大家好,又见面了,我是你们的朋友全栈君。
前言
本文整理了填空、选择、判断等一些课后习题答案,具体的编程题可以见:Python快速编程入门课后程序题答案。
第一章
一、填空题
- Python是一种面向
对象的高级语言。 - Python可以在多种平台运行,这体现了Python语言的
可移植特性。 - Python源代码被解释器转换后的格式为
字节码。 - Python 3.x 默认使用的编码是
UTF-8。
二、判断题
- Python是开源的,它可以被一直到许多平台上。(
√) - Python的优点之一是具有伪代码的本质。(
√) - Python可以开发Web程序,也可以管理操作系统。(
√) - Mac系统自带Python开发环境。(
√) - Python自带的shell,其性能优于IPython。(
×) - 我们编写的Python代码在运行过程中,会被编译成二进制代码。(
×) - Python程序被解释器转换后的文件格式后缀名为.pyc。(
√) - Python 3.x 版本的代码完全兼容 Python 2.x。(
×) - PyCharm是开发Python的集成开发环境。(
√) - 代码print(3,4)是Python 2.x的输出格式。(
×)
三、选择题
-
下列选项中,不属于Python语言特点的是(
C)。
A.简单易学 B.开源 C.面对过程 D.可移植性 -
下列领域中,使用Python可以实现的是(
ABCD)。(多选)
A.Web开发 B.操作系统管理 C.科学计算 D.游戏 -
下列关于Python 2.x和Python 3.x的说法,正确的是(
B)。
A.Python 3.x使用print语句输出数据
B.Python 3.x默认使用的编码是UTF-8
C.Python 2.x和Python 3.x使用//进行除法运算的结果不一致
D.Python 3.x版本的异常可以直接被抛出 -
下列关于Python的说法中,错误的是(
C)。
A.Python是从ABC发展起来的
B.Python是一门高级的计算机语言
C.Python是一门只面向对象的语言
D.Python是一种代表简单主义思想的语言 -
下列关于IPython的说法,错误的是(
D)。
A.IPython集成了交互式Python的很多有点
B.IPython的性能远远优于标准的Python的shell
C.IPython支持变量自动补全,自动收缩
D.与标准的Python相比,IPython缺少内置的功能和函数
四、简答题
-
简述Python的特点。
•简单易学
•开源
•高级语言
•可移植性
•解释性
•面向对象
•可扩展性
•丰富的库
•规范的代码 -
简述Python的应用领域(至少3个)。
•web应用开发
•操作系统管理、服务器运维的自动化脚本
•科学计算
•桌面软件
•服务器软件(网络软件)
•游戏
•构思实现,产品早期原型和迭代 -
简述Python 2.x和Python 3.x的区别。
(1)、在python2.x中,输出数据使用的是print语句。但是在python3.x中, print语句没有了,取而代之的是print()函数
(2)、python2有ASCII Str()类型,unicode()是单独的,不是byte类型。在python3.x版本的源代码中,默认使用的是UTF-8编码,从而可以很好的支持中文字符。
(3)、在python 2.x中,使用运算符/进行除法运算,整数相除的结果是一个整数,浮点数除法会保留小数点的部分得到一个浮点数的结果。在python 3.x中使用运算符/进行除法,整数之间的相除,结果也会是浮点数。
(4)、相比python2.x版本,python3.x版本在异常方面有很多改变:
•在python2.x版本,所有类型的对象都是直接被抛出的,但是,在python3.x版本中,只有继承自BaseException的对象才可以被抛出。
•在python2.x版本中,捕获异常的语法是except exc,var。在python3.x版本中,引入了as关键字,捕获异常的语法变更为except exc as var。
•在python2.x版本中,处理异常使用raise Exception(args)。在python3.x版本中,处理异常使用raiseException, args。
•python3.x取消了异常类的序列行为和.message属性。
(5)、在Python 3.x中,表示八进制字面量的方式只有一种,并且必须写0o1000这样的方式,原来01000的方式不能使用了。
(6)、Python 2.x中不等于有两种写法 != 和 <>;但是,Python 3.x中去掉了<>, 只有!=一种写法
(7)、python3.x去除了long类型,现在只有一种整型int,但它的行为就像是python2.x版本的long。 -
简述Python程序的执行原理。
Python程序的执行原理如图所示:
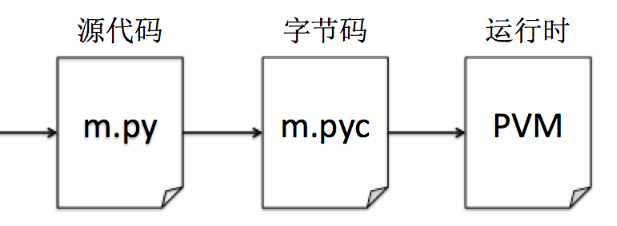

Python解释器将源代码转换为字节码,然后把编译好的字节码转发到Python虚拟机(PVM)中进行执行。 -
简述IPython的特点。
•IPython具有卓越的Python shell,其性能远远优于标准Python的shell。
•IPython支持变量自动补全,自动缩进,支持 bash shell 命令,内置了许多很有用的功能和函数。
•IPython提供了基于控制台命令环境的定制功能,可以十分轻松地将交互式Python shell包含在各种Python应用中,甚至可以当作系统级shell来使用。
第二章
一、填空题
- 在Python中,int表示的数据类型是
整型。 - 布尔类型的值包括
True和False。 - Python的浮点数占
8个字节。 - 如果要在计算机中表示浮点数 1.2 × 1 0 5 1.2\times10^5 1.2×105,则表示方法为
1.2e5。 - 00001000>>2的结果是
00000010。 - 若a=20,那么bin(a)的值为
0b10100。 - 如果想测试变量的类型,可以使用
type()来实现。 - 若a=1,b=2,那么(a or b)的值为
1。 - 若a=10,b=20,那么(a and b)结果为
20。 - 4.34E5表示的是
4.34×10^5。
二、判断题
- Python使用符号#表示单行注释。(
√) - 标识符可以以数字开头。(
×) - type()方法可以查看变量的数据类型。(
√) - Python中的代码块使用缩进来表示。(
√) - Python中的多行语句可以使用反斜杠来实现。(
×) - Python中标识符不区分大小写。(
×) - Python中的标识符不能使用关键字。(
√) - 使用help()命令可以进入帮助系统。(
√) - Python中的成员运算符用于判断制定序列中是否包含某个值。(
√) - 比较运算符用于比较两个数,其返回的结果智能是True或False。(
√)
三、选择题
-
下列选项中,(
D)的布尔值不是Flase。
A.None
B.0
C.()
D.1 -
假设a=9,b=2,那么下列运算中,错误的是(
D)。
A.a+b的值是11
B.a//b的值是4
C.a%b的值是1
D.a**b的值是18 -
下列标识符中,合法的是(
AD)。
A.helloWorld
B.2ndObj
C.hello#world
D._helloworld -
下列符号中,表示Python中单行注释的是(
A)。
A.#
B.//
C.<!– –>
D.”“” -
下列选项中,符合Python命名规范的标识符是(
C)。
A.user-Passwd
B.if
C._name
D.setup.exe -
下列选项中,Python不支持的数据类型有(
B)。
A.int
B.char
C.float
D.dicitionary -
下列表达式中,返回 True 的是(
B)。
A.a=2 b=2 a=b
B.3>2>1
C.True and False
D.2!=2 -
下列语句中,哪个在 Python 中是非法的?(
B)。
A.x = y = z = 1
B.x = (y = z + 1)
C.x, y = y, x
D.x += y -
下列关于 Python 中的复数,说法错误的是(
C)。
A.表示复数的语法是 real + image j
B.实部和虚部都是浮点数
C.虚部必须后缀 j,且必须是小写
D.一个复数必须有表示虚部的实数和 j -
下列选项中,幂运算的符号为(
D)。
A.*
B.++
C.%
D.**
四、简答题
- 简述Python中标识符的命名规则。
•标识符由字母、下划线和数字组成,且数字不能开头。
•python中的标识符是区分大小写的。
•python中的标识符不能使用关键字。 - 简述Python中的数字类型。
int(整型)、long(长整型)、float(浮点数)、complex(复数)
第三章
一、填空题
- 在循环体中使用
break语句可以跳出循环体。 elif语句是else语句和if语句的组合。- 在循环体中可以使用
continue语句跳过本次循环后面的代码,重新开始下一次循环。 - 如果希望循环是无限的,我们可以通过设置条件表达式永远为
True来实现无限循环。 - Python中的
pass表示的是空语句。
二、判断题
- elif可以单独使用。(
×) - pass语句的出现是为了保持进程结构的完整性。(
√) - 在Python中没有switch-case语句。(
√) - 每个if条件后面都要使用冒号。(
√) - 循环语句可以嵌套使用。(
√)
三、选择题
- 下列选项中,会输出1,2,3三个数字的是(
BC)。
A.
for i in range(3):
print(i)
B.
for i in range(3):
print(i + 1)
C.
a_list = [0,1,2]
for i in a_list:
print(i + 1)
D.
i = 1
while i < 3:
print(i)
i = i + 1
- 阅读下面的代码:
sum = 0
for i in range(100):
if(i%10):
continue
sum = sum + i
print(sum)
上述程序的执行结果是(C)。
A.5050 B.4950 C.450 D.45
- 已知x=10,y=20,z=30:以下语句执行后x,y,z的值是(
C)。
if x < y:
z=x
x=y
y=z
A.10,20,30
B.10,20,20
C.20,10,10
D.20,10,30
- 有一个函数关系如下所示:
| x | y |
|---|---|
| x<0 | x-1 |
| x=0 | x |
| x>0 | x+1 |
下面程序段中,能正确表示上面关系的是(C)。
A.
y = x + 1
if x >= 0
if x == 0:
y = x
else:
y = x - 1;
B.
y = x - 1
if x != 0:
if x > 0:
y = x + 1
else:
y = x
C.
if x <= 0:
if x < 0:
y = x - 1
else:
y = x
else:
y = x + 1
D.
y = x
if x <= 0:
if x < 0:
y = x - 1
else:
y = x + 1
- 下列Python语句正确的是(
D)。
A.min=x if x<y else y
B.max=x>y?x:y
C.if(x>y) print x
D.while True:pass
四、简答题
- 简述Python中pass语句的作用。
Python中的pass是空语句,它的出现是为了保持程序结构的完整性。
pass不做任何事情,一般用做占位语句。 - 简述break和continue的区别。
break语句用于结束整个循环;
continue的作用是用来结束本次循环,紧接着执行下一次的循环。
第四章
一、单选题
-
当需要在字符串中使用特殊字符的时候,Python使用(
A)作为转义字符。
A.\
B./
C.#
D.% -
下列数据中不属于字符串的是(
D)。
A.‘ab’
B.’’‘perfect’’’
C.“52wo”
D.abc -
使用(
B)符号对浮点类型的数据进行格式化。
A.%c
B.%f
C.%d
D.%s -
字符串’Hi,Andy’中,字符’A’对应的下标位置为(
C)。
A.1
B.2
C.3
D.4 -
下列方法中,能够返回某个子串在字符串中出现次数的是(
C)。
A.length
B.index
C.count
D.find -
下列方法中,能够让所有单词的首字母变成大写的方法是(
B)。
A.capitalize
B.title
C.upper
D.ljust -
字符串的strip方法的作用是(
A)。
A.删除字符串头尾指定的字符 B.删除字符串末尾的指定字符
C.删除字符串头部的指定字符 D.通过指定分隔符对字符串切片
二、判断题
- 无论使用单引号或者双引号包含字符,使用print输出的结果都一样。(
√) - 无论input接收任何的数据,都会以字符串的方式进行保存。(
√) - Python中只有一个字母的字符串属于字符类型。(
×) - 使用下标可以访问字符串中的每个字符。(
√) - Python中字符串的下表是从1开始的。(
×) - 切片选区的区间范围是从起始位开始的,到结束位结束。(
×) - 如果index方法没有在字符串中找到子串,则会返回-1。(
×)
三、填空题
- 字符串是一种表示
文本数据的类型。 - 像双引号这样的特殊符号,需要对它进行
转义输出。 - Python3提供了
input函数从标准输入(如键盘)读入一行文本。 切片指的是对操作的对象截取其中的一部分。- 切片选取的区间是左闭右
开型的,不包含结束位的值。
四、程序分析题
阅读下面的程序,分析代码是否可以编译通过。如果编译通过,请列出运行的结果,否则说明编译失败的原因。
- 代码一:
num_one = input("请输入一个整数:")
num_two = input("请输入一个整数:")
if num_one % num_two == 0:
print("验证码正确")
答:不能编译通过。因为num1和num2属于字符串类型,不能执行取余操作。
- 代码二:
name = 'Steve Jobs'
print(name[6])
结果为:J
- 代码三:
string_example = 'hello world itheima'
index = string_example.index("itheima",0,10)
print(index)
答:由于没有在字符串中找到子串,index方法默认会抛出ValueError异常。
- 代码四:
string_example = " hello world "
print(string_example.strip())
结果为:Hello World (默认删除两头的空格)
- 代码五:
string_example = "Hello" + 'Python'
print(string_example)
结果为:HelloPython
第五章
一、选择题
-
关于列表的说法,描述有错误的是(
D)。
A.list是一个有序集合,没有固定大小
B.list可以存放任意类型的元素
C.使用list时,其下标可以是负数
D.list是不可变的数据类型 -
以下程序的输出结果是(
B)。(提示:ord(“a”)==97)
list_demo=[1,2,3,4,5,'a','b']
print(list_demo[1],list_demo[5])
A.1 5
B.2 a
C.1 97
D.2 97
- 执行下面的操作后,list_two的值为(
C)。
list_one=[4,5,6]
list_two=list_one
list_one[2]=3
A.[4,5,6]
B.[4,3,6]
C.[4,5,3]
D.A,B,C都不正确
- 阅读下面的程序:
list_demo=[1,2,1,3]
nums=set(list_demo)
for i in nums:
print(i,end="")
程序执行的结果为(D)。
A.1213
B.213
C.321
D.123
-
下列选项中,正确定义了一个字典的是(
D)。
A.a=[‘a’,1,‘b’,2,‘c’,3]
B.b=(‘a’,1,‘b’,2,‘c’,3)
C.c={‘a’,1,‘b’,2,‘c’,3}
D.d={‘a’:1,‘b’:2,‘c’:3} -
下列选项中,不能使用下标运算的是(
C)。
A.列表
B.元组
C.集合
D.字符串 -
下列程序执行后输出的结果为(
A)。
x = 'abc'
y = x
y = 100
print(x)
A.abc
B.100
C.97,98,99
D.以上三项均是错误的
-
下列删除列表中最后一个元素的函数是(
B)。
A. del B. pop C. remove C. cut -
下列函数中,用于返回元祖中元素最小值的是(
C)。
A. len B. max C. min D.tuple
二、判断题
- 列表的索引是从0开始的。(
√) - 通过insert方法可以在制定位置插入元素。(
√) - 使用下标能修改列表的元素。(
√) - 列表的嵌套指的是一个列表的元素是另一个列表。(
√) - 通过下标索引可以修改和访问元祖的元素。(
×) - 字典中的值只能够是字符串类型。(
×) - 在字典中,可以使用count方法计算键值对的个数。(
×)
三、填空题
- Python序列类型包括字符串、列表和元组三种,
字典是Python中唯一的映射类型。 - Python中的可变数据类型有
字典和列表。 - 在列表中查找元素时可以使用
not in和in运算符。 - 如果要从小到大的排列列表的元素,可以使用
sort方法实现。 - 元组使用
圆括号存放元素,列表使用的是方括号。
四、简答题
请简述元组、列表和字典的区别。
(1)、外形:列表是中括号括起来的数据;元组是圆括号括起来的数据;字典是花括号括起来的数据
(2)、存储结构:列表可以存储多个不同类型的数据,以逗号分隔;元组同样能存储多个不同类型的数据,以逗号分隔;字典能存储多个键值对,以逗号分隔,键是唯一的,值是任何类型的。
(3)、访问方式:列表可以通过下标索引访问元素,索引从0开始;元组可以通过下标索引访问值,索引从0开始;字典通过键来访问值。
(4)、是否可变类型:列表是可变类型,元组是不可变类型,字典是可变类型。
五、程序分析题
阅读下面的程序,分析代码是否能够编译通过。如果能编译通过,请列出运行的结果,否则请说明编译失败的原因。
- 代码一:
tup = ('a','b','c')
tup[3] = 'd'
print(tup)
答:程序运行错误,元组不能使用下标增加元素。
- 代码二:
dict_demo={
'a':1,'b':2,'c':3}
print(dict_demo['a'])
结果为:1
- 代码三:
list_demo=[10,23,66,26,35,1,76,88,58]
list_demo.reverse()
print(list_demo[3])
list_demo.sort()
print(list_demo[3])
结果为:
1
26
第六章
一、单选题
- 阅读下面的程序:
def func():
print(x)
x=100
func()
执行上述语句后,输出的结果为(C)。
A.0 B.100 C.程序出现异常 D.程序编译失败
-
下面关于函数的说法,错误的是(
C)。
A.函数可以减少代码的重复,使得程序更加模块化
B.在不同的函数中可以使用相同名字的变量
C.调用函数时,传入参数的顺序和函数定义时的顺序必须相同
D.函数体中如果没有return语句,也会返回一个None值 -
下列有关函数的说法中,正确的是(
C)。
A.函数的定义必须在程序的开头
B.函数定义后,其中的程序就可以自动执行
C.函数定义后需要调用才会执行
D.函数体与关键字def必须左对齐 -
下列函数调用使用的参数传递方式是(
A)。
result = sum(num1, num2, num3)
A.位置绑定 B.关键字绑定 C.变量类型绑定 D.变量名称绑定
-
使用(
C)关键字创建自定义函数。
A. function B. func C.def D.procedure -
使用(
D)关键字声明匿名函数。
A. function B. func C.def D.lambda
二、判断题
- 函数的名称可以随意命名。(
×) - 不带return的函数代表返回None。(
√) - 默认情况下,参数值和参数名是跟函数声明定义的顺序匹配的。(
√) - 函数定义完成后,系统会自动执行其内部的功能。(
×) - 函数体以冒号起始,并且是缩进格式的。(
√) - 带有默认值的参数一定位于参数列表的末尾。(
√) - 局部变量的作用域是整个程序,任何时候使用都有效。(
×) - 匿名函数就是没有名字的函数。(
√)
三、填空题
- 函数可以有多个参数,参数之间使用
逗号分隔。 - 使用
return语句可以返回函数值并退出函数。 - 通过
return结束函数,从而选择性地返回一个值给调用方。 - 函数能处理比声明时更多的参数,它们是
不定长参数。 - 在函数里面调用另外一个函数,这就是函数
嵌套调用。 - 在函数的内部定义的变量称作
局部变量。 - 全局变量定义在函数外,可以在
整个程序范围内访问。 - 如果想在函数中修改全部变量,需要在变量的前面加上
global关键字。
四、简答题
- 请简述局部变量和全局变量的区别。
局部变量:
(1)、函数内部定义的变量;
(2)、作用域是函数的内部。
全局变量:
(1)、函数外部定义的变量;
(2)、作用域是整个程序。 - 请简要说明函数定义的规则。
(1)、以def关键字开头,后面接函数标识符名称和圆括号;
(2)、给函数起名字的时候,规则跟变量的名字是一样的;
(3)、任何传入参数和自变量必须放在圆括号中间;
(4)、函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明;
(5)、函数内容以冒号起始,并且缩进;
(6)、return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
五、程序分析题
阅读下面的程序,分析代码是否能够编译通过。如果能编译通过,请列出运行的结果,否则请说明编译失败的原因。
- 代码一:
def func():
x = 200
x = 100
func()
print(x)
结果为:100
- 代码二:
def func():
global x
x = 200
x = 100
func()
print(x)
结果为:200
- 代码三:
def func():
x = 200
def func2():
print(x)
func2()
x = 100
func()
print(x)
结果为:
200
100
第七章
一、单选题
-
关于装饰器,下列说法错误的是(
B)。
A.装饰器是一个包裹函数
B.装饰器智能有一个参数
C.通过在函数定义的面前加上@符号阿和装饰器名,使得装饰器函数生效
D.如果装饰器带有参数,则必须在装饰函数的外层再嵌套一层函数 -
下列函数中,用于使用函数对制定序列进行过滤的是(
C)。
A.map函数 B.select函数 C.filter函数 D.reduce函数 -
下列选项中,不能作为filter函数参数的是(
D)。
A.列表 B.元组 C.字符串 D.整数 -
阅读下面一段程序:
def foo():
a = 1
def bar():
a = a + 1
return a
return bar
print(foo()())
上述程序执行的结果为(A)。
A.程序出现异常
B.2
C.1
D.没有输出结果
二、判断题
- 闭包是内部函数对外部作用域的变量进行引用。(
×) - 当外部函数执行结束,其内部闭包引用的变量一定会立即释放。(
×) - 装饰器是一个变量。(
×) - 装饰器函数至少要接收一个函数。(
√) - 装饰器既能装饰带参数的函数,也能自己带参数。(
√) - 如果map函数传入的两个序列个数不同,那么个数多的序列会把多余的元素删除。(
×) - map函数只能传递一个序列。(
×) - map传入函数的参数个数必须跟序列的个数一样。(
√) - filter传入的函数可以为None。(
√) - filter函数智能对序列执行过滤操作。(
×) - filter函数的返回值为字符串,它的序列类型一定是字符串。(
√)
三、填空题
- 内部函数引用了外部函数作用域的变量,那么内部函数叫作
闭包。 - 装饰器本质上是一个
函数。 - 装饰器函数需要接收一个参数,这个参数表示
被修饰的函数。 - 在函数定义的前面添加装饰器名和
@符号,实现对函数的包装。 - 支持参数的装饰器函数需要再多一层
内嵌函数。 map函数会根据提供的函数对制定的序列做映射。- map的两个序列的元素个数不一致,那么元素少的序列会以
None补齐。 filter函数会对制定序列执行过滤操作。- filter传入的函数的返回值是
布尔值。 - reduce传入的是带有
两个参数的函数,该函数不能为None。
四、简答题
-
请简述闭包满足的三个条件。
(1)、存在于嵌套关系的函数中;
(2)、嵌套的内部函数引用了外部函数的变量;
(3)、嵌套的外部函数会将内部函数名作为返回值返回。 -
请简述装饰器的应用场景。
(1)、引入日志;
(2)、函数执行时间统计;
(3)、执行函数前预备处理;
(4)、执行函数后清理功能;
(5)、权限校验;
(6)、缓存。 -
请简述map、filter、reduce函数的作用。
(1)、map函数会根据提供的函数对指定的序列做映射。
(2)、filter函数会对指定序列执行过滤操作。
(3)、reduce函数会对参数序列中的元素进行累积。
五、程序分析题
阅读下面的程序,分析代码是否能够编译通过。如果能编译通过,请列出运行的结果,否则请说明编译失败的原因。
- 代码一:
def funX():
x = 5
def funY():
nonlocal x
x += 1
return x
return funY
a = funX()
print(a())
print(a())
print(a())
结果为:
6
7
8
- 代码二:
def funX():
x = 5
def funY():
nonlocal x
x += 1
return x
return funY
return funY
a = funX
print(a()())
print(a()())
print(a()())
结果为:
6
6
6
第八章
一、单选题
-
打开一个已有文件,然后在文件末尾添加信息,正确的打开方式为(
C)。
A.‘r’ B.‘w’ C.‘a’ D.‘w+’ -
假设文件不存在,如果使用open方法打开文件会报错,那么该文件的打开方式是下列哪种模式?(
A)
A.‘r’ B.‘w’ C.‘a’ D.‘w+’ -
假设file是文本文件对象,下列选项中,哪个用于读取一行内容?(
C)
A.file.read() B.file.read(200)
C.file.readline() D.file.readlines() -
下列方法中,用于向文件中写出内容的是(
B)。
A.open B.write C.close D.read -
下列荣方法中,用于获取当前目录的是(
D)。
A.open B.write C.Getcwd D.read -
下列语句打开文件的位置应该在(
D)。
f = open('itheima.txt','w')
A.C盘根目录下
B.D盘根目录下
C.Python安装目录下
D.与源文件在相同的目录下
- 若文本文件abc.txt中的内容如下:
abcdef
阅读下面的程序:
file=open("abc.txt","r")
s=file.readline()
s1=list(s)
print(s1)
上述程序执行的结果为(C)。
A.[‘abcdef’]
B.[‘abcdef\n’]
C.[‘a’,‘b’,‘c’,‘d’,‘e’,‘f’]
D.[‘a’,‘b’,‘c’,‘d’,‘e’,‘f’,’\n’]
二、判断题
- 文件打开的默认方式是只读。(
√) - 打开一个可读写的文件,如果文件存在会被覆盖。(
√) - 使用write方法写入文件时,数据会追加到文件的末尾。(
√) - 实际开发中,文件或者文件夹操作都要用到os模块。(
√) - read方法只能一次性读取文件中的所有数据。(
×)
三、填空题
- 打开文件对文件进行读写,操作完成后应该调用
close()方法关闭文件,以释放资源。 - seek方法用于移动指针到制定位置,该方法中
offset参数表示要偏移的字节数。 - 使用readlines方法把整个文件中的内容进行一次性读取,返回的是一个
列表。 - os模块中的mkdir方法用于创建
文件夹。 - 在读写文件的过程中,
tell方法可以获取当前的读写位置。
四、简答题
- 请简述文本文件和二进制文件的区别。
文本文件存储的是常规字符串,由若干文本行组成,通常每行以换行符“\n”结尾。二进制文件把对象内容以字节串进行存储,无法用记事本或其他普通字处理软件直接进行编辑,无法被人类直接阅读和理解,需要使用专门的软件进行解码后读取、显示、修改或执行。 - 请简述读取文件的几种方法和区别。
(1)、使用read(size)方法可以指定读取的字节数,或者读取整个文件;
(2)、使用readlines方法可以把整个文件的内容进行一次性读取;
(3)、使用readline方法一行一行读数据。
第九章
一、单选题
- 下列程序运行以后,会产生如下(
B)异常。
a
A.SyntaxError B.NameError C.IndexError D.KeyError
-
下列选项中,(
C)是唯一不再运行时发生的异常。
A.ZeroDivisionError B.NameError C.SyntaxError D.KeyError -
当try语句中没有任何错误信息时,一定不会执行(
D)语句。
A.try B.else C.finaly D.except -
在完整的异常语句中,语句出现的顺序正确的是(
D)。
A.try—->except—–>else—->finally
B.try—->else—->except—–>finally
C.try—->except—–>finally—>else
D.try—–>else—->else—–>except -
下列选项中,用于触发异常的是(
A)。
A.try B.catch C.raise D.except -
关于抛出异常的说法中,描述错误的是(
C)。
A.当raise指定异常的类名时,会隐式地创建异常类的实例
B.显式地创建异常类实例,可以使用raise直接引发
C.不带参数的raise语句,只能引发刚刚发生过的异常
D.使用raise抛出异常时,无法指定描述信息 -
关于抛出异常的说法中,描述错误的是(
D)。
A.当raise指定异常的类名时,会隐式地创建异常类的实例
B.显式地创建异常类实例,可以使用raise直接引发
C.不带参数的raise语句,只能引发刚刚发生过的异常
D.使用raise抛出异常时,无法指定描述信息
二、判断题
- 默认情况下,系统检测到错误后会终止程序。(
√) - 在使用异常时必须先导入exceptions模块。(
×) - 一个try语句只能对应一个except子句。(
×) - 如果except子句没有指明任何异常类型,则表示捕捉所有的异常。(
√) - 无论程序是否捕捉到异常,一定会执行finally语句。(
√) - 所有的except子句一定在else和finally的前面。(
√)
三、填空题
- Python中所有的异常类都是
Exception子类。 - 当使用序列中不存在的
索引时,会引发IndexError异常。 - 一个try语句智能对应一个
finally子句。 - 当约束条件不满足时,
assert语句会触发AssertionError异常。 - 如果在没有
except的try语句中使用else语句,会引发语法错误。
四、简答题
- 请简述什么是异常。
在Python中,程序在执行的过程中产生的错误称为异常,比如列表索引越界、打开不存在的文件等。 - 处理异常有哪些方式?
try、except、else、finally语句。
第十章
一、单选题
-
下列关键字中,用来引入模块的是(
C)。
A.include B.from C.import D.continue -
关于引入模块的方式,错误的是(
D)。
A.import math
B.from fib import fibnacci
C.form math import *
D.from * import fib -
关于__name__的说法,下列描述错误的是(
A)。
A.它是Python提供的一个方法
B.每个模块内部都有一个__name__属性
C.当它的值为’__main__‘时,表示模块自身在运行
D.当它的值不为’__main__’时,表示模块被引用
二、判断题
- Python解释器会优先查看默认的路径搜索模块的位置。(
×) - 每个Python文件就是一个模块。(
√) - 当__name__属性的值为__main__时,代表该模块自身在运行。(
√) - 包目录下必须有一个__init__py文件。(
√) - 外部模块都提供了自动安装的文件,直接双击安装就行。(
×)
三、填空题
- 要调用random模块的randint函数,书写形式为
random. randint。 - 每个Python文件都可以作为一个模块,模块的名字就是
文件的名字。 - 每个模块都有一个
__name__属性,使程序块智能在模块自身运行时执行。 - 为了更好地组织模块,通常会把多个模块放在一个
包中。 - 当程序中需要引入外部模块时,需要从外面下载并
安装。 - 如果要搜索模块的路径,可以使用sys模块的
path变量。
四、简答题
- 解释Python脚本程序的”__name__”的作用。
每个Python脚本在运行时都有一个“__name__”属性。如果脚本作为模块被导入,则其“__name__”属性的值被自动设置为模块名;如果脚本独立运行,则其“__name__”属性值被自动设置为“__name__”属性。利用“__name__”属性即可控制Python程序的运行方式。 - 请简述Python解释器搜索模块位置的顺序。
(1)、搜索当前目录,如果不在当前目录,Python则搜索在shell变量PYTHONPATH下的每个目录。
(2)、如果都找不到。Python会继续查看默认路径。 - 请简述模块的概念。
在Python中有一个概念叫做模块(module),这个和C语言中的头文件以及Java中的包很类似,比如在Python中要调用sqrt函数,必须用import关键字引入math这个模块。 - 请简述导入模块的方法。
在Python中用关键字import来引入某个模块:
(1)、导入模块,使用“import 模块”引入;
(2)、导入模块中的某个函数,使用“from 模块名 import 函数名”引入;
(3)、导入模块的全部内容,使用“from 模块 import *”。
第十一章
一、单选题
-
关于面向过程和面向对象,下列说法错误的是(
B)。
A.面向过程和面向对象都是解决问题的一种思路
B.面向过程是基于面向对象的
C.面向过程强调的是解决问题的步骤
D.面向对象强调的是解决问题的对象 -
关于类和对象的关系,下列描述正确的是(
D)。
A.类和面向对象的核心
B.类是现实中事物的个体
C.对象是根据类创建的,并且一个类只能对应一个对象
D.对象描述的是现实的个体,它是类的实例 -
构造方法的作用是(
C)。
A.一般成员方法 B.类的初始化
C.对象的初始化 D.对象的建立 -
构造方法是类的一个特殊方法,Python中它的名称为(
C)。
A.与类同名 B._construct C._init_ D. init -
Python类中包含一个特殊的变量(
A),它表示当前对象自身,可以访问类的成员。
A.self B.me C.this D.与类同名 -
下列选项中,符合类的命名规范的是(
A)。
A.HolidayResort
B.Holiday Resort
C.hoildayResort
D.hoilidayresort -
Python中用于释放类占用资源的方法是(
B)。
A.__init__
B.__del__
C._del
D.delete
二、判断题
- 面向对象是基于面向过程的。(
×) - 通过类可以创建对象,有且只有一个对象实例。(
×) - 方法和杉树的格式是完全一样的。(
×) - 创建类的对象时,系统会自动调用构造方法进行初始化。(
√) - 创建完对象后,其属性的初始值是固定的,外界无法进行修改。(
×) - 使用del语句删除对象,可以手动释放它所占用的资源。(
√)
三、填空题
- 在Python中,可以使用
class关键字来声明一个类。 - 面向对象需要把问题划分多个独立的
对象,然后调用其方法解决问题。 - 类的方法中必须有一个
self参数,位于参数列表的开头。 - Python提供了名称为
__init__的构造方法,实现让类的对象完成初始化。 - 如果想修改属性的默认值,可以在构造方法中使用
参数设置。
四、简答题
- 请简述self在类中的意义。
不用实例化对象就能够在本类中访问自身的属性或方法。 - 类是由哪三个部分组成的?
类名,属性,方法。 - 请简述构造方法和析构方法的作用。
分别用于初始化对象的属性和释放类所占用的资源。
五、程序分析题
阅读下面的程序,分析代码是否能够编译通过。如果能编译通过,请列出运行的结果,否则请说明编译失败的原因。
- 代码一:
class Person:
def __init__(self, name):
self.name = name
def __str__(self):
return "我的名字是" + self.name
person = Person("小明")
print(person)
结果为:我的名字是小明
- 代码二:
class Person:
def __del__(self):
print("--del--")
person = Person()
del person
print("--end--")
结果为:
–del–
–end–
第十二章
一、选择题
-
Python中定义私有属性的方法是(
D)。
A. 使用private关键字 B.使用public关键字
C.使用__XX__定义属性名 D.使用__XX定义属性名 -
下列选项中,不属于面向对象程序设计的三个特征的是(
A)。
A.抽象 B.封装 C. 继承 D.多态 -
以下C类继承A类和B类的格式中,正确的是(
C)。
A. class C A,B: B. class C(A:B) C.class C(A,B) D.class C A and B: -
下列选项中,与class Person等价的是(
C)。
A. class Person(Object) B. class Person(Animal)
C. class Person(object) D. class Person: object -
下列关于类属性和示例属性的说法,描述正确的是(
B)。
A.类属性既可以显示定义,又能在方法中定义
B.公有类属性可以通过类和类的实例访问
C.通过类可以获取实例属性的值
D.类的实例只能获取实例属性的值 -
下列选项中,用于标识为静态方法的是(
C)。
A.@classmethood B.@instancemethod
C.@staticmethod D.@privatemethod -
下列方法中,不可以使用类名访问的是(
A)。
A.实例方法 B.类方法 C.静态方法 D.以上3项都不符合
二、判断题
- Python中没有任何关键字区分公有属性和私有属性。(
√) - 继承会在原有类的基础上产生新的类,这个新类就是父类。(
×) - 带有两个下划线的方法一定是私有方法。(
√) - 子类能继承父类的一切属性和方法。(
×) - 子类通过重写继承的方法,覆盖掉跟父类同名的方法。(
√) - 如果类属性和实例属性重名,对象有限访问类属性的值。(
×) - 使用类名获取到的值一定是类属性的值。(
√) - 静态方法中一定不能访问实例属性的值。(
√)
三、填空题
- 如果属性名的前面加上了两个
下划线,就表明它是私有属性。 - 在现有类基础上构建新类,新的类称作子类,现有的类称作
父类。 - 父类的
私有属性和方法是不能被子类继承的,更不能被子类访问。 - Python语言既支持单继承,也支持
多继承。 - 子类想按照自己的方式实现方法,需要
重写从父类继承的方法。 - 子类通过
super()可以成功地访问父类的成员。 - 位于类内部、方法外部的方法是
类方法。 - 类方法是类拥有的方法,使用修饰器
@classmethod来标识。
四、简答题
-
请简述如何保护类的属性。
(1)、把属性定义为私有属性,即在属性名的前面加上两个下划线;
(2)、添加用于设置或者获取属性值的两个方法供外界调用。 -
什么是继承?
类的继承是指在一个现有类的基础上构建一个新的类,构建出来的新类被称作子类,现有类被称作父类,子类会自动拥有父类的属性和方法。 -
请简述私有属性无法访问的原理。
当在一个类的内部定义了私有方法或者私有属性的时候,Python在运行的过程中,把属性或者方法的名字进行了修改,即在属性或者方法名称的前面加上“_类名”,导致原有的方法无法访问到。 -
什么是多态?
在Python中,多态是指在不考虑对象类型的情况下使用对象。 -
请简述实例方法、类方法和静态方法的区别。
(1)、类方法需要使用@classmethod进行标识,该方法可以访问类属性,无法访问实例属性,可以通过类实例和类进行调用。
(2)、静态方法使用@staticmethod进行标识,该方法无法访问实例属性和类属性,起到类似于函数的作用,使用类或者类实例进行调用。
(3)、实例方法直接在类中使用def进行定义,可以访问其实例属性和类属性,使用类实例进行调用。
(4)、如果要修改实例属性的值,就直接使用实例方法;如果要修改类属性的值,就直接使用类方法;如果是辅助功能,比如打印菜单,这时可以考虑使用静态方法,可以在不创建对象的前提下使用。 -
请简述Python中以下划线开头的变量名的特点。
在Python中,以下划线开头的变量名有着特殊的含义,尤其是在类的定义中。用下划线作为变量前缀和后缀来表示类的特殊成员:
(1)、_xx:这样的对象叫做保护变量,不能用from module import *导入,只有类对象和子类对象能够访问这些变量。
(2)、__xx__:系统定义的特殊成员名字。
(3)、__xx:类中的私有成员,只有类对象自己能访问,子类对象也不能访问到这个成员,但在对象外部可以通过“对象名.__类名__ xx”这样特殊的方式来访问。Python中没有纯粹的C++意义上的私有成员。
END
如果本文有什么写的不对的地方或有什么更好地建议和想法,欢迎在下方评论留言或私信我,大家一起进步学习!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/136559.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
