大家好,又见面了,我是你们的朋友全栈君。
5.3 SPPNet
学习目标
-
目标
-
知道SPPNet与RCNN的对比特点
-
掌握空间金字塔池化(spatial pyramid pooling)的原理和作用
-
掌握SPPNet的训练过程以及测试结果对比
-
知道SPPNet优缺点总结
-
-
应用
-
无
-
5.3.1 SPPNet介绍
针对之前R-CNN的缺点,我们来看
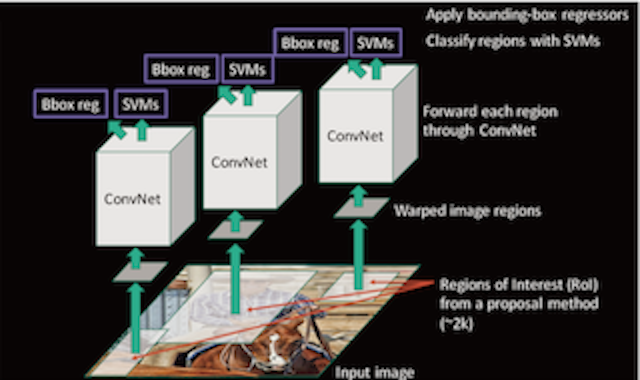

1、每个候选区域都进行了卷积操作提取特征,计算量大速度低效。
2、对于卷积网络来讲都需要输入的图像尺寸固定(比如224×224)。这种人为的需要导致面对任意尺寸和比例的图像或子图像时降低识别的精度。当遇到任意尺寸的图像是,都是先将图像适应成固定尺寸,方法包括裁剪和变形。裁剪会导致信息的丢失,变形会导致位置信息的扭曲,就会影响识别的精度。
5.3.1.1 SPPNet与RCNN对比
-
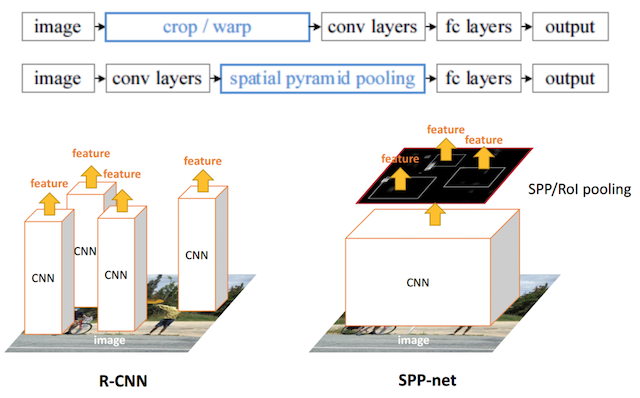
方法:SPPNet引入一种空间金字塔池化( spatial pyramid pooling,SPP)层以移除对网络固定尺寸的限制。
-
SPP层放在最后一个卷积层之后。SPP层对特征进行池化,并产生固定长度的输出,这个输出再喂给全连接层
-
注:在CNN之前,SPP一直是各大分类比赛和检测比赛的冠军系统中的核心组件,分类或者检测中都会用到
-
|
R-CNN模型 |
SPPNet模型 |
|
1、R-CNN是让每个候选区域经过crop/wrap等操作变换成固定大小的图像 2、固定大小的图像塞给CNN 传给后面的层做训练回归分类操作 |
1、SPPNet把全图塞给CNN得到全图的feature map 2、让SS算法得到候选区域与feature map直接映射,得到候选区域的映射特征向量(这是映射来的,不需要过CNN) 3、映射过来的特征向量大小不固定,所以这些特征向量塞给SPP层(空间金字塔变换层),SPP层接收任何大小的输入,输出固定大小的特征向量,再塞给FC层4、经过映射+SPP转换,简化了计算,速度/精确度也上去了 |
-
1、SPP层怎么可以接收任意大小的输入,输出固定的向量?
-
2、SPPNet怎么就能把候选区域从全图的feature map 直接得到特征向量?
5.3.1.2 spatial pyramid pooling layer
全连接层或在SVM/softmax这一类的分类器需要输入规定长度的向量。
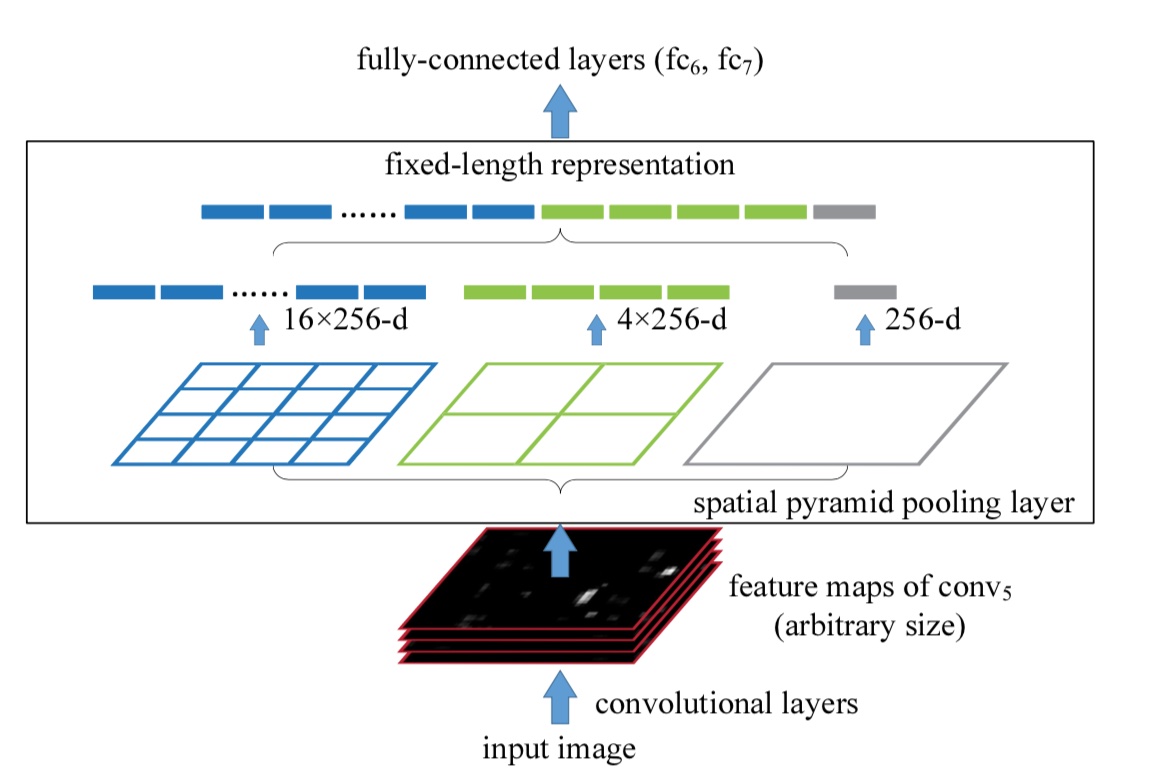
注:因为选择的是Alex-Net, conv5得到的feature map大小是13 13 256, 所以是256维向量
pooling使用max pooling,具体操作如下:
-
1、假设conv5输出feature map大小为 a a,pyramid level层数为P,每一层大小为 n n 个bin (每一层不同)
-
2、max pooling滑窗参数取值为:win=a/nwin=a/n(向上取整),stride=a/nstride=a/n(向下取整)
-
3、spp layer会将每一个候选区域分成1×1,2×2,4×4三张子图,对每个子图的每个区域作max pooling,得出的特征再连接到一起就是(16+4+1)x256=21×256=5376结果,接着给全连接层做进一步处理,如下图:
-
Spatial bins(空间盒个数):1+4+16=21
-
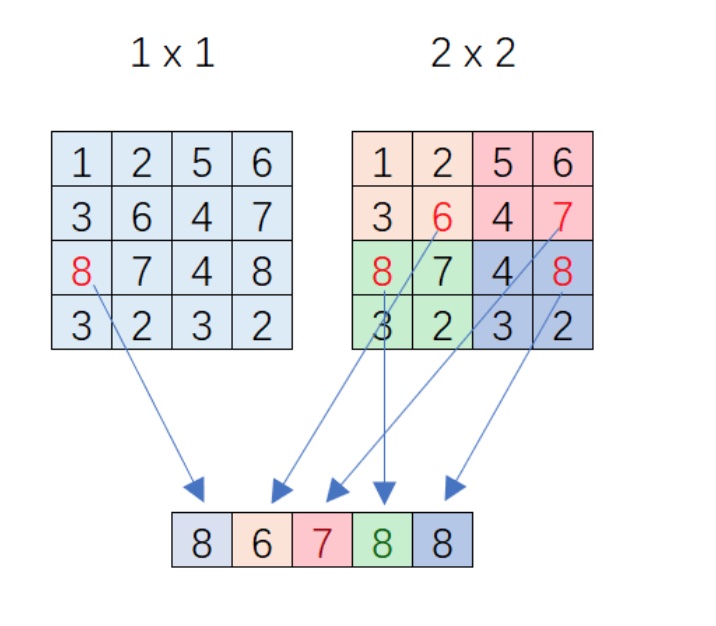
如下简单的1×1和2×2的例子,输入4×4的feature map
-
-
-
SPP突出的优点
-
1、SPP能在输入尺寸任意的情况下产生固定大小的输出,而以前的深度网络中的滑窗池化(sliding window pooling)则不能
-
2、SPP使用了多级别的空间箱(bin),而滑窗池化则只用了一个窗口尺寸。多级池化对于物体的变形十分鲁棒
-
3、由于其对输入的灵活性,SPP可以池化从各种尺度抽取出来的特征
-
-
效果
-
基于SPP-net的系统(建立在R-CNN流水线上)比R-CNN计算特征要快24-120倍,可以做到0.5s处理一张图片,在Pascal VOC 2007预测准确率更高。
-
5.3.1.3 映射
如何得到每个候选区域的特征向量?这个步骤也大大提高了特征计算的速度!
SPPnet的做法是首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。然后把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中通过映射关系找到各个候选框的区域。最后再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。
-
问题:特征图(feature maps)的大小是根据图片的大小与卷积层的卷积核大小(kernel size)与步长(stride)决定的,如何在特征图上找到原图上对应的候选区域,即两者之间的映射关系是怎么样的?
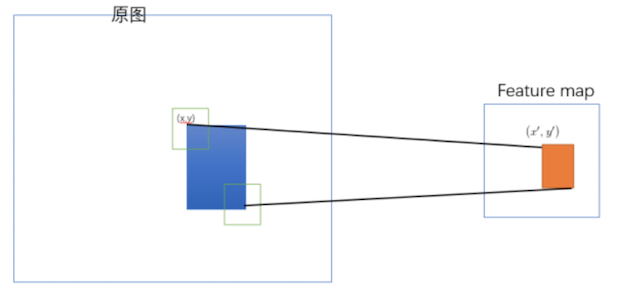
整个映射过程有具体的公式,如下
假设(x′,y′)(x′,y′)表示特征图上的坐标点,坐标点(x,y)表示原输入图片上的点,那么它们之间有如下转换关系,这种映射关心与网络结构有关:(x,y)=(S∗x′,S∗y′),即
-
左上角的点:
-
x′=[x/S]+1
-
-
右下角的点:
-
x′=[x/S]−1
-
其中 S 就是CNN中所有的strides的乘积,包含了池化、卷积的stride。论文中使用S的计算出来为2x2x2x2=16,在ZF-5结构中。
5.3.1.4 SPPNet 结果
-
网络架构:论文中研究了四种不同的网络架构,对所有这些架构,SPP都提升了准确度。简单介绍如下:
-
1、ZF-5:基于Zeiler和Fergus的“快速”模式网络架构。数字5代表5层卷积网络。使用ZF-5的SPP-net模型(单一尺寸训练)。在每个候选窗口,我们使用一个4级空间金字塔(1×1, 2×2, 3×3, 6×6, 总共50块),每个窗口将产生一个12800(256×50)维的表示。
-
2、Convnet-5:在conv2和conv3(而不是conv1和conv2)之后加入了两个池化层。
-
3、Overfeat-5/7:基于Overfeat论文
-
-
训练
-
SVM:针对每个分类训练一个二分线性SVM分类器。使用真实标注的窗口去生成正例。负样本是那些与正例窗口IoU不超过30%的候选窗口。如果一个负样本与另一个负样本IoU超过70%就会被移除。对于全部20个分类训练SVM小于1个小时。
-
卷积网络的训练:conv5之后的固定长度的池化后的特征,后面跟着fc6,fc7和一个21个分类(有一个负例类别)fc8层。fc8的权重使用高斯分布标准差σ=0.01进行初始化,调优过程中正样本是与目标重叠度达到[0.5, 1]的窗口,负例是重叠度为[0.1, 0.5),每个mini-batch,25%是正例。我们使用学习率1e-4训练了250k个minibatch,然后使用1e-5训练50k个minibatch。因为只调优fc层,所以训练非常的快,在GPU上只需要2个小时。
-
看图理解:
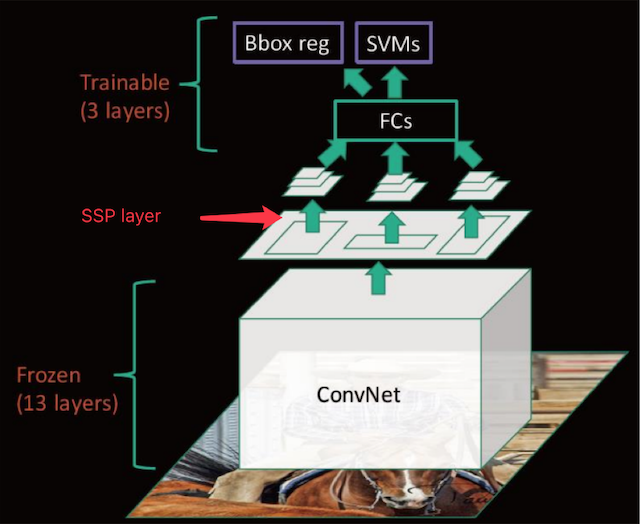
卷积网络训练注意点:
SPPnet在微调时不能更新空间金字塔池化层之前的卷积层参数,这一点限制了深度网络的精度。关于最后一点其实不准确,SPPnet也可以反向传播,但是会很复杂。Ross Girshick在论文《Fast R-CNN》中认为SPPnet在微调时指出,当训练来自不同图像的ROI(候选区域或感兴趣区域)时反向传播经过SPP 层的效率非常低下,这时更新卷积层参数耗时较长,不能更新卷积层参数,而不是不可以更新。
为什么?SPP-Net中fine-tuning的样本是来自所有图像的所有RoI打散后均匀采样的,即RoI-centric sampling,这就导致SGD的每个batch的样本来自不同的图像,需要同时计算和存储这些图像的Feature Map,这个过程变得代价非常大。
-
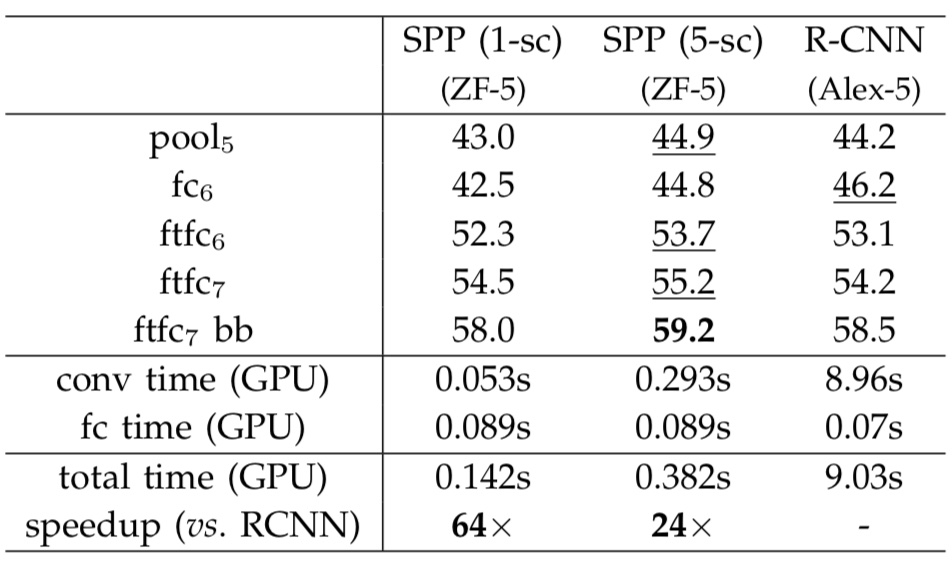
Pascal VOC 2007数据集的测试结果
特点:multi-scale feature extraction 能够进一步改善算法:论文中将image尺度调整为min(w,h)=s,s属于{480,576,688,864,1200},并且计算每个scale的feature maps。可以通过逐个通道池化的方法结合从每个尺度提取到的特征,也就是训练的时候在epoch中首先训练一个尺寸产生一个Model,然后加载该Model训练第二个尺度,直到训练完所有的尺寸为止。
测试的mAP与测试时间对比:
5.3.1.4 代码实现
import tensorflow as tf
import math
def Spp_layer(feature_map, bins):
''' 使用 [3, 2, 1] denote 3*3, 2*2, 1*1 bins做金字塔赤化输出'''
# get feature map shape
batch_size, a, _, _ = feature_map.get_shape().as_list()
pooling_out_all = []
for layer in range(len(bins)):
# 计算每个不同池化尺寸的输出
k_size = math.ceil(a / bins[layer])
stride = math.floor(a / bins[layer])
pooling_out = tf.nn.max_pool(feature_map,
ksize=[1, k_size, k_size, 1],
strides=[1, stride, stride, 1],
padding='VALID')
pooling_out_resized = tf.reshape(pooling_out, [batch_size, -1])
pooling_out_all[layer] = pooling_out_resized
# 特征图合并输出结果
feature_map_out = tf.concat(axis=1, values=pooling_out_all)
return feature_map_out5.3.2 SPPNet总结
来看下SPPNet的完整结构
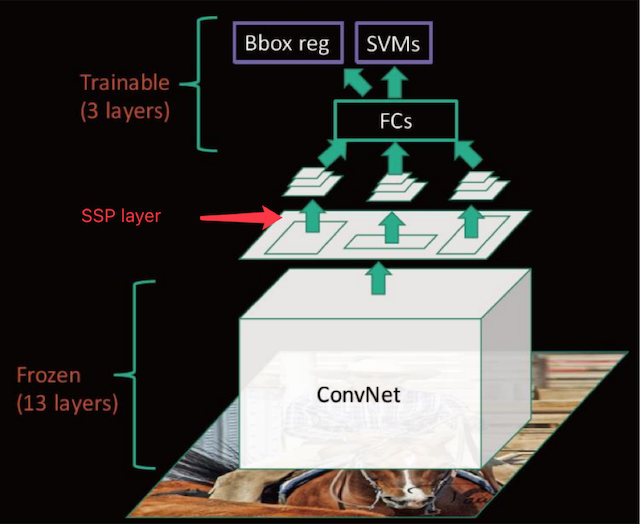
-
优点
-
SPPNet在R-CNN的基础上提出了改进,通过候选区域和feature map的映射,配合SPP层的使用,从而达到了CNN层的共享计算,减少了运算时间, 后面的Fast R-CNN等也是受SPPNet的启发
-
-
缺点
-
训练依然过慢、效率低,特征需要写入磁盘(因为SVM的存在)
-
分阶段训练网络:选取候选区域、训练CNN、训练SVM、训练bbox回归器, SPPNet反向传播效率低
-
5.3.3 总结
-
SPPNet与RCNN的对比特点
-
SPPNet SPP层原理过程、映射过程
-
SPPNet的训练过程以及测试结果对比
-
SPPNet优缺点总结
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/137637.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
