大家好,又见面了,我是你们的朋友全栈君。
配置清单:
eclipse:mars.1
maven:3.3.9
jdk:1.7
1,从码云上将代码clone到本地

现在需要将这两个项目导入eclipse中
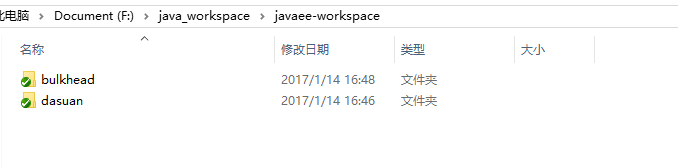
2,eclipse中maven的配置
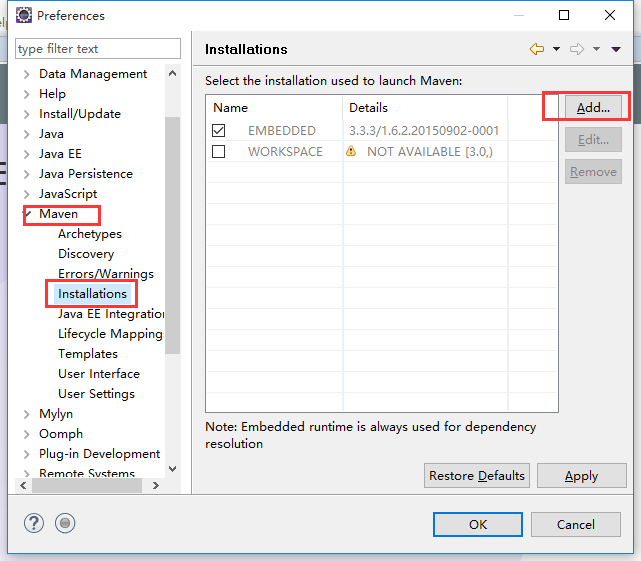
选择本地maven保存的路径,配置maven的安装路径
配置完成之后选择复选框
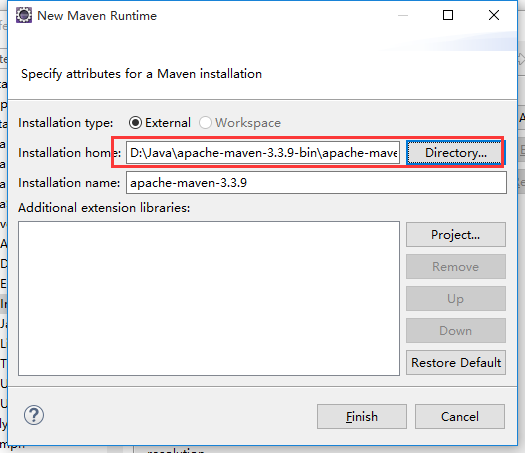
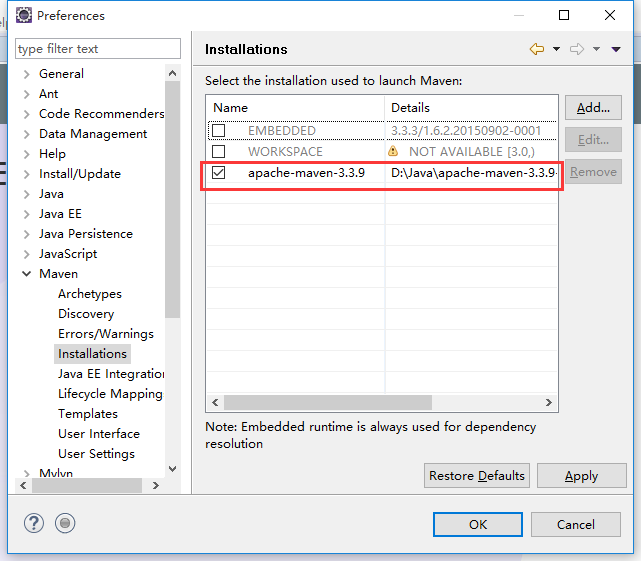
3,配置仓库位置和配置文件信息(这是没有配置之前的)
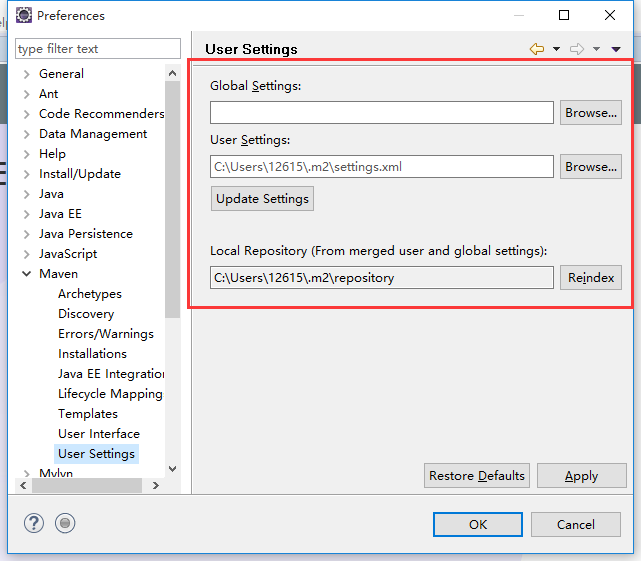
(1)找到apache-maven-3.3.9-bin\apache-maven-3.3.9\conf你的maven文件夹下的conf下的settings.xml文件
(2)编辑该文件
在节点配置以下代码,设置本地仓库的下载jar文件的镜像,使用的是阿里的maven镜像
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror> 在配置文件的末尾添加一行,配置本地仓库的位置,我指向的是D:\Java\m2\repository
<localRepository>D:\Java\m2\repository</localRepository>
</settings>4,回到eclipse继续配置步骤3的信息
(1)global的browse选择D:\Java\apache-maven-3.3.9-bin\apache-maven-3.3.9\conf下的setting.xml配置文件
(2)user Setting复制上面的路径就行
(3)本地仓库位置,自动获取配置文件的路径,就是步骤3所配置的D:\Java\m2\repository文件夹
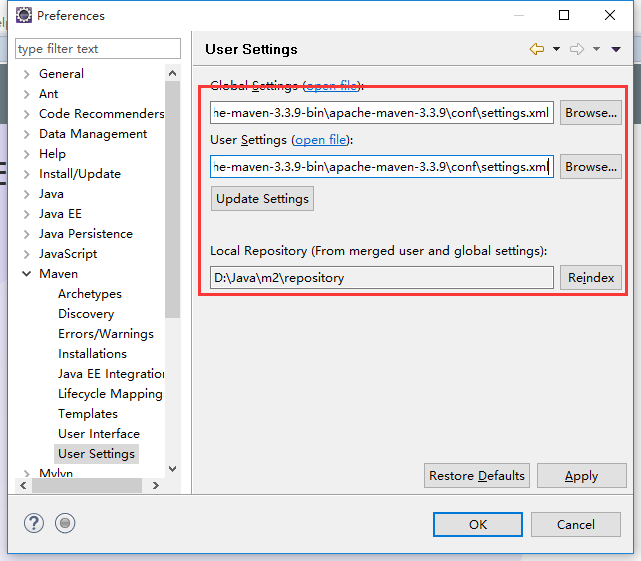
依次点击apply,OK即可,配置完成,下面开始导入项目
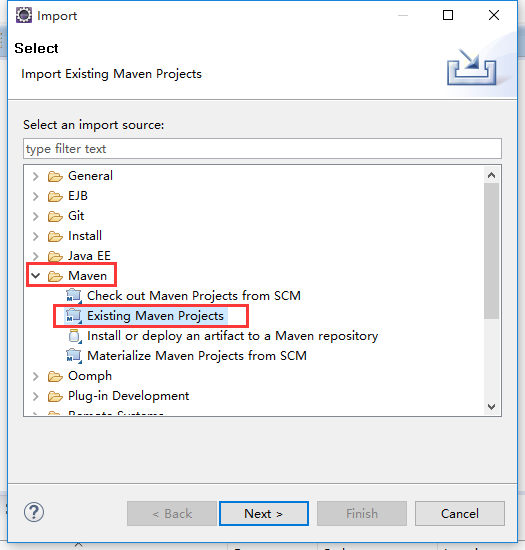
5,导入项目
点击finish即可,安静等待,maven下载项目所需要的jar文件
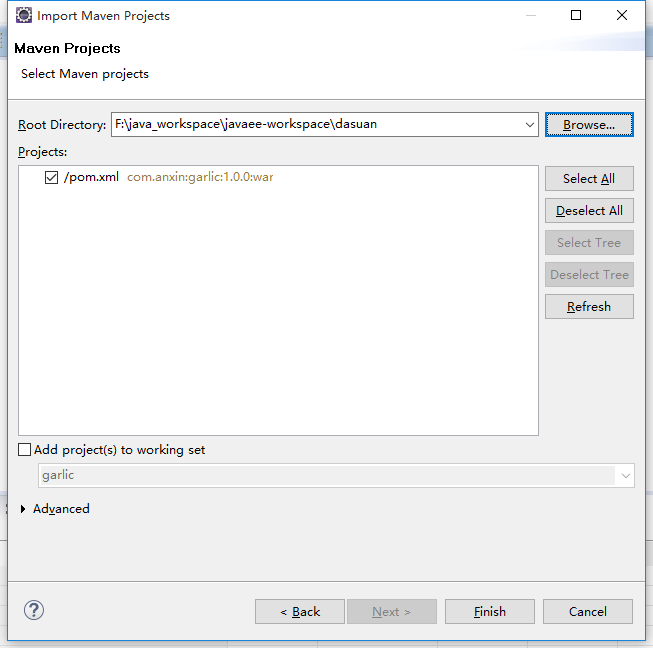
6,导入完成
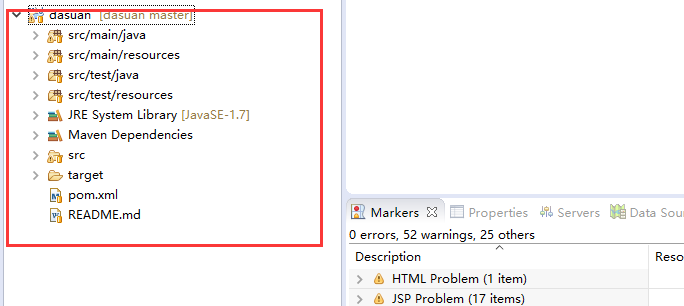
注意:
1,导入项目如果不修改setting.xml镜像位置,下载过程可能会很漫长,但是千万不要在下载过程中关闭eclipse,这样很可能会引起,maven工程所需的jar文件不完整,再次导入的时候报错。(这是我深刻的领悟,我关掉之后,再次导入的时候总是出现jar文件缺失,项目导入失败,折腾了一天,起初还以为是maven插件版本和我的eclipse不匹配,eclipse都不知道换了几个版本,差点把jdk从1.6试到1.8)
2,最好还是配置一下maven的镜像,能事半功倍(很重要)
3,maven的本地仓库默认在C盘下(随着jar文件的增多,占用C盘的存储空间也会变大),看起来很不爽。不设置也没问题,在eclipse中只需要配置maven的路径就能用,连配置环境变量都省了。虽然看起来不太专业,但是这样确实挺方便。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/138129.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
