大家好,又见面了,我是你们的朋友全栈君。
BERT 模型是一种 NLP 预训练技术,本文不介绍 BERT 的原理,主要关注如何快速上手使用 BERT 模型生成词向量用于下游任务。
Google 已经公开了 TensorFlow 版本的预训练模型和代码,可以用于生成词向量,但是还有更简单的方法:直接调用封装好的库 bert-as-service 。

使用 bert-as-service 生成词向量
bert-as-service 是腾讯 AI Lab 开源的一个 BERT 服务,它让用户可以以调用服务的方式使用 BERT 模型而不需要关注 BERT 的实现细节。bert-as-service 分为客户端和服务端,用户可以从 python 代码中调用服务,也可以通过 http 的方式访问。
安装
使用 pip 命令进行安装,客户端与服务端可以安装在不同的机器上:
pip install bert-serving-server # 服务端
pip install bert-serving-client # 客户端,与服务端互相独立
其中,服务端的运行环境为 Python >= 3.5 和 Tensorflow >= 1.10
客户端可以运行于 Python 2 或 Python 3
下载预训练模型
根据 NLP 任务的类型和规模不同,Google 提供了多种预训练模型供选择:
- BERT-Base, Chinese: 简繁体中文, 12-layer, 768-hidden, 12-heads, 110M parameters
- BERT-Base, Multilingual Cased: 多语言(104 种), 12-layer, 768-hidden, 12-heads, 110M parameters
- BERT-Base, Uncased: 英文不区分大小写(全部转为小写), 12-layer, 768-hidden, 12-heads, 110M parameters
- BERT-Base, Cased: 英文区分大小写, 12-layer, 768-hidden, 12-heads , 110M parameters
也可以使用中文效果更好的哈工大版 BERT:
以上列出了几个常用的预训练模型,可以到 这里 查看更多。
解压下载到的 .zip 文件以后,会有 6 个文件:
- TensorFlow 模型文件(
bert_model.ckpt) 包含预训练模型的权重,模型文件有三个 - 字典文件(
vocab.txt) 记录词条与 id 的映射关系 - 配置文件(
bert_config.json) 记录模型的超参数
启动 BERT 服务
使用 bert-serving-start 命令启动服务:
bert-serving-start -model_dir /tmp/english_L-12_H-768_A-12/ -num_worker=2
其中,-model_dir 是预训练模型的路径,-num_worker 是线程数,表示同时可以处理多少个并发请求
如果启动成功,服务器端会显示:

在客户端获取句向量
可以简单的使用以下代码获取语料的向量表示:
from bert_serving.client import BertClient
bc = BertClient()
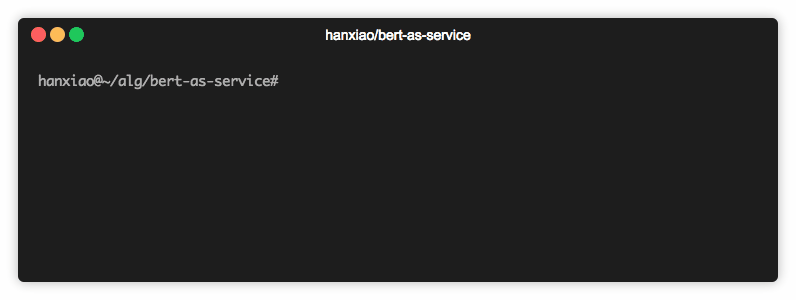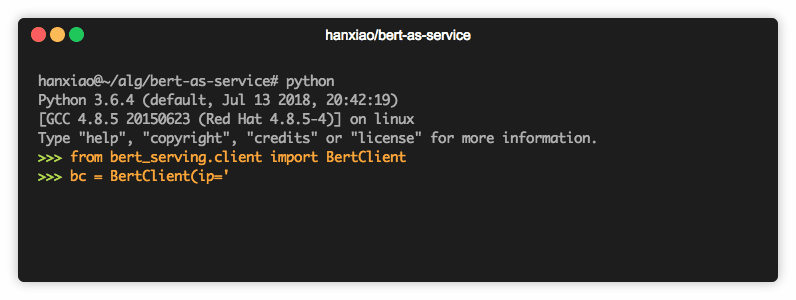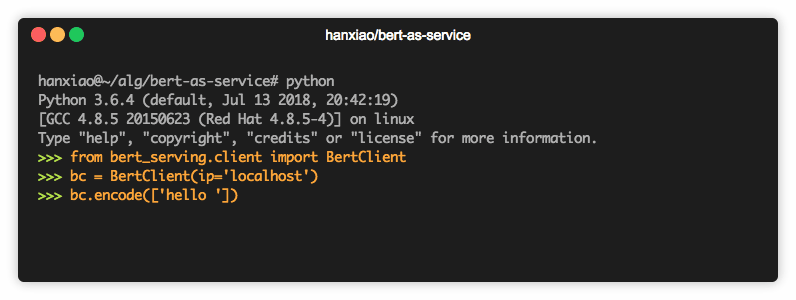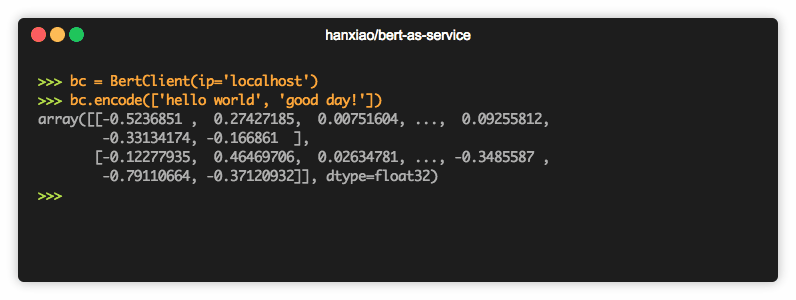
doc_vecs = bc.encode(['First do it', 'then do it right', 'then do it better'])
doc_vecs 是一个 numpy.ndarray ,它的每一行是一个固定长度的句子向量,长度由输入句子的最大长度决定。如果要指定长度,可以在启动服务使用 max_seq_len 参数,过长的句子会被从右端截断。
BERT 的另一个特性是可以获取一对句子的向量,句子之间使用 ||| 作为分隔,例如:
bc.encode(['First do it ||| then do it right'])
获取词向量
启动服务时将参数 pooling_strategy 设置为 None :
bert-serving-start -pooling_strategy NONE -model_dir /tmp/english_L-12_H-768_A-12/
这时的返回是语料中每个 token 对应 embedding 的矩阵
bc = BertClient()
vec = bc.encode(['hey you', 'whats up?'])
vec # [2, 25, 768]
vec[0] # [1, 25, 768], sentence embeddings for `hey you`
vec[0][0] # [1, 1, 768], word embedding for `[CLS]`
vec[0][1] # [1, 1, 768], word embedding for `hey`
vec[0][2] # [1, 1, 768], word embedding for `you`
vec[0][3] # [1, 1, 768], word embedding for `[SEP]`
vec[0][4] # [1, 1, 768], word embedding for padding symbol
vec[0][25] # error, out of index!
远程调用 BERT 服务
可以从一台机器上调用另一台机器的 BERT 服务:
# on another CPU machine
from bert_serving.client import BertClient
bc = BertClient(ip='xx.xx.xx.xx') # ip address of the GPU machine
bc.encode(['First do it', 'then do it right', 'then do it better'])
这个例子中,只需要在客户端 pip install -U bert-serving-client
其他
配置要求
BERT 模型对内存有比较高的要求,如果启动时一直卡在 load graph from model_dir 可以将 num_worker 设置为 1 或者加大机器内存。
处理中文是否要提前分词
在计算中文向量时,可以直接输入整个句子不需要提前分词。因为 Chinese-BERT 中,语料是以字为单位处理的,因此对于中文语料来说输出的是字向量。
举个例子,当用户输入:
bc.encode(['hey you', 'whats up?', '你好么?', '我 还 可以'])
实际上,BERT 模型的输入是:
tokens: [CLS] hey you [SEP]
input_ids: 101 13153 8357 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
input_mask: 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
tokens: [CLS] what ##s up ? [SEP]
input_ids: 101 9100 8118 8644 136 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
input_mask: 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
tokens: [CLS] 你 好 么 ? [SEP]
input_ids: 101 872 1962 720 8043 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
input_mask: 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
tokens: [CLS] 我 还 可 以 [SEP]
input_ids: 101 2769 6820 1377 809 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
input_mask: 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
在英语中词条化后的 ##something 是什么
当某个词在不在词典中时,使用最长子序列的方法进行词条化,例如:
input = "unaffable"
tokenizer_output = ["un", "##aff", "##able"]
参考资料
- https://github.com/google-research/bert
- https://github.com/hanxiao/bert-as-service
本作品采用知识共享署名-非商业性使用 3.0 未本地化版本许可协议进行许可。欢迎转载,演绎,但是必须保留本文的链接,不得用于商业目的。如您有任何疑问或者授权方面的协商,请与我联系。

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/137750.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
