大家好,又见面了,我是你们的朋友全栈君。


ECCV 2014 的文章,后来又扩展成了 TPAMI
整体的先后次序:RCNN(CVPR2014)->SPPnet(ECCV2014)->Fast RCNN(ICCV2015)->Faster RCNN(NIPS2015)
现有的深度卷积网络需要固定大小的输入图片(比如 224 × 224 224\times 224 224×224),这个要求人工设计的痕迹过于明显,并且可能会降低一个任意形状的图片的识别准确度。这篇文章提出了 spatial pyramid pooling 来消除这一限制。新提出的叫做 SPPnet 的框架,可以不考虑图像的大小就能生成固定长度的特征表示(fixed-length representation)。pyramid pooling 对物体的形变也很鲁棒。这个方法不但对于分类有好处,对于目标检测也很有好处。在目标检测中使用 SPPnet ,首先从整张图只计算一次 feature map,然后从任意区域 pool features 来生成定长表示,这些定长表示被用来对 detector 进行训练。这个方法避免了对卷积特征的重复计算。在测试时,SPPnet 比 RCNN 快了 24-102 倍。
现有的网络只能处理固定大小的图片,对于任意大小的图片,现在的方法通常是通过 cropping (裁剪)或 warping (扭曲)来使输入图像能够统一变成一个固定的长度。但是 cropped region 不一定包含整个物体,而 warped content 可能会造成不想要的几何形变。由于这样的方法造成的内容损失或失真,识别的准确率因此受到影响(recognition accuracy can be compromised due to the content loss or distortion)。另外,预先定义好的尺度不一定适合所有物体。
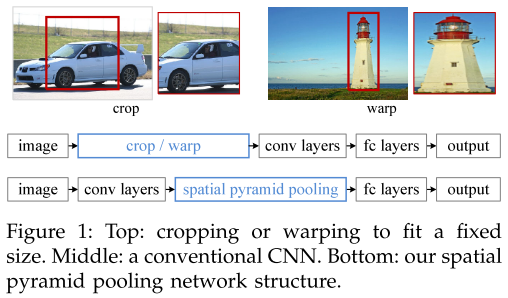
那么问题来了,为啥 CNN 需要定长的输入?CNN 包括两部分:卷积层和全连接层。卷积层以滑动窗口的方式来进行处理,其并不需要定长输入,它可以产生任意大小的特征图。而全连接层需要定长输入。所以问题主要出现在全连接层这里。
SPPnet 就是用来去掉定长这一限制的。具体地,我们在最后一个卷积层后面加了一个 SPP layer,SPP layer pools the features and generates fixed-length outputs ,然后这些定长输出再喂给全连接层(或其他的分类器)。换句话说,我们在卷积层和全连接层之间进行了一些信息聚合来避免从一开始就进行 cropping 和 warping 。
Spatial pyramid pooling[14,15] (popularly known as spatial pyramid matching or SPM[15]),作为 Bag-of-Words(BoW)[16] 的一个扩展版,是计算机视觉领域中一个非常成功的方法。它把图像分成多个区域(from coarse to fine),然后把他们中局部的特征聚合起来。SPP 在CNN出现之前长时间以来都是分类[17,18,19]以及检测[20]竞赛中使用的关键构件。然后 SPP 在 CNN 中还没有被考虑过。SPP 对于 deep CNN 有以下几个重要的性质:
- SPP 可以不考虑输入的大小来生成定长输出,但是之前的 sliding window pooling (AlexNet 中的 max pooling 吧?) 不能
- SPP 使用多级的空间盒子,但是 sliding window pooling(应该就是指 max pooling) 只使用一个单一的 window size。多级的 pooling 已经被证明对于物体形变十分鲁棒[15]。
- SPP 可以对多个尺度上的 feature 进行池化(pool)操作

SPPnet 不能能够从任意大小的图像中提取特征来进行测试,也允许我们在训练时能够用多种尺度和形状的图片。使用变长的图像可以增加尺度不变性并且减少过拟合。为了使一个网络能够接受变长输入,我们用共享所有参数的多个网络来进行近似,其中每一个网络都是用定长输入进行训练的。在每一个 epoch 中我们用一个给定的输入大小来对网络进行训练,然后在下一个 epoch 时切换到另外一种输入尺寸(就是训练一个网络,输入图片有一个放缩范围?应该就是 multi-scale training 吧)
RCNN 中计算特征非常耗时,因为它不断地在数千个 warped regions per image 上使用 deep CNN 来提取特征,但是SPPnet 只需要在整张图片上提取特征一次,然后在 feature map 上用 SPPnet 来提取特征。这个方法比 RCNN 要快一百倍。注意到在 feature map 上(而不是 image regions 上)进行 detector 的训练和运行是更加受欢迎的一个想法(比如 OverFeat,DPM,HOG)。
正文开始:Deep networks with Spatial Pyramid Pooling
Convolutional layers and feature maps
考虑流行的七层网络(AlexNet,ZFNet),前五层是卷积层,其中一些后面有 pooling 层,这些 pooling 层也可以被认为是 convolutional 的,因为他们使用的也是 sliding windows 的操作。最后两层是全连接层,输出是 N-way softmax ,其中 N 为类别的数量。
其中卷积层的输出和输入图片有着差不多的宽高比,这些输出被叫做 feature maps ,他们不仅包含响应的强度,也包含空间位置信息。卷积层不要求定长输入。这些由 deep CNN 生成的 feature map 和传统方法得到 feature map 是类似的。比如 SIFT vector 或 image patches 通过 vector quantization, sparse coding 或 Fisher kernels 来提取并编码。这些编码的特征包含特征图,然后再用 Bag-og-Words(BoW) 或 spatial pyramids 来 pool 一下。类似地,deep CNN 的 feature 也可以这样 pool 一下hhh
The spatial pyramid pooling layer
卷积层变长入变长出,分类器(SVM/softmax)或全连接层接受定长入(fixed-length vectors)。这些定长向量可以通过 Bag-of-Words 来得到。Spatial pyramid pooling 改进了 BoG,它可以通过在局部空间盒子中维持空间信息。这些空间盒子大小正比于图像大小,因此盒子的数量是固定的。可以和 sliding window pooling 进行比较,sliding window pooling 的 window 数量是和输入大小有关的。
为了使 deep network 接受任意大小输入,我们把最后一个 pooling 层改成了 spatial pyramid pooling layer
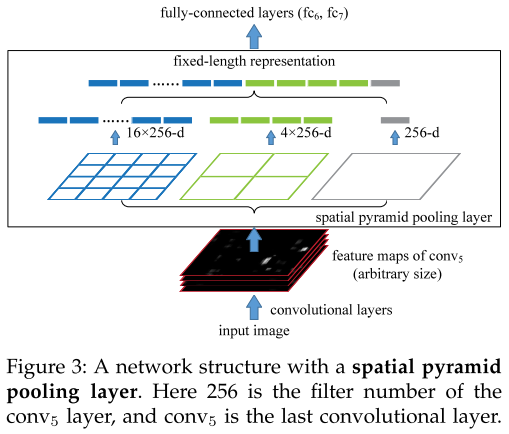
SPP layer 的输出是 k M kM kM 维的向量,其中 M M M 为盒子的个数, k k k 是最后一层卷积层的 filters 数(此处是图中的 256)
有了 SPP layer 后,输入图像便可以是任意大小——不仅是任意宽高比,而且是任意尺度。我们可以将输入图像 resize 成任意尺度,然后用到同样的网络中。当输入的图像在不同尺度时,网络会在不同的尺度提取特征。在传统方法中 scale 扮演了一个重要的角色。比如 SIFT vector 通常就是在多个尺度下进行提取的(通过 patches 的大小和 Gaussian filters 来确定)。
有趣的是,最粗略的 pyramid level 只有一个盒子,这个盒子的范围是全图,相当于 global pooling 的操作(更准确地说是 global max pooling)。有很多同期工作研究了这种操作,Network in Network 和 GoogLeNet 中 global average pooling 被用来减少模型的大小并减少过拟合现象。在 VGG 中 global average pooling 在测试时所有的全连接层之后使用,目的是提高准确率。在 [34] 中,global max pooling 被用来进行弱监督目标检测。global pooling 的操作对应于传统的 Bag-of-Words 方法。

Training the network
Single-size training
考虑最后一卷积层的输出大小为 a × a a\times a a×a,pyramid level 的盒子个数为 n × n n\times n n×n,则 max pooling 时的每个窗口大小为 ⌈ a / n ⌉ \lceil a/n\rceil ⌈a/n⌉,stride 为 ⌊ a / n ⌋ \lfloor a/n\rfloor ⌊a/n⌋ ,比如 a = 13 a=13 a=13, n = 3 , 2 , 1 n=3,2,1 n=3,2,1,则每个 level 对应的窗口大小分别为 5 , 7 , 13 5,7,13 5,7,13,stride 为 4 , 6 , 13 4,6,13 4,6,13 。

Multi-size training
SPPnet 可以接受任意尺度的图像。为了解决训练过程种多变的图像尺度问题,我们考虑一系列提前定义好的尺寸: 180 × 180 180\times 180 180×180 以及 224 × 224 224\times224 224×224 ,并不是从中截出来 180 × 180 180\times 180 180×180,而是 resize 成 180 × 180 180\times 180 180×180
直接看 detection 的部分:
复习 RCNN:RCNN 首先通过 SS 提出大约 2000 个候选框,然后每个窗口被 resize 成固定的长度( 227 × 227 227\times 227 227×227)然后再用一个网络来对每个窗口中的图像进行特征提取。最后在这些提取的特征上面训练一个 SVM 。由于 RCNN 每个图片要重复两千多次特征提取,因此速度很慢,提特征是主要瓶颈。
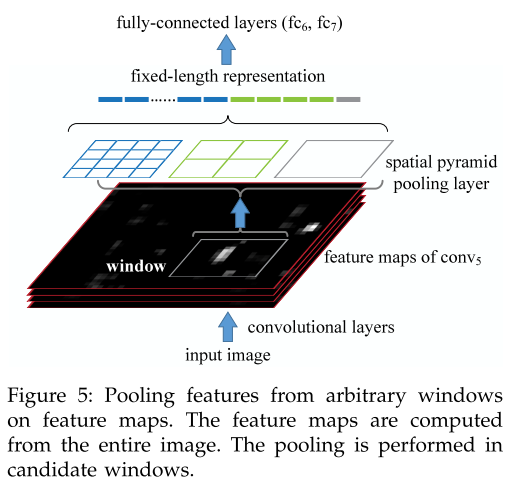
SPPnet 从整张图只提一次特征,然后通过 SPP layer 在每个 window 上提定长向量的特征。
Fast RCNN 和 SPPnet 有什么区别?
Fast RCNN 也是用其他方法(比如SS)生成 proposal,RoI pooling 的操作和 SPP 非常像,不同之处在于 SPP 有多个 level 的输出,最终聚合在一起,RoI pooling 则只有最后一个窗口(如 7 × 7 7\times7 7×7)
SPPnet 最后对每个 proposal 生成的特征进行分类,使用的方法仍然是 SVM,但是 Fast RCNN 把 classification 和 bbox regression 以及前面的 RoI pooling layer 整合在了一个网络里了,除了前面的 proposal,后面部分都是联合训练的。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/136719.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
