大家好,又见面了,我是你们的朋友全栈君。
Python爬取豆瓣电影Top250并进行数据分析


利用Python爬取豆瓣电影TOP250并进行数据分析,爬取’排名’,‘电影名称’,‘导演’,‘上映年份’,‘制作国家’,‘类型’,‘评分’,‘评价分数’,’短评’等字段。
手动声明
版权声明:本文为博主原创文章,创作不易
本文链接:https://beishan.blog.csdn.net/article/details/112735850
文章目录
数据爬取
翻页操作
#https://beishan.blog.csdn.net/article/details/112735850
第一页:https://movie.douban.com/top250
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
观察可知,我们只需要修改start参数即可
反爬说明
推荐阅读:
一篇文章带你掌握requests模块
Python网络爬虫基础–BeautifulSoup
matplotlib实用绘图技巧总结
Python 数据可视化–Seaborn绘图总结1
Python数据可视化–Seaborn绘图总结2
Tableau数据分析-Chapter01条形图、堆积图、直方图
Tableau数据分析-Chapter02数据预处理、折线图、饼图
Tableau数据分析-Chapter03基本表、树状图、气泡图、词云
Tableau数据分析-Chapter04标靶图、甘特图、瀑布图
Tableau数据分析-Chapter05数据集合并、符号地图
Tableau数据分析-Chapter06填充地图、多维地图、混合地图
Tableau数据分析-Chapter07多边形地图和背景地图
Tableau数据分析-Chapter08数据分层、数据分组、数据集
Tableau数据分析-Chapter09粒度、聚合与比率
Tableau数据分析-Chapter10 人口金字塔、漏斗图、箱线图
Tableau中国五城市六年PM2.5数据挖掘
通过headers字段来反爬
headers中有很多字段,这些字段都有可能会被对方服务器拿过来进行判断是否为爬虫
1.1 通过headers中的User-Agent字段来反爬
- 反爬原理:爬虫默认情况下没有User-Agent,而是使用模块默认设置
- 解决方法:请求之前添加User-Agent即可;更好的方式是使用User-Agent池来解决(收集一堆User-Agent的方式,或者是随机生成User-Agent)
1.2 通过referer字段或者是其他字段来反爬
- 反爬原理:爬虫默认情况下不会带上referer字段,服务器端通过判断请求发起的源头,以此判断请求是否合法
- 解决方法:添加referer字段
1.3 通过cookie来反爬
- 反爬原因:通过检查cookies来查看发起请求的用户是否具备相应权限,以此来进行反爬
- 解决方案:进行模拟登陆,成功获取cookies之后在进行数据爬取
通过请求参数来反爬
请求参数的获取方法有很多,向服务器发送请求,很多时候需要携带请求参数,通常服务器端可以通过检查请求参数是否正确来判断是否为爬虫
2.1 通过从html静态文件中获取请求数据(github登录数据)
- 反爬原因:通过增加获取请求参数的难度进行反爬
- 解决方案:仔细分析抓包得到的每一个包,搞清楚请求之间的联系
2.2 通过发送请求获取请求数据
- 反爬原因:通过增加获取请求参数的难度进行反爬
- 解决方案:仔细分析抓包得到的每一个包,搞清楚请求之间的联系,搞清楚请求参数的来源
2.3 通过js生成请求参数
- 反爬原理:js生成了请求参数
- 解决方法:分析js,观察加密的实现过程,通过js2py获取js的执行结果,或者使用selenium来实现
2.4 通过验证码来反爬
- 反爬原理:对方服务器通过弹出验证码强制验证用户浏览行为
- 解决方法:打码平台或者是机器学习的方法识别验证码,其中打码平台廉价易用,更值得推荐
在这里我们只需要添加请求头即可
数据定位
这里我使用的是xpath
推荐阅读:
也可以使用BeautifulSoup来定位数据
# -*- coding: utf-8 -*-
# @Author: Kun
import requests
from lxml import etree
import pandas as pd
df = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4343.0 Safari/537.36',
'Referer': 'https://movie.douban.com/top250'}
columns = ['排名','电影名称','导演','上映年份','制作国家','类型','评分','评价分数','短评']
def get_data(html):
xp = etree.HTML(html)
lis = xp.xpath('//*[@id="content"]/div/div[1]/ol/li')
for li in lis:
"""排名、标题、导演、演员、"""
ranks = li.xpath('div/div[1]/em/text()')
titles = li.xpath('div/div[2]/div[1]/a/span[1]/text()')
directors = li.xpath('div/div[2]/div[2]/p[1]/text()')[0].strip().replace("\xa0\xa0\xa0","\t").split("\t")
infos = li.xpath('div/div[2]/div[2]/p[1]/text()')[1].strip().replace('\xa0','').split('/')
dates,areas,genres = infos[0],infos[1],infos[2]
ratings = li.xpath('.//div[@class="star"]/span[2]/text()')[0]
scores = li.xpath('.//div[@class="star"]/span[4]/text()')[0][:-3]
quotes = li.xpath('.//p[@class="quote"]/span/text()')
for rank,title,director in zip(ranks,titles,directors):
if len(quotes) == 0:
quotes = None
else:
quotes = quotes[0]
df.append([rank,title,director,dates,areas,genres,ratings,scores,quotes])
d = pd.DataFrame(df,columns=columns)
d.to_excel('Top250.xlsx',index=False)
for i in range(0,251,25):
url = "https://movie.douban.com/top250?start={}&filter=".format(str(i))
res = requests.get(url,headers=headers)
html = res.text
get_data(html)
原文链接:https://blog.csdn.net/qq_45176548/article/details/112735850
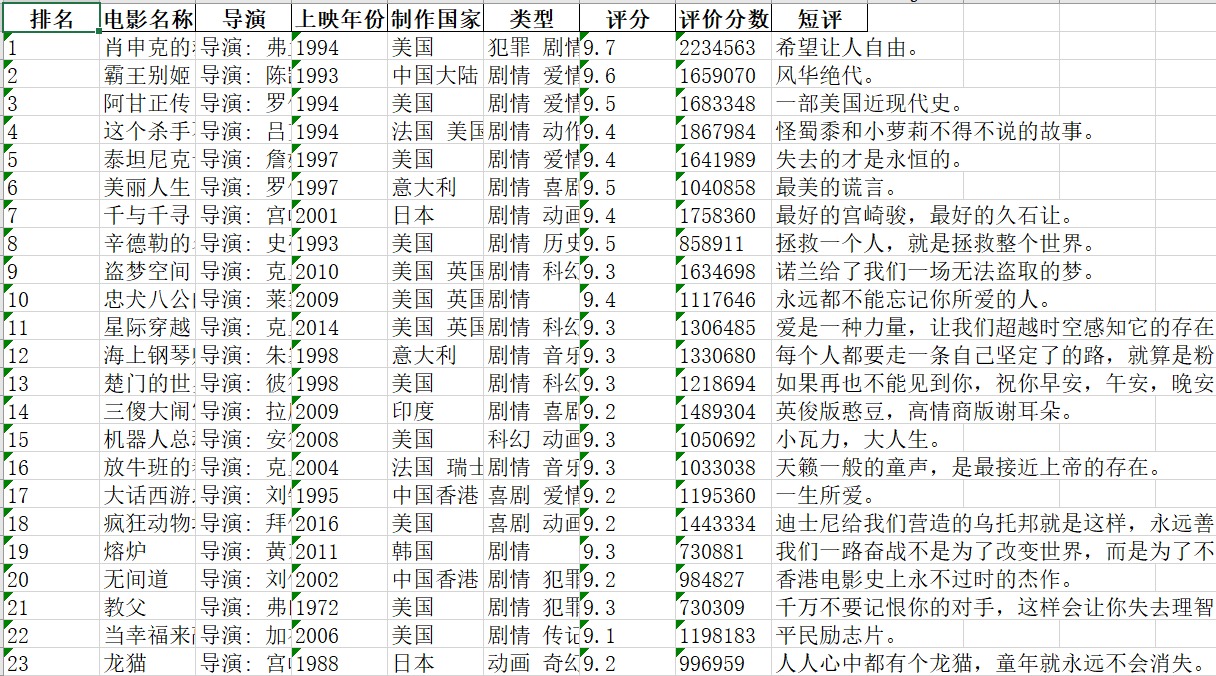
结果如下:
- 使用面向对象+线程
# -*- coding: utf-8 -*-
""" Created on Tue Feb 2 15:19:29 2021 @author: 北山啦 """
import pandas as pd
import time
import requests
from lxml import etree
from queue import Queue
from threading import Thread, Lock
class Movie():
def __init__(self):
self.df = []
self.headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4343.0 Safari/537.36',
'Referer': 'https://movie.douban.com/top250'}
self.columns = ['排名','电影名称','导演','上映年份','制作国家','类型','评分','评价分数','短评']
self.lock = Lock()
self.url_list = Queue()
def get_url(self):
url = 'https://movie.douban.com/top250?start={}&filter='
for i in range(0,250,25):
self.url_list.put(url.format(str(i)))
def get_html(self):
while True:
if not self.url_list.empty():
url = self.url_list.get()
resp = requests.get(url,headers=self.headers)
html = resp.text
self.xpath_parse(html)
else:
break
def xpath_parse(self,html):
xp = etree.HTML(html)
lis = xp.xpath('//*[@id="content"]/div/div[1]/ol/li')
for li in lis:
"""排名、标题、导演、演员、"""
ranks = li.xpath('div/div[1]/em/text()')
titles = li.xpath('div/div[2]/div[1]/a/span[1]/text()')
directors = li.xpath('div/div[2]/div[2]/p[1]/text()')[0].strip().replace("\xa0\xa0\xa0","\t").split("\t")
infos = li.xpath('div/div[2]/div[2]/p[1]/text()')[1].strip().replace('\xa0','').split('/')
dates,areas,genres = infos[0],infos[1],infos[2]
ratings = li.xpath('.//div[@class="star"]/span[2]/text()')[0]
scores = li.xpath('.//div[@class="star"]/span[4]/text()')[0][:-3]
quotes = li.xpath('.//p[@class="quote"]/span/text()')
for rank,title,director in zip(ranks,titles,directors):
if len(quotes) == 0:
quotes = None
else:
quotes = quotes[0]
self.df.append([rank,title,director,dates,areas,genres,ratings,scores,quotes])
d = pd.DataFrame(self.df,columns=self.columns)
d.to_excel('douban.xlsx',index=False)
def main(self):
start_time = time.time()
self.get_url()
th_list = []
for i in range(5):
th = Thread(target=self.get_html)
th.start()
th_list.append(th)
for th in th_list:
th.join()
end_time = time.time()
print(end_time-start_time)
if __name__ == '__main__':
spider = Movie()
spider.main()
数据分析
获取数据后,就可以对自己感兴趣的内容进行分析了
数据预处理
df = pd.read_excel("Top250.xlsx",index_col=False)
df.head()
- 上映年份格式不统一
year = []
for i in df["上映年份"]:
i = i[0:4]
year.append(i)
df["上映年份"] = year
df["上映年份"].value_counts()
x1 = list(df["上映年份"].value_counts().sort_index().index)
y1 = list(df["上映年份"].value_counts().sort_index().values)
y1 = [str(i) for i in y1]
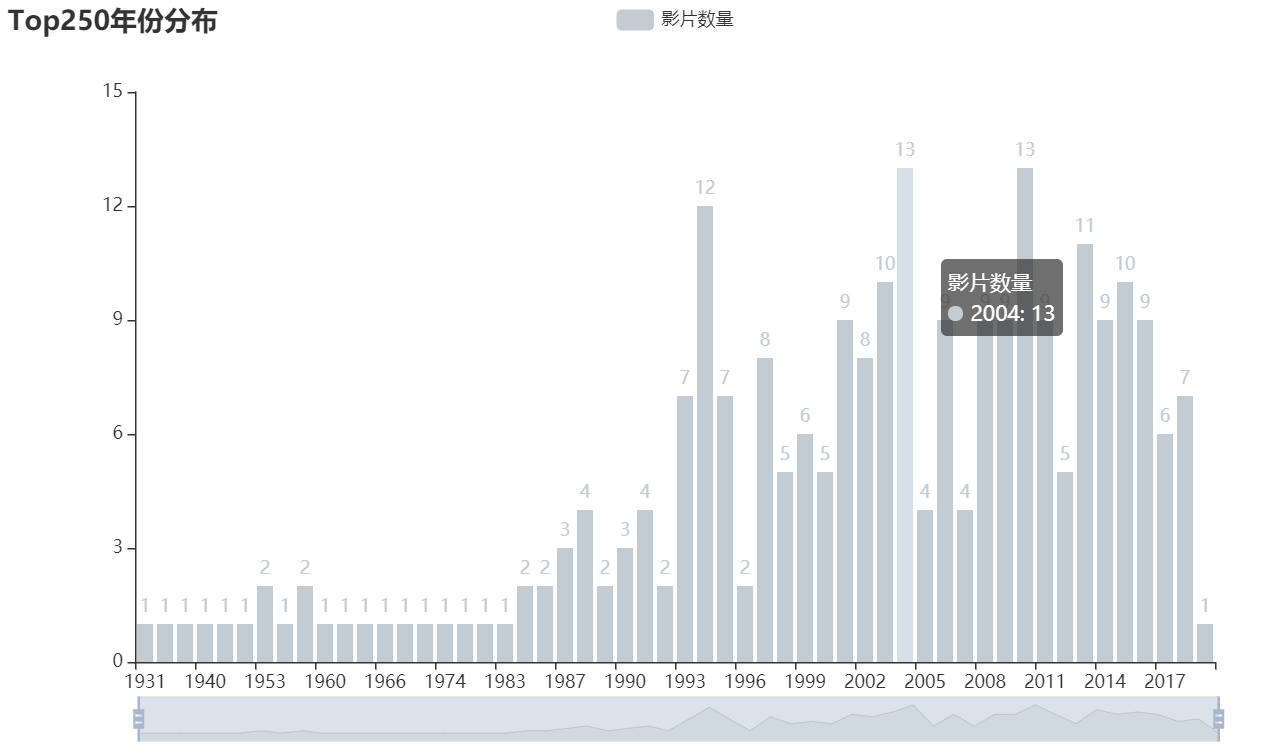
上映年份分布
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.faker import Faker
c1 = (
Bar()
.add_xaxis(x1)
.add_yaxis("影片数量", y1)
.set_global_opts(
title_opts=opts.TitleOpts(title="Top250年份分布"),
datazoom_opts=opts.DataZoomOpts(),
)
.render("1.html")
)
-
这里可以看出豆瓣电影TOP250里,电影的上映年份,多分布于80年代以后。其中有好几年是在10部及以上的。
-
从年份的分布情况看,大部分高分电影都上映在 1987 年之后,并且随着时间逐渐增加,而近两年的高分电影的数量相对比较少。
评分分布情况
plt.figure(figsize=(10,6))
plt.hist(list(df["评分"]),bins=8,facecolor="blue", edgecolor="black", alpha=0.7)
plt.show()
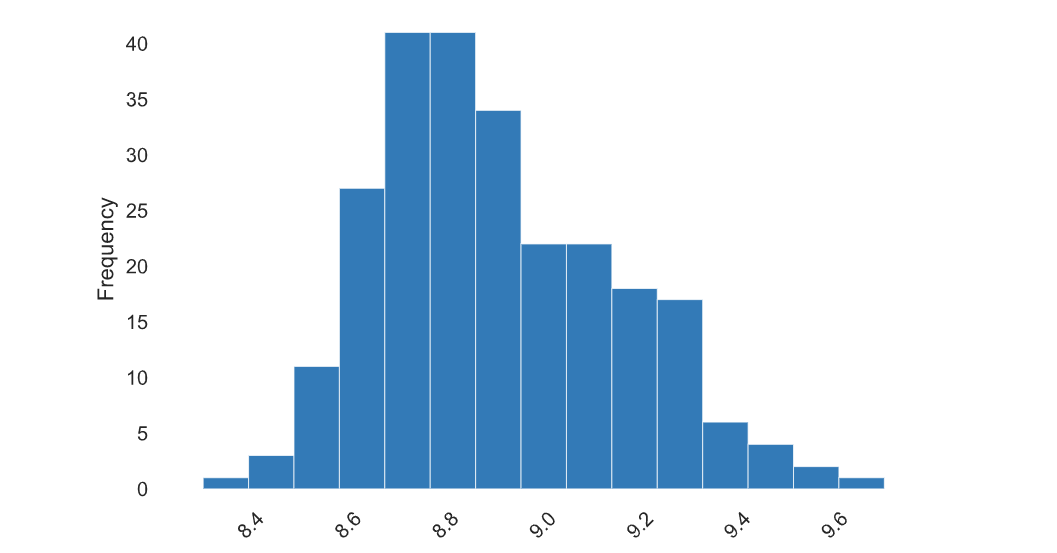
-
从上图分析,随着评分升高,排名也基本靠前,评分主要集中在 8.4~9.2 之间。同时可以通过 pandas 计算平均数,众数和相关系数,平均分为 8.83 分,众数为 8.7 分,而相关系数为 -0.6882,评分与排名强相关。
-
大多分布于「8.5」到「9.2」之间。最低「8.3」,最高「9.6」
排名与评分分布情况
plt.figure(figsize=(10,5), dpi=100)
plt.scatter(df.index,df['评分'])
plt.show()
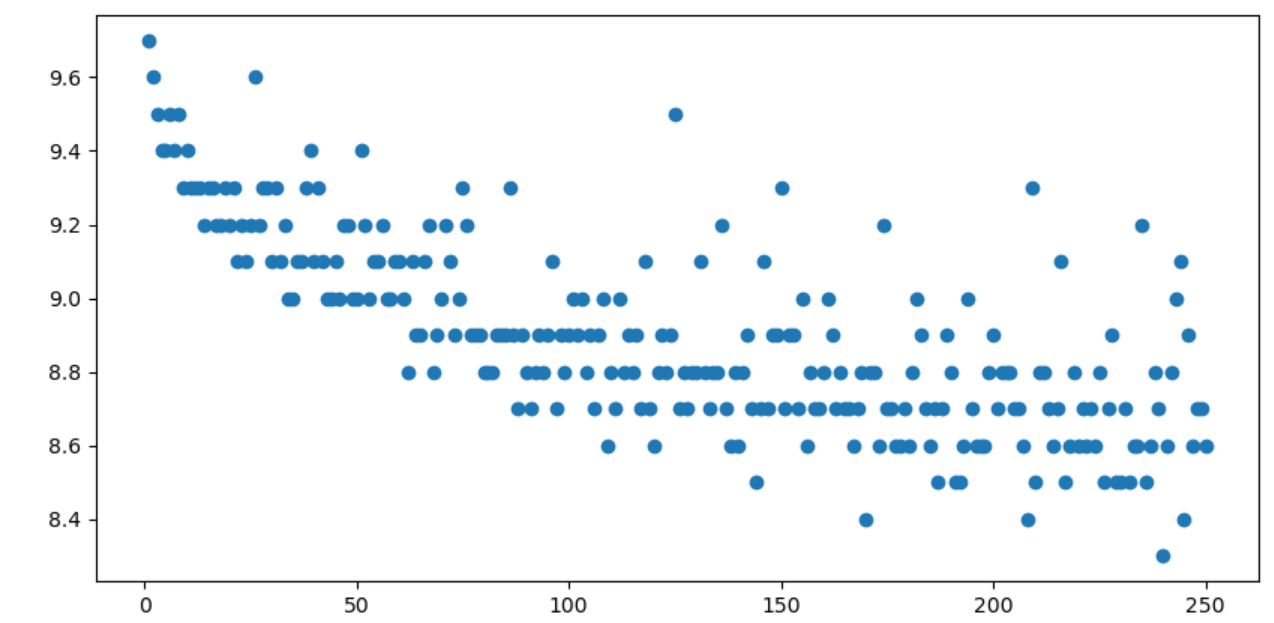
总的来说,排名越靠前,评价人数越多,并且分数也越高。
评论人数TOP10
c2 = (
Bar()
.add_xaxis(df1["电影名称"].to_list())
.add_yaxis("评论数", df1["评价分数"].to_list(),color=Faker.rand_color())
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title="电影评论Top10"))
.render("2.html")
)
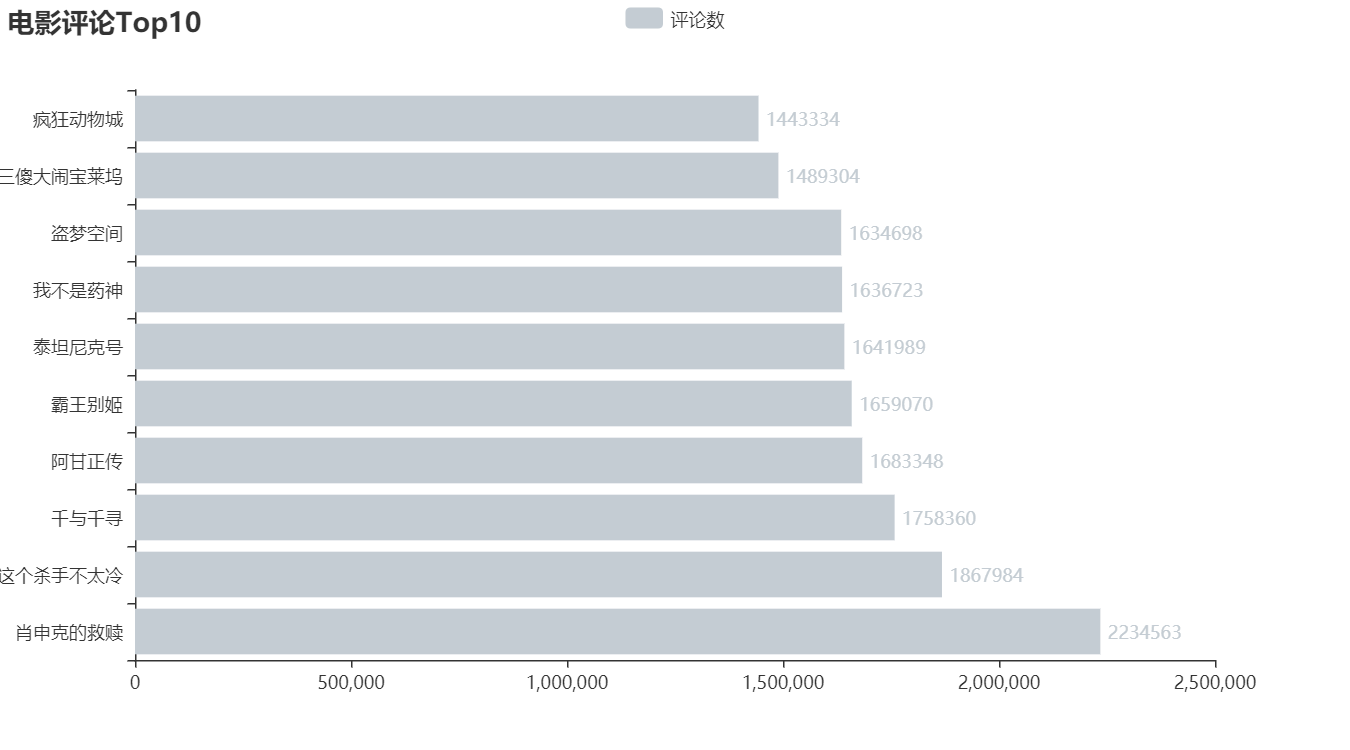
让我们来看看人气最高的有哪些影片,你又看过几部呢?
导演排名
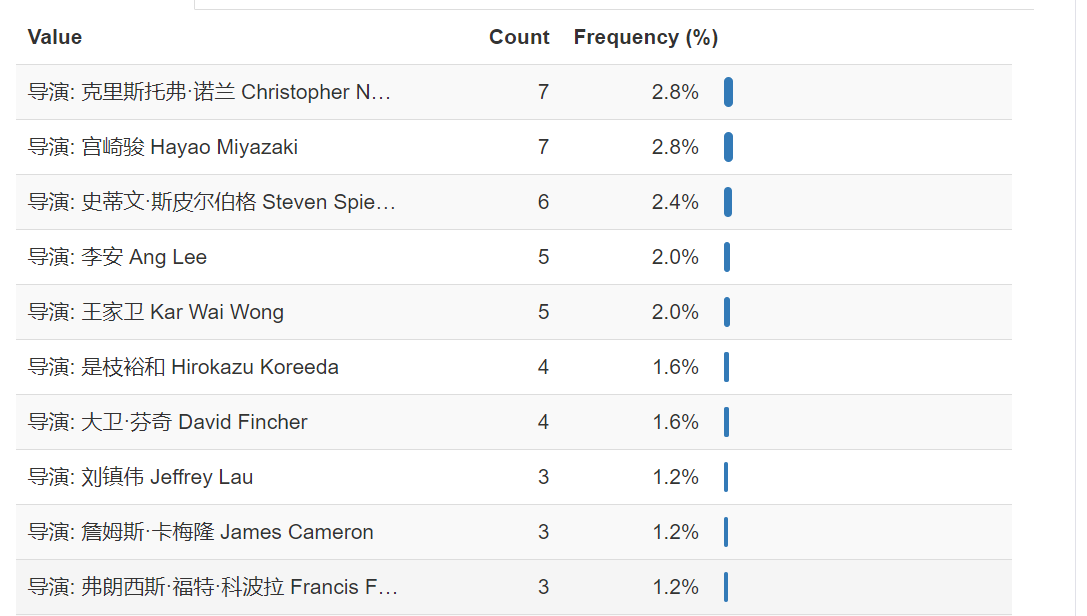
可以看到这些导演很?呀
电影类型图
from collections import Counter
colors = ' '.join([i for i in df[ '类型']]).strip().split()
c = dict(Counter(colors))
c
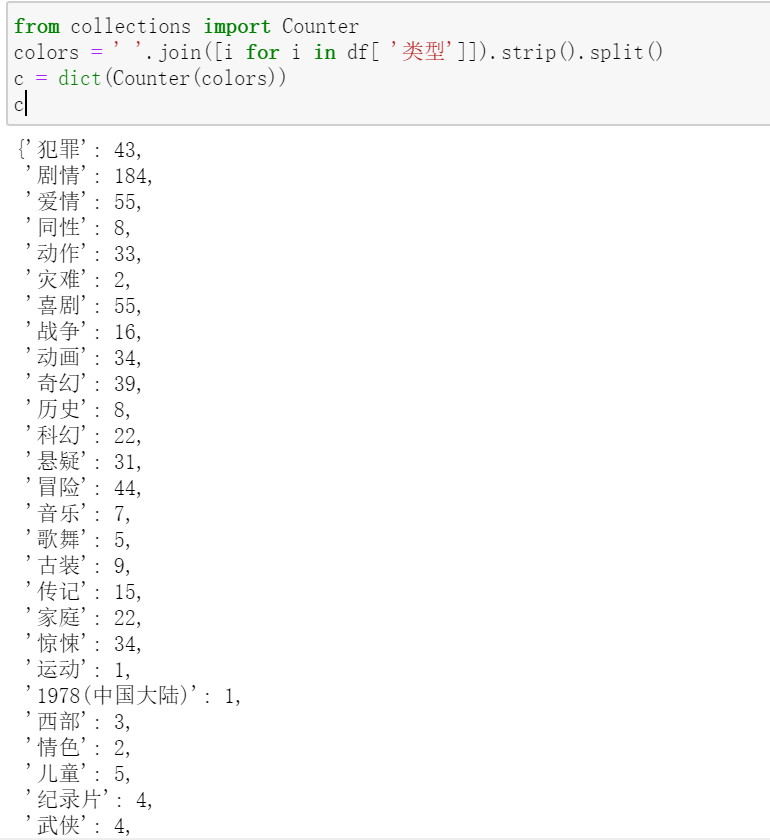
发现有个错误值
d = c.pop('1978(中国大陆)')
删除即可
- 对于删除字典的值有以下方法
方法一 pop(key[,default])
d = {
'a':1,'b':2,'c':3}
# 删除key值为'a'的元素,并赋值给变量e1
e1 = d.pop('a')
print(e1)
# 如果key不存在,则可以设置返回值
e2 = d.pop('m','404')
print(e2)
# 如果key不存在,不设置返回值就报错
e3 = d.pop('m')
方法二 del[d[key]]
d = {
'a':1,'b':2,'c':3}
# 删除给定key的元素
del d['a']
print(d)
# 删除不存在的元素
del d['m']
clear一次性删除所有字典元素
d = {
'a':1,'b':2,'c':3}
print(d)
# 删除所有元素,允许d为{}
d.clear()
print(d)
统计展示
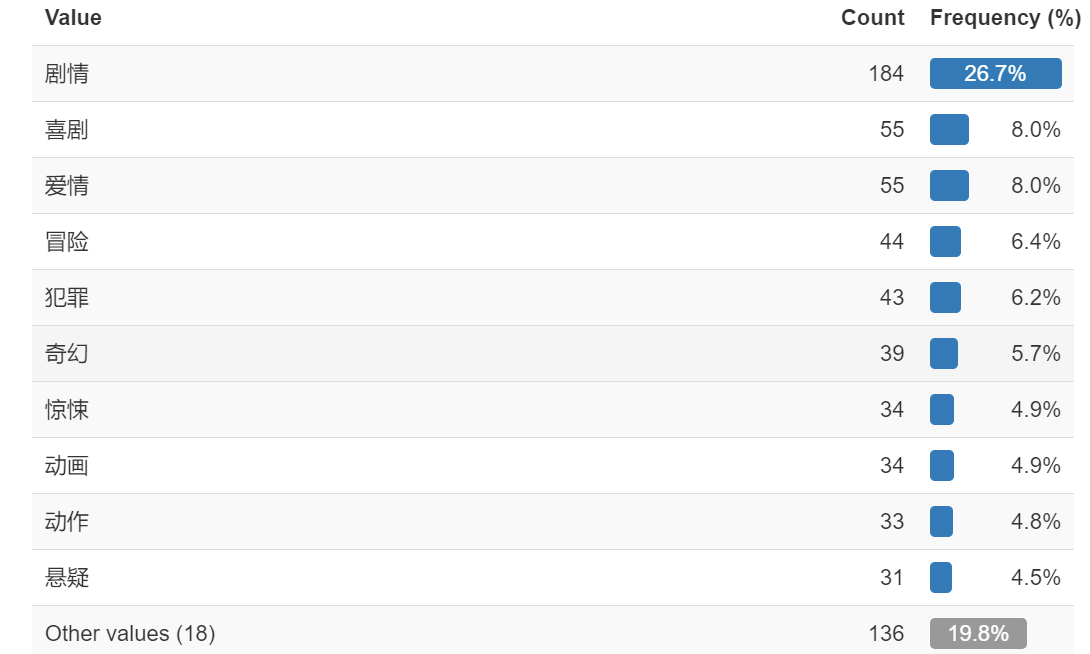
可视化展示
c = (
WordCloud()
.add(
"",
words,
word_size_range=[20, 100],
textstyle_opts=opts.TextStyleOpts(font_family="cursive"),
)
.set_global_opts(title_opts=opts.TitleOpts(title="WordCloud-自定义文字样式"))
.render("wordcloud_custom_font_style.html")
)
## https://blog.csdn.net/qq_45176548/article/details/112735850

往期回顾
- 冰冰B站视频弹幕爬取原理解析
- Python建立时间序列ARIMA模型实战案例
- 使用xpath爬取数据
- jupyter notebook使用
- BeautifulSoup爬取豆瓣电影Top250
- 一篇文章带你掌握requests模块
- Python网络爬虫基础–BeautifulSoup
到这里就结束了,如果对你有帮助,欢迎点赞关注评论,你的点赞对我很重要

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/137561.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
