大家好,又见面了,我是你们的朋友全栈君。
英文版地址:ITDSD- 3. Overview of Distributed Engineering
Sun shuo(sun.shuo@aliyun.com)
导论
这是关于分布式架构新手入门的第三篇文章。这一篇文章主要简要的介绍分布式工程学在理论上的基本概念,历史和现状,以及未来发展方向。让大家能够了解为什么学习分布式工程学。分布式工程学在计算机科学中的地位,以及分布式工程学要解决的问题。您可以点击以下链接找到前面三篇文章。
- Distributed Method of Web Services
- Introduction to Distributed System Design – 1. Splitting in Microservice Architecture
- Introduction to Distributed System Design – 2. Practice of Splitting in Microservice Architecture
历史
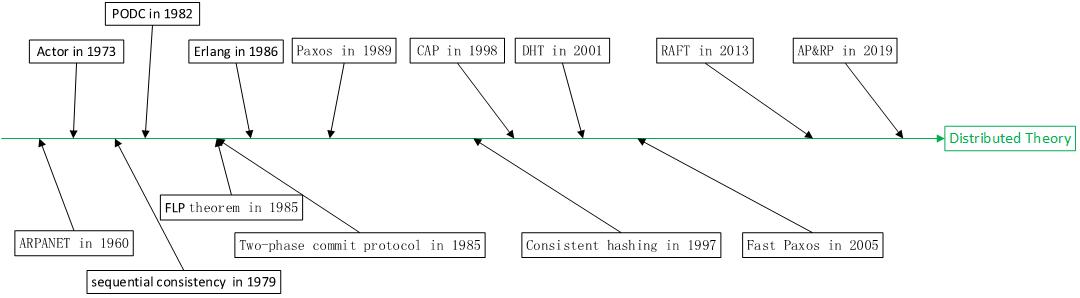
分布式工程学是一门实践性很强的工科学。所以会出现与其他工科一样的现象就是实践会先于理论。在1960年末被公认为是第一个分布式系统的ARPANET就诞生于美国[1]。在美国50年代到60年受曼哈顿计划的影响,计算机理论迎来了大爆炸的时代。在那个年代发明了我们今天所用到的大部分计算机理论。作为一个新兴学科,当年的科学家大都是刚刚毕业正是壮年。而今他们大多已经是高龄老人,有些科学家则已经离世。在这里向哪些为计算机理论作出贡献的科学家们表示敬意。
在1973年Carl Hewitt发明了演员模型[2]。这个模型试图在计算机网络内建立与现实相对应的虚拟对象并使它们之间建立关系。由计算机网络内的虚拟对象负责处理现实场景所产生的请求。演员模型对后来语言中的面向对象和面向对象数据库产生了深远的影响。是按产品功能划分计算机软件模块的重要理论依据。
在1979年Lamport提出了顺序一致性的理论[3]。一致性理论最初被用于系统设计。主要在硬件和计算机系统发挥作用。这期间科学家们试图找到一个方法,可以保持多个硬件中的数据一致性,所以诞生了各种各样的一致性理论。
在1982年Symposium on Principles of Distributed Computing (PODC)正式成立[4]。标志着分布式正式成为独立的研究方向。
在1985年Fischer, Lynch, Paterson 三位科学家发表了FLP定理[5]。证明使用异步通信不可能达成绝对共识。但随后在1988年,Lynch,Dwork和Stockmeyer发表了” Consensus in the Presence of Partial Synchrony”的论文[6]。这让人们对分布式系统是否可靠稳定产生了困惑。如果分布式系统是一个不稳定的系统,那么构建在其上的软件系统也就是一个不稳定系统。找到一个让分布式系统稳定的算法又成为新的问题。考虑当时正处于硬件爆炸发展的时代背景。硬件系统的不稳定确实让科学家们伤透了脑筋。
在1985年二阶段提交协议被Mohan, Bruce Lindsay发明[7]。这是已知最早的使用投票方式在分布式系统中保持一致性的协议。
在1986年,分布式工程学中重要的工业实践被启动,这就是erlang的语言诞生[8]。显然爱立信公司已经等不及科学家们争论出分布式系统是否稳定了。大量遍布全球的电话交换机业务急需一个庞大的分布式系统进行处理。其由Joe Armstrong, Robert Virding,和Mike Williams主导开发。Joe Armstrong在上个月也就是2019年4月20日去世,在此表达我的敬意。
在1989年Lamport又提出了饱受争议的Paxos协议[9]。以希腊Paxos岛上使用的虚构立法系统命名。因为论文更像一篇故事而被拒绝发表,直到1998年才正式发表。
在1997年Karger发表的论文中首次使用了一致性哈希的术语。虽然Teradata公司在1986年开发的分布式数据中已经使用了这个技术[10]。
在1998年Eric Brewer提出了CAP定理,来描述一致性和可用性与分区的关系[11]。他在文章[12]中试图将其描述为一种软件设计准则。但似乎并没有可操作方法来实施这个准则。
在2001年由Freenet,gnutella,BitTorrent和Napster 等P2P软件推动的DHT技术大量被使用[13]。其最初来源于Ian Clarke未在任何期刊发表的论文[14]。DHT技术是P2P和分布式内存数据库中有着重要的技术地位。
在2005年Lamport对其Paxos算法的改进版本Fast Paxos被发明。这是第一次将Paxos算法用作应用程序代码的版本。
在2013年,参考了Paxos算法实现的RAFT算法被发明[15]。之前2011年有着与RAFT算法类似的ZAB算法被公布。ZAB算法被用于ZooKeeper。ZooKeeper是用于在分布式系统中提供系统配置信息的节点。因为ZooKeeper在分布式系统中被大量应用。所以RAFT算法随着ZooKeeper的流行而流行开来。
在2019年我发明了AP&RP方法解决了多任务系统边界划分的问题。并于4月发表论文[16]。
分布式数据库的历史较为曲折,这里要单独介绍[17]。在1960年早期DBMS时期是一种基于硬盘的key-value类型的数据库。并且这种数据库很快衍生出了分布式架构。1970年关系型DBMS崛起后,数据库技术又发生从分布式架构向集中式架构的转变[18]。这期间和硬件的高速发展有着很深的关系。2000年后随着NOSQL运动的开始,数据库又开始向key-value类型的分布式系统发展。
在1999年的google公司。由Sanjay Ghemawat[19]和Jeff Dean[20]等工程师推动了一系列的分布式工程实践。包括MapReduce,Google File System,Bigtable等。直接推动了大数据,内存数据库,微服务等分布式技术的产业化。为分布式工程学的产业化做出了巨大贡献。

- 分布式要解决的问题
我们可以看到在分布式这个研究方向上有很多的问题。那个问题才是分布式这个学科最核心的问题呢?我认同在1993年Borowsky, Elizabeth; Gafni, Eli在其论文[21]中指出的“各种模型下可解与不可解分布式任务边界的划分是分布式计算理论的圣杯”的说法。
也就是说分布式工程学要解决的核心问题是:对任意软件系统给出能否分布,如何分布和分布结果?这个问题在本文之前是没有答案的。也就是说分布式在这之前只是一个研究方向。过去没有任何已知的方法来解决分布式工程学的核心问题。只有本文给出了解决核心问题的方法论,分布式才从研究方向变为学说。
要回答对任何软件系统能否分布,如何分布和分布结果。首先要对软件系统进行分类。我们将软件系统分为4类。它们分别是单任务&计算,多任务&计算,单任务&计算并有共享数据集,多任务&计算并有共享数据集。这个分类涉及到3个概念。首先任务就是离散数学中所表述的程序逻辑。是由一步或多步的计算过程组成。计算是指由计算单元完成程序逻辑的运行。共享数据集是指每次任务执行完成后所生成的数据,是否保留给下次执行时使用或其他任务共同使用。对于这4种情况我们分析如下。
1,单任务&计算。最容易理解,例如生成π的计算。这种算法能否分布式是数学意义上的概念。目前已知只有少量数学算法可以进一步细化为分布式。
2,多任务&计算。可以理解为多个数学算法的同时执行。也就是我们传统上互相隔离的计算机进程。这种完全隔离的计算机进程是可以分布式。例如两台硬件上的计算机系统就可以理解为广义的分布式系统。
3,单任务&计算并有数据集。这种情况比较常见于集成电路或控制器中。例如汽车的速度传感器收集速度数据,使用速度数据修改显示屏。这种情况是不能进一步细化为分布式。但从广义角度说这种情况和第2种情况相同。对于多个 “单任务&计算并有数据集”共同工作的场景也可以认为是一种广义的分布式系统。
4,对于最后一种情况“多任务&计算并有共享数据集”,也就是我们常说的异步网络下的软件系统。使用AP&RP方法可以明确地指出这种状态能否分布,如何分布以及分布结果。而演员模型也就是面向对象的模型或称为按产品功能划分的方法。不具备判断能否分布的能力,需要不断尝试不同的分割方案,并判断是否会导致数据冲突。直到找到一个错误较少的分割方案。也同样无法给出分布式的结果。同样一致性哈希表也不能给出任何答案。一致性哈希技术通常是使用最大冗余的方法试图覆盖所有可能的分割结果。
到此我们知道对于给定的任意软件系统第1,3类不能分布式或在少数特定情况下可以分布式。第2类天然就是分布式结构。而最后第4类可以通过AP&RP的方法解决分布式问题。到此我们给出了解决核心问题的方法论。
分布式系统中的稳定性
分布式系统的稳定性又常常被称为可用性。FLP定理首先指出了分布式系统是个非常不稳定的系统。这里包括著名的停机问题[22]也一直困扰着科学家。
通过进一步观察,其中又分为硬件和软件的问题,这里我们先从硬件的角度来说。硬件是否稳定是遵循着另外一个规律就是澡盆曲线[23]。每个硬件都会有着一个不稳定期到稳定期到老化期的过程。假设在一个分布式系统中有n个硬件组成。每个硬件的平均损坏概率为x则由基本的概率公式得知。集群中任意一台服务器发生损坏的概率为x1*x2*x3…*xn。于是我们得到了定理1。
定理1,分布式系统随着硬件的增加,整体的不稳定性在增加。
也就是说随着分布式集群的增加发生损坏的概率也就越高。而从另外的角度来看随着分布式集群的增加任意硬件损坏,导致集群整体受损的面积也再减少,也就是集群受损的面积减少为1/n。于是我们得到了定理2。
定理2,分布式系统随着硬件的增加损坏面积在减少。
所以不要再担心分布式集群稳定性了!以及为何不稳定性增加了。因为他们转化为了受损面积的减少。所以我们要做的是减少集群中的时序依赖,也就是不可替换的层级关系。避免任意单点的服务停止导致受损面积进一步的扩大。有趣的是这与企业的现代管理制度非常相似。于是我们得到了定理3。
定理3,层级关系及其不可替换性扩大了损害面积。
软件问题和硬件问题非常类似。软件为了提高代码的可重复使用率。在软件工程中引入了大量的层级关系。这种层级关系随着软件的分布式也被影射到了分布式系统中。同样硬件的分布式规则也适用于软件。于是我们可以得到分布式系统受到损坏的定理。
定理4:分布式中任意单点的层级关系,不可替换性和最终影响面积决定了损坏面积。
在分布式系统中为了减少任意单点损坏造成更大的破坏。我们要减少分布式系统中的层级关系和任意单点的不可替代性。但我们知道接收消息的系统服务是无法被替换的。否则会制造新的原子关系问题。即接收两个相同消息而产生的不同处理结果在系统内将无法调和。所以最小损坏面积与分布式系统中接收消息的最小服务单元相等同。
分布式系统中的一致性
FLP定理已经证明了分布式中不存在绝对的一致性。我认为这是基于能量守恒定理做出的简单推论。即信息的传播是有方向和能量消耗的。从任意源到任意目地的信息传播都是需要消耗能量并遵守能量守恒定律。因此信息传播的时间就不能为零。所以对这种传播过程的描述包括顺序一致性,基于时间t的一致性[24]。它们所描述的情形都是相同的。基于简单的概率原理这种传播涉及的硬件越少,能量越少,时间越少,则出现损坏的概率越低。反之则越不可靠,也就是容易出现不一致性。也就是说从能量守恒的角度说不存在绝对一致性。任何系统中一致性的评价都是基于它的坐标系提出的比较结果。例如广域网比局域网要相对不稳定,局域网比硬件要相对不稳定。所以建立对分布式精度的评判体系显得更为有意义。
结论
计算机理论中的分布式工程学是一门非常年轻的学科。随着摩尔定律进入到减速期,硬件的发展速度放缓。以及互联网行业的爆发,软件系统越来越复杂。分布式工程学迎来了一个难得的历史机遇。当下因为软件系统的产品逻辑与分布式架构的混淆,导致软件系统开发,及其二次开发和维护的成本高昂。企业需要雇佣大量的开发人员以保持对软件系统的控制能力。我估计随着产品逻辑与架构的解耦初步可以降低一半左右的开发工作量。并大幅减少二次开发的工作量和维护成本。对于企业在一般情况下可以比现在降低95 %左右的开发成本。这将大幅降低传统企业进入互联网的门槛,并从繁重的维护工作中释放大量的开发人员。可以预见在不远的将来,将再次迎来互联网行业的爆发期。并诞生大量的工具用于分布式软件的开发。并诞生真正意义的分布式操作系统。目前分布式工程学还非常的薄弱,在中国大陆仍在进行分布式研究的大学有8家。随着分布式工程学实用化进程的开展。分布式技术的推广和标准化仍然需要大量的工作。希望看到更多的学者,更多的开发者,更多的公司和组织投入到分布式工程学中。
引用
- https://en.wikipedia.org/wiki/Distributed_computing
- https://en.wikipedia.org/wiki/Actor_model
- https://en.wikipedia.org/wiki/Consistency_model#Sequential_consistency
- https://dl.acm.org/citation.cfm?id=800220&picked=prox
- https://en.wikipedia.org/wiki/Dijkstra_Prize
- Dwork, Cynthia; Lynch, Nancy; Stockmeyer, Larry (April 1988). “Consensus in the Presence of Partial Synchrony” (PDF). Journal of the ACM. 35 (2): 288–323. CiteSeerX 10.1.1.13.3423. doi:10.1145/42282.42283.
- C. Mohan, Bruce Lindsay (1985): “Efficient commit protocols for the tree of processes model of distributed transactions”,ACM SIGOPS Operating Systems Review, 19(2),pp. 40-52 (April 1985)
- https://en.wikipedia.org/wiki/Erlang_(programming_language)
- https://en.wikipedia.org/wiki/Paxos_(computer_science)
- https://en.wikipedia.org/wiki/Consistent_hashing
- https://en.wikipedia.org/wiki/CAP_theorem
- https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
- https://en.wikipedia.org/wiki/Distributed_hash_table
- Ian Clarke. A distributed decentralised information storage and retrieval system. Unpublished report, Division of Informatics, University of Edinburgh, 1999.
- https://en.wikipedia.org/wiki/Raft_(computer_science)
- Sun shuo.”Distributed Method of Web Services”. https://www.codeproject.com/Articles/3335097/Distributed-Method-of-Web-Services
- https://en.wikipedia.org/wiki/Database
- R.A. Davenport. Distributed database technology−asurvey. Computer Networks, 2(3):155–167, 1978.
- https://en.wikipedia.org/wiki/Sanjay_Ghemawat
- https://en.wikipedia.org/wiki/Jeff_Dean_(computer_scientist)
- Borowsky, Elizabeth; Gafni, Eli (1993). “Generalized FLP impossibility result for t-resilient asynchronous computations”. P 25th Annual ACM Symposium on Theory of Computing. ACM. pp. 91–100.
- https://en.wikipedia.org/wiki/Halting_problem
- https://en.wikipedia.org/wiki/Bathtub_curve
- Seth Gilbert, Nancy Lynch. “Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services”. ACM SIGACT News, v.33 n.2, June 2002 [doi>10.1145/564585.564601]
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/138269.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
