大家好,又见面了,我是你们的朋友全栈君。
多重共线性在python中的解决方法
本文将讨论多重共线性的相关概念及利用python自动化消除多重共线性的方法,以供参考,欢迎拍砖
线性模型与非线性模型
关于线性模型与非线性模型的定义,似乎并没有确切的定论,但是个人认为建模首先得清楚地认识样本,样本有线性可分与线性不可分两种,所谓是否线性可分,是指是否存在一条直线(或平面)将样本分开。
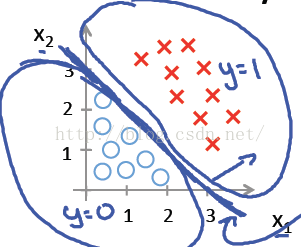

上图中y=0和y=1的样本可以由一条直线分开,如逻辑回归模型最佳的应用样本即为上图样本(线性可分);如果样本是线性不可分,决策树等模型可以更有效地将样本分开,此时选择逻辑回归分类结果可能较差。
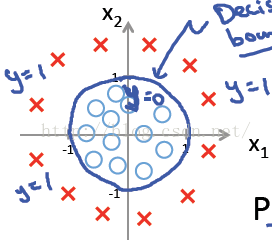
如上图中的样本,使用逻辑回归可能取得较差的分类效果。但是如果将特征映射到更高维空间,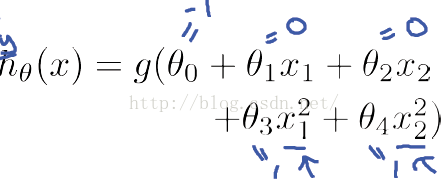
上式在二维直角坐标系中表现为圆,就可以将图中样本分开。
因此总结来说
- 选择何种模型取决于数据本身,线性可分数据使用逻辑回归等可以线性分开数据的线性模型可以取得更好的分类效果;线性不可分数据则不适合。
- 传统的线性模型可以通过将特征映射到高维空间中达到线性分开数据的目的,如SVM采用核技巧,逻辑回归加入原始特征的高维转换等。
多重共线性对线性回归和逻辑回归的影响
多重共线性是指在变量空间中,存在自变量可以近似地等于其他自变量的线性组合:
Y 约等于 W1X1 + W2X2 + … + Wn*Xn
此时如果将所有自变量用于线性回归或逻辑回归的建模,将导致模型系数不能准确表达自变量对Y的影响。比如:如果X1和X2近似相等,则模型Y = X1 + X2 可能被拟合成Y = 3 X1 – X2,原来 X2 与 Y 正向相关被错误拟合成负相关,导致模型没法在业务上得到解释。在评分卡建模中,可能将很多相关性很高的变量加入到建模自变量中,最终得到的模型如果用变量系数去解释自变量与目标变量的关系是不合适的。
VIF 和相关系数
相关矩阵是指由样本的相关系数组成的矩阵,自变量相关系数过大意味着存在共线性,同时会导致信息冗余,维度增加。设置相关系数的阈值,当大于threshold时,删除IV值较小的变量(IV值的定义及计算后文解释)。
VIF(variance inflation factors)VIF =1/(1-R^2) 式中,R^2是以xj为因变量时对其它自变量回归的复测定系数。VIF越大,该变量与其他的变量的关系越高,多重共线性越严重。如果所有变量最大的VIF超过10,删除最大VIF的变量。
解决方案(利用statsmodels.stats)
利用相关系数删除相关性过高的变量(df中变量先得按IV值从大到小排序)
def get_var_no_colinear(cutoff, df):
corr_high = df.corr().applymap(lambda x: np.nan if x>cutoff else x).isnull()
col_all = corr_high.columns.tolist()
del_col = []
i = 0
while i < len(col_all)-1:
ex_index = corr_high.iloc[:,i][i+1:].index[np.where(corr_high.iloc[:,i][i+1:])].tolist()
for var in ex_index:
col_all.remove(var)
corr_high = corr_high.loc[col_all, col_all]
i += 1
return col_all
利用VIF删除导致高共线性的变量
import numpy as np
import pandas as pd
from statsmodels.stats.outliers_influence import variance_inflation_factor
## 每轮循环中计算各个变量的VIF,并删除VIF>threshold 的变量
def vif(X, thres=10.0):
col = list(range(X.shape[1]))
dropped = True
while dropped:
dropped = False
vif = [variance_inflation_factor(X.iloc[:,col].values, ix)
for ix in range(X.iloc[:,col].shape[1])]
maxvif = max(vif)
maxix = vif.index(maxvif)
if maxvif > thres:
del col[maxix]
print('delete=',X_train.columns[col[maxix]],' ', 'vif=',maxvif )
dropped = True
print('Remain Variables:', list(X.columns[col]))
print('VIF:', vif)
return list(X.columns[col])
如果对原理和代码有问题。欢迎一起讨论哦,IV值的定义及计算后面再讲哈
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/137450.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
