大家好,又见面了,我是你们的朋友全栈君。
1. 如何检验数据是否服从正态分布?
一、图示法
(1)P-P图。以样本的累积频率作为横坐标,以安装正太分布计算的相应累计概率作为纵坐标,把样本值表现为直角坐标系中的散点,如果服从正太分布,则样本点围绕第一象限的对角线分布。
(2)Q-Q图。以样本的分位数作为横坐标,以按照正态分布计算的相应分位点作为纵坐标,把样本表现为指教坐标系的散点。如果资料服从正态分布,则样本点应该呈一条围绕第一象限对角线的直线。
(3)直方图。判断是否以钟形分布,同时可以选择输出正态性曲线
(4)箱式图。观测离群值和中位数
(5)茎叶图。类似于直方图,但实质不同。
二、计算法
(1)偏度系数和峰度系数
偏度计算公式:

峰度计算公式: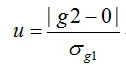
其中,表示偏度,表示峰度,通过计算,及其标准误差、,再做U计算。当两种检验同时得出=1.96,即p>0.05时,才可以认为该组服从正太分布。
2. 中心极限定理
中心极限定理,是指概率论中讨论随机变量序列部分和分布渐进于正太分布的一类定理。是指样本平均值约等于总体平均值。
随着n的增大,n个数的样本均值会趋近于正太分布,并且这个正太分布以u为均值,为方差。
相关结论:
结论1:用样本估计整体;
结论2:样本的平均值呈正态分布;
结论3:在无法知道总体的情况下,可以用样本估计整体。(除以n-1)
3. 过拟合问题
过拟合是指为了得到一致假设而使假设变得过度严格。
常见产生原因:
(1)建模样本选取有误,包括样本数量太少,选择方法错误,样本标签错误等,导致选取的样本的数据不足以代表预定的分类规则。
(2)样本噪音干扰过大,从而扰乱分类规则。
(3)假设的模型无法合理存在,或者说是假设成立的条件实际并不成立
(4)参数太多,使得模型复杂度过高。
(5)对于决策树模型,如果我们对于其生长没有合理的限制,其自由生长有可能使节点只包含单纯的事件数据(event)或非事件数据(no event),使其虽然可以完美匹配(拟合)训练数据,但是无法适应其他数据集。
(6)对于神经网络模型:a)对样本数据可能存在分类决策面不唯一,随着学习的进行,,BP算法使权值可能收敛过于复杂的决策面;b)权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。
常见解决办法:
(1)增加样本数据;
(2)选取合适的停止训练标准,使对机器的训练在合适的程度;
(3)保留验证数据集,对训练成果进行验证;
(4)获取额外数据进行交叉验证;
(5)正则化,即在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项,一般有L1正则与L2正则等。
(6)进行特征选择、特征降维
(7)控制模型的复杂度。如进行剪枝、控制树深度;增大分割平面间隔;
未完,,待继补充。。。
参考:https://wenku.baidu.com/view/29b3f4021fb91a37f111f18583d049649a660e31.html
https://blog.csdn.net/liubo187/article/details/77092729
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/136463.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
