大家好,又见面了,我是你们的朋友全栈君。
在《面试官:为啥加了索引查询会变快?》一文中,我们介绍了索引的数据结构,正是因为索引使用了B+树,才使得查询变快。说白了,索引的原理就是减少查询的次数、减少磁盘IO,达到快速查找所需数据的目的
我们一起来看一下InnoDB存储引擎中的索引
聚集索引
聚集索引(clustered index)就是按照每张表的主键构造一棵B+树,同时叶子节点中存放的即为整张表的行记录数据,也将聚集索引的叶子节点称为数据页。聚集索引的这个特性决定了索引组织表中数据也是索引的一部分
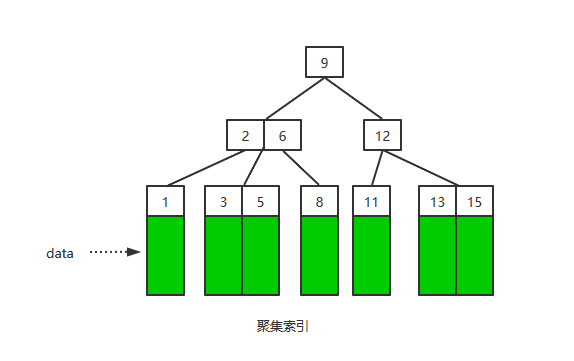

(备注:真实的B+树叶子节点是通过链表相连的,这里只是为了说明聚集索引存储了行数据,凑合着看吧~)
每张表只能拥有一个聚集索引。在多数情况下,查询优化器倾向于采用聚集索引。因为聚集索引能够在B+树索引的叶子节点上直接找到数据。此外,由于定义了数据的逻辑顺序,聚集索引能够特别快地访问针对范围值的查询。查询优化器能够快速发现某一段范围的数据页需要扫描
辅助索引
辅助索引(Secondary Index,也称非聚集索引),叶子节点并不包含行记录的全部数据。叶子节点除了包含键值以外,每个叶子节点中的索引行中还包含了指向主键的指针。
辅助索引的存在并不影响数据在聚集索引中的组织,因此每张表上可以有多个辅助索引。当通过辅助索引来寻找数据时,InnoDB存储引擎会遍历辅助索引并通过叶级别的指针获得指向主键索引的主键,然后再通过聚集索引来找到一个完整的行记录
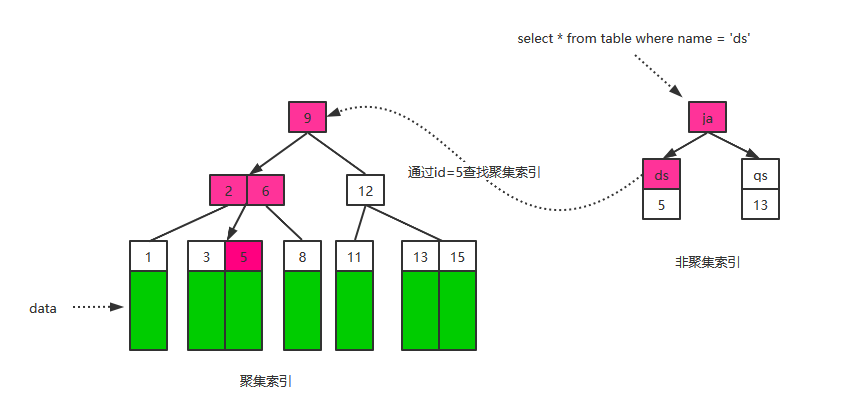
联合索引
联合索引是指对表上的多个列进行索引
从本质上来说,联合索引也是一棵B+树,不同的是联合索引的键值的数量不是1,而是大于等于2
联合索引有如下特点:
最左前缀原则
创建了(a,b,c)联合索引,如下几种情况都可以走索引:
- select * from table where a = xxx;
- select * from table where a = xxx and b = xxx;
- select * from table where a = xxx and b = xxx and c = xxx
如下几种情况不走索引
- select * from table where b = xxx;
- select * from table where c = xxx;
- select * from table where b = xxx and c = xxx;
本质上讲(a,b,c)联合索引等同于(a)单列索引、(a,b)联合索引、(a,b,c)联合索引三种索引的组合,符合最左前缀原则
覆盖索引
InnoDB存储引擎支持覆盖索引(covering index,或称索引覆盖),即从辅助索引中就可以得到查询的记录,而不需要查询聚集索引中的记录。使用覆盖索引的一个好处是辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的IO操作
- 非聚集索引上直接可以拿到所需数据,不需要再回表查,比如 select id from table where name = xxx;(id为主键、name为索引列)
- 在统计操作中也会使用覆盖索引。比如(a,b)联合索引,select * from table where b = xxx语句按最左前缀原则是不会走索引的,但如果是统计语句select count(*) from table where b = xxx;就会使用覆盖索引。
选择性
并不是在所有的查询条件中出现的列都需要添加索引。对于什么时候添加B+树索引,一般的经验是,在访问表中很少一部分时使用B+树索引才有意义。对于性别字段、地区字段、类型字段,它们可取值的范围很小,称为低选择性
按性别进行查询时,可取值的范围一般只有’M’、‘F’。因此上述SQL语句得到的结果可能是该表50%的数据(假设男女比例1∶1),这时添加B+树索引是完全没有必要的。相反,如果某个字段的取值范围很广,几乎没有重复,即属于高选择性,则此时使用B+树索引是最适合的
所以,我们在添加索引的时候,要尽量选择高选择性的字段,反之你在低选择性的字段上加了字段,查询可能也不会走索引
如果感觉对你有些帮忙,请收藏好,你的关注和点赞是对我最大的鼓励!
如果想跟我一起学习,坚信技术改变世界,请关注【Java天堂】公众号,我会定期分享自己的学习成果,第一时间推送给您

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/135995.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
