大家好,又见面了,我是你们的朋友全栈君。
写在前面
本文隶属于专栏《100个问题搞定大数据理论体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和文献引用请见100个问题搞定大数据理论体系
解答


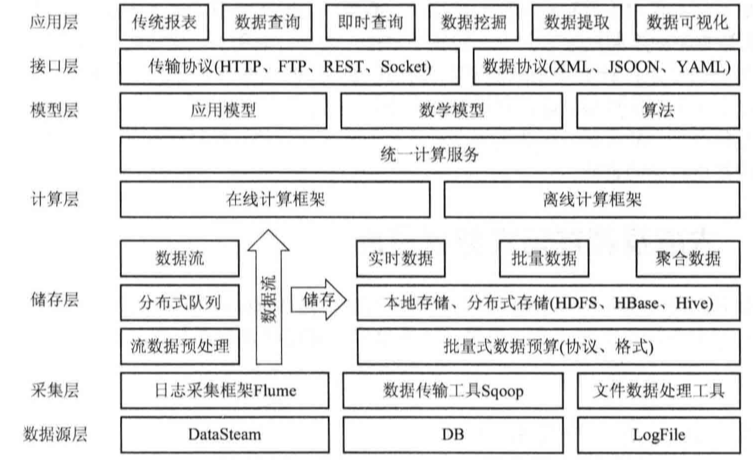
一个大数据平台架构通常如图所示,大数据开发涵盖了图中从下到上各层的实现,其中主要的部分是采集层、储存层、计算层、模型层和接口层,核心部分是储存层和计算层。
各层中功能模块的技术实现会根据实际业务场景不同而有所变化,但仍然是围绕着储存数据和数值计算这两大核心功能来进行的。
因此,大数据开发的作用主要集中在以下几个方面
1. 资源配置
大数据处理系统面向的是大体量、多来源、多类型的数据。因此,大数据开发需要综合考虑系统资源的合理设计和分配,综合考虑节点数量和角色的分配、硬盘容量和可能的扩展、后台任务和内存空间的分配以及程序设计时内存和并发量等问题。
如果这些资源问题没有处理好,会导致整个大数据集群性能和稳定性下降,极端情况下可能会导致集群部分服务异常关闭,甚至整个集群宕机。
2. 数据移动
数据移动问题包括数据从外部流入到平台、数据从平台流出到外部、数据在平台内的移动以及平台之间的数据移动。
在这个过程中,大数据开发需要充分考虑数据量大小和对数据实时性的要求,避免数据积压和数据丢失。
3.计算性能
如何保障大数据处理平台的计算性能是开发人员在大数据开发过程中需要考虑的问题。
根据不同的业务场景和数据类型,选择合适的计算方式,合理地设计数据存储机制与数据结构,可以在一定程度上保持并优化大数据计算的效率。
4.数据安全
数据安全指的是数据的可用性、完整性和保密性。在进行大数据开发时可以充分利用大数据技术框架所提供的相关数据安全机制,保障数据安全。
5.灵活性和容错性
灵活性是指大数据平台的应变能力,使其在面对不同应用需求时可以不用进行过多的改动和重构。
容错性是指在大数据平台出现部分功能故障时,仍能保证平台的主体功能不失效,或能够在主体功能受到严重影响前重启功能服务或启动替代功能服务。
大数据处理系统的基础设施规模通常比较庞大,采用的又都是廉价的商用设备,因此必须经过大数据开发工作的仔细设计,才能保证存储系统的灵活性和容错性,使其能够随应用一起扩容及扩展,并且稳定运行。
补充
什么是大数据开发?
使用程序语言和大数据技术框架,将与大数据相关的需求实现为一个系统、软件或模块的开发过程
为了进一步明确这个概念,请注意以下几种情况:
- 不使用程序开发语言的,不属于大数据开发的范畴。例如用 Excel分析数据的过程。
- 功能需求与大数据无关的,不属于大数据开发的范畴。例如用一台服务器就可以承载所有功能的需求。
- 最终产品并非是一个系统、软件或模块的,不属于大数据开发的范畴。例如最终产品是一份数据分析报告,或使用 Spark Shell命令行完成的数据处理过程。
- 需求被明确前或需求被满足后的工作,不属于大数据开发的范畴。例如大数据平台已经按照需求开发完成,数据分析师利用平台中储存的数据进行算法研发。
值得注意的是,大数据开发是一个完整的系统性工程,应该用整体观念来看待,不能把其中的某项工作单独割裂出来进行界定。
例如,操作Linux Shell或使用图形界面来部署调试集群、査看日志等工作,虽然不符合上述定义,但却是整个系统性开发工作中不可分割的一部分,因此仍然在大数据开发工作的范畴之中;
另一方面,虽然我们试图尽可能清晰地界定大数据开发与其他工作之间的边界,但这个边界仍然是模糊的,需要在实际开发工作中灵活变通,如向 Hadoop集群中提交一个实现某种数椐挖掘功能的
MapReduce任务,即使该任务与整个平台的耦合性并不强,可以被割裂出来界定为数据挖掘工作,但若被界定为数据开发工作,也并没有明显的不妥。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/135978.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
