大家好,又见面了,我是你们的朋友全栈君。
本文会简述大数据分析场景需要解决的技术挑战,讨论目前主流大数据架构模式及其发展。最后我们将介绍如何结合云上存储、计算组件,实现更优的通用大数据架构模式,以及该模式可以涵盖的典型数据处理场景。
大数据处理的挑战
现在已经有越来越多的行业和技术领域需求大数据分析系统,例如金融行业需要使用大数据系统结合VaR(value at risk)或者机器学习方案进行信贷风控,零售、餐饮行业需要大数据系统实现辅助销售决策,各种IOT场景需要大数据系统持续聚合和分析时序数据,各大科技公司需要建立大数据分析中台等等。
抽象来看,支撑这些场景需求的分析系统,面临的都是大致相同的技术挑战:
- 业务分析的数据范围横跨实时数据和历史数据,既需求低延迟的实时数据分析,也需求对PB级的历史数据进行探索性的数据分析;
- 可靠性和可扩展性问题,用户可能会存储海量的历史数据,同时数据规模有持续增长的趋势,需要引入分布式存储系统来满足可靠性和可扩展性需求,同时保证成本可控;
- 技术栈深,需要组合流式组件、存储系统、计算组件和;
- 可运维性要求高,复杂的大数据架构难以维护和管控;
简述大数据架构发展
Lambda架构
Lambda架构是目前影响最深刻的大数据处理架构,它的核心思想是将不可变的数据以追加的方式并行写到批和流处理系统内,随后将相同的计算逻辑分别在流和批系统中实现,并且在查询阶段合并流和批的计算视图并展示给用户。Lambda的提出者Nathan Marz还假定了批处理相对简单不易出现错误,而流处理相对不太可靠,因此流处理器可以使用近似算法,快速产生对视图的近似更新,而批处理系统会采用较慢的精确算法,产生相同视图的校正版本。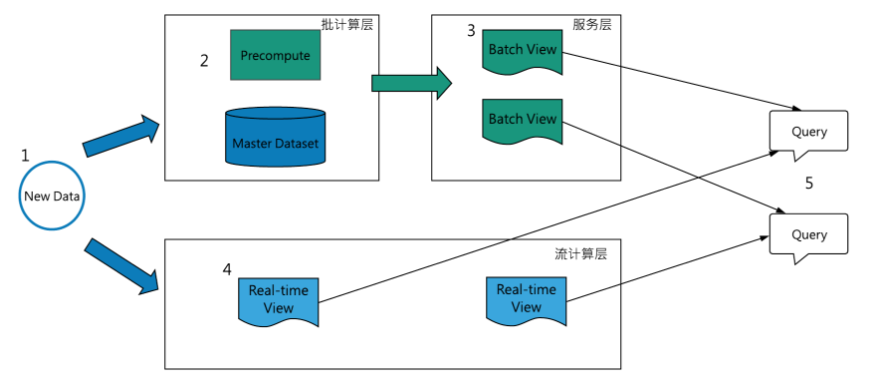

图 1 Lambda架构示例
Lambda架构典型数据流程是(http://lambda-architecture.net/):
- 所有的数据需要分别写入批处理层和流处理层;
- 批处理层两个职责:(i)管理master dataset(存储不可变、追加写的全量数据), (ii)预计算batch view;
- 服务层对batch view建立索引,以支持低延迟、ad-hoc方式查询view;
- 流计算层作为速度层,对实时数据计算近似的real-time view,作为高延迟batch view的补偿快速视图;
- 所有的查询需要合并batch view和real-time view;
Lambda架构设计推广了在不可变的事件流上生成视图,并且可以在必要时重新处理事件的原则,该原则保证了系统随需求演进时,始终可以创建相应的新视图出来,切实可行的满足了不断变化的历史数据和实时数据分析需求。
Lambda架构的四个挑战
Lambda架构非常复杂,在数据写入、存储、对接计算组件以及展示层都有复杂的子课题需要优化:
- 写入层上,Lambda没有对数据写入进行抽象,而是将双写流批系统的一致性问题反推给了写入数据的上层应用;
- 存储上,以HDFS为代表的master dataset不支持数据更新,持续更新的数据源只能以定期拷贝全量snapshot到HDFS的方式保持数据更新,数据延迟和成本比较大;
- 计算逻辑需要分别在流批框架中实现和运行,而在类似Storm的流计算框架和Hadoop MR的批处理框架做job开发、调试、问题调查都是比较复杂的;
- 结果视图需要支持低延迟的查询分析,通常还需要将数据派生到列存分析系统,并保证成本可控;
流批融合的Lambda架构
针对Lambda架构的问题3,计算逻辑需要分别在流批框架中实现和运行的问题,不少计算引擎已经开始往流批统一的方向去发展,例如Spark和Flink,从而简化lambda架构中的计算部分。实现流批统一通常需要支持:1.以相同的处理引擎来处理实时事件和历史回放事件;2.支持exactly once语义,保证有无故障情况下计算结果完全相同;3.支持以事件发生时间而不是处理时间进行窗口化;
Kappa架构
Kappa架构由Jay Kreps提出,不同于Lambda同时计算流计算和批计算并合并视图,Kappa只会通过流计算一条的数据链路计算并产生视图。Kappa同样采用了重新处理事件的原则,对于历史数据分析类的需求,Kappa要求数据的长期存储能够以有序log流的方式重新流入流计算引擎,重新产生历史数据的视图。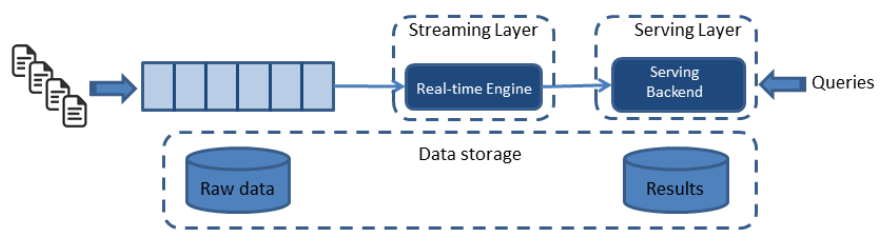
图2 Kappa大数据架构
Kappa方案通过精简链路解决了1数据写入和3计算逻辑复杂的问题,但它依然没有解决存储和展示的问题,特别是在存储上,使用类似kafka的消息队列存储长期日志数据,数据无法压缩,存储成本很大,绕过方案是使用支持数据分层存储的消息系统(如Pulsar,支持将历史消息存储到云上存储系统),但是分层存储的历史日志数据仅能用于Kappa backfill作业,数据的利用率依然很低。
Lambda和Kappa的场景区别:
- Kappa不是Lambda的替代架构,而是其简化版本,Kappa放弃了对批处理的支持,更擅长业务本身为append-only数据写入场景的分析需求,例如各种时序数据场景,天然存在时间窗口的概念,流式计算直接满足其实时计算和历史补偿任务需求;
- Lambda直接支持批处理,因此更适合对历史数据有很多ad hoc查询的需求的场景,比如数据分析师需要按任意条件组合对历史数据进行探索性的分析,并且有一定的实时性需求,期望尽快得到分析结果,批处理可以更直接高效地满足这些需求;
Kappa+
Kappa+是Uber提出流式数据处理架构,它的核心思想是让流计算框架直读HDFS类的数仓数据,一并实现实时计算和历史数据backfill计算,不需要为backfill作业长期保存日志或者把数据拷贝回消息队列。Kappa+将数据任务分为无状态任务和时间窗口任务,无状态任务比较简单,根据吞吐速度合理并发扫描全量数据即可,时间窗口任务的原理是将数仓数据按照时间粒度进行分区存储,窗口任务按时间序一次计算一个partition的数据,partition内乱序并发,所有分区文件全部读取完毕后,所有source才进入下个partition消费并更新watermark。事实上,Uber开发了Apache hudi框架来存储数仓数据,hudi支持更新、删除已有parquet数据,也支持增量消费数据更新部分,从而系统性解决了问题2存储的问题。下图3是完整的Uber大数据处理平台,其中Hadoop -> Spark -> Analytical data user涵盖了Kappa+数据处理架构。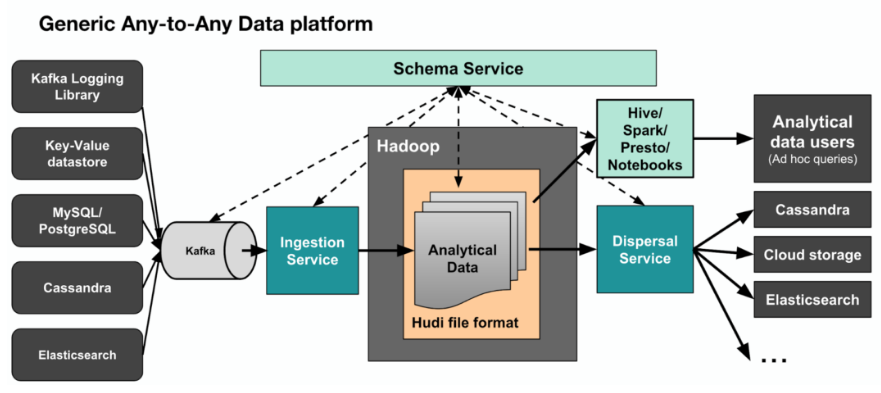
图3 Uber围绕Hadoop dataset的大数据架构
混合分析系统的Kappa架构
Lambda和Kappa架构都还有展示层的困难点,结果视图如何支持ad-hoc查询分析,一个解决方案是在Kappa基础上衍生数据分析流程,如下图4,在基于使用Kafka + Flink构建Kappa流计算数据架构,针对Kappa架构分析能力不足的问题,再利用Kafka对接组合ElasticSearch实时分析引擎,部分弥补其数据分析能力。但是ElasticSearch也只适合对合理数据量级的热数据进行索引,无法覆盖所有批处理相关的分析需求,这种混合架构某种意义上属于Kappa和Lambda间的折中方案。
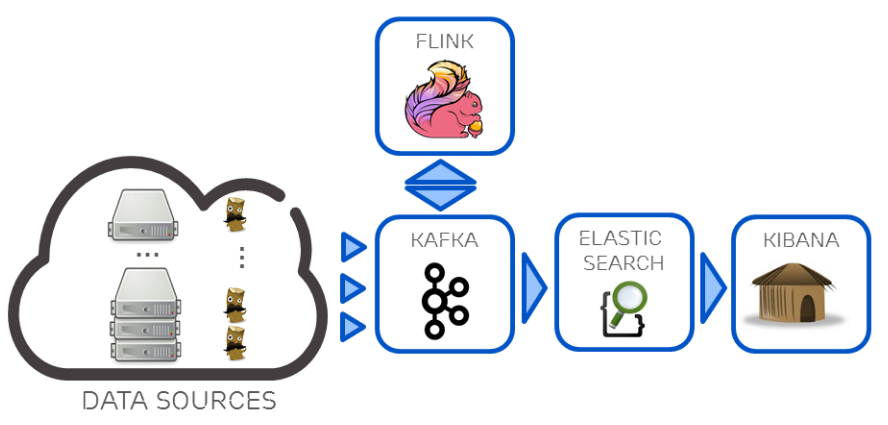
图4 Kafka + Flink + ElasticSearch的混合分析系统
Lambda plus:Tablestore + Blink流批一体处理框架
Lambda plus是基于Tablestore和Blink打造的云上存在可以复用、简化的大数据架构模式,架构方案全serverless即开即用,易搭建免运维。
表格存储(Tablestore)是阿里云自研的NoSQL多模型数据库,提供PB级结构化数据存储、千万TPS以及毫秒级延迟的服务能力,表格存储提供了通道服务(TunnelService)支持用户以按序、流式地方式消费写入表格存储的存量数据和实时数据,同时表格存储还提供了多元索引功能,支持用户对结果视图进行实时查询和分析。
Blink是阿里云在Apache Flink基础上深度改进的实时计算平台,Blink旨在将流处理和批处理统一,实现了全新的 Flink SQL 技术栈,在功能上,Blink支持现在标准 SQL 几乎所有的语法和语义,在性能上,Blink也比社区Flink更加强大。
在TableStore + blink的云上Lambda架构中,用户可以同时使用表格存储作为master dataset和batch&stream view,批处理引擎直读表格存储产生batch view,同时流计算引擎通过Tunnel Service流式处理实时数据,持续生成stream view。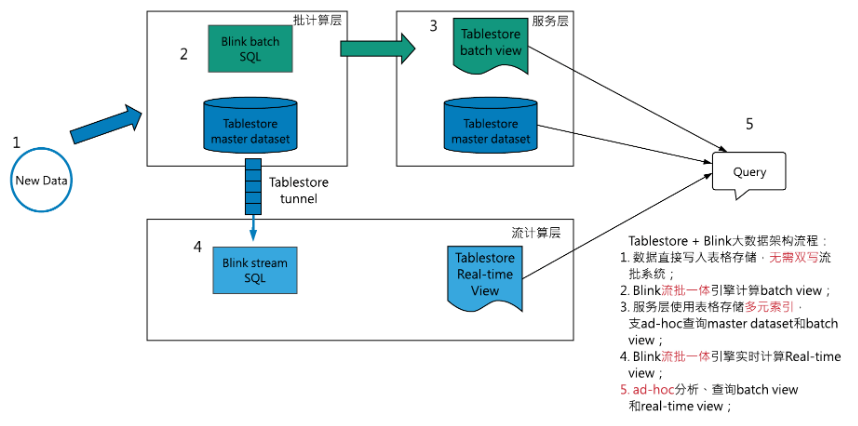
图5 Tablestore + Blink的Lambda plus大数据架构
如上图5,其具体组件分解:
-
Lambda batch层:
- Tablestore直接作为master dataset,支持用户直读,配合Tablestore多元索引,用户的线上服务直读、ad-hoc查询master dataset并将结果返回给用户;
- blink批处理任务向Tablestore下推SQL的查询条件,直读Tablestore master dataset,计算batch view,并将batch view重新写回Tablestore;
-
Streaming层:
- blink流处理任务通过表格存储TunnelService API直读master dataset中的实时数据,持续产生stream view;
- Kappa架构的backfill任务,可以通过建立全量类型数据通道,流式消费master dataset的存量数据,从新计算;
-
Serving层:
- 为存储batch view和stream view的Tablestore结果表建立全局二级索引和多元索引,业务可以低延迟、ad-hoc方式查询;
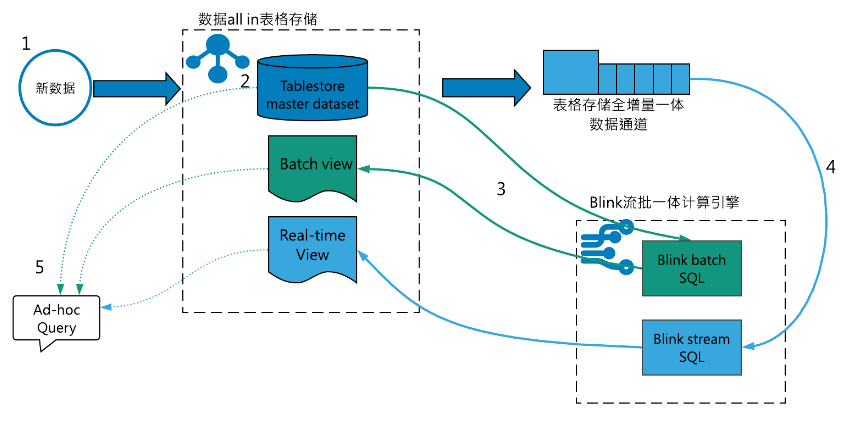
图6 Lambda plus的数据链路
针对上述Lambda架构1-4的技术问题,Lambda plus的解决思路:
- 针对数据写入的问题,Lambda plus数据只需要写入表格存储,Blink流计算框架通过通道服务API直读表格存储的实时数据,不需要用户双写队列或者自己实现数据同步;
- 存储上,Lambda plus直接使用表格存储作为master dataset,表格存储支持用户tp系统低延迟读写更新,同时也提供了索引功能ad-hoc查询分析,数据利用率高,容量型表格存储实例也可以保证数据存储成本可控;
- 计算上,Lambda plus利用blink流批一体计算引擎,统一流批代码;
- 展示层,表格存储提供了多元索引和全局二级索引功能,用户可以根据解决视图的查询需求和存储体量,合理选择索引方式;
总结,表格存储实现了batch view、master dataset直接查询、stream view的功能全集,Blink实现流批统一,Tablestore加blink的Lambda plus模式可以明显简化Lambda架构的组件数量,降低搭建和运维难度,拓展用户数据价值。
表格存储是如何实现支持上述功能全集的
-
存储引擎的高并发、低延迟特性:
- 表格存储面向在线业务提供高并发、低延迟的访问,并且tps按分区水平扩展,可以有效支持批处理和Kappa backfill的高吞吐数据扫描和流计算按分区粒度并发实时处理;
-
使用通道服务精简架构:
- Tablestore数据通道支持用户以按序、流式地方式消费写入表格存储的存量数据和实时数据,避免Lambda架构引入消息队列系统以及master dataset和队列的数据一致性问题;
-
- 存储在表格存储的batch view和real-time view可以使用多元索引和二级索引实现ad-hoc查询,使用多元索引进行聚合分析计算;
- 同时展示层也可以利用二级索引和多元索引直接查询表格存储master dataset,不强依赖引擎计算结果;
Lambda plus的适用场景
基于Tablestore和Blink的Lambda plus架构,适用于基于分布式NoSQL数据库存储数据的大数据分析场景,如IOT、时序数据、爬虫数据、用户行为日志数据存储等,数据量以TB级为主。典型的业务场景如:
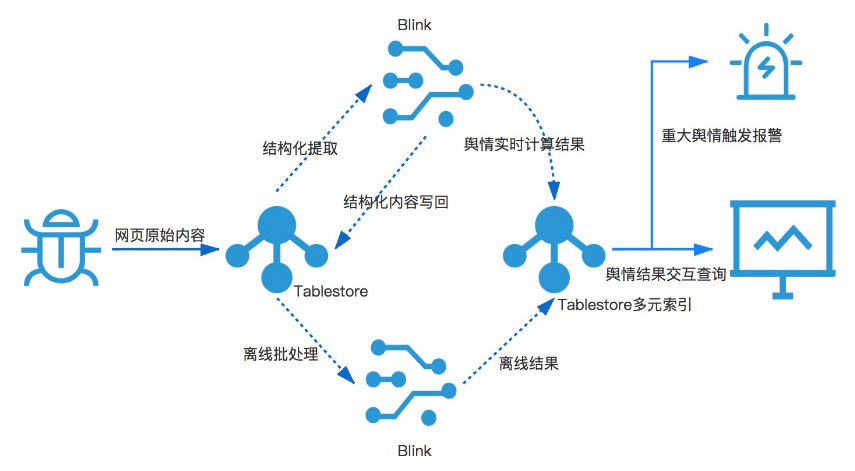
- 大数据舆情分析系统
拓展阅读
可以参考下列资源快速体验表格存储+blink的大数据架构、表格存储多元索引及其相关场景:
原文链接
本文为云栖社区原创内容,未经允许不得转载。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/137139.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
