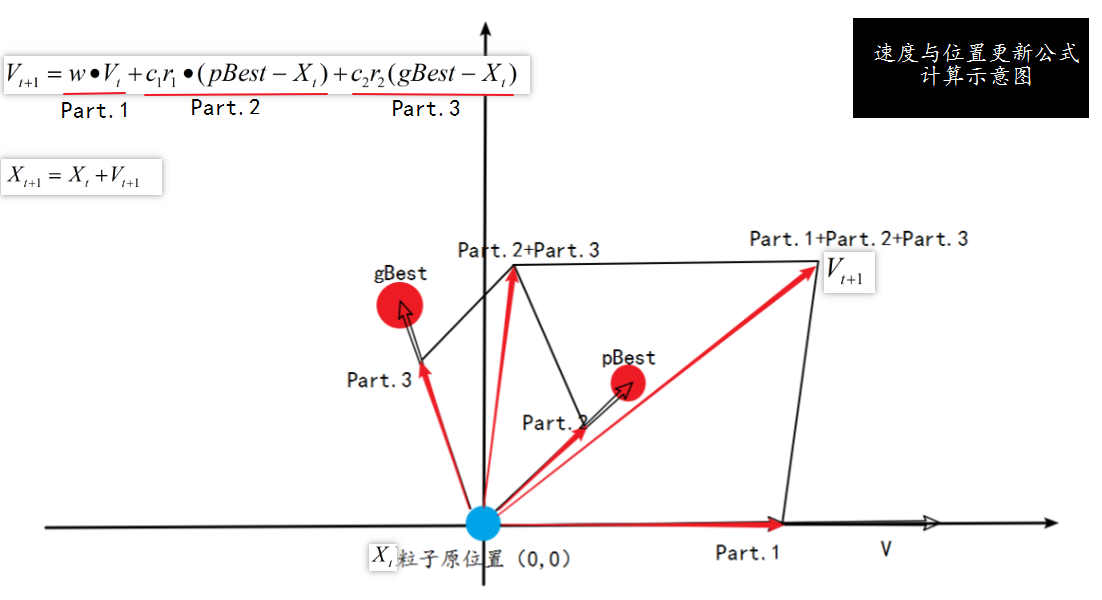
如上图所示,假设这是一个在2维平面内寻找最优解的待求解问题,某一时间的某一粒子 X t X_t Xt处在原点位置 。则该粒子更新后的速度如上图所示 。 更新公式可以分为三个部门:
- Part.1 : “惯性”或”动量”部分,反映粒子有维持自己先前速度的趋势
- Part.2 : “认知”部门 , 反映粒子有向自身历史最优位置逼近的趋势
- Part.3 : “社会”部门 , 反映粒子有向去群体历史最优位置逼近的趋势
例 : 求解函数最小值
求$f(x)=\sum_{i=1}{n}x_i2,(-20 \leq x\leq 20,n=10) $ 的最小值 ?
% author zhaoyuqiang
clear all ;
close all ;
clc ;
N = 100 ; % 种群规模
D = 10 ; % 粒子维度
T = 100 ; % 迭代次数
Xmax = 20 ;
Xmin = -20 ;
C1 = 1.5 ; % 学习因子1
C2 = 1.5 ; % 学习因子2
W = 0.8 ; % 惯性权重
Vmax = 10 ; % 最大飞行速度
Vmin = -10 ; % 最小飞行速度
popx = rand(N,D)*(Xmax-Xmin)+Xmin ; % 初始化粒子群的位置(粒子位置是一个D维向量)
popv = rand(N,D)*(Vmax-Vmin)+Vmin ; % 初始化粒子群的速度(粒子速度是一个D维度向量)
% 初始化每个历史最优粒子
pBest = popx ;
pBestValue = func_fitness(pBest) ;
%初始化全局历史最优粒子
[gBestValue,index] = max(func_fitness(popx)) ;
gBest = popx(index,:) ;
for t=1:T
for i=1:N
% 更新个体的位置和速度
popv(i,:) = W*popv(i,:)+C1*rand*(pBest(i,:)-popx(i,:))+C2*rand*(gBest-popx(i,:)) ;
popx(i,:) = popx(i,:)+popv(i,:) ;
% 边界处理,超过定义域范围就取该范围极值
index = find(popv(i,:)>Vmax | popv(i,:)<Vmin);
popv(i,index) = rand*(Vmax-Vmin)+Vmin ; %#ok<*FNDSB>
index = find(popx(i,:)>Xmax | popx(i,:)<Xmin);
popx(i,index) = rand*(Xmax-Xmin)+Xmin ;
% 更新粒子历史最优
if func_fitness(popx(i,:))>pBestValue(i)
pBest(i,:) = popx(i,:) ;
pBestValue(i) = func_fitness(popx(i,:));
end
if pBestValue(i) > gBestValue
gBest = pBest(i,:) ;
gBestValue = pBestValue(i) ;
end
end
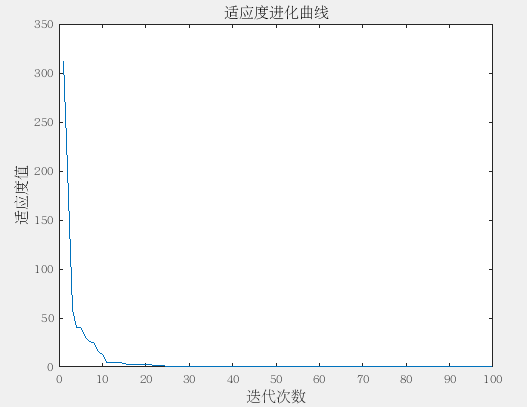
% 每代最优解对应的目标函数值
tBest(t) = func_objValue(gBest); %#ok<*SAGROW>
end
figure
plot(tBest);
xlabel('迭代次数') ;
ylabel('适应度值') ;
title('适应度进化曲线') ;
完整代码下载:https://download.csdn.net/download/g425680992/10502951
粒子群算法的驱动因素
粒子群算法是一种随机搜索算法 。粒子的下一个位置受到自身历史经验和全局历史经验的双重影响,全局历史经验时刻左右着粒子的更新,群体中一旦出现新的全局最优,则后面的粒子立马应用这个新的全局最优来更新自己,大大提高了效率,相比与一般的算法(如遗传算法的交叉),这个更新过程具有了潜在的指导,而并非盲目的随机 。
自身历史经验和全局历史经验的比例尤其重要,这能左右粒子的下一个位置的大体方向,所以,粒子群算法的改进也多种多样,尤其是针对参数和混合其他算法的改进 。
总体来说,粒子群算法是一种较大概率收敛于全局最优解的,适合在动态、多目标优化环境中寻优的一种高效率的群体智能算法。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/138504.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
