大家好,又见面了,我是你们的朋友全栈君。
神经网络学习小记录-番外篇——常见问题汇总
- 前言
- 问题汇总
-
- 1、下载问题
- 2、环境配置问题
-
- a、20系列所用的环境
- b、30系列显卡环境配置
- c、CPU环境配置
- d、GPU利用问题与环境使用问题
- e、DLL load failed: 找不到指定的模块
- f、no module问题(no module name utils.utils、no module named ‘matplotlib’ )
- g、cuda安装失败问题
- h、Ubuntu系统问题
- i、VSCODE提示错误的问题
- j、使用cpu进行训练与预测的问题
- k、tqdm没有pos参数问题
- l、提示decode(“utf-8”)的问题
- m、提示TypeError: __array__() takes 1 positional argument but 2 were given错误
- n、如何查看当前cuda和cudnn
- o、为什么按照你的环境配置后还是不能使用
- p、其它问题
- 3、目标检测库问题汇总(人脸检测和分类库也可参考)
-
- a、shape不匹配问题。
- b、显存不足问题(OOM、RuntimeError: CUDA out of memory)。
- c、为什么要进行冻结训练与解冻训练,不进行行吗?
- d、我的LOSS好大啊,有问题吗?(我的LOSS好小啊,有问题吗?)
- e、为什么我训练出来的模型没有预测结果?
- f、为什么我计算出来的map是0?
- g、gbk编码错误(’gbk’ codec can’t decode byte)。
- h、我的图片是xxx*xxx的分辨率的,可以用吗?
- i、我想进行数据增强!怎么增强?
- j、多GPU训练。
- k、能不能训练灰度图?
- l、断点续练问题。
- m、我要训练其它的数据集,预训练权重能不能用?
- n、网络如何从0开始训练?
- o、为什么从0开始训练效果这么差(修改了网络主干,效果不好怎么办)?
- p、你的权值都是哪里来的?
- q、视频检测与摄像头检测
- r、如何保存检测出的图片
- s、遍历问题
- t、路径问题(No such file or directory、StopIteration: [Errno 13] Permission denied: ‘XXXXXX’)
- u、和原版比较问题,你怎么和原版不一样啊?
- v、我的检测速度是xxx正常吗?我的检测速度还能增快吗?
- w、预测图片不显示问题
- x、算法评价问题(目标检测的map、PR曲线、Recall、Precision等)
- y、coco数据集训练问题
- z、UP,怎么优化模型啊?我想提升效果
- aa、UP,有Focal LOSS的代码吗?怎么改啊?
- ab、部署问题(ONNX、TensorRT等)
- 4、语义分割库问题汇总
-
- a、shape不匹配问题
- b、显存不足问题(OOM、RuntimeError: CUDA out of memory)。
- c、为什么要进行冻结训练与解冻训练,不进行行吗?
- d、我的LOSS好大啊,有问题吗?(我的LOSS好小啊,有问题吗?)
- e、为什么我训练出来的模型没有预测结果?
- f、为什么我计算出来的miou是0?
- g、gbk编码错误(’gbk’ codec can’t decode byte)。
- h、我的图片是xxx*xxx的分辨率的,可以用吗?
- i、我想进行数据增强!怎么增强?
- j、多GPU训练。
- k、能不能训练灰度图?
- l、断点续练问题。
- m、我要训练其它的数据集,预训练权重能不能用?
- n、网络如何从0开始训练?
- o、为什么从0开始训练效果这么差(修改了网络主干,效果不好怎么办)?
- p、你的权值都是哪里来的?
- q、视频检测与摄像头检测
- r、如何保存检测出的图片
- s、遍历问题
- t、路径问题(No such file or directory、StopIteration: [Errno 13] Permission denied: ‘XXXXXX’)
- u、和原版比较问题,你怎么和原版不一样啊?
- v、我的检测速度是xxx正常吗?我的检测速度还能增快吗?
- w、预测图片不显示问题
- x、算法评价问题(miou)
- y、UP,怎么优化模型啊?我想提升效果
- z、部署问题(ONNX、TensorRT等)
- 5、交流群问题
- 6、怎么学习的问题
前言
搞个问题汇总吧,不然一个一个解释也挺难的。


问题汇总
1、下载问题
a、代码下载
问:up主,可以给我发一份代码吗,代码在哪里下载啊?
答:Github上的地址就在视频简介里。复制一下就能进去下载了。
问:up主,为什么我下载的代码提示压缩包损坏?
答:重新去Github下载。
问:up主,为什么我下载的代码和你在视频以及博客上的代码不一样?
答:我常常会对代码进行更新,最终以实际的代码为准。
b、 权值下载
问:up主,为什么我下载的代码里面,model_data下面没有.pth或者.h5文件?
答:我一般会把权值上传到Github和百度网盘,在GITHUB的README里面就能找到。
c、 数据集下载
问:up主,XXXX数据集在哪里下载啊?
答:一般数据集的下载地址我会放在README里面,基本上都有,没有的话请及时联系我添加,直接发github的issue即可。
2、环境配置问题
a、20系列所用的环境
pytorch代码对应的pytorch版本为1.2,博客地址对应https://blog.csdn.net/weixin_44791964/article/details/106037141。
keras代码对应的tensorflow版本为1.13.2,keras版本是2.1.5,博客地址对应https://blog.csdn.net/weixin_44791964/article/details/104702142。
tf2代码对应的tensorflow版本为2.2.0,无需安装keras,博客地址对应https://blog.csdn.net/weixin_44791964/article/details/109161493。
问:你的代码某某某版本的tensorflow和pytorch能用嘛?
答:最好按照我推荐的配置,配置教程也有!其它版本的我没有试过!可能出现问题但是一般问题不大。仅需要改少量代码即可。
b、30系列显卡环境配置
30系显卡由于框架更新不可使用上述环境配置教程。
当前我已经测试的可以用的30显卡配置如下:
pytorch代码对应的pytorch版本为1.7.0,cuda为11.0,cudnn为8.0.5,博客地址对应https://blog.csdn.net/weixin_44791964/article/details/120668551。
keras代码无法在win10下配置cuda11,在ubuntu下可以百度查询一下,配置tensorflow版本为1.15.4,keras版本是2.1.5或者2.3.1(少量函数接口不同,代码可能还需要少量调整。)
tf2代码对应的tensorflow版本为2.4.0,cuda为11.0,cudnn为8.0.5,博客地址对应为https://blog.csdn.net/weixin_44791964/article/details/120657664。
c、CPU环境配置
pytorch代码对应的pytorch-cpu版本为1.2,博客地址对应https://blog.csdn.net/weixin_44791964/article/details/120655098
keras代码对应的tensorflow-cpu版本为1.13.2,keras版本是2.1.5,博客地址对应https://blog.csdn.net/weixin_44791964/article/details/120653717。
tf2代码对应的tensorflow-cpu版本为2.2.0,无需安装keras,博客地址对应https://blog.csdn.net/weixin_44791964/article/details/120656291。
d、GPU利用问题与环境使用问题
问:为什么我安装了tensorflow-gpu但是却没用利用GPU进行训练呢?
答:确认tensorflow-gpu已经装好,利用pip list查看tensorflow版本,然后查看任务管理器或者利用nvidia命令看看是否使用了gpu进行训练,任务管理器的话要看显存使用情况。
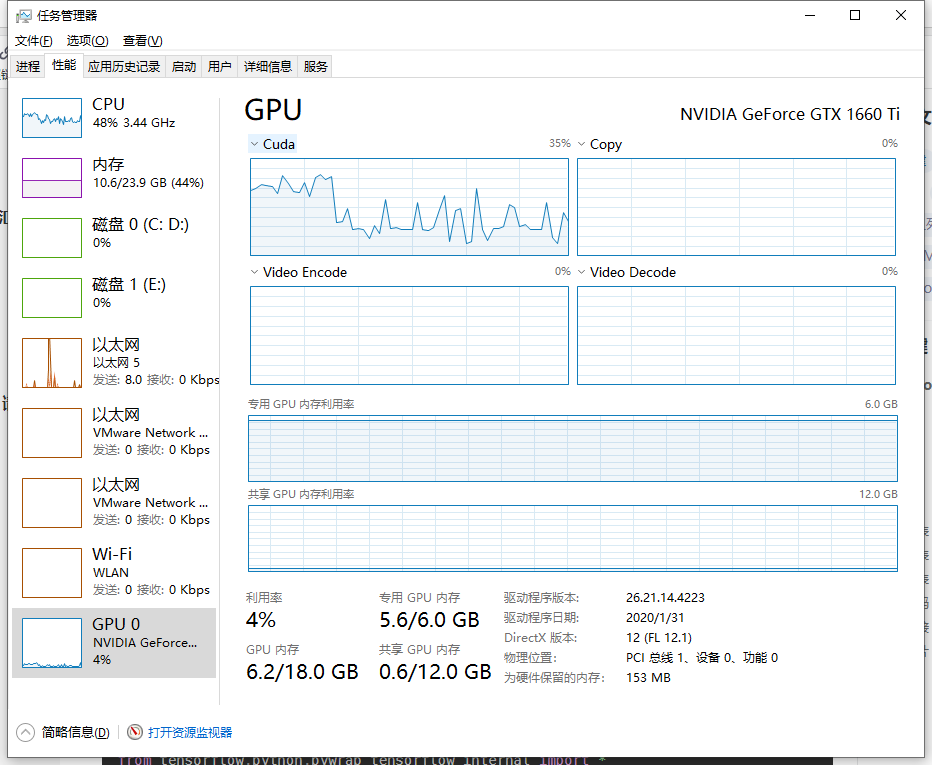
问:up主,我好像没有在用gpu进行训练啊,怎么看是不是用了GPU进行训练?
答:查看是否使用GPU进行训练一般使用NVIDIA在命令行的查看命令。在windows电脑中打开cmd然后利用nvidia-smi指令查看GPU利用情况
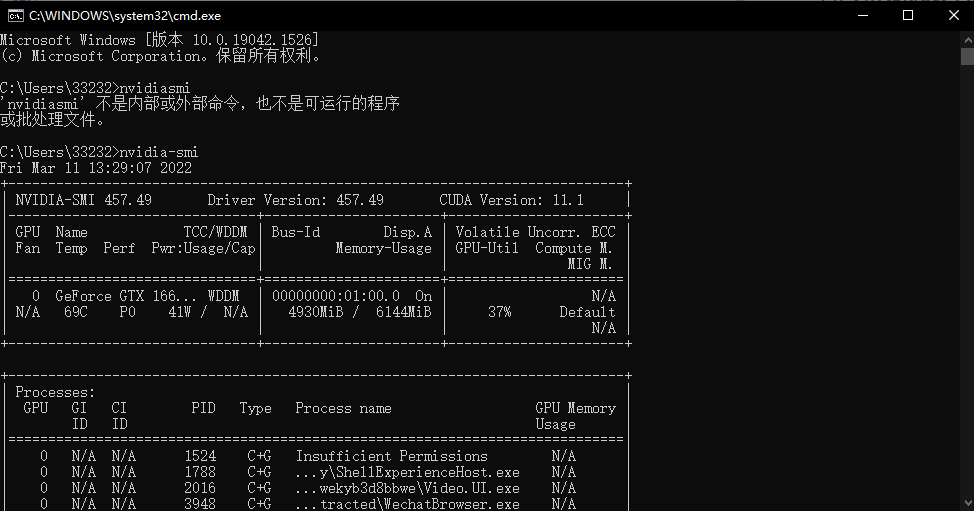

如果要一定看任务管理器的话,请看性能部分GPU的显存是否利用,或者查看任务管理器的Cuda,而非Copy。
e、DLL load failed: 找不到指定的模块
问:出现如下错误
Traceback (most recent call last):
File "C:\Users\focus\Anaconda3\ana\envs\tensorflow-gpu\lib\site-packages\tensorflow\python\pywrap_tensorflow.py", line 58, in <module>
from tensorflow.python.pywrap_tensorflow_internal import *
File "C:\Users\focus\Anaconda3\ana\envs\tensorflow-gpu\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py", line 28, in <module>
pywrap_tensorflow_internal = swig_import_helper()
File "C:\Users\focus\Anaconda3\ana\envs\tensorflow-gpu\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py", line 24, in swig_import_helper
_mod = imp.load_module('_pywrap_tensorflow_internal', fp, pathname, description)
File "C:\Users\focus\Anaconda3\ana\envs\tensorflow-gpu\lib\imp.py", line 243, in load_modulereturn load_dynamic(name, filename, file)
File "C:\Users\focus\Anaconda3\ana\envs\tensorflow-gpu\lib\imp.py", line 343, in load_dynamic
return _load(spec)
ImportError: DLL load failed: 找不到指定的模块。
答:如果没重启过就重启一下,否则重新按照步骤安装,还无法解决则把你的GPU、CUDA、CUDNN、TF版本以及PYTORCH版本私聊告诉我。
f、no module问题(no module name utils.utils、no module named ‘matplotlib’ )
问:为什么提示说no module name utils.utils(no module name nets.yolo、no module name nets.ssd等一系列问题)啊?
答:utils并不需要用pip装,它就在我上传的仓库的根目录,出现这个问题的原因是根目录不对,查查相对目录和根目录的概念。查了基本上就明白了。
问:为什么提示说no module name matplotlib(no module name PIL,no module name cv2等等)?
答:这个库没安装打开命令行安装就好。pip install matplotlib
问:为什么我已经用pip装了opencv(pillow、matplotlib等),还是提示no module name cv2?
答:没有激活环境装,要激活对应的conda环境进行安装才可以正常使用
问:为什么提示说No module named ‘torch’ ?
答:其实我也真的很想知道为什么会有这个问题……这个pytorch没装是什么情况?一般就俩情况,一个是真的没装,还有一个是装到其它环境了,当前激活的环境不是自己装的环境。
问:为什么提示说No module named ‘tensorflow’ ?
答:同上。
g、cuda安装失败问题
一般cuda安装前需要安装Visual Studio,装个2017版本即可。
h、Ubuntu系统问题
所有代码在Ubuntu下可以使用,我两个系统都试过。
i、VSCODE提示错误的问题
问:为什么在VSCODE里面提示一大堆的错误啊?
答:我也提示一大堆的错误,但是不影响,是VSCODE的问题,如果不想看错误的话就装Pycharm。
最好将设置里面的Python:Language Server,调整为Pylance。
j、使用cpu进行训练与预测的问题
对于keras和tf2的代码而言,如果想用cpu进行训练和预测,直接装cpu版本的tensorflow就可以了。
对于pytorch的代码而言,如果想用cpu进行训练和预测,需要将cuda=True修改成cuda=False。
k、tqdm没有pos参数问题
问:运行代码提示’tqdm’ object has no attribute ‘pos’。
答:重装tqdm,换个版本就可以了。
l、提示decode(“utf-8”)的问题
由于h5py库的更新,安装过程中会自动安装h5py=3.0.0以上的版本,会导致decode(“utf-8”)的错误!
各位一定要在安装完tensorflow后利用命令装h5py=2.10.0!
pip install h5py==2.10.0
m、提示TypeError: array() takes 1 positional argument but 2 were given错误
可以修改pillow版本解决。
pip install pillow==8.2.0
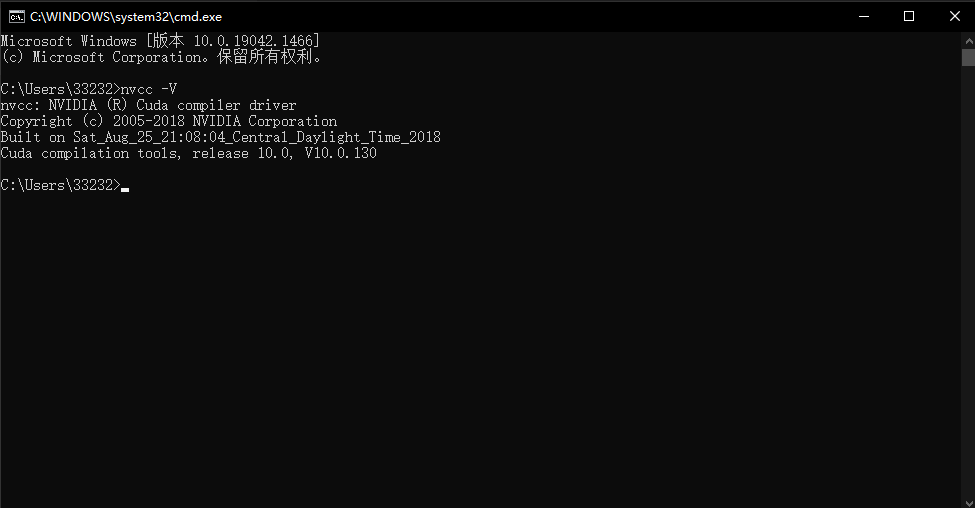
n、如何查看当前cuda和cudnn
window下cuda版本查看方式如下:
1、打开cmd窗口。
2、输入nvcc -V。
3、Cuda compilation tools, release XXXXXXXX中的XXXXXXXX即cuda版本。
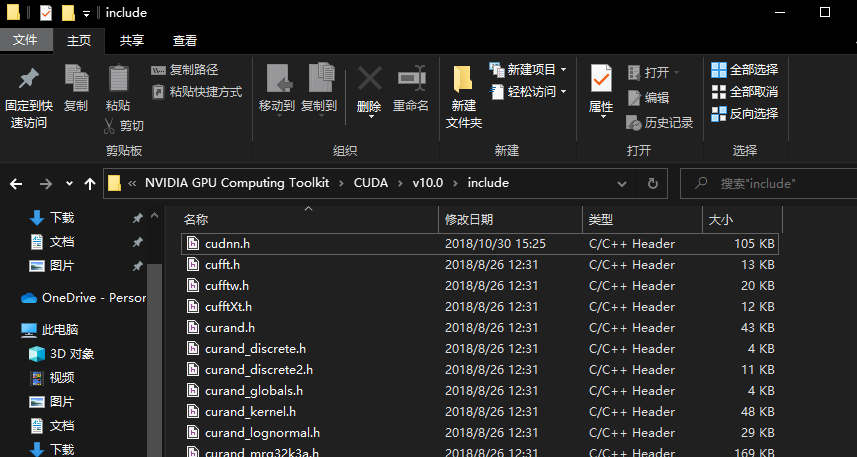
window下cudnn版本查看方式如下:
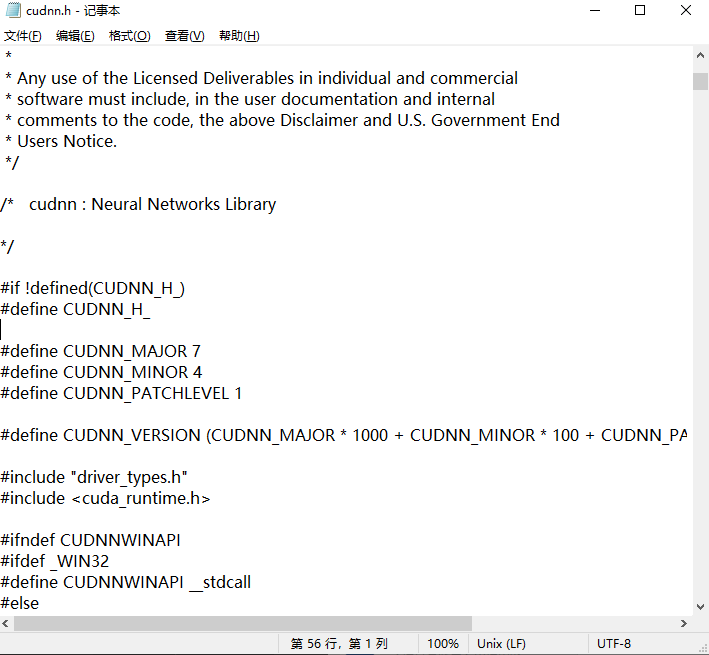
1、进入cuda安装目录,进入incude文件夹。
2、找到cudnn.h文件。
3、右键文本打开,下拉,看到#define处可获得cudnn版本。
#define CUDNN_MAJOR 7
#define CUDNN_MINOR 4
#define CUDNN_PATCHLEVEL 1
代表cudnn为7.4.1。
o、为什么按照你的环境配置后还是不能使用
问:up主,为什么我按照你的环境配置后还是不能使用?
答:请把你的GPU、CUDA、CUDNN、TF版本以及PYTORCH版本B站私聊告诉我。
p、其它问题
问:为什么提示TypeError: cat() got an unexpected keyword argument ‘axis’,Traceback (most recent call last),AttributeError: ‘Tensor’ object has no attribute ‘bool’?
答:这是版本问题,建议使用torch1.2以上版本
其它有很多稀奇古怪的问题,很多是版本问题,建议按照我的视频教程安装Keras和tensorflow。比如装的是tensorflow2,就不用问我说为什么我没法运行Keras-yolo啥的。那是必然不行的。
3、目标检测库问题汇总(人脸检测和分类库也可参考)
a、shape不匹配问题。
1)、训练时shape不匹配问题。
问:up主,为什么运行train.py会提示shape不匹配啊?
答:在keras环境中,因为你训练的种类和原始的种类不同,网络结构会变化,所以最尾部的shape会有少量不匹配。
2)、预测时shape不匹配问题。
问:为什么我运行predict.py会提示我说shape不匹配呀。
i、copying a param with shape torch.Size([75, 704, 1, 1]) from checkpoint
在Pytorch里面是这样的:

ii、Shapes are [1,1,1024,75] and [255,1024,1,1]. for ‘Assign_360’ (op: ‘Assign’) with input shapes: [1,1,1024,75], [255,1024,1,1].
在Keras里面是这样的:
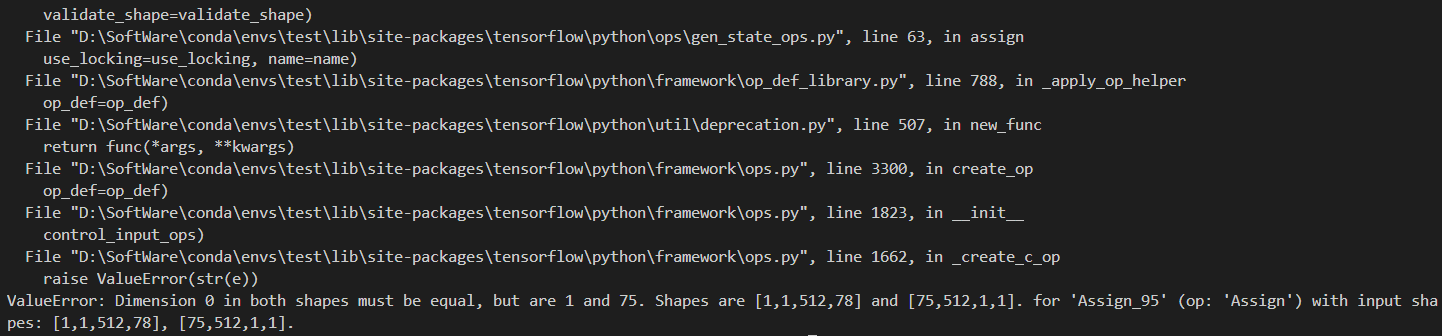
答:原因主要有仨:
1、训练的classes_path没改,就开始训练了。
2、训练的model_path没改。
3、训练的classes_path没改。
请检查清楚了!确定自己所用的model_path和classes_path是对应的!训练的时候用到的num_classes或者classes_path也需要检查!
b、显存不足问题(OOM、RuntimeError: CUDA out of memory)。
问:为什么我运行train.py下面的命令行闪的贼快,还提示OOM啥的?
答:这是在keras中出现的,爆显存了,可以改小batch_size,SSD的显存占用率是最小的,建议用SSD;
2G显存:SSD、YOLOV4-TINY
4G显存:YOLOV3
6G显存:YOLOV4、Retinanet、M2det、Efficientdet、Faster RCNN等
8G+显存:随便选吧。
需要注意的是,受到BatchNorm2d影响,batch_size不可为1,至少为2。
问:为什么提示 RuntimeError: CUDA out of memory. Tried to allocate 52.00 MiB (GPU 0; 15.90 GiB total capacity; 14.85 GiB already allocated; 51.88 MiB free; 15.07 GiB reserved in total by PyTorch)?
答:这是pytorch中出现的,爆显存了,同上。
问:为什么我显存都没利用,就直接爆显存了?
答:都爆显存了,自然就不利用了,模型没有开始训练。
c、为什么要进行冻结训练与解冻训练,不进行行吗?
问:为什么要冻结训练和解冻训练呀?
答:可以不进行,本质上是为了保证性能不足的同学的训练,如果电脑性能完全不够,可以将Freeze_Epoch和UnFreeze_Epoch设置成一样,只进行冻结训练。
同时这也是迁移学习的思想,因为神经网络主干特征提取部分所提取到的特征是通用的,我们冻结起来训练可以加快训练效率,也可以防止权值被破坏。
在冻结阶段,模型的主干被冻结了,特征提取网络不发生改变。占用的显存较小,仅对网络进行微调。
在解冻阶段,模型的主干不被冻结了,特征提取网络会发生改变。占用的显存较大,网络所有的参数都会发生改变。
d、我的LOSS好大啊,有问题吗?(我的LOSS好小啊,有问题吗?)
问:为什么我的网络不收敛啊,LOSS是XXXX。
答:不同网络的LOSS不同,LOSS只是一个参考指标,用于查看网络是否收敛,而非评价网络好坏,我的yolo代码都没有归一化,所以LOSS值看起来比较高,LOSS的值不重要,重要的是是否在变小,预测是否有效果。
e、为什么我训练出来的模型没有预测结果?
问:为什么我的训练效果不好?预测了没有框(框不准)。
答:
考虑几个问题:
1、目标信息问题,查看2007_train.txt文件是否有目标信息,没有的话请修改voc_annotation.py。
2、数据集问题,小于500的自行考虑增加数据集,同时测试不同的模型,确认数据集是好的。
3、是否解冻训练,如果数据集分布与常规画面差距过大需要进一步解冻训练,调整主干,加强特征提取能力。
4、网络问题,比如SSD不适合小目标,因为先验框固定了。
5、训练时长问题,有些同学只训练了几代表示没有效果,按默认参数训练完。
6、确认自己是否按照步骤去做了,如果比如voc_annotation.py里面的classes是否修改了等。
7、不同网络的LOSS不同,LOSS只是一个参考指标,用于查看网络是否收敛,而非评价网络好坏,LOSS的值不重要,重要的是是否收敛。
8、是否修改了网络的主干,如果修改了没有预训练权重,网络不容易收敛,自然效果不好。
f、为什么我计算出来的map是0?
问:为什么我的训练效果不好?没有map?
答:
首先尝试利用predict.py预测一下,如果有效果的话应该是get_map.py里面的classes_path设置错误。如果没有预测结果的话,解决方法同e问题,对下面几点进行检查:
1、目标信息问题,查看2007_train.txt文件是否有目标信息,没有的话请修改voc_annotation.py。
2、数据集问题,小于500的自行考虑增加数据集,同时测试不同的模型,确认数据集是好的。
3、是否解冻训练,如果数据集分布与常规画面差距过大需要进一步解冻训练,调整主干,加强特征提取能力。
4、网络问题,比如SSD不适合小目标,因为先验框固定了。
5、训练时长问题,有些同学只训练了几代表示没有效果,按默认参数训练完。
6、确认自己是否按照步骤去做了,如果比如voc_annotation.py里面的classes是否修改了等。
7、不同网络的LOSS不同,LOSS只是一个参考指标,用于查看网络是否收敛,而非评价网络好坏,LOSS的值不重要,重要的是是否收敛。
8、是否修改了网络的主干,如果修改了没有预训练权重,网络不容易收敛,自然效果不好。
g、gbk编码错误(‘gbk’ codec can’t decode byte)。
问:我怎么出现了gbk什么的编码错误啊:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa6 in position 446: illegal multibyte sequence
答:标签和路径不要使用中文,如果一定要使用中文,请注意处理的时候编码的问题,改成打开文件的encoding方式改为utf-8。
h、我的图片是xxx*xxx的分辨率的,可以用吗?
问:我的图片是xxx*xxx的分辨率的,可以用吗!
答:可以用,代码里面会自动进行resize与数据增强。
i、我想进行数据增强!怎么增强?
问:我想要进行数据增强!怎么做呢?
答:可以用,代码里面会自动进行resize与数据增强。
j、多GPU训练。
问:怎么进行多GPU训练?
答:pytorch的大多数代码可以直接使用gpu训练,keras的话直接百度就好了,实现并不复杂,我没有多卡没法详细测试,还需要各位同学自己努力了。
k、能不能训练灰度图?
问:能不能训练灰度图(预测灰度图)啊?
答:我的大多数库会将灰度图转化成RGB进行训练和预测,如果遇到代码不能训练或者预测灰度图的情况,可以尝试一下在get_random_data里面将Image.open后的结果转换成RGB,预测的时候也这样试试。(仅供参考)
l、断点续练问题。
问:我已经训练过几个世代了,能不能从这个基础上继续开始训练
答:可以,你在训练前,和载入预训练权重一样载入训练过的权重就行了。一般训练好的权重会保存在logs文件夹里面,将model_path修改成你要开始的权值的路径即可。
m、我要训练其它的数据集,预训练权重能不能用?
问:如果我要训练其它的数据集,预训练权重要怎么办啊?
答:数据的预训练权重对不同数据集是通用的,因为特征是通用的,预训练权重对于99%的情况都必须要用,不用的话权值太过随机,特征提取效果不明显,网络训练的结果也不会好。
n、网络如何从0开始训练?
问:我要怎么不使用预训练权重啊?
答:看一看注释、大多数代码是model_path = ‘’,Freeze_Train = Fasle,如果设置model_path无用,那么把载入预训练权重的代码注释了就行。
o、为什么从0开始训练效果这么差(修改了网络主干,效果不好怎么办)?
问:为什么我不使用预训练权重效果这么差啊?
答:因为随机初始化的权值不好,提取的特征不好,也就导致了模型训练的效果不好,voc07+12、coco+voc07+12效果都不一样,预训练权重还是非常重要的。
问:up,我修改了网络,预训练权重还能用吗?
答:修改了主干的话,如果不是用的现有的网络,基本上预训练权重是不能用的,要么就自己判断权值里卷积核的shape然后自己匹配,要么只能自己预训练去了;修改了后半部分的话,前半部分的主干部分的预训练权重还是可以用的,如果是pytorch代码的话,需要自己修改一下载入权值的方式,判断shape后载入,如果是keras代码,直接by_name=True,skip_mismatch=True即可。
权值匹配的方式可以参考如下:
# 加快模型训练的效率
print('Loading weights into state dict...')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_dict = model.state_dict()
pretrained_dict = torch.load(model_path, map_location=device)
a = {
}
for k, v in pretrained_dict.items():
try:
if np.shape(model_dict[k]) == np.shape(v):
a[k]=v
except:
pass
model_dict.update(a)
model.load_state_dict(model_dict)
print('Finished!')
问:为什么从0开始训练效果这么差(我修改了网络主干,效果不好怎么办)?
答:一般来讲,网络从0开始的训练效果会很差,因为权值太过随机,特征提取效果不明显,因此非常、非常、非常不建议大家从0开始训练!如果一定要从0开始,可以了解imagenet数据集,首先训练分类模型,获得网络的主干部分权值,分类模型的 主干部分 和该模型通用,基于此进行训练。
网络修改了主干之后也是同样的问题,随机的权值效果很差。
问:怎么在模型上从0开始训练?
答:在算力不足与调参能力不足的情况下从0开始训练毫无意义。模型特征提取能力在随机初始化参数的情况下非常差。没有好的参数调节能力和算力,无法使得网络正常收敛。
如果一定要从0开始,那么训练的时候请注意几点:
- 不载入预训练权重。
- 不要进行冻结训练,注释冻结模型的代码。
问:为什么我不使用预训练权重效果这么差啊?
答:因为随机初始化的权值不好,提取的特征不好,也就导致了模型训练的效果不好,voc07+12、coco+voc07+12效果都不一样,预训练权重还是非常重要的。
p、你的权值都是哪里来的?
问:如果网络不能从0开始训练的话你的权值哪里来的?
答:有些权值是官方转换过来的,有些权值是自己训练出来的,我用到的主干的imagenet的权值都是官方的。
q、视频检测与摄像头检测
问:怎么用摄像头检测呀?
答:predict.py修改参数可以进行摄像头检测,也有视频详细解释了摄像头检测的思路。
问:怎么用视频检测呀?
答:同上
r、如何保存检测出的图片
问:检测完的图片怎么保存?
答:一般目标检测用的是Image,所以查询一下PIL库的Image如何进行保存。详细看看predict.py文件的注释。
问:怎么用视频保存呀?
答:详细看看predict.py文件的注释。
s、遍历问题
问:如何对一个文件夹的图片进行遍历?
答:一般使用os.listdir先找出文件夹里面的所有图片,然后根据predict.py文件里面的执行思路检测图片就行了,详细看看predict.py文件的注释。
问:如何对一个文件夹的图片进行遍历?并且保存。
答:遍历的话一般使用os.listdir先找出文件夹里面的所有图片,然后根据predict.py文件里面的执行思路检测图片就行了。保存的话一般目标检测用的是Image,所以查询一下PIL库的Image如何进行保存。如果有些库用的是cv2,那就是查一下cv2怎么保存图片。详细看看predict.py文件的注释。
t、路径问题(No such file or directory、StopIteration: [Errno 13] Permission denied: ‘XXXXXX’)
问:我怎么出现了这样的错误呀:
FileNotFoundError: 【Errno 2】 No such file or directory
StopIteration: [Errno 13] Permission denied: 'D:\\Study\\Collection\\Dataset\\VOC07+12+test\\VOCdevkit/VOC2007'
……………………………………
……………………………………
答:去检查一下文件夹路径,查看是否有对应文件;并且检查一下2007_train.txt,其中文件路径是否有错。
关于路径有几个重要的点:
文件夹名称中一定不要有空格。
注意相对路径和绝对路径。
多百度路径相关的知识。
所有的路径问题基本上都是根目录问题,好好查一下相对目录的概念!
u、和原版比较问题,你怎么和原版不一样啊?
问:原版的代码是XXX,为什么你的代码是XXX?
答:是啊……这要不怎么说我不是原版呢……
问:你这个代码和原版比怎么样,可以达到原版的效果么?
答:基本上可以达到,我都用voc数据测过,我没有好显卡,没有能力在coco上测试与训练。
问:你有没有实现yolov4所有的tricks,和原版差距多少?
答:并没有实现全部的改进部分,由于YOLOV4使用的改进实在太多了,很难完全实现与列出来,这里只列出来了一些我比较感兴趣,而且非常有效的改进。论文中提到的SAM(注意力机制模块),作者自己的源码也没有使用。还有其它很多的tricks,不是所有的tricks都有提升,我也没法实现全部的tricks。至于和原版的比较,我没有能力训练coco数据集,根据使用过的同学反应差距不大。
v、我的检测速度是xxx正常吗?我的检测速度还能增快吗?
问:你这个FPS可以到达多少,可以到 XX FPS么?
答:FPS和机子的配置有关,配置高就快,配置低就慢。
问:我的检测速度是xxx正常吗?我的检测速度还能增快吗?
答:看配置,配置好速度就快,如果想要配置不变的情况下加快速度,就要修改网络了。
问:为什么我用服务器去测试yolov4(or others)的FPS只有十几?
答:检查是否正确安装了tensorflow-gpu或者pytorch的gpu版本,如果已经正确安装,可以去利用time.time()的方法查看detect_image里面,哪一段代码耗时更长(不仅只有网络耗时长,其它处理部分也会耗时,如绘图等)。
问:为什么论文中说速度可以达到XX,但是这里却没有?
答:检查是否正确安装了tensorflow-gpu或者pytorch的gpu版本,如果已经正确安装,可以去利用time.time()的方法查看detect_image里面,哪一段代码耗时更长(不仅只有网络耗时长,其它处理部分也会耗时,如绘图等)。有些论文还会使用多batch进行预测,我并没有去实现这个部分。
w、预测图片不显示问题
问:为什么你的代码在预测完成后不显示图片?只是在命令行告诉我有什么目标。
答:给系统安装一个图片查看器就行了。
x、算法评价问题(目标检测的map、PR曲线、Recall、Precision等)
问:怎么计算map?
答:看map视频,都一个流程。
问:计算map的时候,get_map.py里面有一个MINOVERLAP是什么用的,是iou吗?
答:是iou,它的作用是判断预测框和真实框的重合成度,如果重合程度大于MINOVERLAP,则预测正确。
问:为什么get_map.py里面的self.confidence(self.score)要设置的那么小?
答:看一下map的视频的原理部分,要知道所有的结果然后再进行pr曲线的绘制。
问:能不能说说怎么绘制PR曲线啥的呀。
答:可以看mAP视频,结果里面有PR曲线。
问:怎么计算Recall、Precision指标。
答:这俩指标应该是相对于特定的置信度的,计算map的时候也会获得。
y、coco数据集训练问题
问:目标检测怎么训练COCO数据集啊?。
答:coco数据训练所需要的txt文件可以参考qqwweee的yolo3的库,格式都是一样的。
z、UP,怎么优化模型啊?我想提升效果
问:up,怎么修改模型啊,我想发个小论文!
答:建议看看yolov3和yolov4的区别,然后看看yolov4的论文,作为一个大型调参现场非常有参考意义,使用了很多tricks。我能给的建议就是多看一些经典模型,然后拆解里面的亮点结构并使用。
aa、UP,有Focal LOSS的代码吗?怎么改啊?
问:up,YOLO系列使用Focal LOSS的代码你有吗,有提升吗?
答:很多人试过,提升效果也不大(甚至变的更Low),它自己有自己的正负样本的平衡方式。改代码的事情,还是自己好好看看代码吧。
ab、部署问题(ONNX、TensorRT等)
我没有具体部署到手机等设备上过,所以很多部署问题我并不了解……
4、语义分割库问题汇总
a、shape不匹配问题
1)、训练时shape不匹配问题
问:up主,为什么运行train.py会提示shape不匹配啊?
答:在keras环境中,因为你训练的种类和原始的种类不同,网络结构会变化,所以最尾部的shape会有少量不匹配。
2)、预测时shape不匹配问题
问:为什么我运行predict.py会提示我说shape不匹配呀。
i、copying a param with shape torch.Size([75, 704, 1, 1]) from checkpoint
在Pytorch里面是这样的:
ii、Shapes are [1,1,1024,75] and [255,1024,1,1]. for ‘Assign_360’ (op: ‘Assign’) with input shapes: [1,1,1024,75], [255,1024,1,1].
在Keras里面是这样的:
答:原因主要有二:
1、train.py里面的num_classes没改。
2、预测时num_classes没改。
3、预测时model_path没改。
请检查清楚!训练和预测的时候用到的num_classes都需要检查!
b、显存不足问题(OOM、RuntimeError: CUDA out of memory)。
问:为什么我运行train.py下面的命令行闪的贼快,还提示OOM啥的?
答:这是在keras中出现的,爆显存了,可以改小batch_size。
需要注意的是,受到BatchNorm2d影响,batch_size不可为1,至少为2。
问:为什么提示 RuntimeError: CUDA out of memory. Tried to allocate 52.00 MiB (GPU 0; 15.90 GiB total capacity; 14.85 GiB already allocated; 51.88 MiB free; 15.07 GiB reserved in total by PyTorch)?
答:这是pytorch中出现的,爆显存了,同上。
问:为什么我显存都没利用,就直接爆显存了?
答:都爆显存了,自然就不利用了,模型没有开始训练。
c、为什么要进行冻结训练与解冻训练,不进行行吗?
问:为什么要冻结训练和解冻训练呀?
答:可以不进行,本质上是为了保证性能不足的同学的训练,如果电脑性能完全不够,可以将Freeze_Epoch和UnFreeze_Epoch设置成一样,只进行冻结训练。
同时这也是迁移学习的思想,因为神经网络主干特征提取部分所提取到的特征是通用的,我们冻结起来训练可以加快训练效率,也可以防止权值被破坏。
在冻结阶段,模型的主干被冻结了,特征提取网络不发生改变。占用的显存较小,仅对网络进行微调。
在解冻阶段,模型的主干不被冻结了,特征提取网络会发生改变。占用的显存较大,网络所有的参数都会发生改变。
d、我的LOSS好大啊,有问题吗?(我的LOSS好小啊,有问题吗?)
问:为什么我的网络不收敛啊,LOSS是XXXX。
答:不同网络的LOSS不同,LOSS只是一个参考指标,用于查看网络是否收敛,而非评价网络好坏,我的yolo代码都没有归一化,所以LOSS值看起来比较高,LOSS的值不重要,重要的是是否在变小,预测是否有效果。
e、为什么我训练出来的模型没有预测结果?
问:为什么我的训练效果不好?预测了没有框(框不准)。
答:
考虑几个问题:
1、数据集问题,这是最重要的问题。小于500的自行考虑增加数据集;一定要检查数据集的标签,视频中详细解析了VOC数据集的格式,但并不是有输入图片有输出标签即可,还需要确认标签的每一个像素值是否为它对应的种类。很多同学的标签格式不对,最常见的错误格式就是标签的背景为黑,目标为白,此时目标的像素点值为255,无法正常训练,目标需要为1才行。
2、是否解冻训练,如果数据集分布与常规画面差距过大需要进一步解冻训练,调整主干,加强特征提取能力。
3、网络问题,可以尝试不同的网络。
4、训练时长问题,有些同学只训练了几代表示没有效果,按默认参数训练完。
5、确认自己是否按照步骤去做了。
6、不同网络的LOSS不同,LOSS只是一个参考指标,用于查看网络是否收敛,而非评价网络好坏,LOSS的值不重要,重要的是是否收敛。
问:为什么我的训练效果不好?对小目标预测不准确。
答:对于deeplab和pspnet而言,可以修改一下downsample_factor,当downsample_factor为16的时候下采样倍数过多,效果不太好,可以修改为8。
f、为什么我计算出来的miou是0?
问:为什么我的训练效果不好?计算出来的miou是0?。
答:
与e类似,考虑几个问题:
1、数据集问题,这是最重要的问题。小于500的自行考虑增加数据集;一定要检查数据集的标签,视频中详细解析了VOC数据集的格式,但并不是有输入图片有输出标签即可,还需要确认标签的每一个像素值是否为它对应的种类。很多同学的标签格式不对,最常见的错误格式就是标签的背景为黑,目标为白,此时目标的像素点值为255,无法正常训练,目标需要为1才行。
2、是否解冻训练,如果数据集分布与常规画面差距过大需要进一步解冻训练,调整主干,加强特征提取能力。
3、网络问题,可以尝试不同的网络。
4、训练时长问题,有些同学只训练了几代表示没有效果,按默认参数训练完。
5、确认自己是否按照步骤去做了。
6、不同网络的LOSS不同,LOSS只是一个参考指标,用于查看网络是否收敛,而非评价网络好坏,LOSS的值不重要,重要的是是否收敛。
g、gbk编码错误(‘gbk’ codec can’t decode byte)。
问:我怎么出现了gbk什么的编码错误啊:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa6 in position 446: illegal multibyte sequence
答:标签和路径不要使用中文,如果一定要使用中文,请注意处理的时候编码的问题,改成打开文件的encoding方式改为utf-8。
h、我的图片是xxx*xxx的分辨率的,可以用吗?
问:我的图片是xxx*xxx的分辨率的,可以用吗!
答:可以用,代码里面会自动进行resize与数据增强。
i、我想进行数据增强!怎么增强?
问:我想要进行数据增强!怎么做呢?
答:可以用,代码里面会自动进行resize与数据增强。
j、多GPU训练。
问:怎么进行多GPU训练?
答:pytorch的大多数代码可以直接使用gpu训练,keras的话直接百度就好了,实现并不复杂,我没有多卡没法详细测试,还需要各位同学自己努力了。
k、能不能训练灰度图?
问:能不能训练灰度图(预测灰度图)啊?
答:我的大多数库会将灰度图转化成RGB进行训练和预测,如果遇到代码不能训练或者预测灰度图的情况,可以尝试一下在get_random_data里面将Image.open后的结果转换成RGB,预测的时候也这样试试。(仅供参考)
l、断点续练问题。
问:我已经训练过几个世代了,能不能从这个基础上继续开始训练
答:可以,你在训练前,和载入预训练权重一样载入训练过的权重就行了。一般训练好的权重会保存在logs文件夹里面,将model_path修改成你要开始的权值的路径即可。
m、我要训练其它的数据集,预训练权重能不能用?
问:如果我要训练其它的数据集,预训练权重要怎么办啊?
答:数据的预训练权重对不同数据集是通用的,因为特征是通用的,预训练权重对于99%的情况都必须要用,不用的话权值太过随机,特征提取效果不明显,网络训练的结果也不会好。
n、网络如何从0开始训练?
问:我要怎么不使用预训练权重啊?
答:看一看注释、大多数代码是model_path = ‘’,Freeze_Train = Fasle,如果设置model_path无用,那么把载入预训练权重的代码注释了就行。
o、为什么从0开始训练效果这么差(修改了网络主干,效果不好怎么办)?
问:为什么我不使用预训练权重效果这么差啊?
答:因为随机初始化的权值不好,提取的特征不好,也就导致了模型训练的效果不好,预训练权重还是非常重要的。
问:up,我修改了网络,预训练权重还能用吗?
答:修改了主干的话,如果不是用的现有的网络,基本上预训练权重是不能用的,要么就自己判断权值里卷积核的shape然后自己匹配,要么只能自己预训练去了;修改了后半部分的话,前半部分的主干部分的预训练权重还是可以用的,如果是pytorch代码的话,需要自己修改一下载入权值的方式,判断shape后载入,如果是keras代码,直接by_name=True,skip_mismatch=True即可。
权值匹配的方式可以参考如下:
# 加快模型训练的效率
print('Loading weights into state dict...')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_dict = model.state_dict()
pretrained_dict = torch.load(model_path, map_location=device)
a = {
}
for k, v in pretrained_dict.items():
try:
if np.shape(model_dict[k]) == np.shape(v):
a[k]=v
except:
pass
model_dict.update(a)
model.load_state_dict(model_dict)
print('Finished!')
问:为什么从0开始训练效果这么差(我修改了网络主干,效果不好怎么办)?
答:一般来讲,网络从0开始的训练效果会很差,因为权值太过随机,特征提取效果不明显,因此非常、非常、非常不建议大家从0开始训练!如果一定要从0开始,可以了解imagenet数据集,首先训练分类模型,获得网络的主干部分权值,分类模型的 主干部分 和该模型通用,基于此进行训练。
网络修改了主干之后也是同样的问题,随机的权值效果很差。
问:怎么在模型上从0开始训练?
答:在算力不足与调参能力不足的情况下从0开始训练毫无意义。模型特征提取能力在随机初始化参数的情况下非常差。没有好的参数调节能力和算力,无法使得网络正常收敛。
如果一定要从0开始,那么训练的时候请注意几点:
- 不载入预训练权重。
- 不要进行冻结训练,注释冻结模型的代码。
问:为什么我不使用预训练权重效果这么差啊?
答:因为随机初始化的权值不好,提取的特征不好,也就导致了模型训练的效果不好,voc07+12、coco+voc07+12效果都不一样,预训练权重还是非常重要的。
p、你的权值都是哪里来的?
问:如果网络不能从0开始训练的话你的权值哪里来的?
答:有些权值是官方转换过来的,有些权值是自己训练出来的,我用到的主干的imagenet的权值都是官方的。
q、视频检测与摄像头检测
问:怎么用摄像头检测呀?
答:predict.py修改参数可以进行摄像头检测,也有视频详细解释了摄像头检测的思路。
问:怎么用视频检测呀?
答:同上
r、如何保存检测出的图片
问:检测完的图片怎么保存?
答:一般目标检测用的是Image,所以查询一下PIL库的Image如何进行保存。详细看看predict.py文件的注释。
问:怎么用视频保存呀?
答:详细看看predict.py文件的注释。
s、遍历问题
问:如何对一个文件夹的图片进行遍历?
答:一般使用os.listdir先找出文件夹里面的所有图片,然后根据predict.py文件里面的执行思路检测图片就行了,详细看看predict.py文件的注释。
问:如何对一个文件夹的图片进行遍历?并且保存。
答:遍历的话一般使用os.listdir先找出文件夹里面的所有图片,然后根据predict.py文件里面的执行思路检测图片就行了。保存的话一般目标检测用的是Image,所以查询一下PIL库的Image如何进行保存。如果有些库用的是cv2,那就是查一下cv2怎么保存图片。详细看看predict.py文件的注释。
t、路径问题(No such file or directory、StopIteration: [Errno 13] Permission denied: ‘XXXXXX’)
问:我怎么出现了这样的错误呀:
FileNotFoundError: 【Errno 2】 No such file or directory
StopIteration: [Errno 13] Permission denied: 'D:\\Study\\Collection\\Dataset\\VOC07+12+test\\VOCdevkit/VOC2007'
……………………………………
……………………………………
答:去检查一下文件夹路径,查看是否有对应文件;并且检查一下2007_train.txt,其中文件路径是否有错。
关于路径有几个重要的点:
文件夹名称中一定不要有空格。
注意相对路径和绝对路径。
多百度路径相关的知识。
所有的路径问题基本上都是根目录问题,好好查一下相对目录的概念!
u、和原版比较问题,你怎么和原版不一样啊?
问:原版的代码是XXX,为什么你的代码是XXX?
答:是啊……这要不怎么说我不是原版呢……
问:你这个代码和原版比怎么样,可以达到原版的效果么?
答:基本上可以达到,我都用voc数据测过,我没有好显卡,没有能力在coco上测试与训练。
v、我的检测速度是xxx正常吗?我的检测速度还能增快吗?
问:你这个FPS可以到达多少,可以到 XX FPS么?
答:FPS和机子的配置有关,配置高就快,配置低就慢。
问:我的检测速度是xxx正常吗?我的检测速度还能增快吗?
答:看配置,配置好速度就快,如果想要配置不变的情况下加快速度,就要修改网络了。
问:为什么论文中说速度可以达到XX,但是这里却没有?
答:检查是否正确安装了tensorflow-gpu或者pytorch的gpu版本,如果已经正确安装,可以去利用time.time()的方法查看detect_image里面,哪一段代码耗时更长(不仅只有网络耗时长,其它处理部分也会耗时,如绘图等)。有些论文还会使用多batch进行预测,我并没有去实现这个部分。
w、预测图片不显示问题
问:为什么你的代码在预测完成后不显示图片?只是在命令行告诉我有什么目标。
答:给系统安装一个图片查看器就行了。
x、算法评价问题(miou)
问:怎么计算miou?
答:参考视频里的miou测量部分。
问:怎么计算Recall、Precision指标。
答:现有的代码还无法获得,需要各位同学理解一下混淆矩阵的概念,然后自行计算一下。
y、UP,怎么优化模型啊?我想提升效果
问:up,怎么修改模型啊,我想发个小论文!
答:建议目标检测中的yolov4论文,作为一个大型调参现场非常有参考意义,使用了很多tricks。我能给的建议就是多看一些经典模型,然后拆解里面的亮点结构并使用。
z、部署问题(ONNX、TensorRT等)
我没有具体部署到手机等设备上过,所以很多部署问题我并不了解……
5、交流群问题
问:up,有没有QQ群啥的呢?
答:没有没有,我没有时间管理QQ群……
6、怎么学习的问题
问:up,你的学习路线怎么样的?我是个小白我要怎么学?
答:这里有几点需要注意哈
1、我不是高手,很多东西我也不会,我的学习路线也不一定适用所有人。
2、我实验室不做深度学习,所以我很多东西都是自学,自己摸索,正确与否我也不知道。
3、我个人觉得学习更靠自学
学习路线的话,我是先学习了莫烦的python教程,从tensorflow、keras、pytorch入门,入门完之后学的SSD,YOLO,然后了解了很多经典的卷积网,后面就开始学很多不同的代码了,我的学习方法就是一行一行的看,了解整个代码的执行流程,特征层的shape变化等,花了很多时间也没有什么捷径,就是要花时间吧。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/136407.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...