大家好,又见面了,我是你们的朋友全栈君。
1. HBase的特点是什么?
1)大:一个表可以有数十亿行,上百万列;
2)无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中
不同的行可以有截然不同的列;
3)面向列:面向列(族)的存储和权限控制,列(族)独立检索;
4)稀疏:空(null)列并不占用存储空间,表可以设计的非常稀疏;
5)数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入
时的时间戳;
6)数据类型单一:Hbase中的数据都是字符串,没有类型。
2. HBase和Hive的区别?
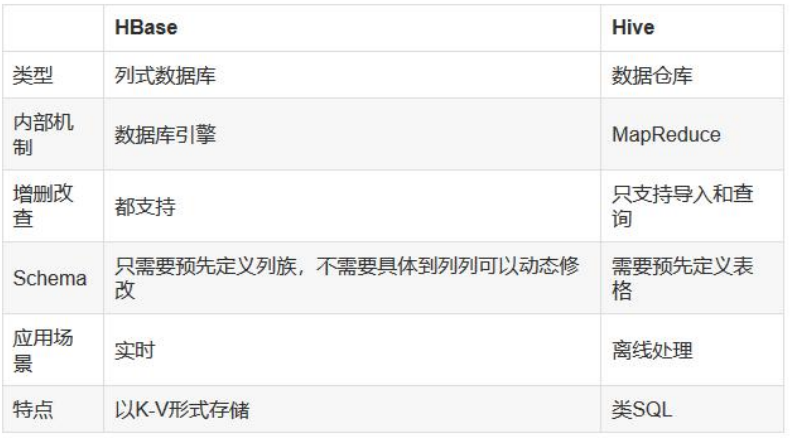

1)Hive和Hbase是两种基于Hadoop的不同技术--Hive是一种类SQL的引擎,并
且运行MapReduce任务,Hbase是一种在Hadoop之上的NoSQL 的Key/vale数据库。
2)这两种工具可以同时使用的。Hive可以用来进行统计查询,HBase可以用来
进行实时查询,数据也可以从Hive写到Hbase,设置再从Hbase写回Hive。
最后再结合自己的实际应用说出来.
3. HBase适用于怎样的情景?
1) 存储半结构化或者结构化的数据
对于数据结构字段不够确定或杂乱无章很难按一个概念去进行抽取的数据适合用
HBase,HBase支持动态增加字段,而RDBMS需要统计维护.
2) 记录稀疏的数据
HBase对于为null的数据不会被存储,节省了空间又提高了读性能。
3) 多版本数据
时间戳和版本号
4) 超大数据量
可以存储数十亿行,上百万列的数据
4.描述HBase的rowKey的设计原则?
-
Rowkey长度原则
Rowkey 是一个二进制码流,Rowkey 的长度被很多开发者建议说设计在10~100 个字节,不 过建议是越短越好,不要超过16 个字节。 -
Rowkey散列原则
避免regionserver热点问题,因为一个rowkey只能属于一个regionserver,所以设计rowkey之处应当遵循散列原则.(建表的时候可以采用预分区)
③ Rowkey唯一原则
5. 描述HBase中scan和get的功能以及实现的异同
HBase的查询实现只提供两种方式:
get功能:
- 局部扫描,根据rowkey获取唯一一条指定的记录
- scan是全部扫描,获取一批记录,)scan 可以通过setFilter 方法添加过滤器,这也是分页、多条件查询的基础; 还可以加 startkey endkey
6 请详细描述HBase中一个cell的结构?
HBase中通过row和columns确定的为一个存贮单元称为cell。
Cell:由{
rowkey, column(=<family> + <label>), version}唯一确定的单元。cell 中的数据是 没有类型的,全部是字节码形式存贮。
7. 简述HBase中compact用途是什么,什么时候触发,分为哪两 种,有什么区别,有哪些相关配置参数?
在hbase中每当有memstore数据flush到磁盘之后,就形成一个storefile,当
storeFile的数量达 到一定程度后,就需要将 storefile 文件来进compaction 操作。
Compact 的作用:
① 合并文件
② 清除过期,多余版本的数据
③ 提高读写数据的效率
HBase 中实现了两种 compaction 的方式:minor and major. 这两种 compaction 方式的
区别是:
1、Minor 操作只用来做部分文件的合并操作以及包括 minVersion=0 并且设置 ttl 的过期版
本清理,不做任何删除数据、多版本数据的清理工作。
2、Major 操作是对 Region 下的HStore下的所有StoreFile执行合并操作,最终的结果是整理
合并出一个文件。
8. 每天百亿数据存入HBase,如何保证数据的存储正确和在规 定的时间里全部录入完毕,不残留数据?
需求分析:
1)百亿数据:证明数据量非常大;
2)存入HBase:证明是跟HBase的写入数据有关;
3)保证数据的正确:要设计正确的数据结构保证正确性;
4)在规定时间内完成:对存入速度是有要求的。
解决思路:
1)数据量百亿条,什么概念呢?假设一整天60x60x24 = 86400秒都在写入数据,那么每秒的
写入条数高达100万条,HBase当然是支持不了每秒百万条数据的,所以这百亿条数据可能不是通
过实时地写入,而是批量地导入。批量导入推荐使用BulkLoad方式(推荐阅读:Spark之读写HBase),
性能是普通写入方式几倍以上;
2)存入HBase:普通写入是用JavaAPI put来实现,批量导入推荐使用BulkLoad;
3)保证数据的正确:这里需要考虑RowKey的设计、预建分区和列族设计等问题;
4)在规定时间内完成也就是存入速度不能过慢,并且当然是越快越好,使用BulkLoad。
9. HBase如何给web前端提供接口来访问?
使用JavaAPI来编写WEB应用,使用HBase提供的RESTFul接口。
10. 请列举几个HBase优化方法?
结合你们自己的项目说吧!!!
11. HBase中RowFilter和BloomFilter原理?
1)RowFilter原理简析
RowFilter顾名思义就是对rowkey进行过滤,那么rowkey的过滤无非就是相等(EQUAL)、
大于(GREATER)、小于(LESS),大于等(GREATER_OR_EQUAL),小于等于(LESS_OR_EQUAL)和
不等于(NOT_EQUAL)几种过滤方式。Hbase中的RowFilter采用比较符结合比较器的方式来进行过滤
比较器的类型如下:
BinaryComparator
BinaryPrefixComparator
NullComparator
BitComparator
RegexStringComparator
SubStringComparator
例如:
Filter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL,
new BinaryComparator(Bytes.toBytes(rowKeyValue)));
Scan scan = new Scan();
scan.setFilter(rowFilter)
...
2)BloomFilter原理简析
主要功能:提供随机读的性能
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/138352.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
