大家好,又见面了,我是你们的朋友全栈君。
不啰嗦,我们直接开始!
一、redis底层数据结构
1.sds结构
Redis中并没有直接使用C语言中的字符串,而是定义了一种简单动态字符串(simple dynamic string)作为Redis的默认字符串实现,简称SDS。
在Redis中,C语言的字符串只会用于一些无需对字符串修改的地方,如日志打印等。
而Redis默认的字符串实现是SDS,如set命令中的key底层即是一个SDS,而value如果是一个字符串类型,则底层也是SDS,如果value是列表,则列表里的每个元素底层都是SDS。
除了set命令外,SDS还被用作缓冲区:AOF模块中的AOF缓冲区,客户端状态中的输入缓冲区等都是SDS实现的。
SDS定义
SDS的定义在Redis源码的src目录下的sds.h和sds.c文件中,定义如下:
typedef struct sdshdr{
//记录buf数组中已使用字节的数量
//等于 SDS 保存字符串的长度
unsigned int len;
//记录 buf 数组中未使用字节的数量
unsigned int free;
//字节数组,用于保存字符串
char buf[];
}
redis使用类似c的方法存储字符串。用’\0’来结尾。’\0’并不用来表示具体的字符,只是一个结尾符。
使用free可以减少处理过程中可能遇到的内存申请和释放的次数。
sds扩容
-
当字符串进行初始化的时候,buf=len+1,就是加上’\0’作为长度
-
当字符串预计小于1mb的时候,扩容后buf大小=预期长度*2+1,既不考虑在雨后的’\0’,buf加倍
-
当字符串预计大于1mb的时候,buf会预留1mb的空间,buf用2倍扩容,但是预留1mb。
2、list结构
typedef struct list{
//表头节点
listNode *head;
//表尾节点
listNode *tail;
//链表所包含的节点数量
unsigned long len;
//节点值复制函数
void (*free) (void *ptr);
//节点值释放函数
void (*free) (void *ptr);
//节点值对比函数
int (*match) (void *ptr,void *key);
}list;
typedef struct listNode{
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
void *value;
}listNode
由于在list的结构中定义了头尾指针和长度,可以让push/pop、或者是求长度的操作复杂度只有o(1)。
使用了void*的操作实现了多态,可以保存不同的类型的数据。
3、ziplist结构
<bytes><tail><len><entry><entry><end>
bytes是ziplist的总长度,tail是尾部元素,len是表示元素的长度,entry是一个个实体
<entry>会有以下的部分组成
<prelen><encode><content>
prelen是前一个实体的长度,encode是指当前信息的编码信息,content是指编码过的信息
4、hashtable结构
typedef struct dictht{
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used;
}dictht
typedef struct dictEntry{
void *key;
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
struct dictEntry *next;
}dictEntry
这里的hash很像java中的hashmap。桶的个数也是2的n次方,方便使用&进行快速运算取模。
hashtable扩容和缩容
负载因子=哈希表中已有元素和哈希桶数的比值
-
负载因子小于1一定不扩容
-
负载因子大于5一定扩容
-
负载因子如果在1-5之间,redis没有进行save/rewrite的操作就会扩容
-
负载因子如果是0.1,那么会进行缩容
扩容会变成原来的2倍,缩容会变成原来的1/2。
5、intset结构
typedef struct intset{
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
}intset
默认其中存放的数据是从小到大有序的,len表示长度,encode表示编码方式。int8_t不保存对应的值,真正的类型由encoding决定
插入的时候先二分查找到插入的位置(O(log(N))),然后在对插入位置后面所有的元素往后移动一个位置。复杂度(O(N))
-
当插入的一个数据比原有的数据的字节都大,那么整个数据中的所占用的字节都会进行升级。
6、skiplist结构
跳表如下图
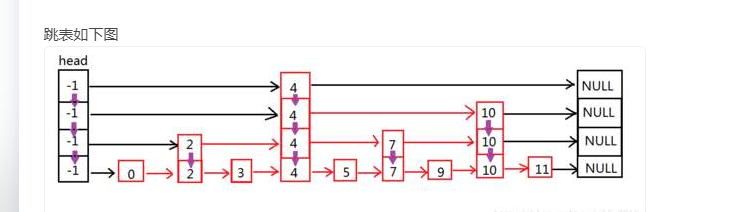

image.png
typedef struct zskiplistNode {
struct zskiplistLevel{
struct zskiplistNode *forward;
unsigned int span;
}level[];
struct zskiplistNode *backward;
double score;
robj *obj;
} zskiplistNode
typedef struct zskiplist{
//表头节点和表尾节点
structz skiplistNode *header, *tail;
//表中节点的数量
unsigned long length;
//表中层数最大的节点的层数
int level;
}zskiplist;
-
跳表有很多层组成。
-
每一层都是有序的,除了最后一层都只包含部分数据
-
最底层的包含所有的数据
搜索:从最上层开始搜索,如果发现当前层的最大值小于搜索的值。那么就去下一层寻找,往复如此的操作,直到找到最下面的一层。复杂度(O(Log(N)))
redis上层数据结构和底层数据结构对应
-
string的数据使用string。
-
list内部使用linkedlist和ziplist,当数量比较小的时候会使用ziplist来减少内存使用,否则使用linkedlist
-
map使用hashtable和ziplist,当数据量比较小的时候使用map,否则使用ziplist
-
set在数据都是整数类型时,使用intset,否则使用hashtable
-
sort-set使用ziplist和skiplist+hashtable,当数据量小的时候使用ziplist,否则使用skiplist+hashtable
二、redis持久化
1、全量写入的方式
1、save模式
save模式可以被客户端触发,也可以在关闭redis的时候出发。当被触发的时候,工作进程开始去串行化地执行一个一个的
命令。当前的无法在处理客户端的请求。因此会花很多的时间,但是由于不在处理客户端的请求,因此整个快照有一致性的。
2、bgsave模式
bgsave模式可以被客户端触发,也可以通过配置定时任务触发。bgsave模式会fork一个子线程出来,在子线程启动以后修改一些状态后
redis的主进程进行处理后续的命令。写快照的任务会和主线程并发执行,因此可以继续提供对外服务。当子线程完成任务后会通知
主进程。在之后的数据修改则不会写入快照。因为子线程是父线程fork出来的,会设计到父进程的内存复制,因为有增加大量的内存开销。
fork也会阻塞主进程。
3、全量恢复流程
redis启动进入事件处理主循环,会全量把快照中的数据全部读出来放到内存中,之后在来处理请求。因为在加载快照的过程中redis是不处理客户端请求的。
4、增量性质的持久化
增量保存的是每一次变化。给定初始状态,经常相同的变化操作后,最终的状态也是一样的。因此可以根据增量持久化数据,通过对一个
初始状态进行变化回复出最终的状态。
2、增量写入的方式
每次主循环处理完写命令以后,通过propagate函数触发。propagate方法将当前的命令append到redisServer对象中的aof_buf中。
在主循环进入下次select之前,redis通过flushAppendOnlyFile将aof_buf的内容write到的aof文件中。但是存在一个问题write只是写入到操作系统的缓存
中,具体什么时候落盘不一定。只有调用fsync()才能强制落地。
1、AOF的三种策略
-
always:每次调用flushAppendOnlyFile直接在调用一次fsync方法,强制数据落地。但是会降低redis的吞吐能力,写操作可能变成瓶颈,
但是是安全性最高的。 -
every secord:每秒异步的触发一次fsync方法。fsync方法会调用bio的中的线程来处理。
-
no:不直接调用,一切有操作系统决定,完全不可控
2、增量恢复流程
AOF也和全量一样,当redis启动进入事件处理主循环之前进行处理。但是存在AOF,redis会选择增量不是全量。因为增量的数据是持续的写入。因此和
全量相比数据更加新一些。会写过程就是把命令在重新执行一遍,只有执行完成以后,redis主循环才会继续接受客户端命令。
不啰嗦,文章结束,期待三连!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/138183.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
