大家好,又见面了,我是你们的朋友全栈君。
原帖地址: http://blog.csdn.net/nsrainbow/article/details/42013293 最新课程请关注原作者博客
声明
- 本文基于Centos 6.x + CDH 5.x
- 官方英文安装教程 http://www.cloudera.com/content/cloudera/en/documentation/cdh5/v5-0-0/CDH5-Installation-Guide/cdh5ig_cdh5_install.html 本文并不是简单翻译,而是再整理
- 如果没有yum源请参考http://blog.csdn.net/nsrainbow/article/details/36629339#t2
架构图
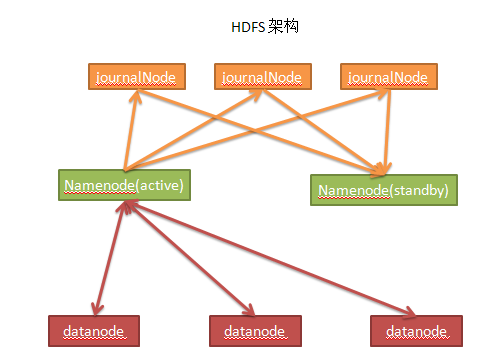

- namenode 总数就2个,不能多也不能少,一个是active状态,一个是standby状态,只有active状态的在工作,另一个只是备份,当active状态的挂了之后,standby的会切换为active状态。但是这个动作其实不是天生自动的,配合上zookeeper才能实现自动化切换。
- journalNode 用于存储active状态的namenode所做的所有改变,并同步到standby的namenode,以保证在standby转换为active之后不会漏掉操作
- namenode管理着datanode,namenode负责存储地址空间,datanode负责真正的存储数据
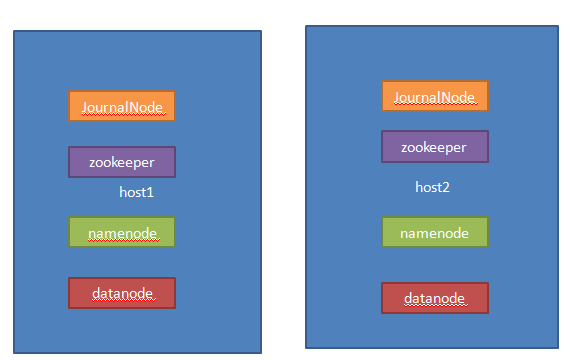
- 为了降低部署的难度,我就虚拟了两台机子,其实真正部署的时候至少要有3台(保持奇数个)
- zookeeper是负责在active的namenode挂掉之后自动把standby状态的namenode切换成active的
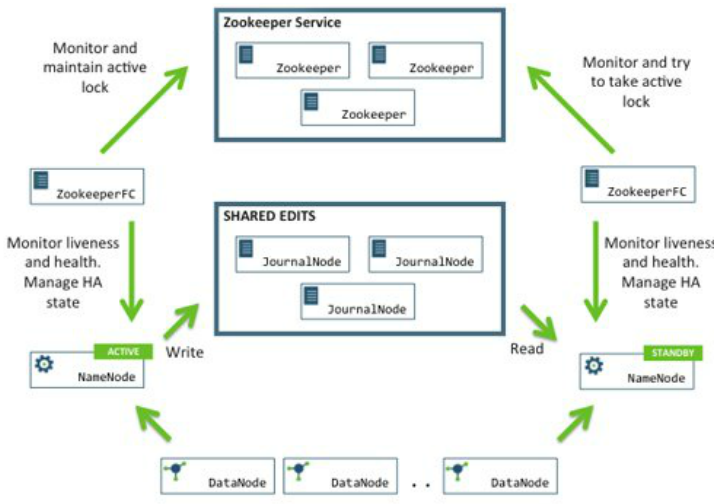
- zookeeper是游离于hadoop集群之外的组件
- hadoop利用 zkfc (zookeeperFC) 来跟 zookeeper进行协作,其实目的很简单,就是在一个namenode挂掉的时候,自动切换成另一个namenode为active状态
准备工作
- 用vmware开出两台虚拟机,安装上Centos6。 我弄了两个host,分别是 host1(192.168.199.126) 和host2(192.168.199.128)
- 开始前请按照 Alex 的 Hadoop 菜鸟教程: 第2课 hadoop 安装教程 (CentOS6 CDH分支 yum方式) 里面的方式添加yum源
安装
安装Zookeeper
yum install zookeeper -y都安装 zookeeper-server
sudo yum install zookeeper-server -y
在
host1 上启动zookeeper
$ sudo service zookeeper-server init --myid=1
$ sudo service zookeeper-server start
JMX enabled by default
Using config: /etc/zookeeper/conf/zoo.cfg
Starting zookeeper ... STARTED
注意:这个 –myid=1 标定了zookeeper的id,会在 /var/lib/zookeeper 下建立一个 myid 文件
在 host2 上启动zookeeper
$ sudo service zookeeper-server init --myid=2
$ sudo service zookeeper-server start
JMX enabled by default
Using config: /etc/zookeeper/conf/zoo.cfg
Starting zookeeper ... STARTED检查下是否在2181端口监听
$ netstat -tpnl | grep 2181
tcp 0 0 :::2181 :::* LISTEN 5477/java
用client端测试一下
zookeeper-client -server host1:2181
配置zookeeper
在两台机子上都编辑 /etc/zookeeper/conf/zoo.cfg 文件
tickTime=2000
dataDir=/var/lib/zookeeper/
clientPort=2181
initLimit=5
syncLimit=2
server.1=host1:2888:3888
server.2=host2:2888:3888
注意:其实zookeeper的服务器最小的安装数量是3台机器,但是现在只有2台,只能凑合了。因为zookeeper是根据超过半数出问题来关停系统的,所以2台就无法正确的判断了,不过我们只是做例子所以没关系。
hadoop在启动的时候会自动去找zookeeper的2181端口,如果没有就启动不起来
安装Resource Manager
host1(192.168.199.126) 安装
yum install hadoop-yarn-resourcemanager -y
安装Name Node
两台机子上都安装name node
sudo yum install hadoop-hdfs-namenode -y
安装Date Node 等
yum install hadoop-yarn-nodemanager hadoop-hdfs-datanode hadoop-mapreduce -y 官方文档说在其中一台机子上安装以下软件,随便挑一台,就挑
host2把
yum install hadoop-mapreduce-historyserver hadoop-yarn-proxyserver -y 在随便一台机器上安装client,选
host1安装吧
yum install hadoop-client -y
配置
配置网络
sudo hostname host1在host2 上
sudo hostname host2这样定义的名字只保持在下次重启之前
192.168.199.126 host1.localdomain host1192.168.199.128 host2.localdomain host2那个localdomain代表的是本地的域名,相当于localhost一样的东西
[root@localhost conf]# uname -aLinux host1 2.6.32-358.el6.x86_64 #1 SMP Fri Feb 22 00:31:26 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux配置HDFS
host1上
<property>
<name>fs.defaultFS</name>
<value>hdfs://host1.localdomain:8020</value>
</property>打开 hdfs-site.xml 添加
<property> <name>dfs.permissions.superusergroup</name> <value>hadoop</value></property>在hdfs-site.xml里面修改一下 namanode 的实际存储位置为更大的磁盘
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:///data/hdfs/1/dfs/nn</value> </property> <property> <name>dfs.permissions.superusergroup</name> <value>hadoop</value> </property></configuration>每一个datanode节点上的hdfs-site.xml里面都配置相同的文件夹来存储数据,比如我就建三个文件夹来存储datanode数据
<property> <name>dfs.datanode.data.dir</name> <value>file:///data/hdfs/1/dfs/dn,file:///data/hdfs/2/dfs/dn,file:///data/hdfs/3/dfs/dn</value> </property>所以最后hdfs-site.xml 是这样的
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hdfs/1/dfs/nn</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>hadoop</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hdfs/1/dfs/dn,file:///data/hdfs/2/dfs/dn,file:///data/hdfs/3/dfs/dn</value>
</property>
</configuration>把
- /data/hdfs/1/dfs/nn
- /data/hdfs/1/dfs/dn
- /data/hdfs/2/dfs/dn
- /data/hdfs/3/dfs/dn
chown -R hdfs.hdfs hdfs
在
host2 上
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://host2.localdomain:8020</value> </property></configuration>hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hdfs/1/dfs/nn</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>hadoop</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hdfs/1/dfs/dn,file:///data/hdfs/2/dfs/dn,file:///data/hdfs/3/dfs/dn</value>
</property>
</configuration>chown -R hdfs.hdfs hdfs格式化namenode
sudo -u hdfs hdfs namenode -format
启动HDFS
for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudo service $x start ; done
建立/tmp文件夹
$ sudo -u hdfs hadoop fs -mkdir /tmp
$ sudo -u hdfs hadoop fs -chmod -R 1777 /tmp这样会在hdfs集群上建立 /tmp 文件夹。
sudo -u hdfs hadoop fs -ls /来看下hdfs上根目录下有什么文件夹
检查是否启动成功
[root@host1 ~]# jps
12044 Jps
2207 ResourceManager
11857 NameNode
host2 上
[root@host2 ~]# jps10735 NameNode10855 Jps10644 DataNode2272 JobHistoryServer客户端测试
如果看到
Overview ‘host1.localdomain:8020’ (active)
这样的字样就成功进入了hadoop的命令控制台
设置HA
- 一个集群可以有多个namenode
- 只有一个namenode处于活跃状态,其他namenode处于备选状态
- 活跃状态的namenode跟备选状态的namenode之间有一定的时间差
- 采用journalNode来记录namenode的所有改动,在活跃namenode到备选namenode切换过程中保证不漏掉操作步骤
配置HA
两台机器都一样的,所以我就只写一份
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hdfs/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>host1:2181,host2:2181</value>
</property>
</configuration>建立对应的文件夹并分配权限
cd /data/hdfs
mkdir tmp
chown -R hdfs.hdfs tmp 参数解释:
- fs.defaultFS 用一个统一的名字来标定集群的名字
- hadoop.tmp.dir 是yarn使用的临时文件夹
- ha.zookeeper.quorum 设定所有zookeeper server的地址,理论上一定要是奇数个,但是现在条件所迫就设置成2个吧
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>host1,host2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.host1</name>
<value>host1:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.host1</name>
<value>host1:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.host2</name>
<value>host2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.host2</name>
<value>host2:50070</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://host1:8485;host2:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/yarn/tmp/journal</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/var/lib/hadoop-hdfs/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>10000</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hdfs/1/dfs/nn</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>hadoop</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hdfs/1/dfs/dn,file:///data/hdfs/2/dfs/dn</value>
</property>
</configuration>配置解释
- dfs.replication 数据的复制份数
- dfs.nameservices serviceid 接下来的配置参数中会用到,也就是一个集群的名字
- dfs.ha.namenodes.mycluster 这个mycluster就是之前定义的serviceid,这边列出所属的namenode,也就是namenode的host名字
- dfs.namenode.rpc-address.mycluster.host1 各个namenode的 rpc通讯地址
- dfs.namenode.http-address.mycluster.host1 各个namenode的http状态页面地址
- dfs.ha.automatic-failover.enabled 是否启用故障自动处理?就是故障的时候会自动启用备选的namenode,暂时设定为false
- dfs.namenode.shared.edits.dir 定义了集群的日志节点,采用统一格式 “qjournal://host1:port1;host2:port2;host3:port3/journalId” ,日志节点是由active状态的namenode写入,由standby(备选)状态节点读出
- dfs.ha.fencing.methods 处于故障状态的时候hadoop要防止脑裂问题,所以在standby机器切换到active后,hadoop还会试图通过内部网络的ssh连过去,并把namenode的相关进程给kill掉,一般是sshfence 就是ssh方式,后面的 dfs.ha.fencing.ssh.private-key-files 则配置了 ssh用的 key 的位置
建立文件夹,并分配权限
sudo mkdir -p /data/yarn/tmp/journal
sudo chown -R hdfs:hdfs /data/yarn删除之前建立的dn文件夹,重新建立新的dn文件夹
# rm -rf /data/hdfs/3
# rm -rf /data/hdfs/1/dfs/dn
# rm -rf /data/hdfs/2/dfs/dn
# mkdir /data/hdfs/1/dfs/dn
# chown -R hdfs.hdfs /data/hdfs/1/dfs/dn/
# mkdir /data/hdfs/2/dfs/dn
# chown -R hdfs.hdfs /data/hdfs/2/dfs/dn/为 dfs.ha.fencing.ssh.private-key-files 建立sshkey
step1
[root@host1 ~]# sudo su -
[root@host1 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.中间过程问的问题全部回车解决
Step2
[root@host2 .ssh]# cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
Step3
[root@host1 .ssh]# cp /root/.ssh/id_rsa /var/lib/hadoop-hdfs/.ssh/
[root@host1 .ssh]# chown hdfs.hdfs /var/lib/hadoop-hdfs/.ssh/id_rsa
Step4
[root@host2 .ssh]# sudo su hdfs
bash-4.1$ ssh root@host2
The authenticity of host 'host2' can't be established.
RSA key fingerprint is dd:91:6c:c2:df:65:20:68:e7:e4:fc:5b:a8:4f:c6:8c.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'host2' (RSA) to the list of known hosts.
Last login: Tue Dec 30 20:34:00 2014 from 10.172.252.22
[root@host2 ~]# ll
Step5
修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>修改yarn-site.xml ,在 <configuration/> 节点里面插入一个属性
<property> <name>yarn.resourcemanager.hostname</name> <value>host1</value> </property>修改文件slave
host1
host2把 core-site.xml , hdfs-site.xml, mapred-site.xml, yarn-site.xml, slaves 复制到host2上
for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudo service $x stop; done
for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudo service $x start ; done
部署HA
安装并启动JournalNodes
两台机器上都执行
yum install hadoop-hdfs-journalnode -y在两台机器上都启动服务
service hadoop-hdfs-journalnode start
格式化
sudo -u hdfs hdfs namenode -format -clusterId myclusterservice hadoop-hdfs-namenode stophost1上初始化journalnode
hdfs namenode -initializeSharedEdits启动namenode
再启动
第一个namenode就是你要作为主要的namenode的那个,这里我把host1作为主要的
service hadoop-hdfs-namenode start接下来启动备用namenode,这里我把host2作为备用的namenode
sudo -u hdfs hdfs namenode -bootstrapStandby可能会问你是否要格式化,记得选Y
service hadoop-hdfs-namenode start我解释一下,当你用 -bootstrapStandby 启动备选的namenode的时候,它会将内容从主namenode上复制过来(包括命名空间信息和最近修改信息)存储的位置就是你在 dfs.namenode.name.dir 和 dfs.namenode.edits.dir里面配置的,在本教程中就是 file:///data/hdfs/1/dfs/nn
启动 datanode
- 最先启动的是所有机器上的 journalnode
- 再启动主机上的namenode
- 启动备选机上的namenode(还需要用 -bootstrapStandby 拉取镜像)
- 启动所有机器上的datanode
设置host1为active状态
hdfs haadmin -failover host2 host1
设置自动failover
yum install hadoop-hdfs-zkfc -y <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
格式化zookeeper
hdfs zkfc -formatZK这一步会在zookeeper根目录下建立 /hadoop-ha/mycluster 这个目录。
# zookeeper-client -server host1:2181[zk: host1:2181(CONNECTED) 0] ls /[hadoop-ha, zookeeper]在两台机器上都启动 zkfc
service hadoop-hdfs-zkfc start官方说明了几点:
- zkfc跟zookeeper关系密切,要是zookeeper挂了,zkfc也就失效了
- 最好监控着zkfc进程,防止zkfc退出了,造成无法自动切换
- zkfc跟namenode的启动顺序是无所谓的
验证namenode状态
参考资料
- http://blog.csdn.net/yczws1/article/details/23566383 这篇教程建议大家也去看下,可以对大于2台机器的安装有些概念上的认识
- http://pan.baidu.com/share/link?shareid=3918641874&uk=2248644272 这篇文章写的相当不错,对概念的解释很到位
- http://www.sizeofvoid.net/hadoop-2-0-namenode-ha-federation-practice-zh/ 对更进一步的 HDFS联盟感兴趣的可以看下这篇文章
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/135740.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
