大家好,又见面了,我是你们的朋友全栈君。
Academic social networks: Modeling, analysis, mining and applications
摘要:
在快速增长的学术大数据背景下,社交网络技术最近引起了学术界和工业界的广泛关注。学术社会网络的概念正是在学术大数据的背景下产生的,指的是由学术实体及其关系形成的复杂的学术网络。有大量的学术大数据处理方法来分析学术社交网络丰富的结构类型和相关信息。现在各种学术数据都很容易获取,这让我们更容易分析和研究学术社交网络。本研究调查了学术社交网络的背景、现状和趋势。我们首先阐述了学术社会网络的概念和相关研究背景。其次,基于节点类型和时效性分析模型。第三,我们回顾分析方法,包括相关的指标,网络属性,和可用的学术分析工具。此外,我们还梳理了一些学术社交网络的关键挖掘技术。最后,我们从行动者、关系和网络三个层面系统地回顾了该领域具有代表性的研究任务。此外,还介绍了一些学术社交网站。本调查总结了当前的挑战和未解决的问题。
关键词:
学术社交网络、科学的科学、学术数据、学术应用
1.介绍
在Web 2.0的背景下,学术界和工业界进行了大量的研究,产生了大量的学术信息(吴等,2014)。学术投入和产出为研究科学的结构和演变创造了前所未有的机会(Fortunato等人,2018年)。随着科学技术的迅速普及和发展,数据正逐步从传统的存储模式向数字存储模式转变。学术信息基本上以科学文件、技术报告、项目提案、论文和其他类型资源的形式生成(Khan等人,2016年)。此外,来自世界各地的学者和研究人员不仅可以产生大量的学术文件,还可以通过专利和幻灯片等教育材料(夏等人,2017年)分享他们的研究成果。学术大数据(SBD)一词是由快速增长的学术资源产生的。
1.1 学术大数据
由于学术实体及其关系的快速增长,学术数据达到了“大数据”的“5V”特征,即容量、速度、多样性、价值和准确性(吴等,2014),这被称为学术大数据()。它包括会议论文、期刊文章、书籍、专利、幻灯片和实验数据等(Williams等,2014b)。有效利用SBD不仅对于学者了解科学发展和学术互动,对于决策者更好地解决资源共享问题具有重要意义,而且对于企业引导发展方向也具有重要意义。因此,如何从数百万SBD人中挖掘有价值的信息是一个紧迫的问题。
SBD分析的目的是在科学学的背景下解决学术问题。对SBD的深入分析不仅能使研究者更有效地利用现有资源,而且有助于学术界和工业界的发展。然而,对这一课题的系统研究还不够。以前,研究人员很难获得有效的学术信息,因为现有的工具和技术不满足SBD分析的要求。此外,的高维数和大尺寸给数据分析带来了一定的挑战(范等人,2014年)。然而,随着互联网的日益普及和相关分析技术的发展,我们现在可以充分利用这些有效信息。一系列在线数字图书馆
和学术服务平台,例如,AMiner,微软学术搜索(MAS),DBLP,谷歌学术(GS),美国国家科学与技术研究院,s . t . o .关于作者,出版物,引文和其他相关信息的数百万数据(Arif,2015)。SBD分析可以分为合作者搜索、研究管理、专家发现系统和推荐系统(汗等人,2016)
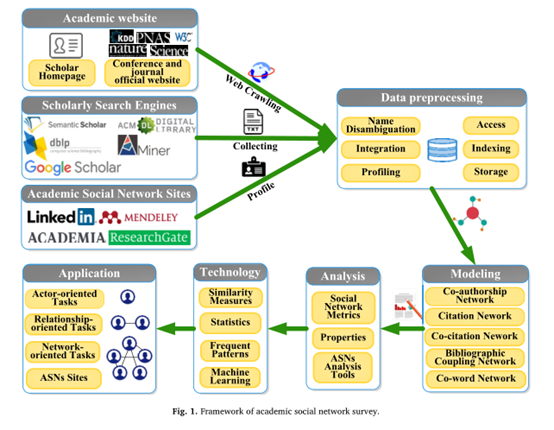

图1 学术社交网络框架
1.2. 社交网络
社会网络分析是近年来流行的一种技术,在许多领域发挥着越来越重要的作用,如社会媒体网络、交通网络(如交通控制)、流行病学网络(如流行病传播模型)和网络网络(如构建万维网结构)。它不仅用于分析Twitter和Facebook等在线社交媒体应用,而且还提供科学研究领域的综合服务。社交网络(SNs)是在协作和社会化等特定情况下相互关联的个人或组织的集合。在SNs中,节点和边分别用来表示实体及其交互,帮助我们分析和挖掘信息。对SNs的分析可以识别信息传播过程中形成的网络关系。
SNs分析方法是研究SBD的有效方法。在学术网络中,研究人员通过各种学术活动建立关系(Fu et al.,2014)。目前,关于SBD各实体之间不同的交流模式的研究引起了研究者的极大兴趣(Luo和Hsu,2009)。此外,数据分析技术的进步和SNs可视化软件的最新发展促进了这些关系以及动态显示的研究(Luo和Hsu,2009)。
1.3. 学术数据中的社交网络
科学科学(SciSci)将科学描述为一个复杂的、自组织的和不断发展的学术信息网络(Fortunato等人,2018)。在SBD中,通过学术活动和信息形成的社会网络称为学术社会网络(ASN)。这种表达方式可以从不同的地理和时间尺度来研究asn,以表征新科学领域的模式,加速科学的发展。建立ASN的方法有很多种,其中合著者是最正式的学术活动形式(Fu et al.,2014)。通过对引文网络的研究,可以揭示研究者在职业生涯中的选择与取舍,这也是SciSci的研究课题之一。此外,一些研究表明,联系良好的学术社交网络往往更为丰富(Lopes et al.,2011),因此我们必须对其进行研究。
目前,在很多领域都有很多使用SNs的调查,例如异常检测(Kaur and Singh,2016)、社交媒体中的签名网络挖掘(Tang et al.,2016)、移动社交网络(Hu et al.,2015)、车载社交网络(Rahim et al.,2017)和社交网络中的社会影响力(Peng et al.,2017)。,2018年),但没有与SBD相关的SNs概述。同时,也有一些关于SBD的调查。Khan等人(2017b)调查了当前学术数据的研究趋势,确定了学术数据平台发展面临的挑战,并将未来的研究方向映射到大数据生命周期的不同阶段。夏等(2017)从学术数据管理、学术数据分析方法和代表性研究问题几个方面对学术大数据进行了全面综述。目前,还没有研究对ASNs进行全面的综述。
在这项工作中,我们提出了一个流行的新兴ASN领域的调查。据我们所知,这篇论文是第一篇使用SNs分析对SBD进行全面综述的论文。我们从建模、分析、挖掘技术和应用四个方面系统地总结了ASNs中的主题。此外,我们还简要介绍了一些有用的ASNs工具和流行的网站。我们的目标是全面解读ASNs的研究现状,了解未来研究的机遇和挑战。
本文的框架如图1所示。第2节阐述了asn的定义和特性。第3节介绍了ASN的建模方法。第4节阐述了ASNs分析,第5节介绍了ASNs中的一些关键采矿技术。第6节描述了一些有前途的研究应用和有用的ASNs站点。最后,第7节讨论了关键的开放性问题和挑战性问题。
2学术社交网络
在本节中,我们将详细阐述学术社交网络的概念、典型实体及其关系以及可用的学术数据集。
2.1. 定义
学术社会网络(ASN)是由大量实体(出版物、学者等)及其关系(引文、合著者等)形成的复杂异质网络(Tang et al.,2008;Wu et al.,2014)。学者们开展了大量的研究课题和数据挖掘任务。以下是一些例子,作者排名(Amjad et al.,2015,2017),作者兴趣发现(Daud,2012),新星发现(Daud et al.,2013,2015),学术建议(Guns and Rousseau,2014)和社区发现(Khan et al.,2017a)。对ASNs的关注导致许多ASNs站点提供SBD收集和分析。例如,MicrosoftAcademic和GoogleScholar提供论文搜索,CiteULike专注于引文关系服务。基于各种各样的网站,我们可以很容易地在网上获得SBD信息。
2.2. 学术实体与关系
图2提供了ASN中的典型实体和关系。节点通常表示学术实体,包括作者、出版物、场所、机构和术语(从论文的内容、摘要或关键词中提取)。不同类型的实体具有不同的属性或标签,可以帮助我们更丰富地分析它们。实体之间的链接通常表示关系,包括合著者、引文、联合引文、书目耦合和联合词。每种类型的关系都可以形成不同的网络,为研究互动和学术交流带来一系列的视角。合作作者侧重于寻找交流模式、书目耦合、共引和共词关系,这些关系强调确定研究主题,而引文关系则更注重知识流的转移。
2.3. 学术语义本体论
语义出版是一种增强语义的期刊出版形式(Shotton,2009)。它通过Web和语义Web技术丰富了出版物的表达形式和知识内容。它还可以提高出版信息的可操作性、相关性和交互性,最终实现智能出版。本体是对共享概念系统的正式和详细描述(Peroni和Shotton,2012)。因此,研究者可以利用本体技术实现对文档对象及其知识内容的语义描述,进而开展丰富的研究工作。表1简要描述了一些常用的本体。
表****1 学术语义本体论的基本特征 。

表****2 现有学术数据集的基本特征
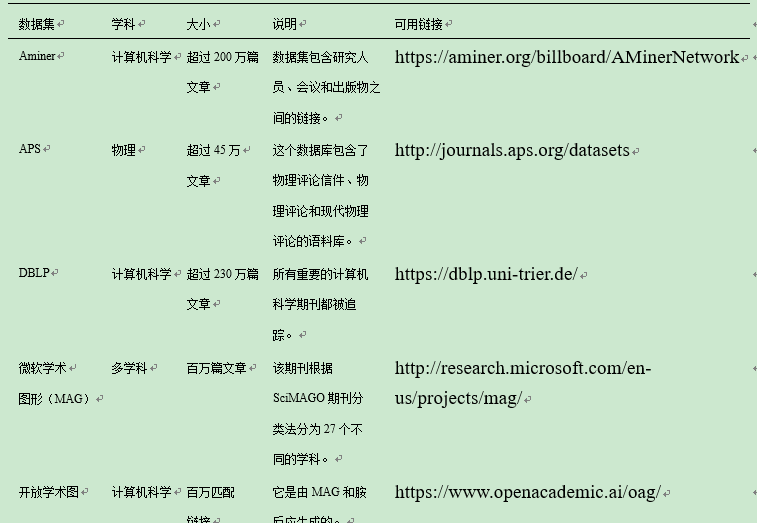
2.4. 可用学术数据集
目前,有许多搜索引擎和数字图书馆提供他们的数据集,以帮助研究人员研究asn。学术数据集是包含许多类型的一般数据的综合学术文档。其中许多是免费下载的,如AMiner,美国物理学会(APS),DBLP,微软学术图(MAG),开放学术图和开放研究语料库。我们在表2中列出了这些数据集的一些基本特征和可用URL。我们可以从书目数据库中获取这些实体,这些数据库包含有关出版物(如作者、所属单位、页数、年份)及其引用出版物(如引用的参考文献、引用次数)的元数据。图2显示了典型实体及其关系。
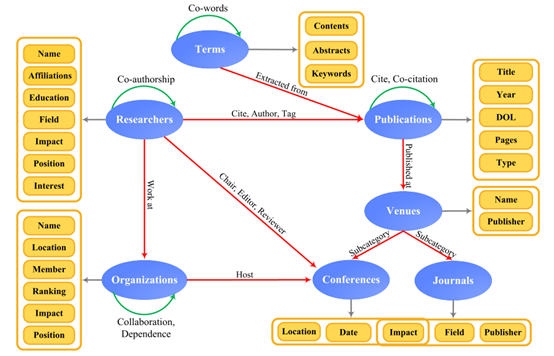
**图2。**典型实体及其关系 。
3 学术社交网络建模
学术社会网络可以以各种拓扑结构构建。学者的学术社会行为可能会随着时间的推移而改变。在静态网络中,节点从不崩溃,边缘保持工作状态。学者们发现,静态网络可以带来稳定的高水平合作(Rand等人,2014)。随着网络数据规模的不断扩大,网络结构变得越来越复杂。因此计算时间和复杂度同时增加。因此,Benson等人(2016)使用了基于子网的graphlet,并开发了高阶连通模式的通用框架。大多数情况下,现实世界的网络是动态的。在动态网络中,节点或边可能出现或消失,使得动态网络拓扑结构随时间而变化。动态网络被广泛使用,因为它们可以描述成分和相互作用(兰德等人,2011年)。另一个重要原因是ASN本身是动态的。大量的研究者通过对动态网络结构的探索,取得了重要的成果。研究发现,重复的积极互动可以促进个体之间和群体内部的合作。然而,动态asn的拓扑结构难以描述,建模困难。
不同类型的网络适合于建模不同的关系。根据网络中节点的不同,学术社交网络可分为同质学术社交网络和异质学术社交网络。
3.1. 同质学术社交网络
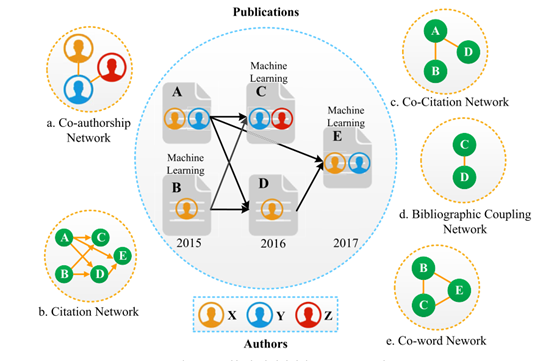
**图3。**典型的学术同质网络 。
同质asn是指那些节点代表相同实体的网络。例如,在图3中,图的中心是论文关系的toy模型的示例,其周围是从中提取的几个典型asn。图3a是合作作者网络,其中X和Y共同撰写论文A和论文E,Y和Z共同撰写论文C。图3b是引文网络,其中论文通过直接引文链接连接。先发表的论文被后发表的论文引用,即先发表的论文向后发表的论文划出箭头。图3c是toy模型的共引网络,其中A和B是C和D的共引,A和D是E的共引。图3d是书目耦合网络。我们可以看到C和D是书目耦合的,因为它们都引用了A和B。图3e是共词网络,而B、C、E都属于机器学习领域。
3.1.1合著网络
合著网络是应用最广泛的asn之一。在图3a的合著者网络中,合著者网络中的每个节点表示作者。合著网络中的边缘是指合著关系。学者们从不同的角度研究合作作者网络。事实证明,合作继续影响研究实践和知识生产,在不同学科中越来越流行(Uddin等人,2013)。协作在几乎所有学科中都变得越来越普遍。此外,随着信息技术、交通运输和通信的发展,科学家不再需要在同一地点,科学合作可能跨越大学边界(Jones et al.,2008),甚至跨越国家边界(Wilsdon et al.,2011)。学者们根据合著者网络研究合作行为。此外,合作团队已被发现是一种新的研究模式。
3.1.2联合引文网络
共引是指在一篇文章中同时引用的两种出版物。共引网络是基于文章的引文关系构建的。显然,共引网络是定向网络,因为两篇论文不能同时引用对方。学者从出版物中生成共引网络,从共引网络中研究学者的行为。Bai等人(2016)研究了共引网络,并确定了异常引用关系。事实上,有些学术社会关系可能不是通过合著者网络发现的,而是可以通过合著引文网络发现的。共引分析是最常用的文献计量分析方法之一。当两个出版物经常被其他文章共同引用时,这两个参考文献可能有共同之处。共引分析作为一种先进的书目分析技术,通常被用来发现共引对的聚类,使学者们对研究趋势有了新的认识。尽管共引分析在显示学科结构方面优于其他文献计量学方法,但要提供有关文献的研究主题的内容描述仍然很困难。
3.1.3 联合词网络
共词分析已经发展到解决这种分析问题(Leung等人,2017)。基于共词网络实现了共词分析,反映了共词的出现频率。关键词共现频率是指两个关键词同时出现的论文数量。通过测量关键字共现链接的强度,共现分析揭示并可视化关键字之间的交互作用。由于关键词是用来描述一篇研究文章核心内容的术语,所以共词分析常常被用来探讨某一特定学科的研究主题和趋势的概念网络。然而,coword分析也有其弱点,即随着时间的推移,期限变化会导致不稳定性。
3.2. 异质学术社交网络
异构asn是指节点代表不同实体的网络。图4示出了异构网络的示例。在图4中,节点分别表示机构、作者、出版物和场所。所有这些实体都是一个网络中的节点,构成了这个异构网络。异质asn被广泛用于分析不同学术实体之间复杂的社会关系。在当前大多数网络科学研究中,社会和信息网络通常被认为是同质的,其中节点是相同实体类型的对象(如学者),链接是相同关系类型的关系(如合著者)。有趣的结果已经产生了许多有影响力的应用,如社区检测方法的研究。怎么做-
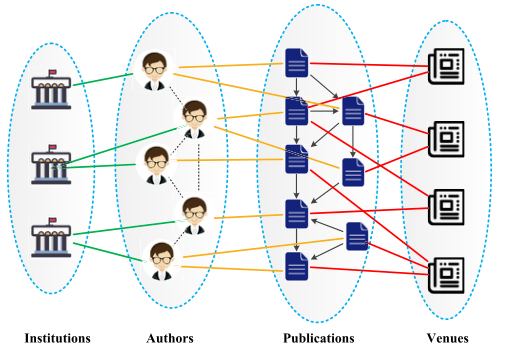
**图4。**异构网络的一个例子。
然而,大多数asn是异构的,节点和关系是不同类型的。
3.2.1论文作者网络
论文作者网络的构建是为了分析论文与学者之间的关系(孙和汉,2013)。许多论文作者网络的建立是为了向目标学者推荐合适的论文。一般来说,学者从书目数据库中提取信息,构建论文作者网络。这些网络包含异质信息,包括文章、作者、共引等。通过分析论文-作者网络,可以探索显性和隐性引用关系。
3.2.2书目耦合网络
书目耦合是一种广泛应用的方法,用于科技论文的分组。当两篇文章引用同一个参考文献时,它被定义为两篇文章之间耦合的基本单位。两篇文章之间的耦合强度是根据耦合单元的数量来衡量的,这意味着当两篇文章引用相同的参考文献时,这两篇文章在一定程度上是相关的。这种联系的强度是由耦合的频率决定的。引文网络的研究主要集中在学术文献的引文方面。为了探索情报学领域的发展变化,Huang et al.(2003)根据书目耦合度量了引文之间的关联,然后对引文进行聚类。Börner等人(2003年)通过共引分析探索了这一领域的发展和趋势。学者们可以利用共引关系对被引文献进行聚类,研究书目引文以及这些聚类之间的关系。
3.2.3混合网络
混合方法被广泛应用于确定研究主题。Liu等人(2010)提出了一个混合聚类的框架,以结合词汇和引文数据进行期刊分析。Zitt等人(2011年)研究了两种主题映射方法的收敛性,即基于引文和基于单词的方法。Boyack和Klavans(2010)研究了几种类型的学术网络,包括联合引文网络、书目耦合网络和引文网络,旨在选择最能代表生物医学研究趋势的网络。Janssens等人(2009)提出了一种新的混合方法,该方法整合了两种类型的信息,分别是引文(以文献矩阵的术语形式)和文本(以文献矩阵的引用文献形式)。
4学术社交网络分析
ASNs的模型是用来表示网络的,而度量主要用来分析网络。在本节中,我们将整理一些网络指标和由asn触发的SNs分析中使用的流行指标。此外,利用社交网络的共同属性也有助于我们更多地了解学术社交网络。
4.1. 社交网络指标
在这一部分中,我们简要梳理了一些通用的社交网络指标。这些指标使我们能够洞察网络结构,而不必知道其图形表示。探索这些网络的结构旨在了解产生这些学术网络的社会系统的行为,这通常是此类分析的最终目标。
4.1.1. 全局指标
有许多指标可以用来探索整个网络的属性。
**直径。**在网络中,节点i和节点j之间的距离dij表示连接这两个节点之间最短路径的边的数目。直径D是指网络的最大偏心率,它描述了最大距离(Yan等人,2010)。用式(1)表示:
**密度。**密度是指测量一个全球网络的连通性,其计算方法是将存在的连接总数除以具有相同节点数的可能连接总数,如等式(2)所定义:
,其中E是网络的边数,Emax是具有相同节点的可能边数。对于有向网络,
**平均最短路径长度。**网络的平均最短路径长度L是任意两个节点之间最短路径的平均长度(Yan等人,2010),表示为式(3):
**调和平均最短路径长度。**当一个网络有多个连接的组件时,前面的公式不成立,因为当没有连接两个节点的路径时,度量通常被定义为无穷大。在这种情况下,我们可以使用调和平均最短路径长度,如公式(4)所示,当它将无限距离变为零时,可以抵消它们对和的影响:
**平均学位。**网络的平均度数⟨⟩是所有节点的度数ki的平均值,如式(5)所示:
它用来反映网络的全球连通性。
4.1.2. 社区指标
研究人员可以通过多种方法来识别网络中的社区。这里我们介绍两个最经典的指标。
**核心。**core度量可以识别整个网络中相互联系紧密的组。K-Core是最大的实体组,其所有节点至少与该组中的其他K个节点相连。K-Core有助于识别较小的互联核心区域。链接的节点独立于它们可能连接到组外部的其他节点。k的值有时被称为
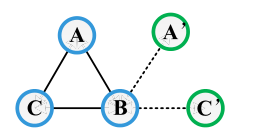
**图5。**一个封闭和开放三胞胎的例子。
一群人。例如,如果所有节点都与组中至少两个其他节点相关联,则此组为双核组。
**派系。**团的度量定义为所有节点直接相邻的最大节点集。在ASNs中,我们可以知道一个集团是一组作者,所有的作者都和其他作者一起写论文。因此,最大的派系将被确定为那些与许多合著者撰写特别文章的人。
4.1.3. 节点度
节点度定义为相邻节点的个数,公式如式(6)所示:
4.1.4. 聚类系数
一个集群意味着任何两个学者之间存在合作,图5显示了玩具三胞胎的构造。因此,如果节点A连接到节点B并且节点B连接到节点C,则节点A也将连接到节点C的概率增加。聚类系数分为局部值和全局值。
**局部聚类系数。**局部聚类系数表示节点邻域的内聚程度。计算局部聚类系数的常用方法如公式所示。
**全局聚类系数。**全局聚类系数度量整个网络的聚类,可以用于有向和无向网络,但不能用于加权网络。公式如式(8)所示:
4.1.5. 中心性
度、贴近度、介数和特征向量中心度是计算节点中心度的基本方法(Wasserman和Faust,1994)。玩具模型如图6所示,其中最重要的节点根据这些中心性进行标记。PageRank的度量是从网页排名中移植出来的。我们将详细描述这五个不同的指标。
**度中心性。**它是所有中心性中最简单的,它是根据节点的邻居数计算的。它代表了网络节点的互联性,反映了节点的通信活动。它通常通过将节点的度数除以n-1来计算,将值限制在[0,1]的范围内。由式(9)计算:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oMXOb7s7-1620524119875)(file:///C:/Users/ADMINI~1/AppData/Local/Temp/msohtmlclip1/01/clip_image016.jpg)]
**接近中心性。**它用于测量从一个节点到所有其他节点的最短路径的平均长度,表示为Eq。
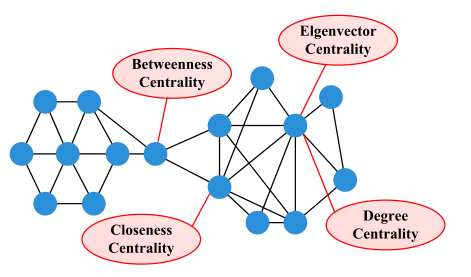
**图6。**合作作者网络的一个例子。
它一般用于网络中最大的组成部分,并考虑连接网络中的所有其他节点。在ASNs中,贴近度中心性是一个能达到的指标,反映了从一个节点到另一个节点的时间。
**中间性中心性。**中间性中心性用来描述节点为了到达其他节点而必须经过的范围。在asn中,具有高介数中心性的节点起着桥梁的作用,在一定程度上控制着网络中的信息流。表示为式(11):
其中()表示节点s和t到节点i之间的最短路径数,是节点s和t之间的最短路径数。
**特征向量中心性。**特征向量中心性是反映节点重要性的另一个度量。该方法根据高分节点对节点得分的贡献大于低分节点的原则,给出了各节点的相对得分。它是利用等式中的邻接矩阵来计算的。
(12):
式中,Aij表示网络中邻接矩阵的第i个特征向量。
**页面排名。**PageRank最初用于谷歌的网页核心排名机制(Page et al.,1999;Brin and Page,2012)。它通过计算使用度链接的节点的权重来发现重要节点,这意味着由这些节点链接的其他节点也具有更高的页面排名。PageRank由公式(13)计算:
其中N表示网络中的节点总数,Kout是节点r的向外度,ri表示节点r的向内度,是阻尼因子。
4.2. 属性
对于asn,这些网络有一些共同的特性。
4.2.1. 幂律度分布
度分布是指节点度在整个网络中的概率分布,用P()表示。在随机网络中,度分布是高度均匀的,因为每个边的存在是等概率的。与随机网络不同的是,Barabási和Albert(1999)发现真实网络中节点的度分布是异质的,如引文网络,其中大多数节点的度分布是不均匀的k
节点具有较低的度数,很少节点具有较高的度数。他们指出,真实网络的度分布近似服从幂律分布。有时,我们将这些网络称为无标度网络(Barabási和Bonabeau,2003)。此外,他们开创性地设计了一个称为Barabási-Albert模型的网络增长模型,这是我们所知道的关于优先依恋的过程。
4.2.2. 小世界地产
Travers和Milgram(1977)通过著名的Milgram实验指出了现实社会网络的小世界特性,并明确解释了“六度分离”的概念。现在已经证明,小世界特性在现实世界中是普遍存在的。在SNs中,小世界特性表示节点之间的平均最短路径长度与固定的平均网络大小成比例(Newman,2003b)。在ASNs中,这个特性表明两个不合作的研究者可以通过他们的一系列合作者联系。
4.2.3. 混合模式
在许多网络中有不同类型的节点。在这些网络中,节点到节点的链接往往是选择性的,并且与节点的类型(例如论文、作者和地点)高度相关。真正的网络往往表现出更高的混合倾向。Newman(2003a)提出了一个称为分类系数的度量标准来度量网络中的混乱程度。
4.2.4. 社区结构
由于网络中边缘分布的异质性,产生了社区结构的性质。社区可以定义为一组相似的节点(Newman和Girvan,2004)。因此,我们通常在网络的某些区域发现高密度的边,而这些区域之间的边密度较低。大多数真实网络都表现出社区结构的特征。在ASNs中,我们可以根据学者之间的相似性将他们划分为不同的群体,并分析群体之间的关系。
4.3. 学术社交网络分析工具
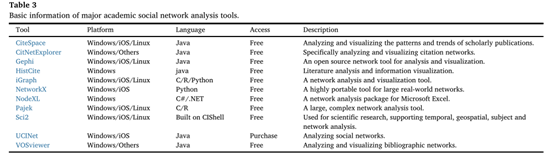
由于SBD的容量很大,asn的类型也很多,手工处理需要花费大量的时间和精力。我们可以使用分析工具通过使用网络特性来构建、分析和可视化ASN。ASNs分析工具的功能是多方面的,例如,网络特征化、关系挖掘、社区检测和可视化。现在,有很多工具,例如CiteSpace(Chen,2004)、CitNetExplorer(Van Eck和Waltman,2014)、Gephi(Bastian等人,2009)、HistCite(Garfield和Pudovkin,2004)、iGraph(Csardi和Nepusz,2006)、NetworkX(Hagberg等人,2008)、NodeXL(Smith等人,2009)、Pajek(Batagelj和Mrvar,2004)、Sci2(Team,2009)、UCINet(Borgati)VOSviewer(Van Eck和Waltman,2011年)。在这里,我们在表3中简要描述了有关这些工具的信息。
表****3 主要学术社交网络分析工具的基本信息 。
5****挖掘关键技术
学术社会网络挖掘是学术社会网络分析的一个重要子任务。它旨在挖掘学术社会关系,即实体之间的联系。随着可用数据和发展中技术的出现,最近的趋势集中于挖掘相互关系。从数据挖掘和SNs挖掘的角度,我们将ASNs挖掘的度量分为以下四类:
•相似性度量
•统计关系学习
•图形挖掘
•机器学习
这些技术通常用于社会网络中的关系抽取,并且可以根据网络隶属关系在学术社会网络中实现。更具体地说,它们可以很容易地在社区检测、关系挖掘和链接预测中实现。图7提供了这些方法的主要分类及其在学术社交网络中的应用。
5.1. 相似性度量
相似性度量用于度量网络中实体之间的相似程度。当前多关系社会网络中相似性模型的研究主要集中在两个方面:基于内容的算法和基于链接和结构的算法。
5.1.1. 基于链接和结构的方法
现有的网络挖掘研究大多基于经典算法PageRank(Page等人,1999)和SimRank(Jeh和Widom,2002),它们在排序过程中使用随机游走技术。随机游走方法的目的是估计通过每个节点的概率。因此,连接良好的结构在网络中具有较高的PageRank分数。这些算法及其应用广泛应用于ASNs中的协作模式挖掘和推荐(Strohman et al.,2007;Lüand Zhou,2011;Li et al.,2014)、新星发现(Daud et al.,2013;Li et al.,2009;Zhang et al.,2016)和科学评估(Chen et al.,2007;Zhou et al.,2012;Wang et al.,2013b)。
5.1.2. 基于内容的方法
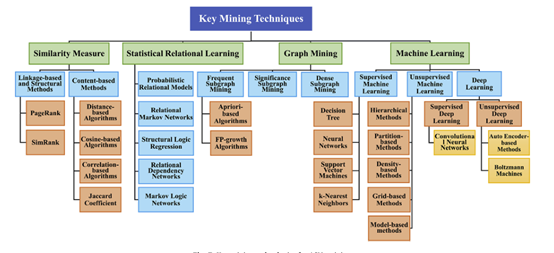
**图7。**ASNs采矿的关键采矿技术。
在基于内容的分析中,最著名的方法是基于距离的算法、基于余弦的算法、基于相关性的算法和Jaccard系数。Minkowski距离、Chebyshev距离、Manhattan距离和Euclidean距离被广泛用于计算距离相似性,并将具有共同特征的实体聚类到不同的组中。这些方法已经成为一种很有吸引力的方式来使用关于项目本身的信息,并在学术建议和分析中提出建议(Ding等人,2014)。
5.2. 统计关系学习
Traves和米尔格拉姆(1977)为大规模网络中结构性质的广泛分析奠定了基础。统计特性在各种典型的社会网络中表现出不同的特点。通过大规模研究这些网络的特性,我们可以深入研究节点间的连通性行为以及网络结构如何随网络演化而变化。
统计关系学习将统计方法的理论与数据表示相结合。它集中于数据的联合概率分布。现阶段对统计关系学习的研究主要集中在学习关系数据中的概率模型所带来的挑战。特别地,研究者提出了三个特征,包括集中联系、程度差异和关系自相关,来建立统计关系学习模型。集中的直线表示不同类型对象之间的连接存在显著的不一致性。度差是由不同类型物体的不同程度产生的。关系自相关是同一属性在不同分支中的相关值。
基于上述特征,典型模型包括概率关系模型(PRM)(Koller,1999)、关系马尔可夫网络(RMN)(Taskar等人,2007)、结构逻辑回归(SLR)(Popescul和Ungar,2003)、关系依赖网络(RDM)(Neville和Jensen,2007),马尔可夫逻辑网络(MLN)(Richardson和Domingos,2006)。这些统计学习模型是为关系数据建立的,对于描述网络和完成分析任务非常有用。
5.3. 图挖掘
图挖掘作为网络挖掘的一个重要方面,近年来受到越来越多的关注。它是指利用图形模型从海量数据中发现有用知识和信息的过程。在ASNs中,它可以应用于链接分析、组检测、元数据挖掘等各个方面。
频繁子图挖掘是图挖掘中一个非常活跃的研究课题。相关方法包括基于Apriori的算法(即AGM(Abramowitz et al.,1966)、ACGM、path join(Li et al.,2001)。等)和FP-growth算法(即gSpan(Yan and Han,2002)、CloseGraph(Yan and Han,2003)、FFSM(Huan et al.,2003)。等等)。它们逐渐扩展频率,得到边缘扩展略有不同的频繁子图。此外,Wang等人(2005)提出了一种基于索引的频繁子图挖掘算法GraphMiner,用于从大型磁盘图形数据库中挖掘频繁模式。对于动态图挖掘,Borgwardt et al.(2006)为时间序列图的静态图的现有模式挖掘设计了DynamicCrew。其他图挖掘算法包括重要子图挖掘(Sugiyama et al.,2015)和稠密子图挖掘(Gunnemann et al.,2010)。
这些算法通常用于提取和分析ASN中实体之间的关系,例如,社区挖掘、科学模式揭示(He et al.,2012)和影响预测(Pobiedina and Ichise,2014)等。
5.4. 机器学习
学术社交网络挖掘的机器学习方法主要涉及有监督技术和无监督测量。在监督域中,关系任务的目标是基于实体对的提及来提取一组已知的关系。学习需要大量的训练数据。相反,无监督任务侧重于预测给定实体的哪个关系类超出了给定的标签。深度学习也是机器学习的一个重要分支。因此,我们将关键的挖掘技术分为以下几类:有监督学习、无监督学习和深度学习。
5.4.1 监督学习
传统的监督学习方法可分为两类:基于特征的方法和基于核的方法。基于相关理论,ASNs中的挖掘任务一般被认为是一个分类问题。有监督学习有太多的分类模型,如决策树、神经网络、支持向量机和K近邻。回归模型(Herlocker等人,1999)也可用于关系分类。这些方法的性能依赖于特征选择和参数设置。例如,Akritidis和Bozanis(2013)通过引入机器学习算法解决了论文自动分类的问题。他们将作者、合著者、关键词和已发表的期刊与许多分类学标签联系起来。XGboost(Chen和Guestrin,2016)是近年来提出的一种机器学习模型。其预测能力在某些方面优于支持向量机和神经网络。其缺点是需要大量的调整参数。Bai等人(2017b)使用XGboost模型综合个人能力、制度位置和国家GDP的特征,预测制度的影响。
5.4.2 无监督学习
在实际应用中,有监督学习过程往往需要精确的标签,这将需要花费大量的时间和精力来生成数据集。不标注数据集的学习称为无监督学习,在关系抽取中通常被认为是一个聚类问题。已经开发了一些技术来识别类似的实体。到目前为止,一般的聚类算法有五种,包括层次方法、基于划分的方法、基于密度的方法、基于网格的方法和基于模型的方法,其中最常用的是层次方法和基于划分的方法(Han等人,2011)。基于划分的算法通过优化评价函数将数据集划分为k个部分,需要研究者确定k作为输入的值。基于划分的方法中的典型算法有K-means、K-medoids(Park和Jun,2009)和CLARANS(Ng和Han,2002)。
分层方法由不同层次的分割聚类组成,层次之间的分割具有嵌套关系。它不需要输入参数,这是与基于分区的方法相比的一个明显优点。然而,研究者需要明确终止条件。典型的分层算法包括BIRCH(Zhang等人,1996)、DBSCAN(Birant和Kut,2007)和CURE(Guha等人,1998)。
尽管无监督学习的性能不如有监督学习,但它可以从大样本集中选取代表性样本进行分类器训练,并通过将样本划分为不同的类别进行人工标注来帮助分类。
5.4.3. 深度学习
深度学习是一种重要的基于数据表示的机器学习方法。与机器学习方法一样,它也包括有监督学习和无监督学习。监督学习下的典型算法是卷积神经网络(CNN)(Krizhevsky等人,2012)。无监督深度学习主要分为两类。一种是基于autoencoder(Rifai等人,2011),其主要目标是将抽象数据还原为一块原始数据。其他的是基于玻耳兹曼机器(Aarts和Korst,1988)。这些算法的主要目标是在机器达到稳定状态时再现原始数据。
6应用
ASNs在学术互动与交流的相关研究中有着广泛的应用。我们不关注算法,而是强调一些已有的新思想和新方法。在本文中,我们从三个方面简要介绍了这些应用程序:面向角色的应用程序、面向关系的应用程序、面向网络的应用程序,如图8所示。最后,我们总结了一些有用的ASNs站点。
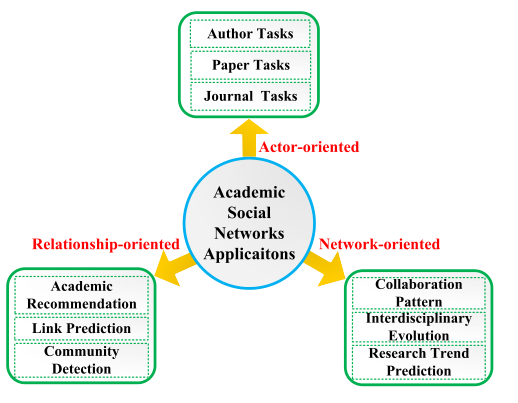
**图8。**学术社交网络的应用 。
6.1. 面向参与者的应用程序
面向角色的应用包括很多方面,我们从作者、论文和期刊三个方面进行了阐述。
6.1.1. 作者级任务
作者是ASNs中的一个重要实体,作者之间的关系复杂。我们回顾了近年来的一些热门研究。
**作者姓名消歧。**作者姓名消歧仍然是文献检索和数据处理中的一个难题(Tang和Walsh,2010)。一个名字可以表示几个不同的作者,一个作者可以搜索多个名字。一些研究表明,作者姓名的模糊性可能会导致对聚类系数等网络属性的强烈偏见(Kim和Diesner,2016)。当我们提取作者信息时,我们需要进行预处理,以消除与作者姓名相关的固有歧义。基本上,有三种方法可以消除模棱两可的名称:基于算法的方法、第一初始方法和所有初始方法(Khan et al.,2016)。Treeratpituk和Giles(2009)使用随机森林模型,通过考虑作者的姓名、隶属关系、合作者和相关因素来消除名称的歧义。基于一个作者可以被他的合著者识别的假设,Kang等人(2009)提出了一种通过目标作者的隐含合著者消除歧义的方法。此外,Kim等人(2014)将上述三种方法用于DBLP数据集消除歧义,发现作者姓名消歧对有效分析数据有显著影响。Cota等人(2010)提出了一种基于合作作者网络中引文信息(如标题)相似性的名称消歧方法。
**作者排名。**基于网络链接结构的作者排序方法可分为两类:迭代法和非迭代法。首先,迭代方法迭代执行指令,直到算法收敛。PageRank(Brin and Page,2012;Page et al.,1999)和HITS(Kleinberg,1999)算法是两种基本的迭代算法,很多作者排名方法都是基于这两种算法思想。Fiala等人(2008)使用修改后的PageRank在书目网络中获得学者排名。Ding等人(2009);Yan和Ding(2011)考虑了网络中边的权重,提出了一种研究引文网络和合著网络的加权PageRank方法。Li和Tang(2008)考虑了时间统计,并将社会网络与随机游走模型相结合。Radicchi等人(2009)提出了一种加权PageRank方法,通过考虑作者的信用扩散。Ding(2011)引入了主题权重,提出了PageRank算法的主题敏感扩展。Amjad等人(2015)在异质学术网络中使用了基于主题的模型。此外,研究人员还通过考虑拓扑特征不断丰富作者排序方法。一般认为,如果一个学者在ASNs中处于某个关键位置,他/她就可以被认为是重要的。Chiang et al.(2013)利用社会关系和本地信息,基于随机游走的概率模型,在合著网络中找到前k名作者。
**专家发现。**信息检索学科受到越来越多的关注,对某一特定领域专业人员的搜索被称为专家发现(Serdyukov,2009)。专家发现是一个以组织为中心的概念,旨在确定具有相关专业知识或丰富经验的人员。基本上,有两种方法:基于内容的方法(Chen et al.,2013),通过测量相关文档和查询之间的相关性来评估学者的专业知识;基于SNs的方法(Kardan et al.,2012),更关注学者在ASN中的社会互动,比如合著和引用关系。我们强调后一种方法,它与本文的主题相关。Noll等人(2009)提出了一种基于命中的方法,通过分配不同的权重来链接用户和文档。为了整合异质信息,Nie等人(2005)提出了PopRank模型,表明作者的得分来源于不同类型对象的综合得分。Sun等人(2009)在异构网络中提出了一种基于ranking的聚类方法,该方法以聚类为目标,同时对聚类中的对象进行排序。Deng等人(2012)提出了一个联合正则化框架,通过将异构网络建模为以文档为中心的正则化约束模型来增强专家发现。Yang et al.(2013)为专家推荐提供了个人社会网络、研究相关性和组织连通性等信息,以扩大研究范围,提高推荐的特异性。
**新星发现。**后起之秀是具有专业知识和能力的学者,在不久的将来可能会在相关领域获得很高的声誉(Daud et al.,2013)。寻找某一领域的新星是近年来的一个新的研究方向,这使得研究团队有可能重视有价值和潜力的研究人员。这个想法最初是由PubRank(Li et al.,2009)计算出来的,它只包含了场馆的静态排名以及作者和论文之间的相互影响。StarRank(Daud et al.,2013)方法通过考虑动态出版物排名,提高了PubRank方法的可靠性。后来,Daud等人(2015)提出了一种机器学习方法,该方法基于出版物、合著者和场地的组合来寻找新星。Wijegunawardana et al.(2016)使用多目标方法和rankaggeration方法的组合,从多个数据源中发现了新星。Panagopoulos等人(2017)提出了一种基于无监督聚类机器学习的方法,该方法考虑了所有关键绩效指标(KPI)来识别新星。此外,Zhang et al.(2016)提出了CocaRank方法,通过整合新定义的指标协作口径、引文计数和混合结果,寻找ASN中的新星。他们的方法可以找到更多的顶级新星和更高的平均引用次数。
6.1.2. 文章级任务
对于论文的应用,学者们感兴趣的是论文的影响评价和预测。论文影响对于评估学者、期刊、机构甚至国家的影响具有重要意义(Bai等人,2017a)。它对于奖励、晋升和招聘的帮助也至关重要。因此,在过去的几十年中,对论文影响的评价和预测的研究并没有减缓。
**文章影响评估。**传统上,论文的引用数量(Lehmann et al.,2006)、影响因子(Timilsina et al.,2016)和h指数(Hirsch,2005)被广泛用于衡量单个论文的科学影响。这些研究大多基于PageRank算法和HITS算法评估论文影响(Chen等人,2007;Zhou等人,2012;Wang等人,2013b)。例如,Ding等人(2009)首先将PageRank算法应用于共引网络,对论文影响力进行排名。基于网络的排名方法是近年来兴起的评价论文影响力的方法。Zhou等人(2012)提出了MutualBank算法,通过对论文、作者和场馆信息进行联合排名来评估影响。Wang等人(2013b)通过挖掘作者、参考文献、期刊和时间信息,提出了CAJTRank方法。为了进一步提高评价的有效性,Yao et al.(2014)提出了一种非线性PageRank方法,对高引用文章优先,对低引用文章进行惩罚。
**文章影响预测。**论文影响预测与论文影响评价同等重要。为了预测未来学术引文的数量,已经做了很多工作。Yan等人(2011)研究了一系列重要特征,以备将来引用。Wang et al.(2013a);Shen et al.(2014)揭示了支配科学影响的基本机制,可以进一步量化和预测未来引用的数量。然而,引文分布会严重影响预测的有效性。Sayyadi和Getoor(2009)提出了FutureRank方法,通过综合考虑作者关系、引用和发表信息来预测论文的未来影响。Yao et al.(2014)提出了一种基于合著网络、加权时间感知引文网络以及文本特征的MRFRank算法来预测论文的未来影响。此外,论文的早期引用对预测长期引用有重要影响(Bruns和Stern,2016)。为了避免过度依赖历史引文数据,社交媒体活动被用来反映论文的潜在影响。Eysenbach(2011)利用推特预测一篇论文在发表后的头30天内是否能被频繁引用。Timilsina et al.(2016)通过将文献计量数据与社交媒体数据相结合,预测了论文影响,证明基于图表的方法可以有效预测学术影响。
6.1.3. 期刊级任务
与前两个任务相比,对期刊级任务的研究较少。期刊级任务的研究主要集中在期刊影响评价方面。
**期刊影响评估。**高质量的期刊往往指导某一特定领域的研究和开发。然而,我国期刊数量众多,对期刊进行合理评价显得尤为重要。有许多衡量期刊影响的指标,如汤森路透影响因子(IF)(Stegmann,1997)、本征因子(Ei)(Bergstrom et al.,2008)、SCImago期刊排名(Jamali et al.,2014)和源标准化论文影响(SNIP)(Waltman et al.,2013)。
目前,有许多研究综合多种指标对期刊进行评价。Su et al.(2013)使用距离度量将多个指标整合到多维空间中。Bartolucci et al.(2015)提出了一种潜在类模型对期刊进行聚类和排序。Yu et al.(2017)通过考虑作者、论文和期刊之间的多重联系,提出了一个相互增强的期刊排名模型(MLMRJR)。Su等人(2017)利用有序加权平均(OWA)算子对多个期刊影响度量进行整合,提出了基于语言术语的模糊聚类方法对期刊进行排序。Beliakov和James(2011)使用Choquet积分分类器整合不同指标,预测了基于引文网络的期刊排名。
6.2. 面向关系的应用程序
关系的应用分为作者关系预测、学术推荐和社区发现。
6.2.1. 作者关系预测
在ASNs中,挖掘更深层次的学者关系可以帮助学者建立潜在的合著或引用关系。目前,识别潜在合作的方法主要集中在机器学习、链接预测和SNs分析。
Sun等人(2011)分析了DBLP异构网络中的合著者和引用关系,以预测合著者。Yang et al.(2012)提出了一种MRIP方法,通过考虑两个作者之间的信息流,提高了协作的预测精度。Zhang和Yu(2014)提出了一种有监督机器学习方法,利用作者的网络特征和语义特征预测生物医学领域的合作。Chen和Fang(2014)建立了一个潜在协作指数模型,通过将网络度量(如程度和距离)与互补度量(如受让人类型和主题相似性)相结合来预测专利受让人之间的协作概率。Guns和Rousseau(2014)将机器学习技术与链接预测相结合,以预测极具潜力的合作者。Wang et al.(2010)通过构建时间约束概率因子图模型挖掘了协作网络中的顾问建议关系。在此基础上,Wang et al.(2017a)进一步探讨了advisor-Advise关系,并进一步考虑了学术年龄和合著论文数量等当地属性。
6.2.2. 学术推荐
在大数据和信息爆炸的时代,通过人工搜索和浏览器检索相关结果并不是最有效的方式。各种学术推荐系统已被引入,以缓解信息过载问题,过滤大量的数据。
**合作建议。**在学术领域,合作有利于提高研究人员的生产力(Abramo等人,2009年)。因此,向研究者推荐合作者是一个亟待解决的问题。协作推荐的方法一般可分为四类(Kong et al.,2017),即基于内容的推荐、基于过滤的协作推荐(Pham et al.,2011)、基于社交网络的推荐(Li et al.,2014)和基于混合的推荐(Kong et al.,2017)。
Sugiyama和Kan(2010)引入了一个通用模型来推荐与研究人员兴趣相关的学术论文。Katz和Martin(1997)考虑了不同水平的协作,发现协作水平越高的研究人员往往效率越高,生产力越高。Yang等人(2015)提出了一种考虑社会邻近性和制度连通性的异构网络推荐方法。上述推荐方法是静态的,但研究者的研究兴趣有时会随着时间的推移而改变。Liang等人(2012)提出了一个考虑主题动态的时间感知主题建议。Daud(2012)提出了一个时间主题模型,发现研究者的兴趣和关系随着时间的推移而改变。Kong et al.(2017)提出了一个新的BCR模型,该模型考虑了兴趣主题的分布、兴趣的时间动态和合作者的水平,以推荐有用的合作者。Chaiwanarom和Lursinsap(2015)根据他们对协作、资历和进化的研究兴趣提出了建议,并发现了研究问题的跨学科性质。基于相关建议,Chen等人(2011)开发了一个推荐潜在合作者的系统。链接预测也是合作者推荐的一种方法(Lüand Zhou,2011)。Benchettara等人(2010)通过二进制拓扑监督学习方法实现了合作者的推荐。Wang和Sukthankar(2013)提出了一种新的链路预测方法,避免了对所有链路的统一处理。为了预测异构网络的链路,Dong等人(2012)提出了一种基于因子的排序图模型,取得了较好的结果。
**论文推荐。**由于出版物的信息过载,论文推荐可以有效地帮助研究者找到特定领域的相关论文。基于两篇论文的相似性,有多种论文推荐方法。由于潜在论文的发现可视为链接预测过程,因此可分为基于引文的链接预测和基于内容的链接预测。
Strohman等人(2007)使用链接预测问题的Katz索引进行引文推荐。Katz索引通过在引文网络中选择较短的长度来计算路径数。许多研究使用重新启动的随机游走进行引文分析(Lao和Cohen,2010),这是一种与PageRank算法相似的有效技术。基于此,Lao和Cohen(2010)提出了一种利用机器学习技术对边缘进行加权的可学习邻近度度量方法。Nassiri等人(2013)提出了一种基于引文计算论文相似度的归一化相似度指数(NSI)。另一方面,基于内容的链接预测考虑了语义信息。Meng et al.(2013)建立了一个基于网络的论文推荐模型,该模型考虑了作者、内容和协作网络等多种信息。Huang等人(2015)将一种新的神经概率模型与语义文本相结合来推荐论文。Kong等人(2018)提出了一种VOPRec方法,该方法利用节点嵌入技术综合考虑文本信息和网络结构信息来推荐论文。
**场地推荐。**研究者在撰写论文之前或完成论文之后,选择合适的地点提交论文,可能是一个两难的选择。因此,我们需要一个系统,可以推荐可能的出版场所,以帮助研究人员。近年来,随着研究人员在寻找新的研究场所时面临越来越多的信息过载问题,围绕学术活动建议的研究和开发重新兴起(Huynh和Hoang,2012)。
Luong等人(2012年)使用网络分析技术,通过两位作者之间合著文章的数量来衡量网络中的场所。然而,作者只是在小范围内评估了他们的建议,数据集仅涵盖16个地点,不到1000篇论文。Boukhris和Ayachi(2014)提出了一种混合推荐方法,使用来自共同学术机构的合作者、合作者和研究人员来推荐会议。Silva et al.(2015)通过分析研究人员的社交网络,确定了类似研究人员发表的期刊,并推荐了考虑手稿质量和相似性的期刊。Yang和Davison(2012)使用了论文主题和写作风格的评分,而Medvet et al.(2014)使用标题和摘要来推荐地点。此外,夏等(2013)提出了一个社会意识会议推荐系统,用于推荐活动。Alhoori和Furuta(2017)提出了一种基于以用户为中心的altmetrics和探索作者阅读兴趣的场馆评估方法。
6.2.3. 社区/群体检测
在SNs中,网络社区/群体检测具有重要意义,因为社区/群体结构可以用来研究人类行为。网络社区结构与asn中的图划分密切相关。检测社区/群体有多种方法。在这里,我们提出了两种主要的检测方法,即基于模块化的方法和其他社区划分方法。
**基于模块化的方法。**模块化最早由Newman和Girvan(2004)提出,是确定网络分区质量的常用标准。模块化是一种可以用来反映网络社区如何被分离和重组的水平或程度的度量。然而,寻找大规模网络的最大模块化是一个NP-hard问题。因此,人们发展了许多快速近似算法,如贪婪型算法、模拟退火算法、极值优化算法和谱优化算法。其中,CNM是由Clauset、Newman和Moore提出的一种经典贪婪型算法,计算复杂度为O(log2n)(Clauset等人,2008)。在许多实际的大型学术网络中,存在着层次结构。此外,一个大的社区也可能包含许多小的社区。为了检测给定大规模学术网络的层次结构,Expert等人(2011)提出了BGLL算法。BGLL在初始化阶段假设网络中的每个节点都是一个社区,然后考虑每个节点的相邻节点,计算相邻节点社区模块化值的增量。n
模块化还可以应用于时间相关网络、多路复用网络和多尺度网络(Chaturvedi等人,2012)。根据切片顺序,多切片网络主要可分为两类。一种是多片网络,其中片已被订购。多层社区检测方法可以用来揭示一些随着时间推移而细化的细节(Mucha和Onnela,2010)。其他多片网络是片没有顺序的。美国一所大学的1640名大学生组成了一个多元化的网络,他们之间有好几种关系,即Facebook友谊、图片友谊、室友和住房群体偏好(Mucha和Onnela,2010)。在这个生成的复用网络中,每个片都是基于各种关系构造的。在学术界,学者们通过构建多元网络来探索不同学科之间的关系。有时,多路复用网络被称为多层网络。
也存在许多嵌入欧几里德空间的真实网络,例如互联网和各种在线社交网络和交通网络。为了研究空间节点边缘分布对网络拓扑和动力学特性的影响,Barthélemy(2011)通过考虑空间的影响修改了模块化。此外,在线社交网络中的信息扩散问题(Myers et al.,2012;Haralabopoulos and Anagnostopoulos,2014a)可以通过多层信息流来解决(Haralabopoulos and Anagnostopoulos,2014b)。Suny等人(2018)提出了一个多重扩散模型(MDM),该模型将多标签Hawkes过程与主题模型相结合来推断社会网络的多重结构。他们通过在真实数据集上的实验,验证了他们的模型更有效地揭示了多路网络的结构。
**其他方法。**有真实的数据表明,一些具有显著社区结构的网络不能被模块化识别,而一些没有显著社区结构的网络通常被认为具有显著的社区结构。此外,模块化的解决使得在大型学术社交网络中识别小型社区变得困难甚至不可能(Fortunato和Barthelemy,2007)。此外,上述方法还考虑到每个节点都可以清晰地划分为一个社区。然而,社区通常有重叠的节点,这些节点可能属于多个社区。为了解决这一问题,Palla等人(2005)提出了一种团渗滤(CP)算法来识别与CFinder软件有重叠的社区。CP算法的关键过程是找到所有k-团开始形成一个初始节点。在找到所有的团之后,可以生成一个团-团重叠矩阵,它类似于邻接矩阵。
Ahn等人(2010)提出了一种基于边缘的社区检测方法,因为许多社区是通过大量的边缘连接起来的,而节点的作用并不是那么重要。基于边缘的网络划分方法可以通过适当的阈值进行分类,以减少混淆和社区。
6.3. 面向网络的应用
面向网络的应用通过考虑整个网络的关系和特性来研究ASN。
6.3.1. 协作模式
自上个世纪以来,协作日益成为许多领域的主流科学知识模式(Wuchty et al.,2007)。科学合作也是ASN的一个热点(Wang等人,2017b)。
Barab–si等人(2002)和Newman(2001、2004)分别对探索协作网络做出了开创性的研究贡献。随后,文学出版物的巨大增长解释了学术合著网络的结构和演变,特别是“无标度”和“小世界”的性质(Yan et al.,2010)。此外,学术协作网络的基本演化机制和演化动力学模型也被广泛研究(Evans et al.,2011)。尽管如此,其他研究者在许多领域关注“社会凝聚力”(White和Harary,2001)的特征。Powell等人(2005)证实了生命科学领域中“内聚核心”属性的存在。通过跟踪复杂网络研究领域中协作网络的演化,Lee等人(2010)发现了网络演化的三个主要过程:小型孤立组件、具有强大核心的巨型树形组件和大规模回收组件。Wei等人(2017)通过将网络划分为个人、机构和国际层面,研究了生产力模式和国际合作。
6.3.2. 跨学科研究
跨学科研究通常被认为是解决当前科学研究中复杂问题的最佳途径。Smajgl和Ward(2013)指出,跨学科研究的发展促进了方法创新。Porter和Rafols(2009)评估了六个领域的跨学科进化,发现被引用学科的数量、每篇论文的参考文献数量和每篇文章的合作者数量都发生了显著变化。他们还发现一篇论文的引用主要集中在相邻的学科领域。Cronin和Sugimoto(2014)也发现,在1945年至1975年的下降之后,跨学科性呈上升趋势。通过对跨学科领域协作网络演化的研究,Liu和Xia(2015)发现,协作网络逐渐从局部小集群演化为“链式社区”结构,进而演化为小世界结构。Chang和Huang(2012)分析了直接引文、书目耦合和合著网络,以研究图书情报学领域跨学科的变化。Chen等人(2015年)研究了100多年来生物化学和分子生物学的跨学科变化,证明跨学科主要从邻近地区发展到遥远的认知领域。Karunan等人(2017年)构建了一个跨学科评估框架,以在论文水平上展示跨学科。
6.3.3. 研究趋势预测
研究主题是动态的,因为突破性研究可以促进某些领域以及新兴的研究课题。因此,研究者必须有效地发现学术界的热点话题,帮助他们了解所关注领域的最新概念、技术和趋势。
早些时候,这个问题是通过手动提取单个特征(如引文关系和合著)的主题来解决的。例如,Katz等人(2001年)通过共引分析,获得了一些对新兴趋势的短期和长期预测,花费了大量的时间和精力来进行。Upham和Small(2010)使用了cocitation集群来寻找前20个新兴主题。Chen et al.(2012)将共引分析与突发检测相结合来描述新兴的主题趋势,发现关键聚类往往与重要论文相关联,这不仅导致引用数量的大幅增加,而且具有高度的中间性中心性。
联合引用并不是唯一用来识别新趋势的方法。Duvvuru等人(2013)分析了学术语料库中的共现关键词网络,并监测了链接权重的时间演变,以检验研究趋势和新兴领域。钱等(2014)采用社区划分的思想,分析论文的核心,揭示学术主题形成和发展的基本过程。但该方法局限于数据量,通用性不够。Salatino et al.(2017)使用基于lique和基于triad的方法来衡量现有主题的动态发展对新主题创建的影响。
6.4. 学术社交网站
为了帮助研究人员建立个人档案,使他们能够分享兴趣和论文,一系列的ASNs网站应运而生。我们回顾了一些比较流行的网站。
AMiner
2006年基于Perl CGI编程建立。目前,该网站包括超过1.3亿名学者、2.33亿份出版物和7.54亿份引文(Tang等人,2008年)。Aminer目前的任务是:(1)创建基于语义的研究者档案;(2)整合来自多个资源的SBD;(3)构建异构网络;(4)分析有趣的模式。目前,已有大量基于胺的ASN研究,如萃取(Tang et al.,2010)、排名(Tang et al.,2008)和影响分析(Wang et al.,2010)。
CiteSeerX
被认为是第一个提供自主引文索引的学术数字图书馆。citeserx与其他学术数字图书馆和搜索引擎相比是独一无二的,因为所有文件都是从公共网站收集的。这就是为什么用户可以完全访问此网站上所有可搜索的文件。此外,它还会自动提取图形实体(如图形和表格)并为其编制索引。人们可以使用元数据和文本提取服务(Williams等人,2014a)进行研究。然而,citeserx在数据收集和信息质量方面存在问题(Wu和Giles)。
Microsoft Academic Search
是一种学术搜索引擎,它从已发布的数据源中提取元数据,自动创建研究人员的个人资料。研究者的概况包括文献信息(出版物列表、关键词、合著者等)和文献计量指标(论文、引文等)。此外,它们还根据论文的主题进行分类。同时,它还提供了一些可视化信息,包括出版趋势、合著者信息和合著者路径(Osborne et al.,2013)。不过,微软学术搜索也存在一些问题。其中之一是信息重复问题(Ortega和Aguillo,2014),这导致在使用数据之前很难进行数据预处理。此外,作者消歧的过程可能很难处理(Pitts等人,2014)。另一个问题是数据更新缓慢(每年更新一次)。最后一个问题在于,这些配置文件中有许多属于远程时段,这导致它们成为非活动配置文件。
Google Scholar
是一个学术检索系统,包含有关出版物(标题、合著者、出版年份等)和指标(引文计数、i10索引、h索引等)的基本信息。与Microsoft Academic Search不同,它的研究人员档案由研究人员自己创建和编辑,因此每个研究人员的信息都是可选的。但这导致了信息标准化的缺陷(De Winter et al.,2014)。此外,它还可以频繁地更新数据。然后,通过创建一个web解析器程序,可以自由地访问和提取信息(barilan,2008)。此外,它是第一个检索文献的书目搜索,不仅限于图书馆和传统文献数据库。
ResearchGate
是一个学术社交网站,允许用户上传论文,参与讨论,并跟踪其他研究人员。它旨在帮助学者建立自己的简介,分享他们的出版物,并与同行提出问题(Thelwall和Kousha,2015)。此外,它还为用户提供altmetric度量,如纵断面图计数和文档下载计数。ResearchGate根据用户的个人资料、他们对内容的贡献以及他们对网站的参与度,为每个作者提供了一个综合评价指数。此外,该网站还有一个Q和一个平台,允许学者们讨论和寻找各种话题的答案。与此同时,网站上有许多主题,学者可以通过这些主题实时查看这些主题的最新信息(Ovadia,2014)。
Academia.edu
是一个网络托管的学术论文平台,允许用户创建自己的简介,并将文档列表上传到学术.edu. 它有一个分析仪表盘,用户可以实时查看其研究的影响和传播(Meishar Tal和Pieterse,2017)。此外,它还提供一项服务,每当感兴趣的研究人员发布新的研究出版物时,就向帐户持有人发送电子邮件,读者可以在论文上贴标签,提醒任何与某个特定主题有关的人。
7展望未来
近年来,由于SBD的快速发展,研究者已经认识到利用SNs分析asn的重要性。为了便于研究人员理解asn,我们的调查工作系统地回顾了asn的新兴领域。本文综述了该领域的研究背景、建模方法、分析方法、关键挖掘技术及应用。除此之外,我们还讨论了一些流行的工具和网站。
SBD带来了存储、处理、信息提取、数据分析等问题。在分析和挖掘asn的过程中存在一些问题。首先,由于数据量巨大,挖掘有用的、有效的信息对研究者来说是一个挑战。这些数据也为研究者带来了更多的合作机会。然而,研究人员很难找到潜在的合作者(Brandao和Moro,2012)。其次,学术论文网络是复杂的:论文中的引文形成了引文网络,而学者之间的合著形成了协作网络。大量SBD由不同机构产生,并由不同平台记录。此外,SBD的异质性导致实体名称的不同变体(Williams等人,2014b)。第三,共享数据也是ASN面临的挑战。例如,与知识产权和版权相关的问题可能会限制不同社区之间的数据复制和共享(Williams等人,2014b)。此外,数据的缺乏也是一个需要处理的问题,然而,当数据很大时,可以通过数据之间存在的各种关系来恢复或补充数据。现有的许多学术数据平台都是针对某一学科而设计的,其中大部分局限于计算机科学领域。这会对跨学科研究造成限制。此外,研究影响评价仍然是学者们面临的一个挑战。尽管关于期刊、会议和机构排名的研究有很多种,但是没有一个统一的框架或系统来整合它们。
本课题的未来研究可以从(1)构建异构学术网络,(2)建立统一的学术影响评价方法,(3)整合多学科的学术数据资源,(4)挖掘隐含指标来探索asn。研究ASN可以促进相关技术的发展,促进相关平台和系统的普及,使机构和政府的政策设计更加合理。
引文网络,而学者之间的合著形成了协作网络。大量SBD由不同机构产生,并由不同平台记录。此外,SBD的异质性导致实体名称的不同变体(Williams等人,2014b)。第三,共享数据也是ASN面临的挑战。例如,与知识产权和版权相关的问题可能会限制不同社区之间的数据复制和共享(Williams等人,2014b)。此外,数据的缺乏也是一个需要处理的问题,然而,当数据很大时,可以通过数据之间存在的各种关系来恢复或补充数据。现有的许多学术数据平台都是针对某一学科而设计的,其中大部分局限于计算机科学领域。这会对跨学科研究造成限制。此外,研究影响评价仍然是学者们面临的一个挑战。尽管关于期刊、会议和机构排名的研究有很多种,但是没有一个统一的框架或系统来整合它们。
本课题的未来研究可以从(1)构建异构学术网络,(2)建立统一的学术影响评价方法,(3)整合多学科的学术数据资源,(4)挖掘隐含指标来探索asn。研究ASN可以促进相关技术的发展,促进相关平台和系统的普及,使机构和政府的政策设计更加合理。
参考文献:
[1] Kong X , Shi Y , Yu S , et al. Academic social networks: Modeling, analysis, mining and applications[J]. Journal of network and computer applications, 2019, 132(APR.):86-103.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/138023.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
