大家好,又见面了,我是你们的朋友全栈君。
之前我们讲解了 正则表达式 的起源、发展、流派、语法、引擎、优化等相关知识,今天我们主要来学习一下 正则表达式在 Python语言 中的应用!
大多数编程语言的正则表达式设计都师从Perl,所以语法基本相似,不同的是每种语言都有自己的函数去支持正则,今天我们就来学习 Python中关于 正则表达式的函数。
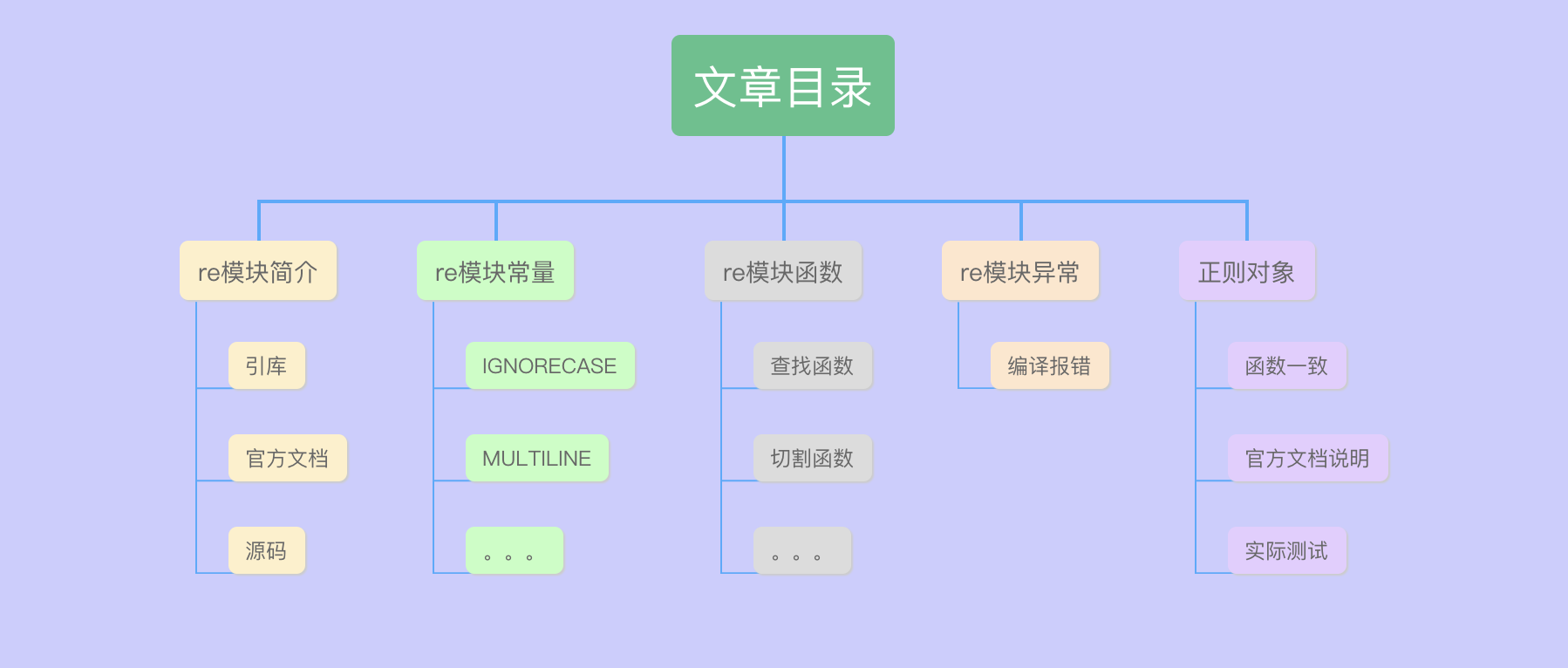

一、re模块简介
聊到Python正则表达式的支持,首先肯定会想到re库,这是一个Python处理文本的标准库。
标准库的意思表示这是一个Python内置模块,不需要额外下载,目前Python内置模块大概有300个。可以在这里查看Python所有的内置模块:https://docs.python.org/3/py-modindex.html#cap-r
因为re是内置模块,所以不需要再下载,使用时直接引入即可:
import re
re模块主要定义了9个常量、12个函数、1个异常,每个常量和函数猪哥都会通过实际代码案例讲解,让大家能更直观的了解其作用!
注:为避免出现代码格式错乱,猪哥尽量使用代码截图演示哦。
re模块官方文档:https://docs.python.org/zh-cn/3.8/library/re.html
re模块库源码:https://github.com/python/cpython/blob/3.8/Lib/re.py
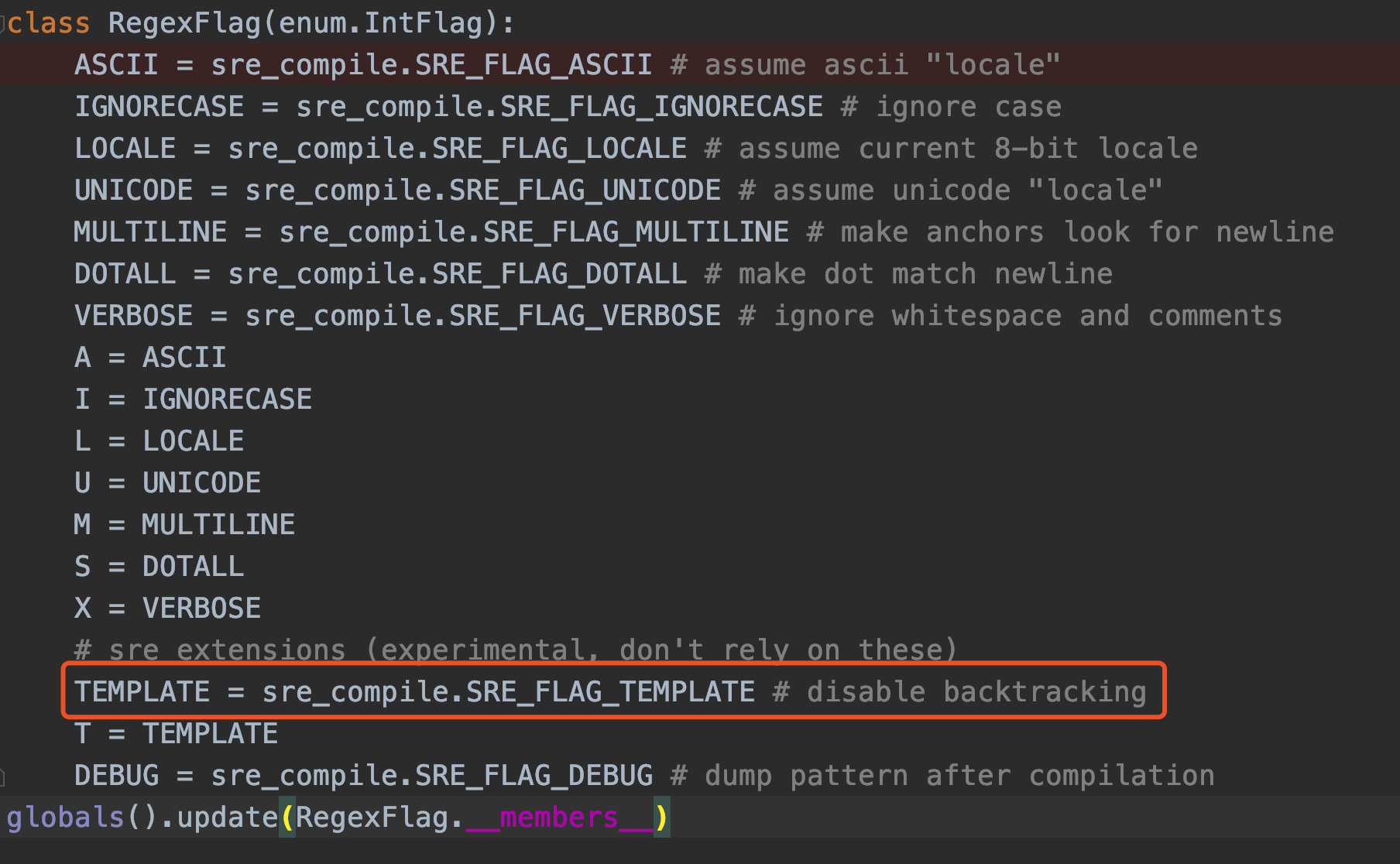
二、re模块常量
常量即表示不可更改的变量,一般用于做标记。
re模块中有9个常量,常量的值都是int类型!
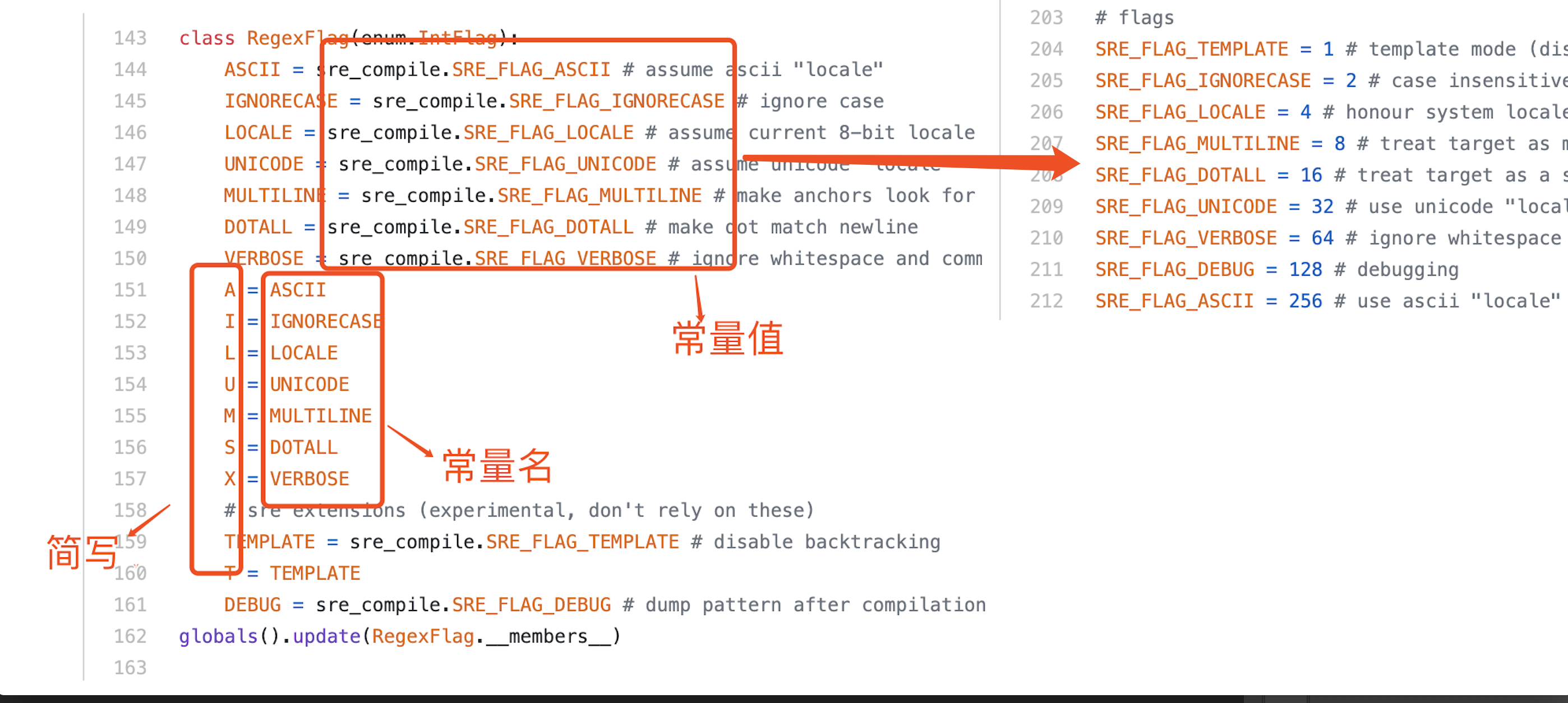
上图我们可以看到,所有的常量都是在RegexFlag枚举类来实现,这是在Python 3.6做的改版。在Python 3.6以前版本是直接将常量写在re.py中,使用枚举的好处就是方便管理和使用!

下面我们来快速学习这些常量的作用及如何使用他们,按常用度排序!
1. IGNORECASE
语法: re.IGNORECASE 或简写为 re.I
作用: 进行忽略大小写匹配。
代码案例:
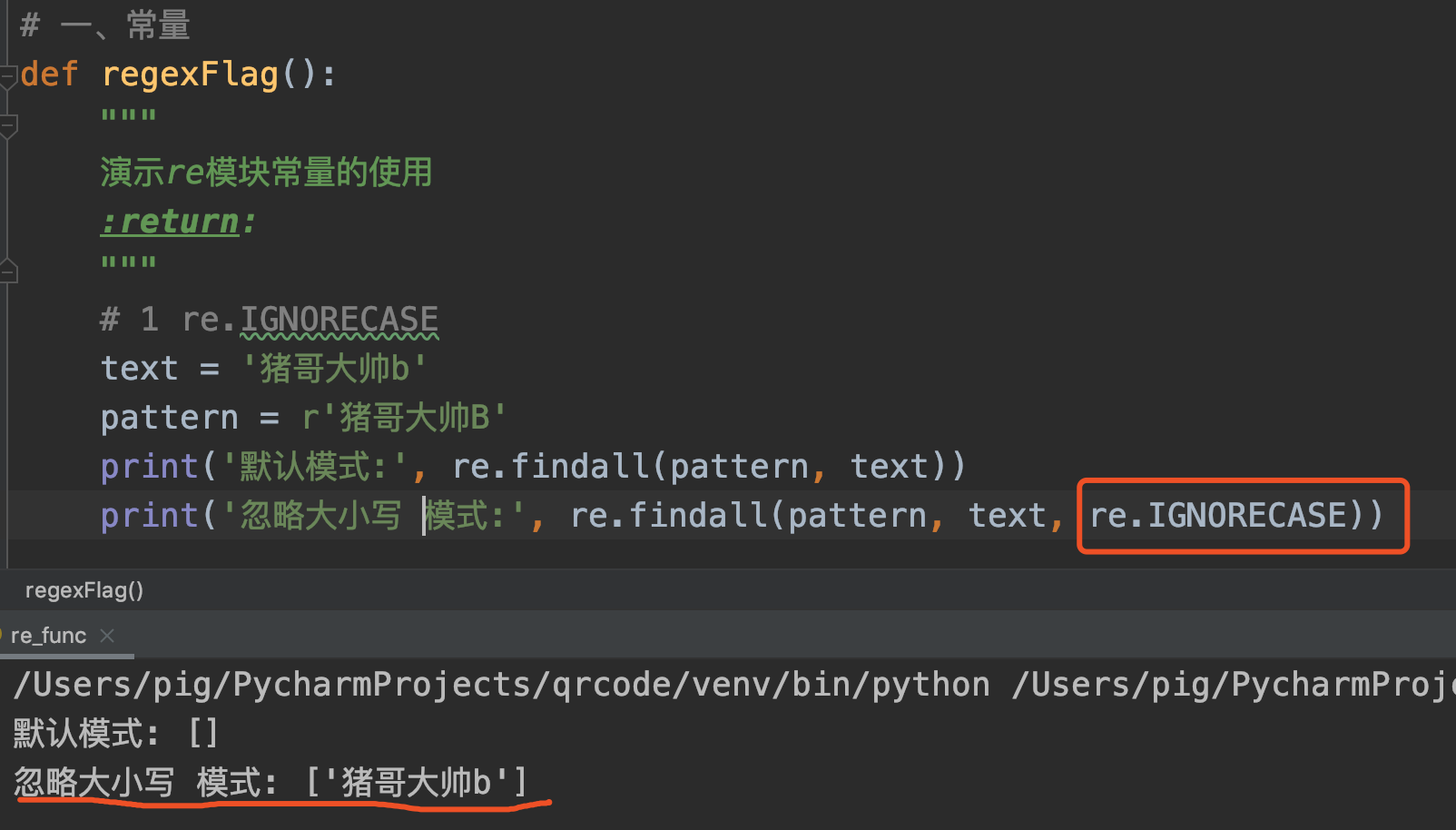
在默认匹配模式下大写字母B无法匹配小写字母b,而在 忽略大小写 模式下是可以的。
2. ASCII
语法: re.ASCII 或简写为 re.A
作用: 顾名思义,ASCII表示ASCII码的意思,让 \w, \W, \b, \B, \d, \D, \s 和 \S 只匹配ASCII,而不是Unicode。
代码案例:
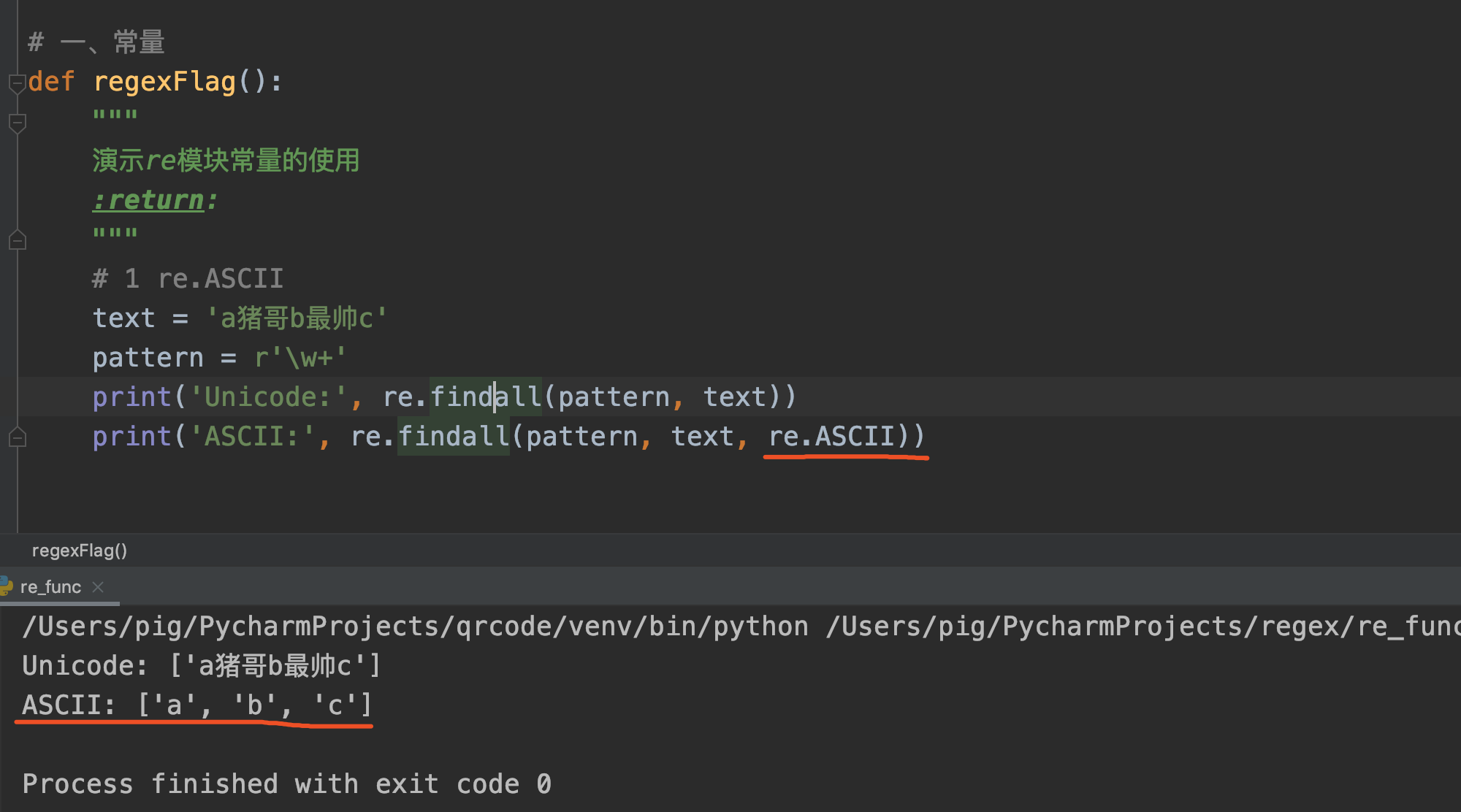
在默认匹配模式下\w+匹配到了所有字符串,而在ASCII模式下,只匹配到了a、b、c(ASCII编码支持的字符)。
注意:这只对字符串匹配模式有效,对字节匹配模式无效。
3. DOTALL
语法: re.DOTALL 或简写为 re.S
作用: DOT表示.,ALL表示所有,连起来就是.匹配所有,包括换行符\n。默认模式下.是不能匹配行符\n的。
代码案例:
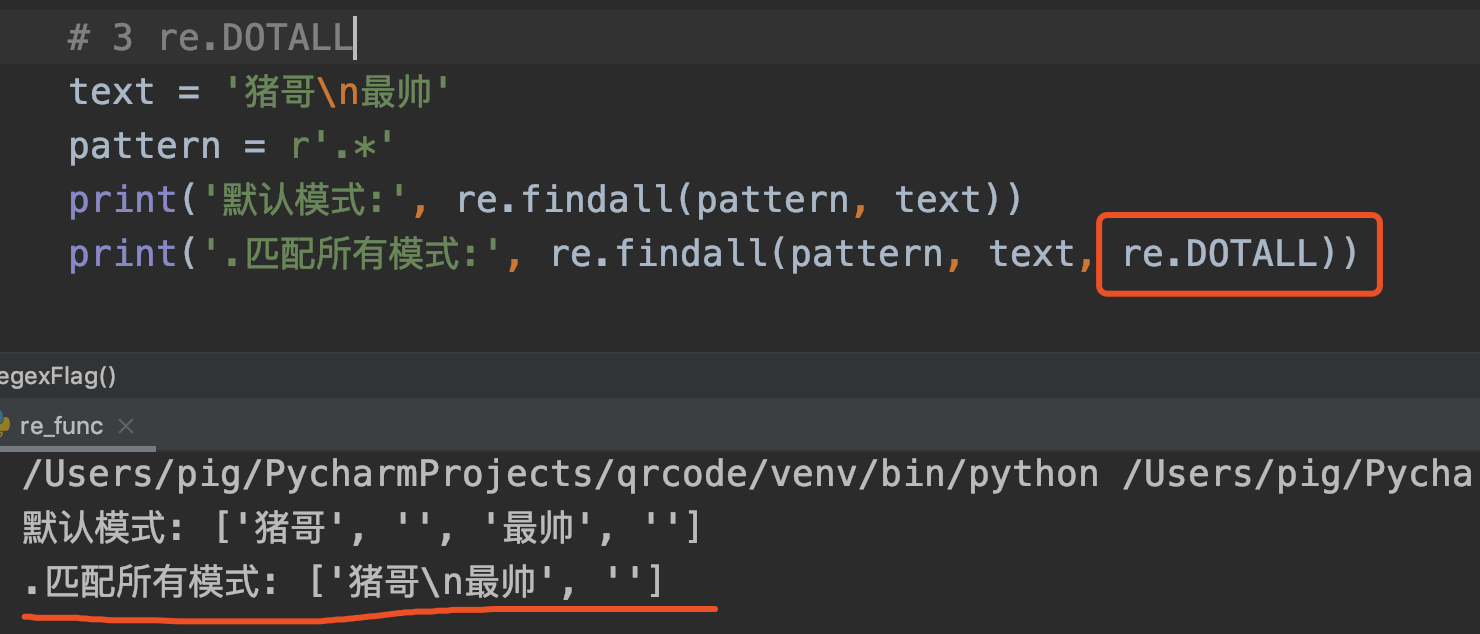
在默认匹配模式下.并没有匹配换行符\n,而是将字符串分开匹配;而在re.DOTALL模式下,换行符\n与字符串一起被匹配到。
注意:默认匹配模式下.并不会匹配换行符\n。
4. MULTILINE
语法: re.MULTILINE 或简写为 re.M
作用: 多行模式,当某字符串中有换行符\n,默认模式下是不支持换行符特性的,比如:行开头 和 行结尾,而多行模式下是支持匹配行开头的。
代码案例:
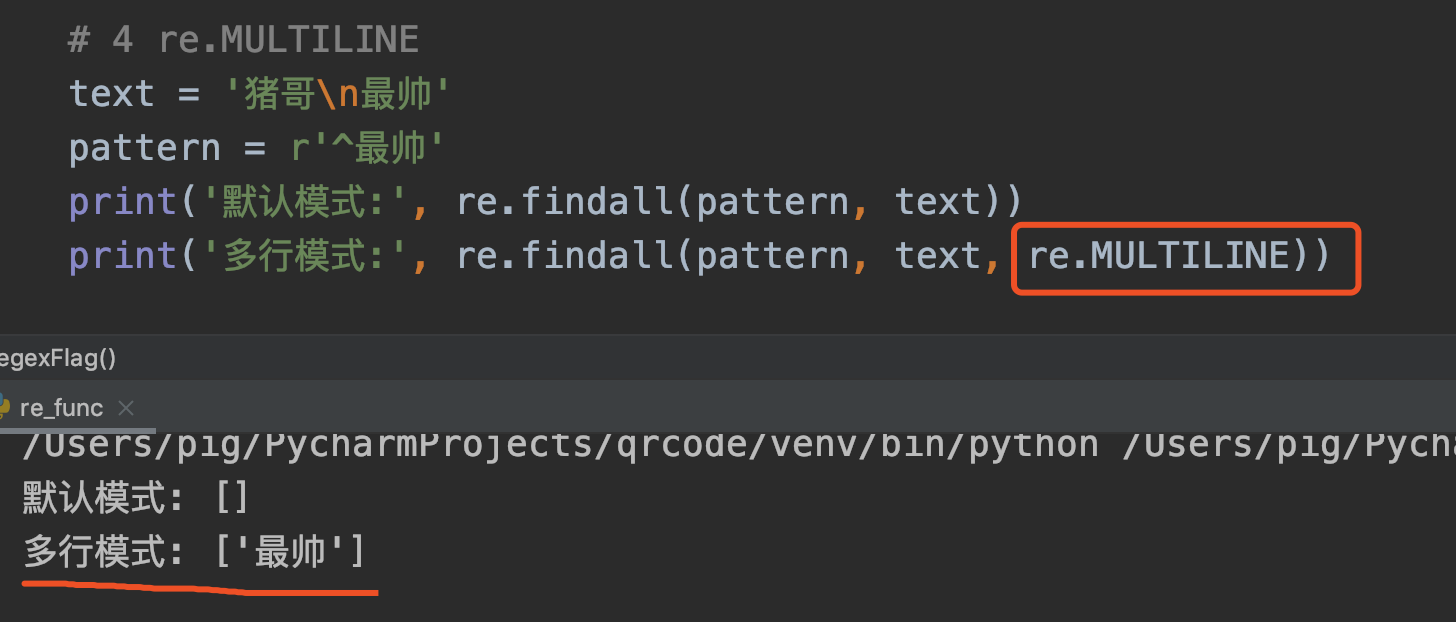
正则表达式中^表示匹配行的开头,默认模式下它只能匹配字符串的开头;而在多行模式下,它还可以匹配 换行符\n后面的字符。
注意:正则语法中^匹配行开头、\A匹配字符串开头,单行模式下它两效果一致,多行模式下\A不能识别\n。
5. VERBOSE
语法: re.VERBOSE 或简写为 re.X
作用: 详细模式,可以在正则表达式中加注解!
代码案例:
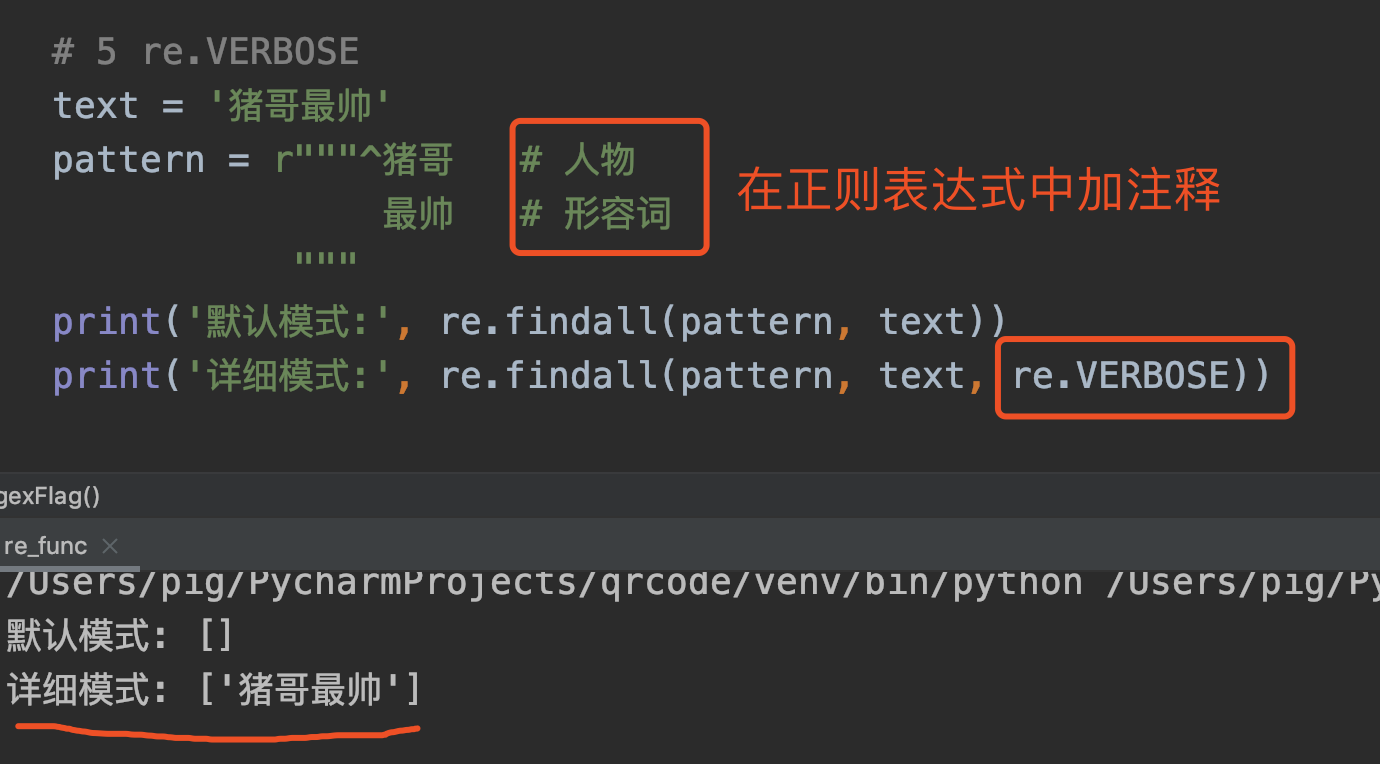
默认模式下并不能识别正则表达式中的注释,而详细模式是可以识别的。
当一个正则表达式十分复杂的时候,详细模式或许能为你提供另一种注释方式,但它不应该成为炫技的手段,建议谨慎考虑后使用!
6.LOCALE
语法: re.LOCALE 或简写为 re.L
作用: 由当前语言区域决定 \w, \W, \b, \B 和大小写敏感匹配,这个标记只能对byte样式有效。这个标记官方已经不推荐使用,因为语言区域机制很不可靠,它一次只能处理一个 “习惯”,而且只对8位字节有效。
注意: 由于这个标记官方已经不推荐使用,而且猪哥也没使用过,所以就不给出实际的案例!
7.UNICODE
语法: re.UNICODE 或简写为 re.U
作用: 与 ASCII 模式类似,匹配unicode编码支持的字符,但是 Python 3 默认字符串已经是Unicode,所以有点冗余。
8. DEBUG
语法: re.DEBUG
作用: 显示编译时的debug信息。
代码案例:
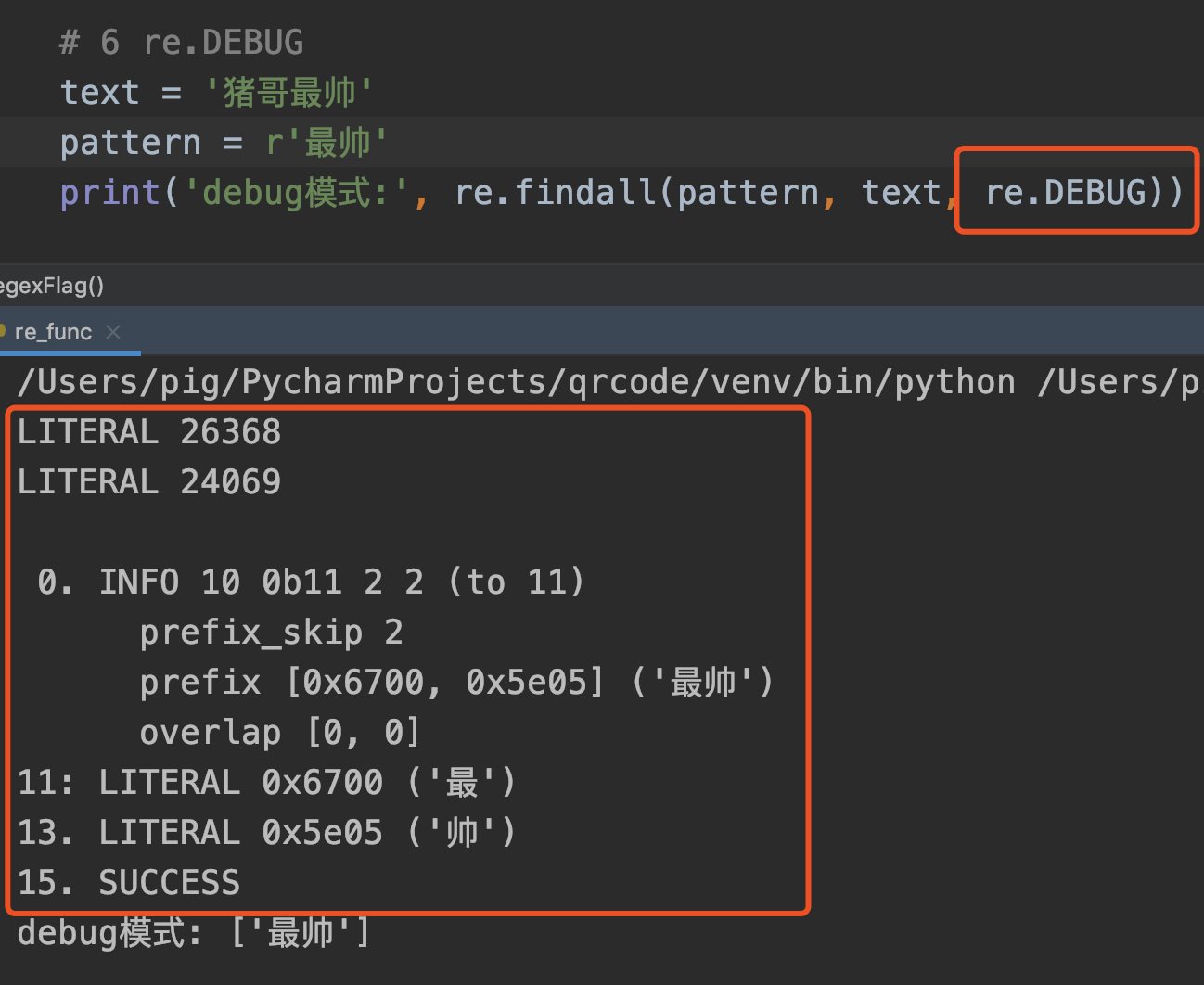
虽然debug模式下确实会打印编译信息,但猪哥并不理解这是什么语言 以及表达的含义,希望了解的朋友能不吝赐教。
9.TEMPLATE
语法: re.TEMPLATE 或简写为 re.T
作用: 猪哥也没搞懂TEMPLATE的具体用处,源码注释中写着:disable backtracking(禁用回溯),有了解的同学可以留言告知!
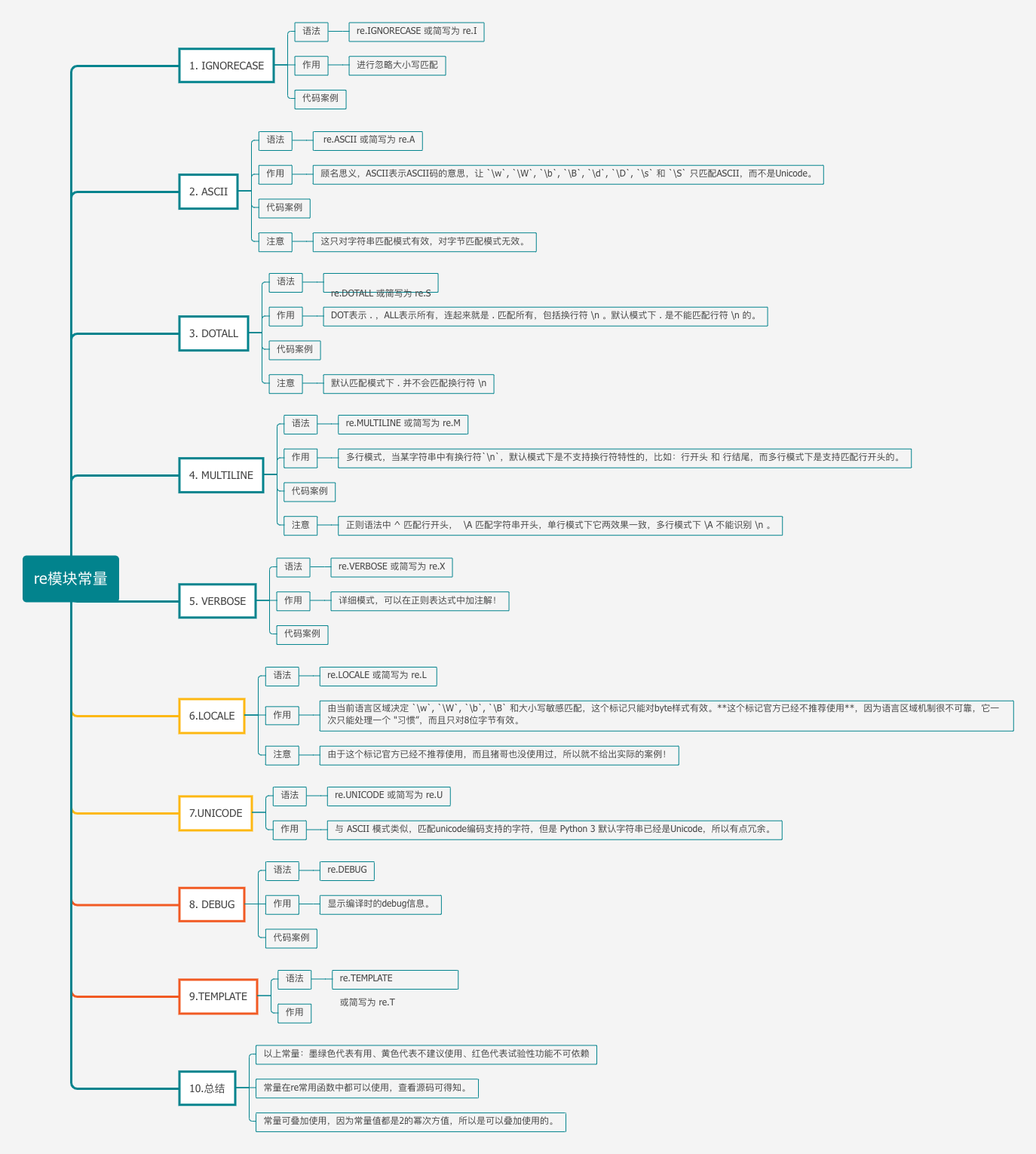
10. 常量总结
- 9个常量中,前5个(IGNORECASE、ASCII、DOTALL、MULTILINE、VERBOSE)有用处,两个(LOCALE、UNICODE)官方不建议使用、两个(TEMPLATE、DEBUG)试验性功能,不能依赖。
- 常量在re常用函数中都可以使用,查看源码可得知。
- 常量可叠加使用,因为常量值都是2的幂次方值,所以是可以叠加使用的,叠加时请使用
|符号,请勿使用+符号!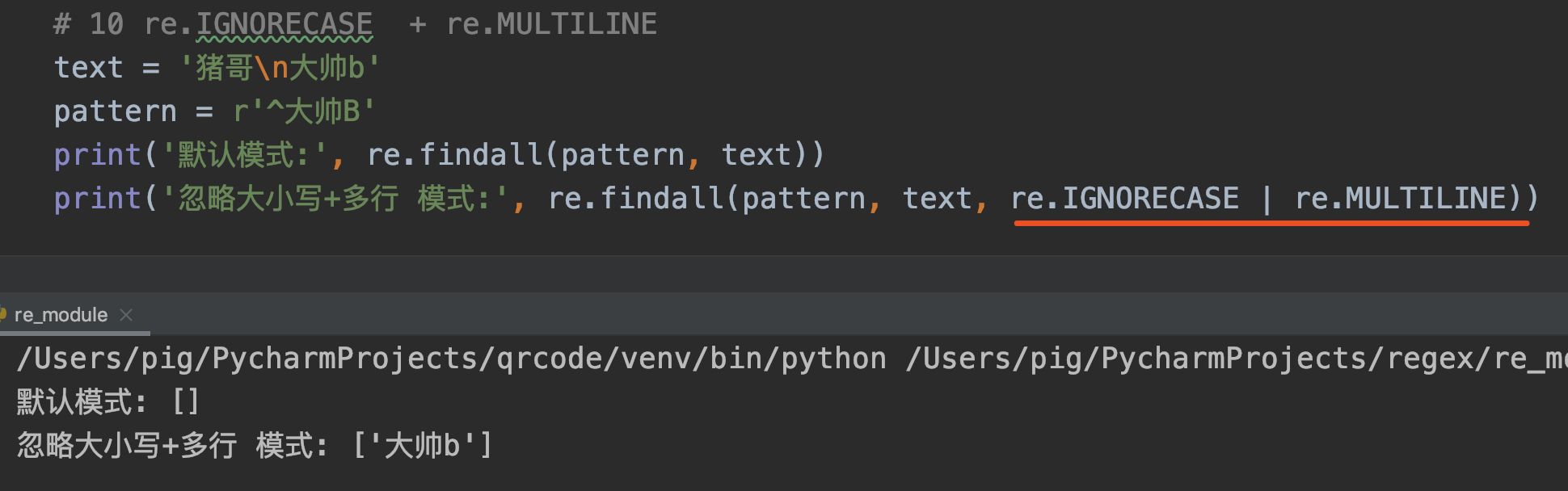
最后来一张思维导图总结一下re模块中的常量吧。
三、re模块函数
re模块有12个函数,猪哥将以功能分类来讲解;这样更具有比较性,同时也方便记忆。
1.查找一个匹配项
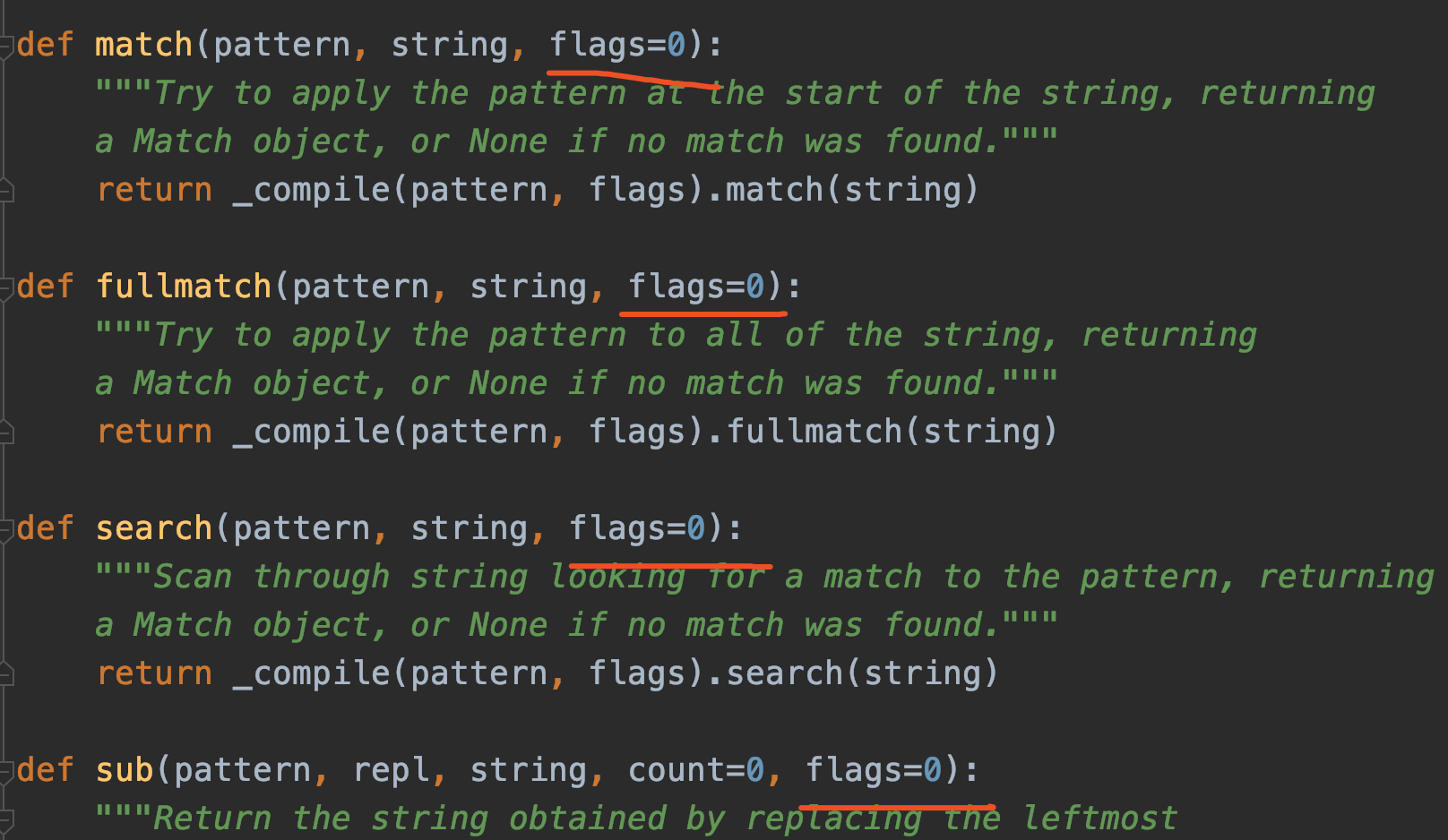
查找并返回一个匹配项的函数有3个:search、match、fullmatch,他们的区别分别是:
- search: 查找任意位置的匹配项
- match: 必须从字符串开头匹配
- fullmatch: 整个字符串与正则完全匹配
我们再来根据实际的代码案例比较:
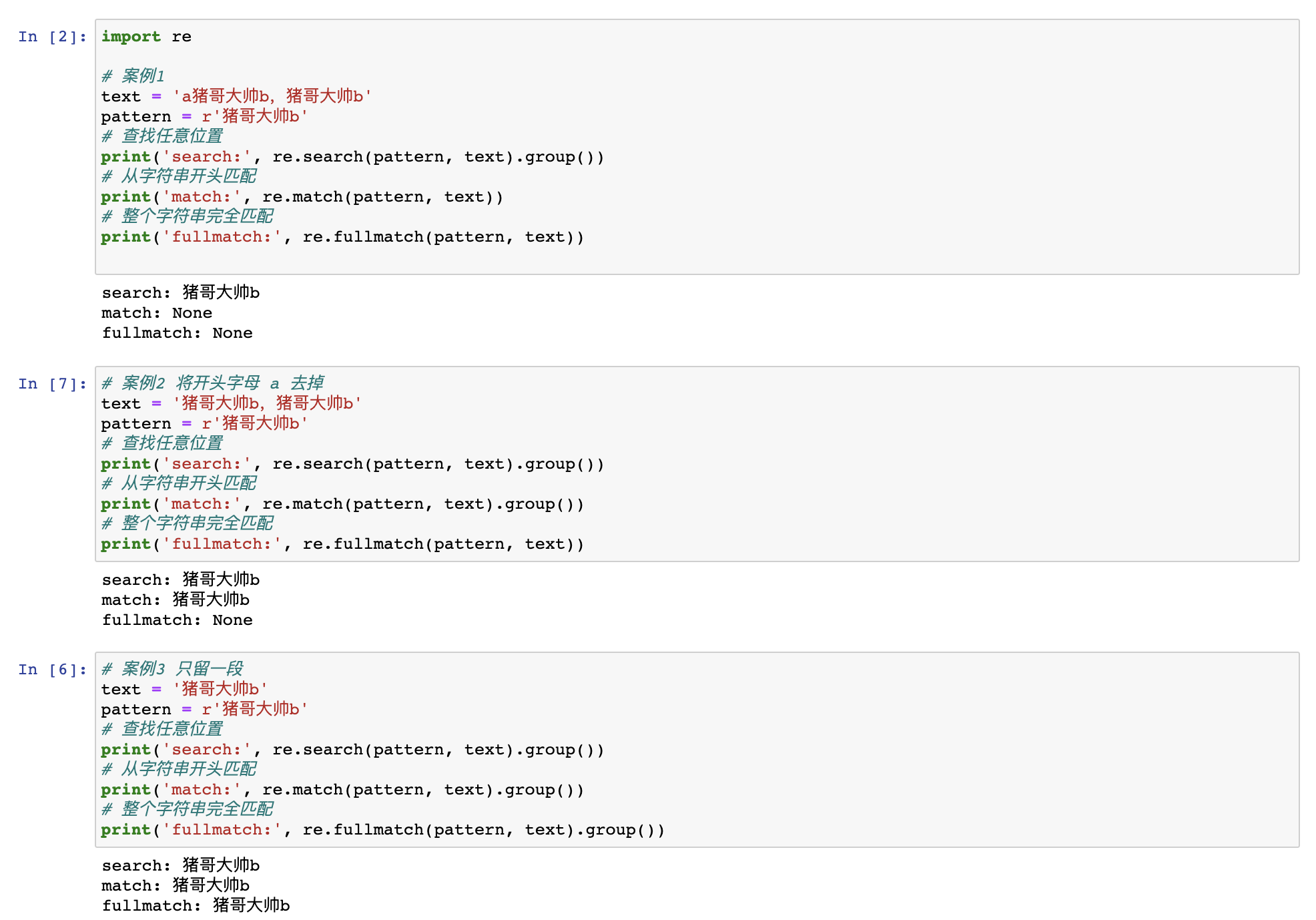
案例1:

案例1中search函数是在字符串中任意位置匹配,只要有符合正则表达式的字符串就匹配成功,其实有两个匹配项,但search函数值返回一个。
而match函数是要从头开始匹配,而字符串开头多了个字母a,所以无法匹配,fullmatch函数需要完全相同,故也不匹配!
案例2:

案例2删除了text最开头的字母a,这样match函数就可以匹配啦,而fullmatch函数依然不能完全匹配!
案例3:

案例3中,我们只留下一段文字,并且与正则表达式一致;这时fullmatch函数终于可以匹配了。
完整案例:
注意:查找 一个匹配项 返回的都是一个匹配对象(Match)。
2.查找多个匹配项
讲完查找一项,现在来看看查找多项吧,查找多项函数主要有:findall函数 与 finditer函数:
- findall: 从字符串任意位置查找,返回一个列表
- finditer:从字符串任意位置查找,返回一个迭代器
两个方法基本类似,只不过一个是返回列表,一个是返回迭代器。我们知道列表是一次性生成在内存中,而迭代器是需要使用时一点一点生成出来的,内存使用更优。

如果可能存在大量的匹配项的话,建议使用finditer函数,一般情况使用findall函数基本没啥影响。
3.分割
re.split(pattern, string, maxsplit=0, flags=0) 函数:用 pattern 分开 string , maxsplit表示最多进行分割次数, flags表示模式,就是上面我们讲解的常量!

注意:str模块也有一个 split函数 ,那这两个函数该怎么选呢?
str.split函数功能简单,不支持正则分割,而re.split支持正则。
关于二者的速度如何? 猪哥实际测试一下,在相同数据量的情况下使用re.split函数与str.split函数执行次数 与 执行时间 对比图:
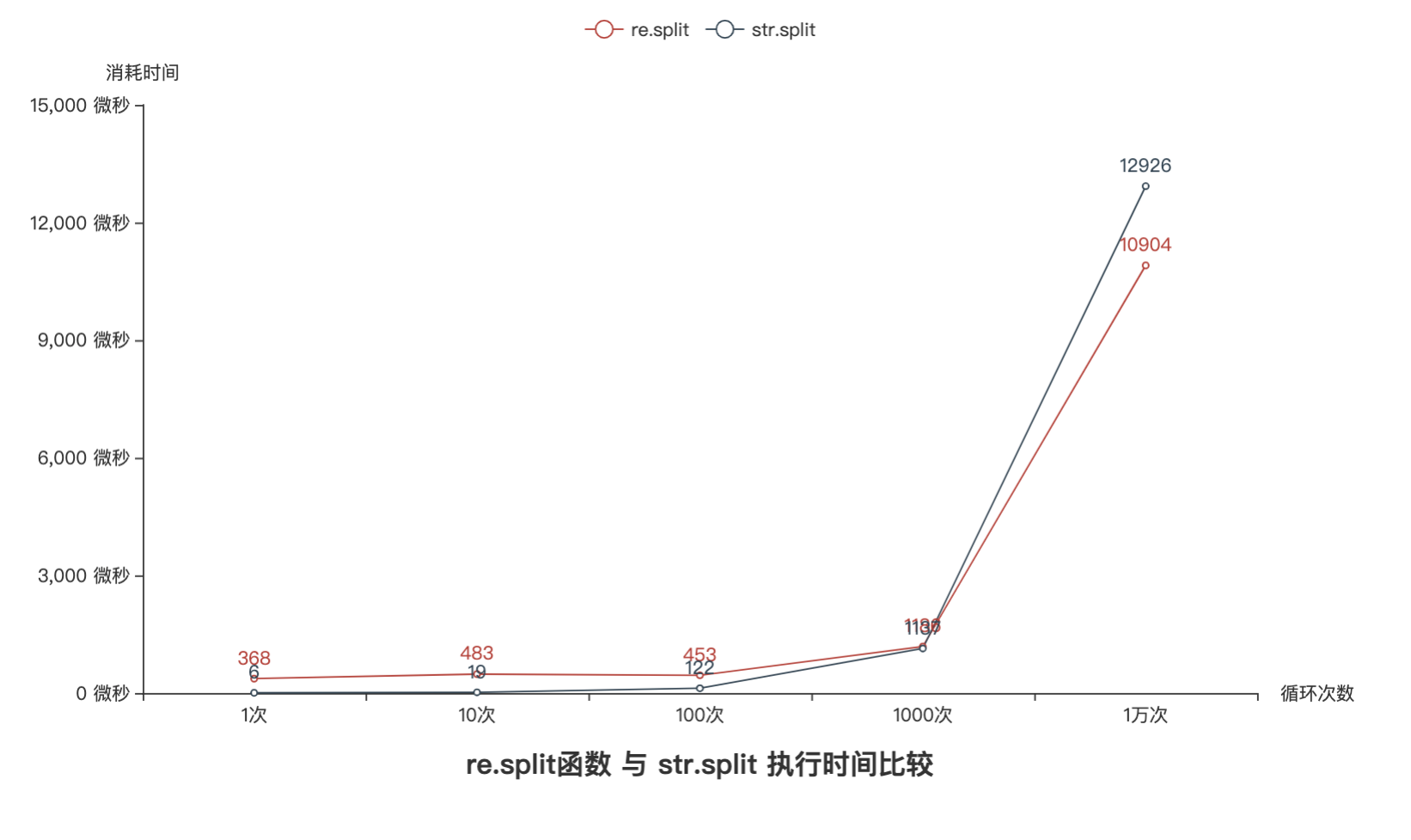
通过上图对比发现,1000次循环以内str.split函数更快,而循环次数1000次以上后re.split函数明显更快,而且次数越多差距越大!
所以结论是:在 不需要正则支持 且 数据量和数次不多 的情况下使用str.split函数更合适,反之则使用re.split函数。
注:具体执行时间与测试数据有关!
4.替换
替换主要有sub函数 与 subn函数,他们功能类似!
先来看看sub函数的用法:
re.sub(pattern, repl, string, count=0, flags=0) 函数参数讲解:repl替换掉string中被pattern匹配的字符, count表示最大替换次数,flags表示正则表达式的常量。
值得注意的是:sub函数中的入参:repl替换内容既可以是字符串,也可以是一个函数哦! 如果repl为函数时,只能有一个入参:Match匹配对象。

re.subn(pattern, repl, string, count=0, flags=0) 函数与 re.sub函数 功能一致,只不过返回一个元组 (字符串, 替换次数)。

5.编译正则对象
compile函数 与 template函数 将正则表达式的样式编译为一个 正则表达式对象 (正则对象Pattern),这个对象与re模块有同样的正则函数(后面我们会讲解Pattern正则对象)。

而template函数 与 compile函数 类似,只不过是增加了我们之前说的re.TEMPLATE 模式,我们可以看看源码。

6.其他
re.escape(pattern) 可以转义正则表达式中具有特殊含义的字符,比如:. 或者 * ,举个实际的案例:

re.escape(pattern) 看似非常好用省去了我们自己加转义,但是使用它很容易出现转义错误的问题,所以并不建议使用它转义,而建议大家自己手动转义!
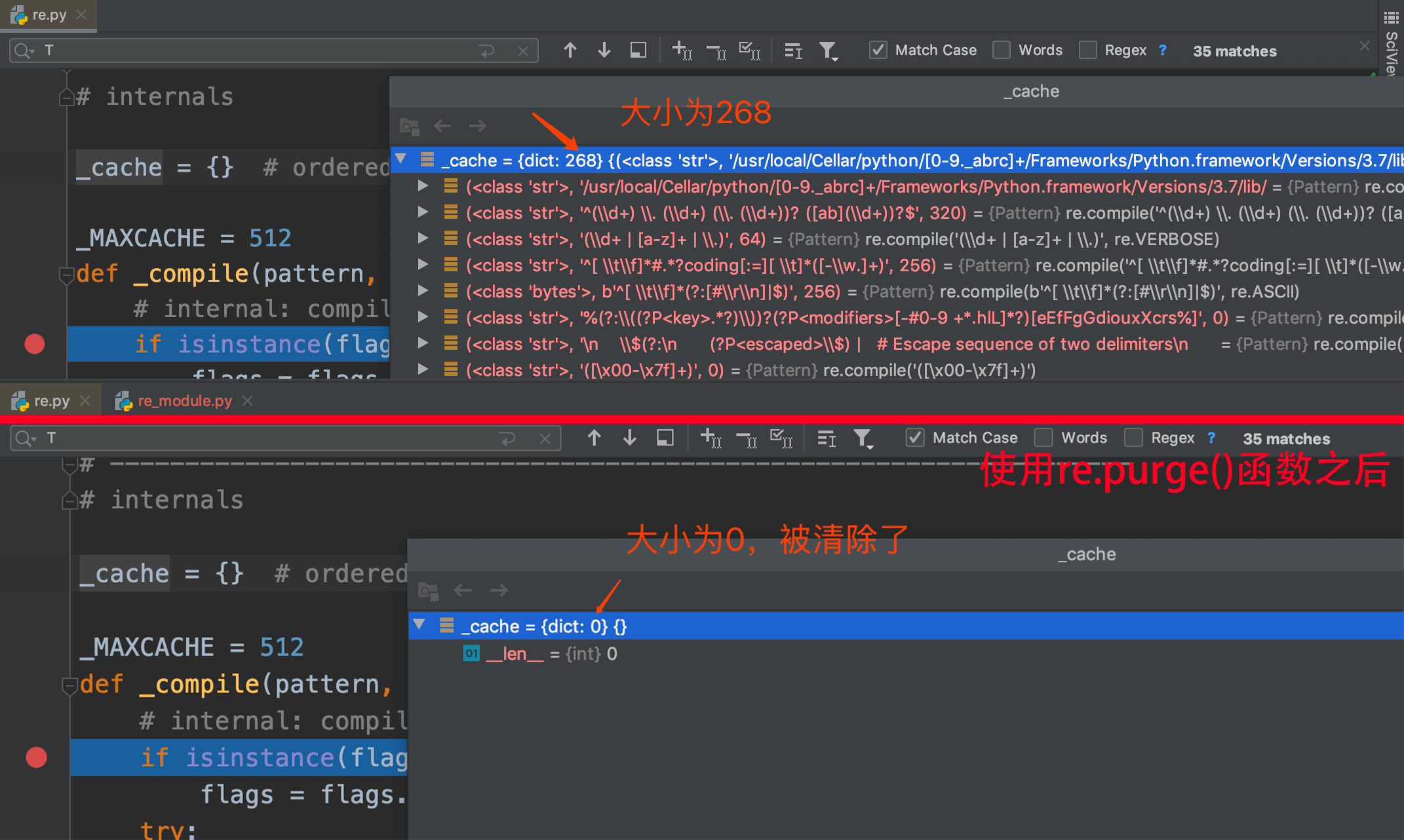
re.purge() 函数作用就是清除 正则表达式缓存,具体有什么缓存呢?我们来看看源码就知道它背地里干了 什么:
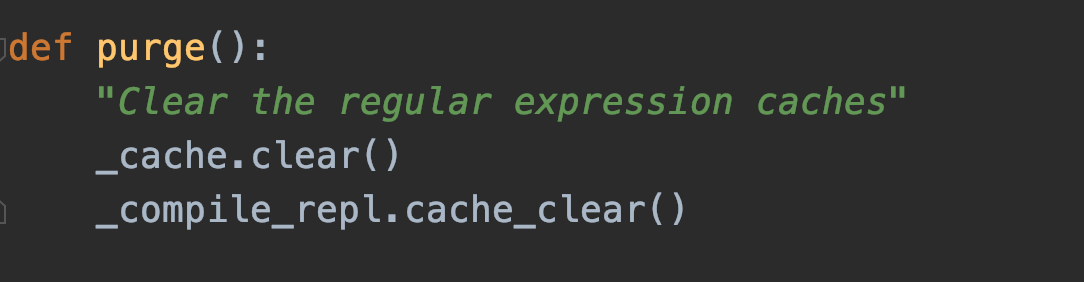
看方法大概是清除缓存吧,我们再来看看具体的案例:
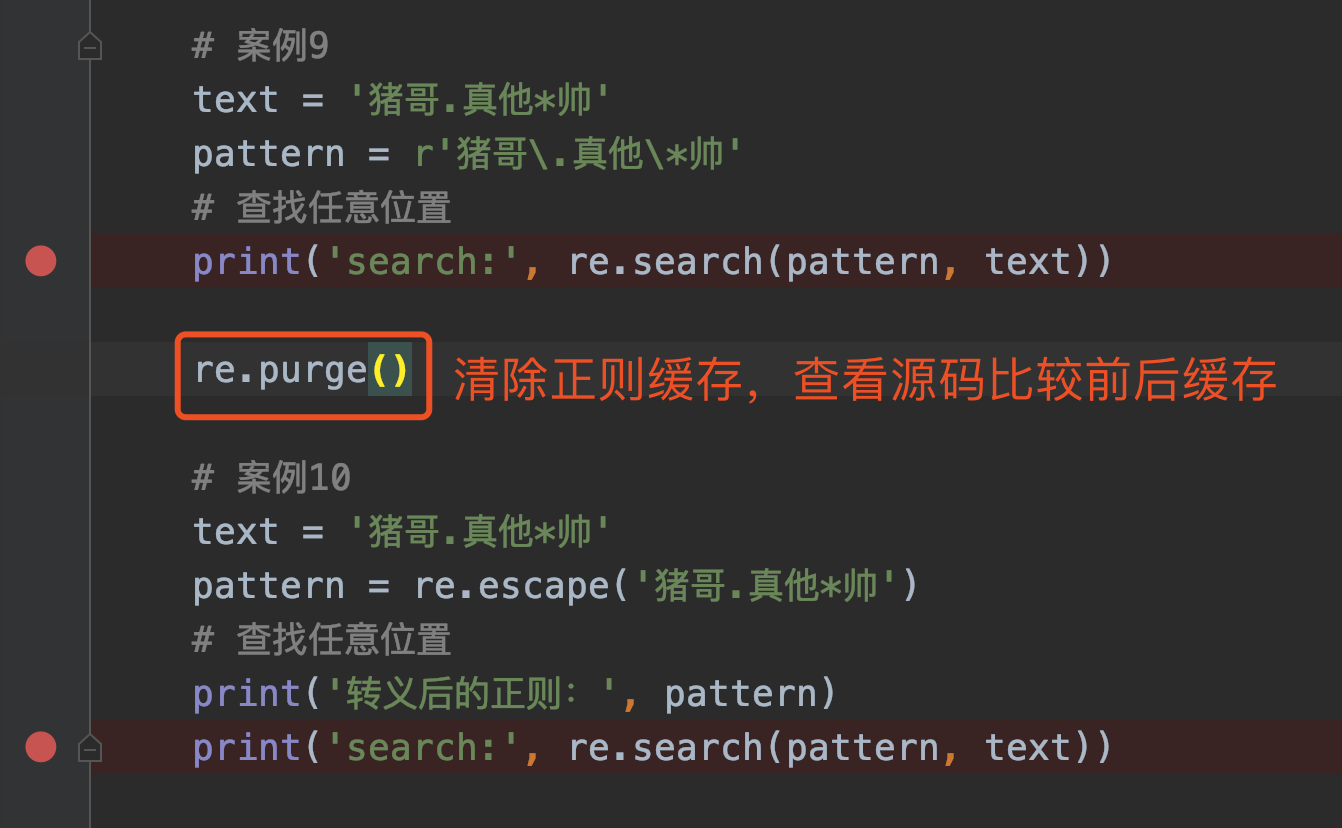
猪哥在两个案例之间使用了re.purge() 函数清除缓存,然后分别比较前后案例源码里面的缓存,看看是否有变化!
7.总结
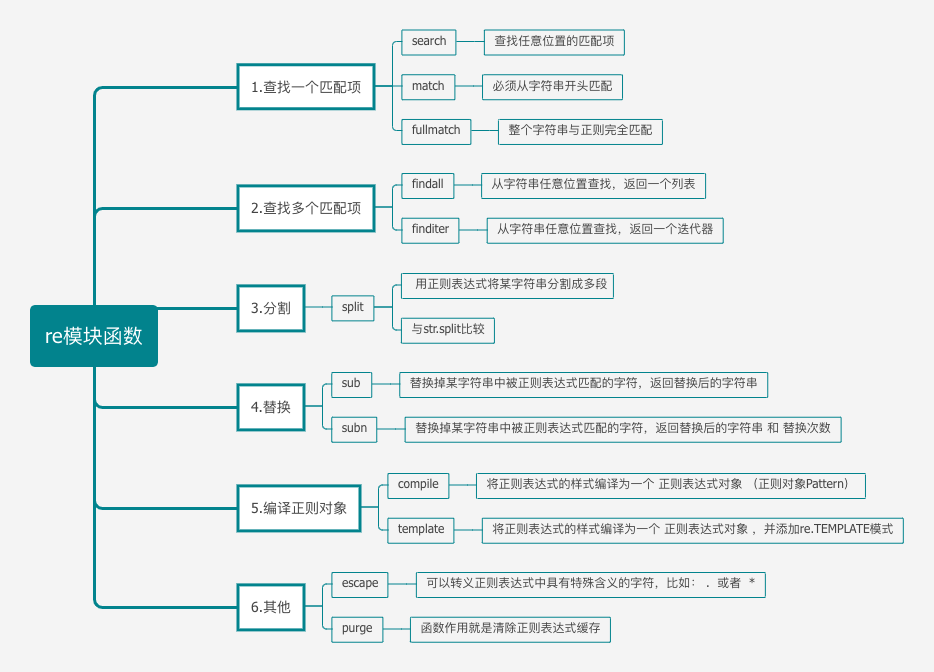
同样最后来一张思维导图总结一下re模块中的函数吧。
四、re模块异常
re模块还包含了一个正则表达式的编译错误,当我们给出的正则表达式是一个无效的表达式(就是表达式本身有问题)时,就会raise一个异常!
我们来看看具体的案例吧:
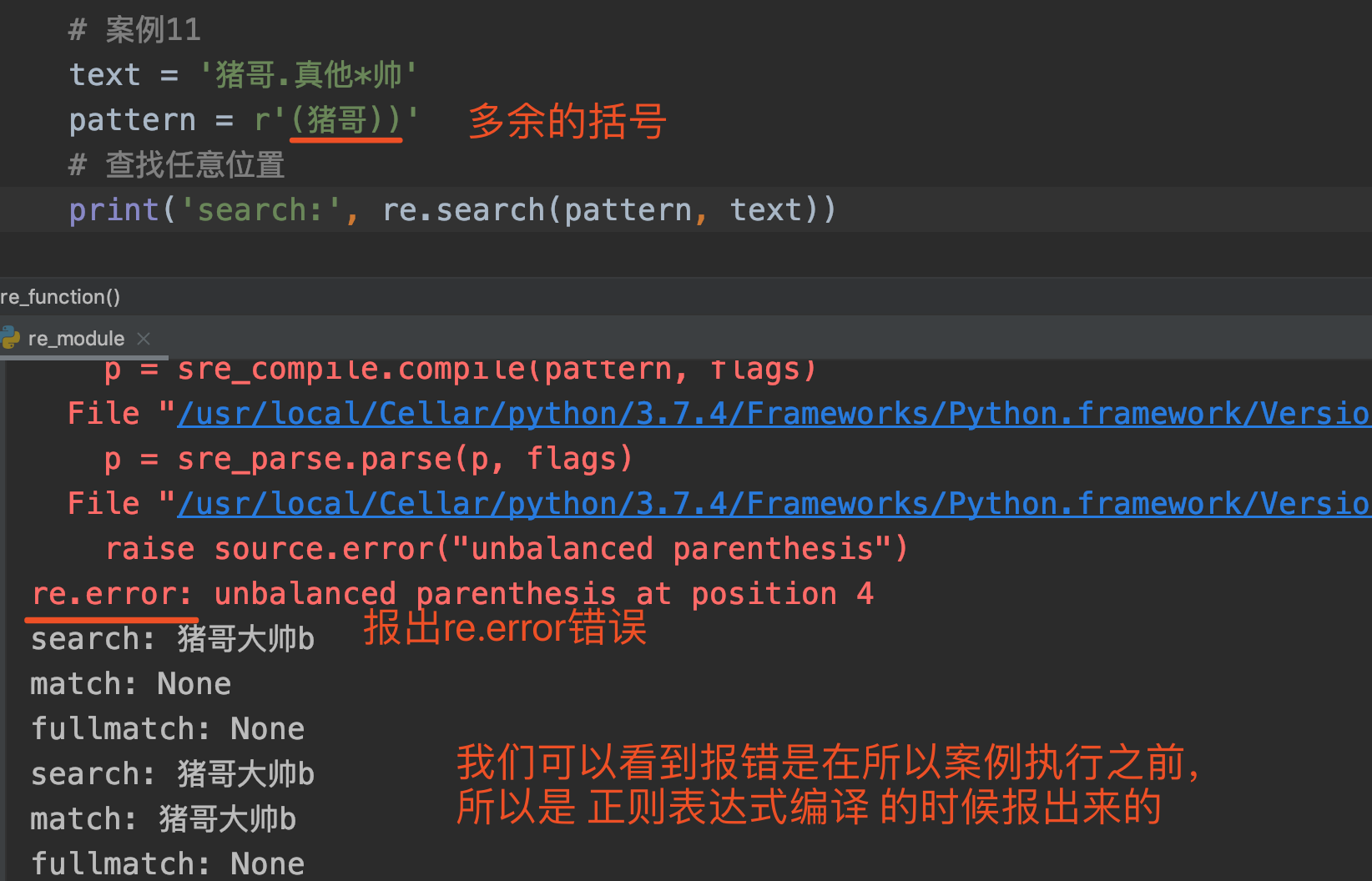
上图案例中我们可以看到,在编写正则表达式中我们多写了一个括号,这导致执行结果报错;而且是在其他所有案例执行之前,所以说明是在正则表达式编译时期就报错了。
注意:这个异常一定是 正则表达式 本身是无效的,与要匹配的字符串无关!
五、正则对象Pattern
关于re模块的常量、函数、异常我们都讲解完毕,但是完全有必要再讲讲正则对象Pattern。
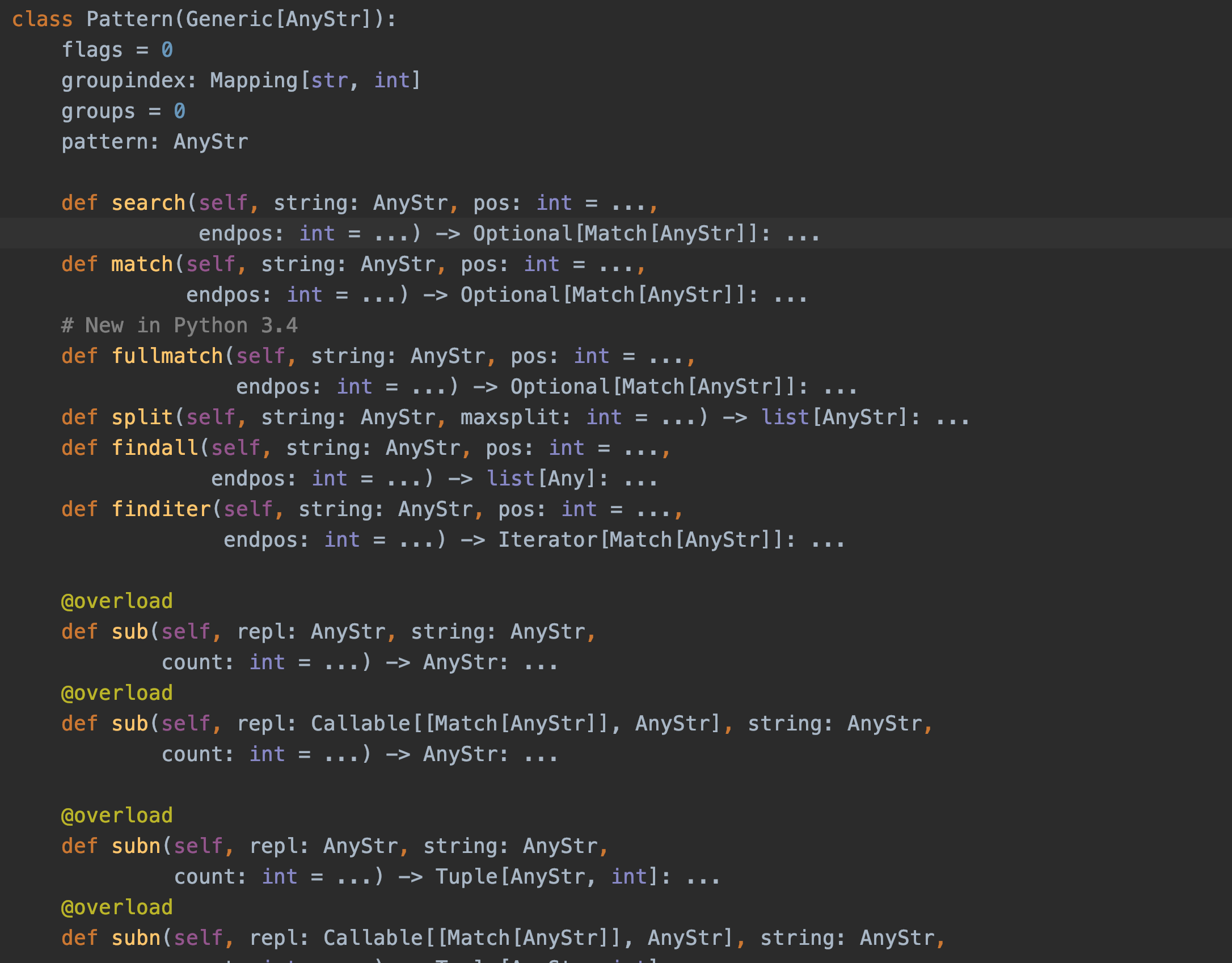
1. 与re模块 函数一致
在re模块的函数中有一个重要的函数 compile函数 ,这个函数可以预编译返回一个正则对象,此正则对象拥有与re模块相同的函数,我们来看看Pattern类的源码。
既然是一致的,那到底该用re模块 还是 正则对象Pattern ?
而且,有些同学可能看过re模块的源码,你会发现其实compile函数 与 其他 re函数(search、split、sub等等) 内部调用的是同一个函数,最终还是调用正则对象的函数!
也就是说下面 两种代码写法 底层实现 其实是一致的:
# re函数
re.search(pattern, text)
# 正则对象函数
compile = re.compile(pattern)
compile.search(text)
那还有必要使用compile函数 得到正则对象再去调用 search函数 吗?直接调用re.search 是不是就可以?
2. 官方文档怎么说
关于到底该用re模块 还是 正则对象Pattern ,官方文档是否有说明呢?
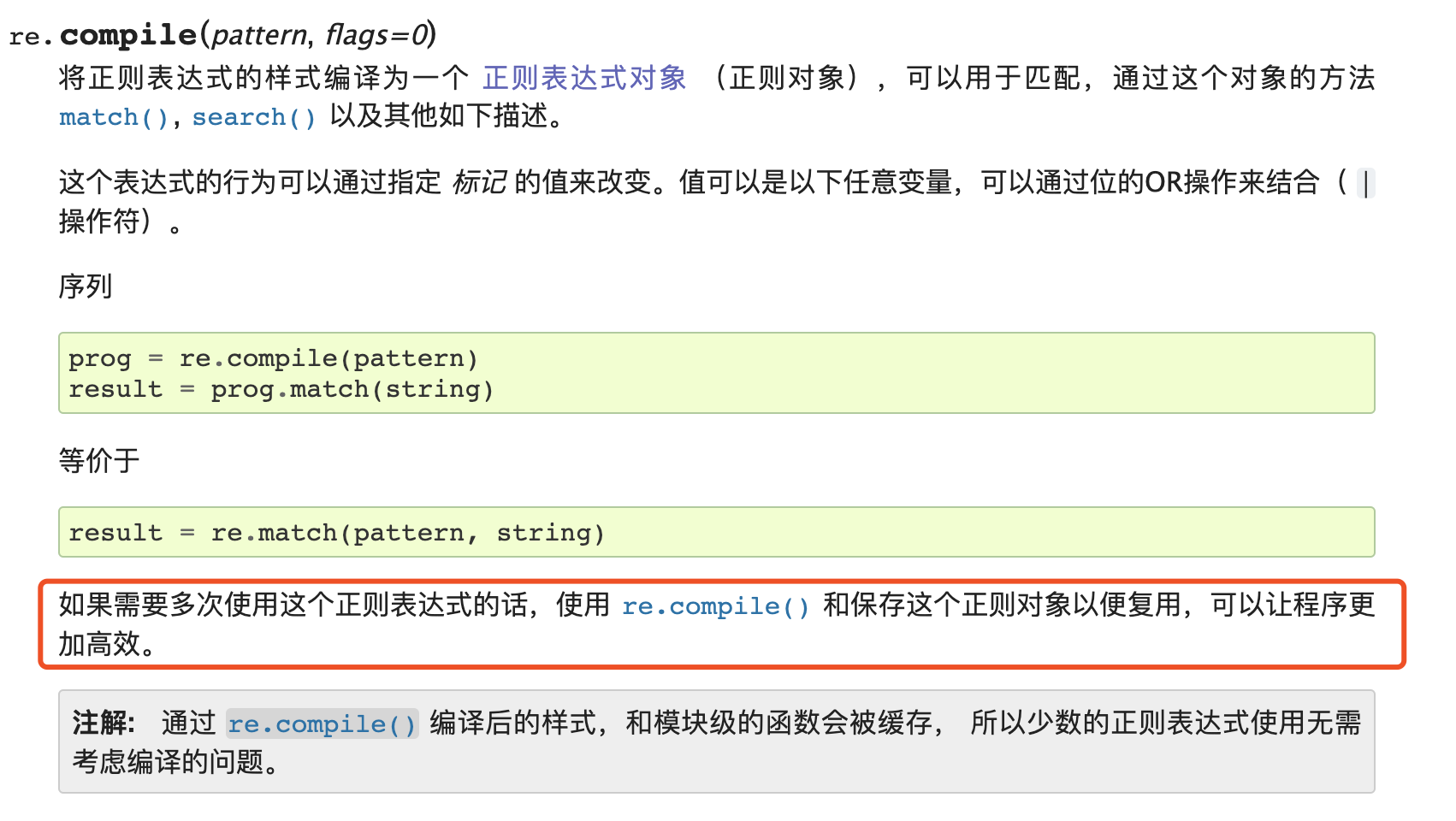
官方文档推荐:在多次使用某个正则表达式时推荐使用正则对象Pattern 以增加复用性,因为通过 re.compile(pattern) 编译后的模块级函数会被缓存!
3. 实际测试又如何?
上面官方文档推荐我们在 多次使用某个正则表达式时使用正则对象,那实际情况真的是这样的吗?
我们在实测一下吧
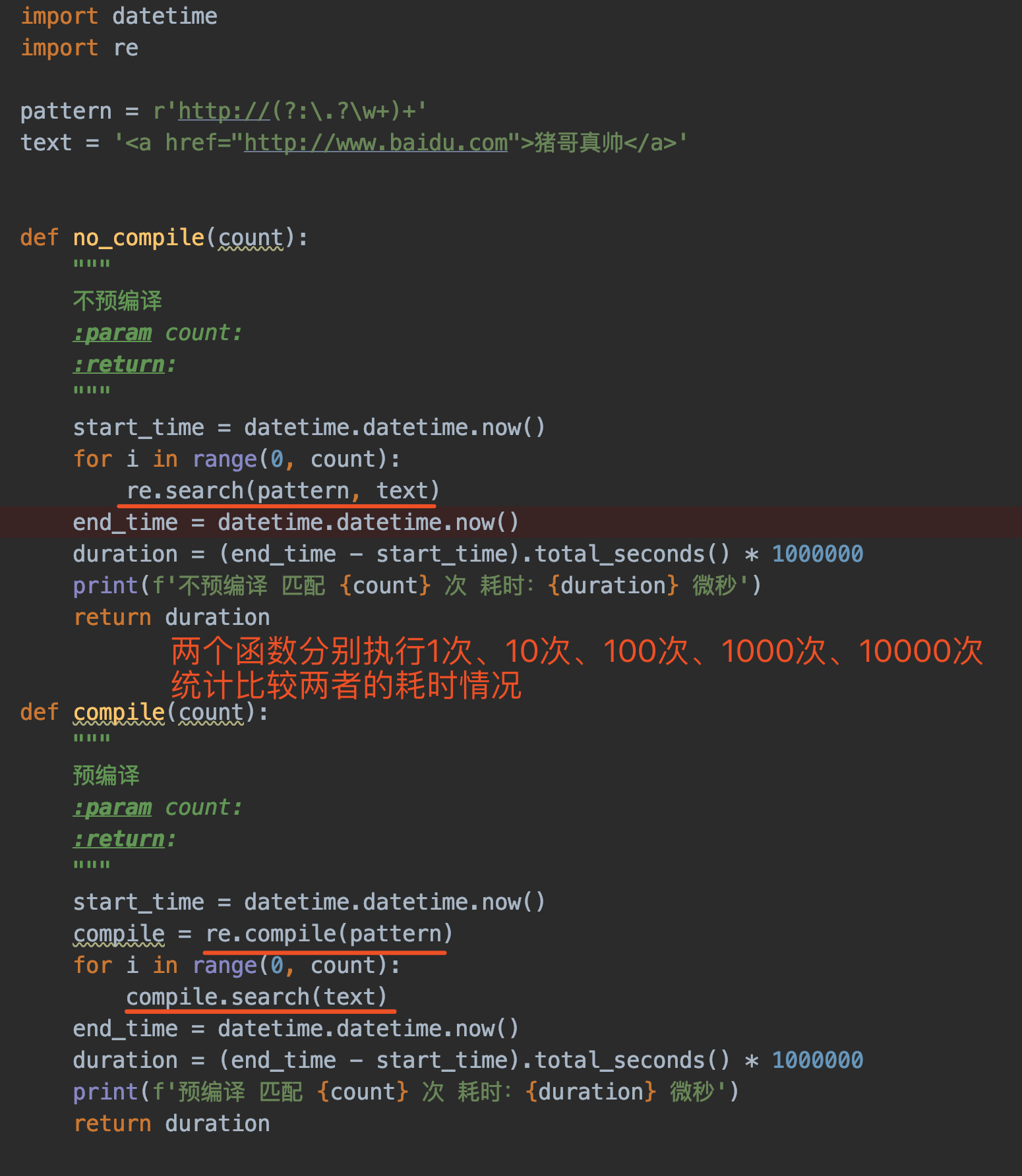
猪哥编写了两个函数,一个使用re.search函数 另一个使用 compile.search函数 ,分别(不同时)循环执行count次(count从1-1万),比较两者的耗时!
得出的结果猪哥绘制成折线图:
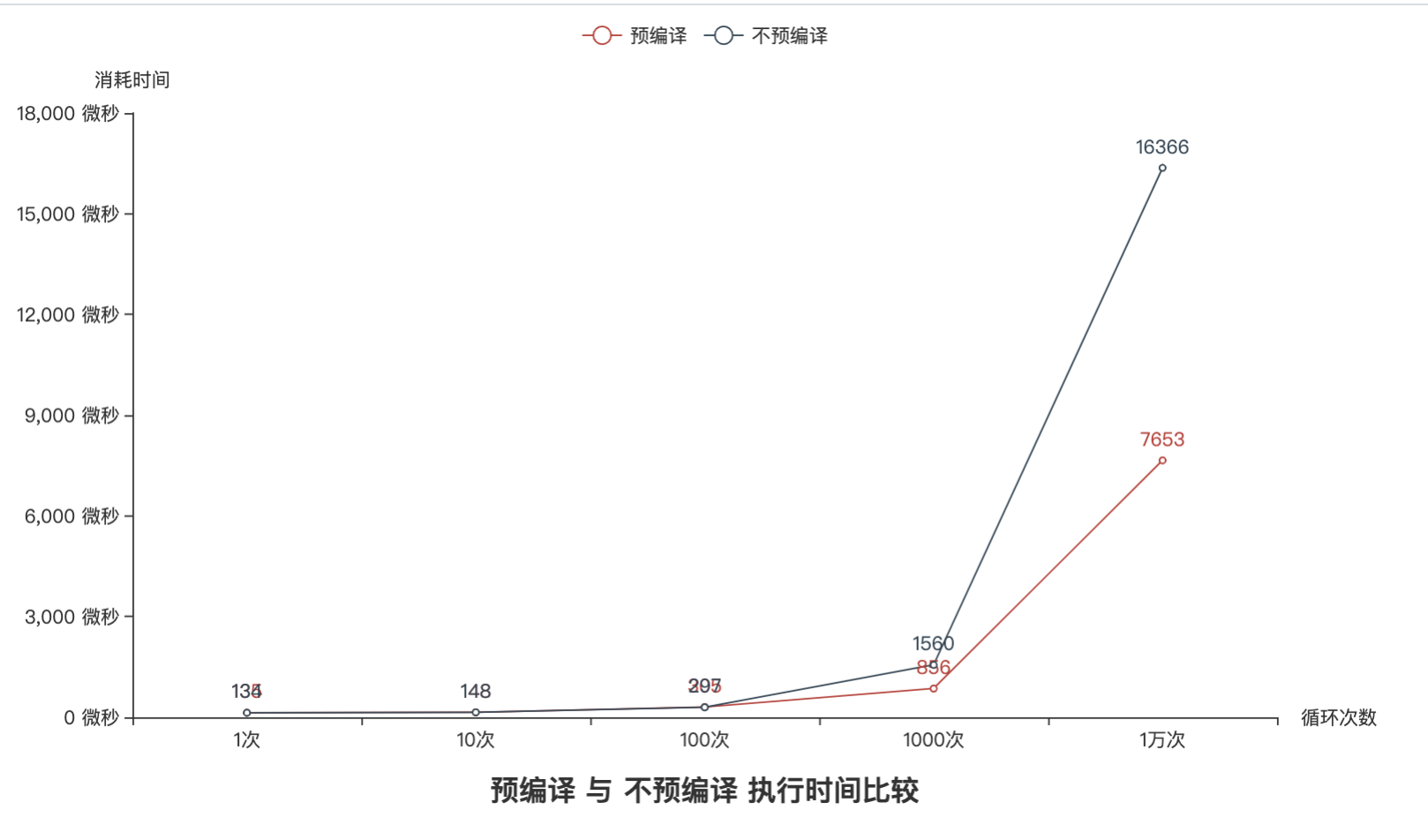
得出的结论是:100次循环以内两者的速度基本一致,当超出100次后,使用 正则对象Pattern 的函数 耗时明显更短,所以比re模块 要快!
通过实际测试得知:Python 官方文档推荐 多次使用某个正则表达式时使用正则对象函数 基本属实!
六、注意事项
Python 正则表达式知识基本讲解完毕,最后稍微给大家提一提需要注意的点。
1.字节串 与 字符串
模式和被搜索的字符串既可以是 Unicode 字符串 (str) ,也可以是8位字节串 (bytes)。 但是,Unicode 字符串与8位字节串不能混用!
2.r 的作用
正则表达式使用反斜杠(’’)来表示特殊形式,或者把特殊字符转义成普通字符。
而反斜杠在普通的 Python 字符串里也有相同的作用,所以就产生了冲突。
解决办法是对于正则表达式样式使用 Python 的原始字符串表示法;在带有 ‘r’ 前缀的字符串字面值中,反斜杠不必做任何特殊处理。
3.正则查找函数 返回匹配对象
查找一个匹配项(search、match、fullmatch)的函数返回值都是一个 匹配对象Match ,需要通过match.group() 获取匹配值,这个很容易忘记。

另外还需要注意:match.group() 与match.groups() 函数的差别!
4.重复使用某个正则
如果要重复使用某个正则表达式,推荐先使用 re.compile(pattern)函数 返回一个正则对象,然后复用这个正则对象,这样会更快!
5.Python 正则面试
笔试可能会遇到需要使用Python正则表达式,不过不会太难的,大家只要记住那几个方法的区别,会正确使用,基本问题不大。
是否对Python的正则表达式有了一个清晰的了解呢?
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/138163.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
