大家好,又见面了,我是你们的朋友全栈君。


导读:用户画像将产品设计的焦点放在目标用户的动机和行为上,从而避免产品设计人员草率地代表用户。产品设计人员经常不自觉的把自己当作用户代表,根据自己的需求设计产品,导致无法抓住实际用户的需求。往往对产品做了很多功能的升级,用户却觉得体验变差了。
在大数据领域,用户画像的作用远不止于此。用户的行为数据无法直接用于数据分析和模型训练,我们也无法从用户的行为日志中直接获取有用的信息。而将用户的行为数据标签化以后,我们对用户就有了一个直观的认识。
同时计算机也能够理解用户,将用户的行为信息用于个性化推荐、个性化搜索、广告精准投放和智能营销等领域。
作者:马海平 于俊 吕昕 向海
本文摘编自《Spark机器学习进阶实战》,如需转载请联系我们
01 概述
用户画像的核心工作就是给用户打标签,标签通常是人为规定的高度精炼的特征标识,如年龄、性别、地域、兴趣等。这些标签集合就能抽象出一个用户的信息全貌,如图10-1所示是某个用户的标签集合,每个标签分别描述了该用户的一个维度,各个维度之间相互联系,共同构成对用户的一个整体描述。

▲图10-1 用户标签集合
02 用户画像流程
1. 整体流程
我们对构建用户画像的方法进行总结归纳,发现用户画像的构建一般可以分为目标分析、体系构建、画像建立三步。
画像构建中用到的技术有数据统计、机器学习和自然语言处理技术(NLP)等,如图10-3所示。具体的画像构建方法会在本章后面的部分详细介绍。
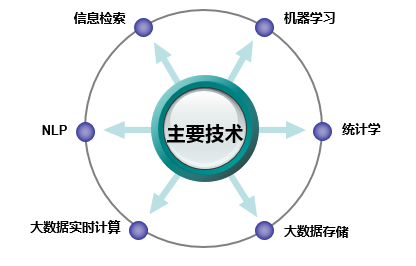
▲图10-3 用户画像的构建技术
2. 标签体系
目前主流的标签体系都是层次化的,如下图10-4所示。首先标签分为几个大类,每个大类下进行逐层细分。在构建标签时,我们只需要构建最下层的标签,就能够映射到上面两级标签。
上层标签都是抽象的标签集合,一般没有实用意义,只有统计意义。例如我们可以统计有人口属性标签的用户比例,但用户有人口属性标签本身对广告投放没有任何意义。
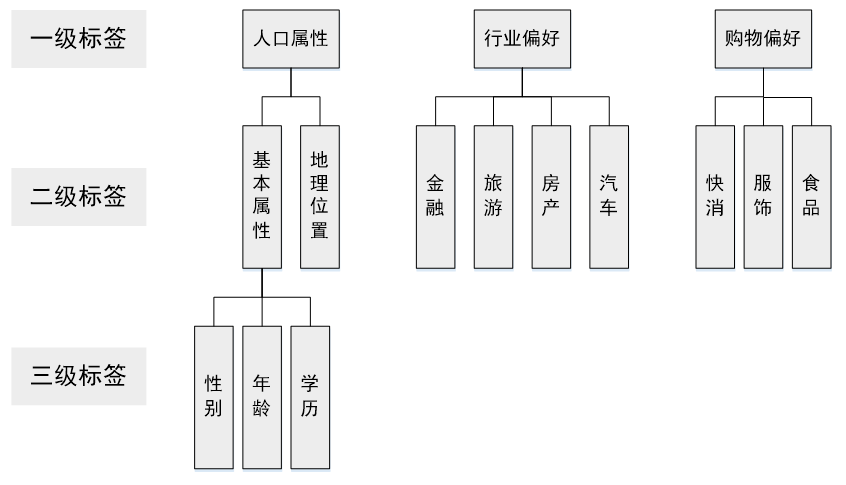
▲图10-4 互联网大数据领域常用标签体系
用于广告投放和精准营销的一般是底层标签,对于底层标签有两个要求:一个是每个标签只能表示一种含义,避免标签之间的重复和冲突,便于计算机处理;另一个是标签必须有一定的语义,方便相关人员理解每个标签的含义。
此外,标签的粒度也是需要注意的,标签粒度太粗会没有区分度,粒度过细会导致标签体系太过复杂而不具有通用性。
表10-1列举了各个大类常见的底层标签。
|
标签类别 |
标签内容 |
|
人口标签 |
性别、年龄、地域、教育水平、出生日期、职业、星座 |
|
兴趣特征 |
兴趣爱好、使用APP/网站、浏览/收藏内容、互动内容、品牌偏好、产品偏好 |
|
社会特征 |
婚姻状况、家庭情况、社交/信息渠道偏好 |
|
消费特征 |
收入状况、购买力水平、已购商品、购买渠道偏好、最后购买时间、购买频次 |
▲表10-1:常见标签
最后介绍一下各类标签构建的优先级。构建的优先级需要综合考虑业务需求、构建难易程度等,业务需求各有不同,这里介绍的优先级排序方法主要依据构建的难易程度和各类标签的依存关系,优先级如图10-5所示。
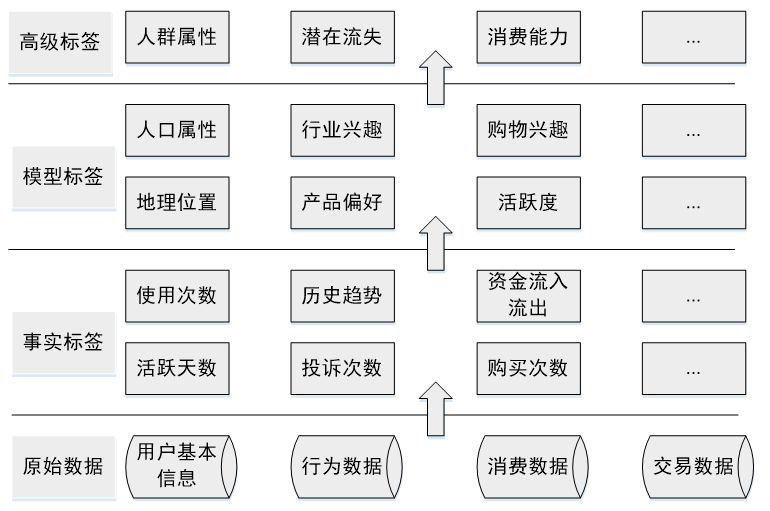
▲图10-5 各类标签的构建优先级
基于原始数据首先构建的是事实标签,事实标签可以从数据库直接获取(如注册信息),或通过简单的统计得到。这类标签构建难度低、实际含义明确,且部分标签可用作后续标签挖掘的基础特征(如产品购买次数可用来作为用户购物偏好的输入特征数据)。
事实标签的构造过程,也是对数据加深理解的过程。对数据进行统计的同时,不仅完成了数据的处理与加工,也对数据的分布有了一定的了解,为高级标签的构造做好了准备。
模型标签是标签体系的核心,也是用户画像工作量最大的部分,大多数用户标签的核心都是模型标签。模型标签的构造大多需要用到机器学习和自然语言处理技术,我们下文中介绍的标签构造方法主要指的是模型标签,具体的构造算法会在本文第03章详细介绍。
最后构造的是高级标签,高级标签是基于事实标签和模型标签进行统计建模得出的,它的构造多与实际的业务指标紧密联系。只有完成基础标签的构建,才能够构造高级标签。构建高级标签使用的模型,可以是简单的数据统计,也可以是复杂的机器学习模型。
03 构建用户画像
我们把标签分为三类,这三类标签有较大的差异,构建时用到的技术差别也很大。
第一类是人口属性,这一类标签比较稳定,一旦建立很长一段时间基本不用更新,标签体系也比较固定;第二类是兴趣属性,这类标签随时间变化很快,标签有很强的时效性,标签体系也不固定;第三类是地理属性,这一类标签的时效性跨度很大,如GPS轨迹标签需要做到实时更新,而常住地标签一般可以几个月不用更新,挖掘的方法和前面两类也大有不同,如图10-6所示。
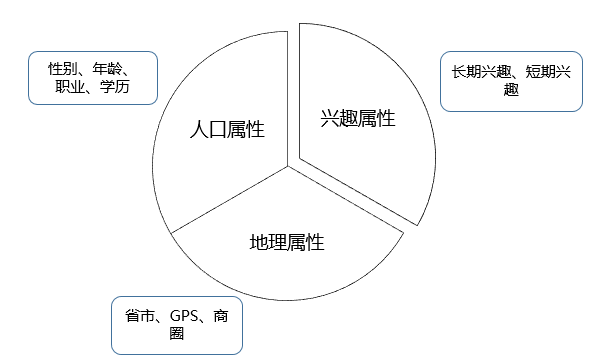
▲图10-6 三类标签属性
1. 人口属性画像
人口属性包括年龄、性别、学历、人生阶段、收入水平、消费水平、所属行业等。这些标签基本是稳定的,构建一次可以很长一段时间不用更新,标签的有效期都在一个月以上。同时标签体系的划分也比较固定,表10-2是MMA中国无线营销联盟对人口属性的一个划分。
大部分主流的人口属性标签都和这个体系比较类似,有些在分段上有一些区别。
|
性别 |
男 |
|
女 |
|
|
未知 |
|
|
年龄 |
12 以下 |
|
12-17 |
|
|
18-19 |
|
|
20-24 |
|
|
25-29 |
|
|
30-34 |
|
|
35-39 |
|
|
40-44 |
|
|
45-49 |
|
|
50-54 |
|
|
55-59 |
|
|
60-64 |
|
|
65 及以上 |
|
|
未知 |
|
|
月收入 |
3500 元以下 |
|
3500-5000 元 |
|
|
5000-8000 元 |
|
|
8000-12500 元 |
|
|
12500-25000 元 |
|
|
25001-40000 |
|
|
40000 元以上 |
|
|
未知 |
|
|
婚姻状态 |
未婚 |
|
已婚 |
|
|
离异 |
|
|
未知 |
|
|
从事行业 |
广告/营销/公关 |
|
航天 |
|
|
农林化工 |
|
|
汽车 |
|
|
计算机/互联网 |
|
|
建筑 |
|
|
教育/学生 |
|
|
能源/采矿 |
|
|
金融/保险/房地产 |
|
|
政府/军事/房地产 |
|
|
服务业 |
|
|
传媒/出版/娱乐 |
|
|
医疗/保险服务 |
|
|
制药 |
|
|
零售 |
|
|
电信/网络 |
|
|
旅游/交通 |
|
|
其它 |
|
|
教育程度 |
初中及以下 |
|
高中 |
|
|
中专 |
|
|
大专 |
|
|
本科 |
|
|
硕士 |
|
|
博士 |
▲表10-2 人口标签
很多产品(如QQ、facebook等)都会引导用户填写基本信息,这些信息就包括年龄、性别、收入等大多数的人口属性,但完整填写个人信息的用户只占很少一部分。而对于无社交属性的产品(如输入法、团购APP、视频网站等)用户信息的填充率非常低,有的甚至不足5%。
在这种情况下,我们一般会用填写了信息的这部分用户作为样本,把用户的行为数据作为特征训练模型,对无标签的用户进行人口属性的预测。这种模型把用户的标签传给和他行为相似的用户,可以认为是对人群进行了标签扩散,因此常被称为标签扩散模型。
下面我们用视频网站性别年龄画像的例子来说明标签扩散模型是如何构建的。
一个视频网站,希望了解自己的用户组成,于是对用户的性别进行画像。通过数据统计,有大约30%的用户注册时填写了个人信息,我们将这30%的用户作为训练集,来构建全量用户的性别画像,我们的数据如表10-3所示。
|
Uid |
Gender |
Watched videos |
|
525252 |
Male |
Game of throat |
|
532626 |
Runing men、最强大脑 |
|
|
526267 |
琅琊榜、伪装者 |
|
|
573373 |
Female |
欢乐喜剧人 |
▲表10-3:视频网站用户数据
下面我们来构建特征。通过分析,我们发现男性和女性,对于影片的偏好是有差别的,因此使用观看的影片列表来预测用户性别有一定的可行性。此外我们还可以考虑用户的观看时间、浏览器、观看时长等,为了简化,这里我们只使用用户观看的影片特征。
由于观看影片特征是稀疏特征,我们可以使用调用MLlib,使用LR、线性SVM等模型进行训练。考虑到注册用户填写的用户信息本身的准确率不高,我们可以从30%的样本集中提取准确率较高的部分(如用户信息填写较完备的)用于训练,因此我们整体的训练流程如图10-7所示。
对于预测性别这样的二分类模型,如果行为的区分度较好,一般准确率和覆盖率都可以达到70%左右。

▲图10-7 训练流程
对于人口属性标签,只要有一定的样本标签数据,并找到能够区分标签分类的用户行为特征,就可以构建标签扩散模型。其中使用的技术方法主要是机器学习中的分类技术,常用的模型有LR、FM、SVM、GBDT等。
2. 兴趣画像
兴趣画像是互联网领域使用最广泛的画像,互联网广告、个性化推荐、精准营销等各个领域最核心的标签都是兴趣标签。兴趣画像主要是从用户海量行为日志中进行核心信息的抽取、标签化和统计,因此在构建用户兴趣画像之前需要先对用户有行为的内容进行内容建模。
内容建模需要注意粒度,过细的粒度会导致标签没有泛化能力和使用价值,过粗的粒度会导致没有区分度。
为了保证兴趣画像既有一定的准确度又有较好的泛化性,我们会构建层次化的兴趣标签体系,使用中同时用几个粒度的标签去匹配,既保证了标签的准确性,又保证了标签的泛化性。下面我们用新闻的用户兴趣画像举例,介绍如何构建层次化的兴趣标签。
2.1 内容建模
新闻数据本身是非结构化的,首先需要人工构建一个层次的标签体系。我们考虑如下图10-9的一篇新闻,看看哪些内容可以表示用户的兴趣。

▲图10-9 新闻例子
首先,这是一篇体育新闻,体育这个新闻分类可以表示用户兴趣,但是这个标签太粗了,用户可能只对足球感兴趣,体育这个标签就显得不够准确。
其次,我们可以使用新闻中的关键词,尤其是里面的专有名词(人名、机构名),如“桑切斯”、“阿森纳”、“厄齐尔”,这些词也表示了用户的兴趣。关键词的主要问题在于粒度太细,如果一天的新闻里没有这些关键词出现,就无法给用户推荐内容。
最后,我们希望有一个中间粒度的标签,既有一定的准确度,又有一定的泛化能力。于是我们尝试对关键词进行聚类,把一类关键词当成一个标签,或者把一个分类下的新闻进行拆分,生成像“足球”这种粒度介于关键词和分类之间的主题标签。我们可以使用文本主题聚类完成主题标签的构建。
至此我们就完成了对新闻内容从粗到细的“分类-主题-关键词”三层标签体系内容建模,新闻的三层标签如表10-4所示。
|
分类 |
主题 |
关键词 |
|
|
使用算法 |
文本分类、SVM、LR、Bayes |
PLSA、LDA |
Tf*idf、专门识别、领域词表 |
|
粒度 |
粗 |
中 |
细 |
|
泛化性 |
好 |
中 |
差 |
|
举例 |
体育、财经、娱乐 |
足球、理财 |
梅西、川普、机器学习 |
|
量级 |
10-30 |
100-1000 |
百万 |
▲表10-4 三层标签体系
既然主题的准确率和覆盖率都不错,我们只使用主题不就可以了嘛?为什么还要构建分类和关键词这两层标签呢?这么做是为了给用户进行尽可能精确和全面的内容推荐。
当用户的关键词命中新闻时,显然能够给用户更准确的推荐,这时就不需要再使用主题标签;而对于比较小众的主题(如体育类的冰上运动主题),若当天没有新闻覆盖,我们就可以根据分类标签进行推荐。层次标签兼顾了对用户兴趣刻画的覆盖率和准确性。
2.2 兴趣衰减
在完成内容建模以后,我们就可以根据用户点击,计算用户对分类、主题、关键词的兴趣,得到用户兴趣标签的权重。最简单的计数方法是用户点击一篇新闻,就把用户对该篇新闻的所有标签在用户兴趣上加一,用户对每个词的兴趣计算就使用如下的公式:
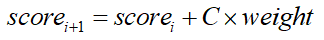
其中:词在这次浏览的新闻中出现C=1,否则C=0,weight表示词在这篇新闻中的权重。
这样做有两个问题:一个是用户的兴趣累加是线性的,数值会非常大,老的兴趣权重会特别高;另一个是用户的兴趣有很强的时效性,昨天的点击要比一个月之前的点击重要的多,线性叠加无法突出近期兴趣。
为了解决这个问题,需要要对用户兴趣得分进行衰减,我们使用如下的方法对兴趣得分进行次数衰减和时间衰减。
次数衰减的公式如下:
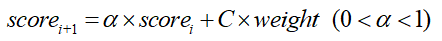
其中,α是衰减因子,每次都对上一次的分数做衰减,最终得分会收敛到一个稳定值 ,α取0.9时,得分会无限接近10。
时间衰减的公式如下:
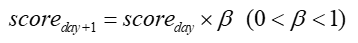
它表示根据时间对兴趣进行衰减,这样做可以保证时间较早的兴趣会在一段时间以后变的非常弱,同时近期的兴趣会有更大的权重。根据用户兴趣变化的速度、用户活跃度等因素,也可以对兴趣进行周级别、月级别或小时级别的衰减。
3. 地理位置画像
地理位置画像一般分为两部分:一部分是常驻地画像;一部分是GPS画像。两类画像的差别很大,常驻地画像比较容易构造,且标签比较稳定,GPS画像需要实时更新。
常驻地包括国家、省份、城市三级,一般只细化到城市粒度。常驻地的挖掘基于用户的IP地址信息,对用户的IP地址进行解析,对应到相应的城市,对用户IP出现的城市进行统计就可以得到常驻城市标签。
用户的常驻城市标签,不仅可以用来统计各个地域的用户分布,还可以根据用户在各个城市之间的出行轨迹识别出差人群、旅游人群等,如图10-10所示是人群出行轨迹的一个示例。
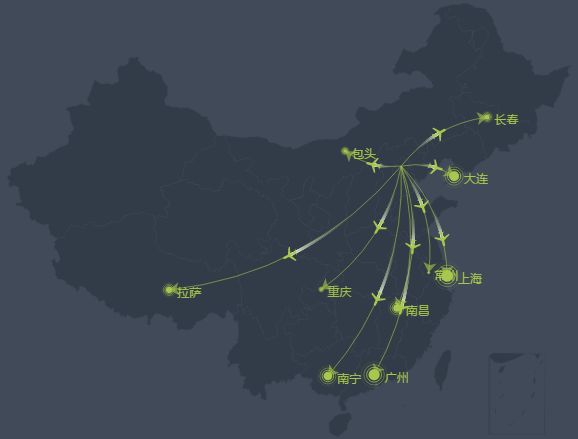
▲图10-10 人群出行轨迹
GPS数据一般从手机端收集,但很多手机APP没有获取用户 GPS信息的权限。能够获取用户GPS信息的主要是百度地图、滴滴打车等出行导航类APP,此外收集到的用户GPS数据比较稀疏。
百度地图使用该方法结合时间段数据,构建了用户公司和家的GPS标签。此外百度地图还基于GPS信息,统计各条路上的车流量,进行路况分析,如图10-11是北京市的实时路况图,红色表示拥堵线路。
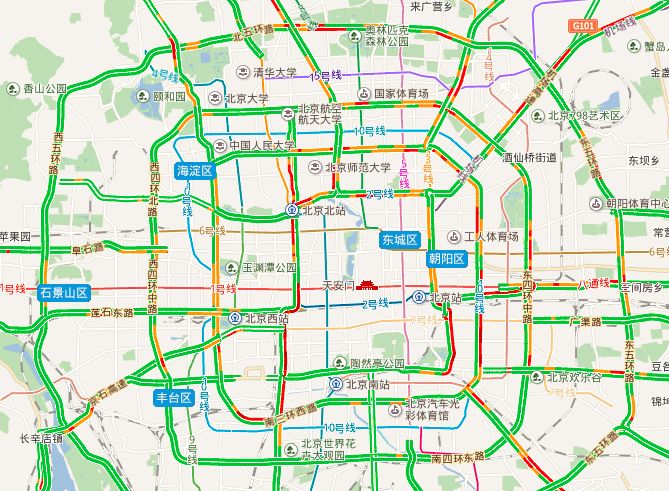
▲图10-11 北京的实时路况图
04 用户画像评估和使用
人口属性画像的相关指标比较容易评估,而兴趣画像的标签比较模糊,兴趣画像的人为评估比较困难,我们对于兴趣画像的常用评估方法是设计小流量的A/B-test进行验证。
我们可以筛选一部分标签用户,给这部分用户进行和标签相关的推送,看标签用户对相关内容是否有更好的反馈。
例如,在新闻推荐中,我们给用户构建了兴趣画像,我们从体育类兴趣用户中选取一小批用户,给他们推送体育类新闻,如果这批用户的点击率和阅读时长明显高于平均水平,就说明标签是有效的。
1. 效果评估
用户画像效果最直接的评估方法就是看其对实际业务的提升,如互联网广告投放中画像效果主要看使用画像以后点击率和收入的提升,精准营销过程中主要看使用画像后销量的提升等。
但是如果把一个没有经过效果评估的模型直接用到线上,风险是很大的,因此我们需要一些上线前可计算的指标来衡量用户画像的质量。
用户画像的评估指标主要是指准确率、覆盖率、时效性等指标。
1.1 准确率
标签的准确率指的是被打上正确标签的用户比例,准确率是用户画像最核心的指标,一个准确率非常低的标签是没有应用价值的。准确率的计算公式如下:
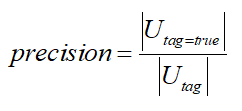
其中| Utag |表示被打上标签的用户数,| Utag=true |表示有标签用户中被打对标签的用户数。准确率的评估一般有两种方法:一种是在标注数据集里留一部分测试数据用于计算模型的准确率;另一种是在全量用户中抽一批用户,进行人工标注,评估准确率。
由于初始的标注数据集的分布和全量用户分布相比可能有一定偏差,故后一种方法的数据更可信。准确率一般是对每个标签分别评估,多个标签放在一起评估准确率是没有意义的。
1.2 覆盖率
标签的覆盖率指的是被打上标签的用户占全量用户的比例,我们希望标签的覆盖率尽可能的高。但覆盖率和准确率是一对矛盾的指标,需要对二者进行权衡,一般的做法是在准确率符合一定标准的情况下,尽可能的提升覆盖率。
我们希望覆盖尽可能多的用户,同时给每个用户打上尽可能多的标签,因此标签整体的覆盖率一般拆解为两个指标来评估。一个是标签覆盖的用户比例,另一个是覆盖用户的人均标签数,前一个指标是覆盖的广度,后一个指标表示覆盖的密度。
用户覆盖比例的计算方法是:
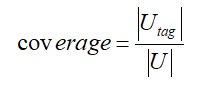
其中| U |表示用户的总数,| Utag |表示被打上标签的用户数。
人均标签数的计算方法是:
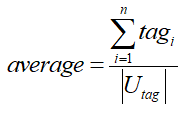
其中| tagi |表示每个用户的标签数,| Utag |表示被打上标签的用户数。覆盖率既可以对单一标签计算,也可以对某一类标签计算,还可以对全量标签计算,这些都是有统计意义的。
1.3 时效性
有些标签的时效性很强,如兴趣标签、出现轨迹标签等,一周之前的就没有意义了;有些标签基本没有时效性,如性别、年龄等,可以有一年到几年的有效期。对于不同的标签,需要建立合理的更新机制,以保证标签时间上的有效性。
1.4 其他指标
标签还需要有一定的可解释性,便于理解;同时需要便于维护且有一定的可扩展性,方便后续标签的添加。这些指标难以给出量化的标准,但在构架用户画像时也需要注意。
2. 画像使用
用户画像在构建和评估之后,就可以在业务中应用,一般需要一个可视化平台,对标签进行查看和检索。画像的可视化一般使用饼图、柱状图等对标签的覆盖人数、覆盖比例等指标做形象的展示,如下图10-12所示是用户画像的一个可视化界面。
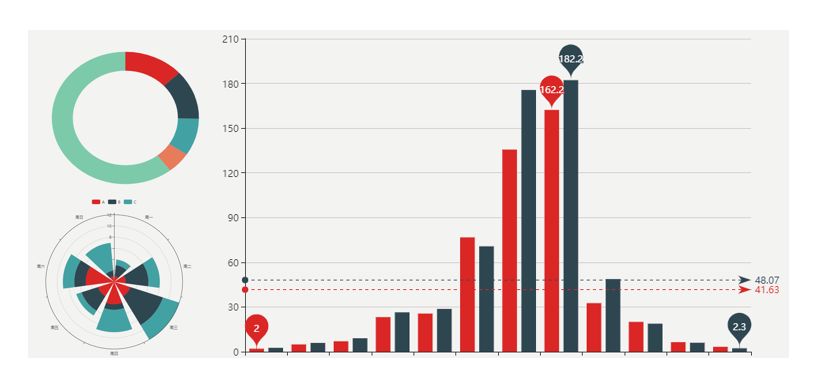
▲图10-12 用户画像的可视化界面
此外,对于构建的画像,我们还可以使用不同维度的标签,进行高级的组合分析,产出高质量的分析报告。在智能营销、计算广告、个性化推荐等领域用户画像都可以得到应用,具体的应用方法,与其应用领域结合比较紧密,我们不再详细介绍。
本文摘编自《Spark机器学习进阶实战》,经出版方授权发布。
延伸阅读《Spark机器学习进阶实战》
点击上图了解及购买
转载请联系微信:togo-maruko
推荐语:科大讯飞大数据专家撰写,从基础到应用,面面俱到。

据统计,99%的大咖都完成了这个神操作
▼
更多精彩
在公众号后台对话框输入以下关键词
查看更多优质内容!
PPT | 报告 | 读书 | 书单
Python | 机器学习 | 深度学习 | 神经网络
区块链 | 揭秘 | 干货 | 数学
猜你想看
-
谁再问你“天天爬那些数据有什么用”,就把这5本书扔给他!
Q: 你都做过哪些网站、app的用户画像?
欢迎留言与大家分享
觉得不错,请把这篇文章分享给你的朋友
转载 / 投稿请联系:baiyu@hzbook.com
更多精彩,请在后台点击“历史文章”查看

 点击阅读原文,了解更多
点击阅读原文,了解更多
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/137563.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
