大家好,又见面了,我是你们的朋友全栈君。
一、需求分析
现在许多实际问题抽象出来的数据结构往往都是二叉树的形式。哈夫曼编码可以对日常数据量很大的数据,进行数据压缩技术来实现存储和传输。
所以在本程序中,需要构造一棵二叉树来存储一大串字符串,对给构造出来的树进行编码,再由已经编好的哈夫曼编码对给定的字符串进行编码,之后对编码的字符串进行解码,最后比较编/解码前后字符串是否相同。
二、设计方案
1、流程
第一,统计频率。计算给定字符串字符出现的频率;结果用map来存储,其中key=字符,value=出现次数。
第二,构造二叉树。把字符出现的频率当作树的权重,构造一棵二叉树。
第三,编造哈夫曼编码。根据二叉树,对每个叶节点进行编码;结果用map来储,其中key=叶节点,value=编码。
第四,编码。根据哈夫曼编码,对给定字符进行编码,返回结果字符串。
第五,解码。对字符串的编码进行解码,返回结果字符串;比较前后数据。
2、方法列表
|
定义节点类 |
HTNode.java |
|
统计字符串频率 |
public static Map<Character,Integer> computeCharCount(String text) |
|
构造二叉树 |
public static HTNode buildTree(List<HTNode> nodes) |
|
编造哈夫曼编码 |
public static Map<Character, String> getCode(HTNode tree) |
|
编码 |
public static String encode(String text, Map<Character, String> code) |
|
解码 |
public static String decode(String text, Map<Character, String> code) |
三、关键算法实现
1、定义节点类(HTNode)
(1)设置节点属性。定义成员变量,存放节点的数据、编码、权重、左孩子、右孩子、是否为叶子节点。
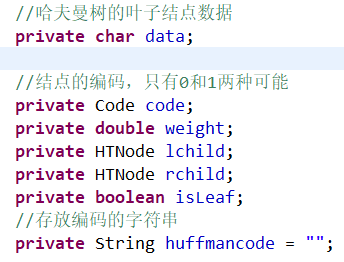

(2)编写成员变量的get、set方法。因为成员变量为私有属性,在其他类里不能直接操作,要通过调用get、set操作。
2、统计字符串中字符出现的次数
(1)把字符串作为实参,传入函数
(2)new一个map对象。map.key=字符,map.value=出现次数
(3)遍历字符串,通过map.containsKey(key)方法,判定字符在map中是否存在。如果存在,让其value+1;否则,将字符和其个数(1)存放到map中。

3、构造二叉树
(1)对节点的属性进行初始化设置,将每个节点存入链表nodes中。把nodes作为实参,传入函数。
(2)根据节点的权重从小到大排序。
(3)每一次取权重最小的节点,定义一个parent节点,将这两个节点作为parent的左右孩子,设置parent不为叶节点,从链表中移除两个节点,将parent节点放入链表。
(4)最后,链表里只剩根节点结束循环,返回根节点。
4、计算哈夫曼编码
(1)将返回的根节点作为实参传入函数。
(2)创建队列,将根节点存放在队列中;创建map,key=叶节点,value=编码。
(3)遍历队列,队列不为空时,使用poll()方法获取并移除队列的头。
(4)判定该节点是否为叶子节点。如果是将叶节点的数据和编码存入map;否则,判断是否有左右孩子,左孩子编码+0,右孩子编码+1。将左右孩子节点放入队列。
(5)直至所以叶节点都被找出,循环结束,反面结果集map对象。
5、对给定字符进行编码
(1)将上一步返回的map对象(对照表:存放叶节点及其编码)和给定的字符串作为实参传入函数。
(2)遍历字符串。将字符串中的每一个字符,作为map的key,通过map.get(key)获取到对应的value,将每一个value值存入字符串str中,返回str。

6、对编码好的字符串,进行解码
(1)将字符串的编码和map对象(对照表:存放叶节点及其编码)作为实参传入函数。
(2)创建队列,将字符串每个字符存入队列。
(3)定义一个临时字符串tmp、结果字符串result。
(4)遍历队列,通过peek获取队列的头,将其中追加到临时变量tmp中。遍历对照表map,获取map中的key和value。
(5)判断tmp是否与对照表中的值相同。如果相同,将对照表中的key存入结果字符串result中,清空tmp,移除队列的头;如果不同,接着往tmp中缀加队列中的元素,和value进行比较,直到有相同时。
四、测试数据
1、统计字符出现频率
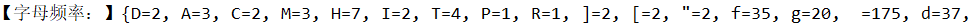
2、构造二叉树
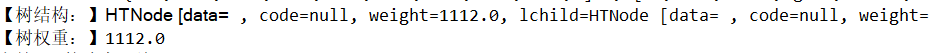
3、每个字符对应的哈夫曼编码

4、对给定字符串进行编码

5、对编码的字符串进行解码

五、遇到的问题与解决方法
问题:按照节点的权重从小到大排序。nodes.sort(bull)报错。
原因:jdk1.6支持nodes.sort(null)这条语句,可以进行排序;但我的电脑装的是jdk1.7,所以要使用Collections包装类,调用其中的sort()方法才可以进行排序。

收获:为了解决这个,我上网搜了很多java关于排序的方法,明白了使用这个排序的原理。要想实现按权重排序的功能,首先需要实现Comparable接口;其次要重写compareTo方法,在这个方法里面设置排序规则。


源程序:
package 哈夫曼树;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import java.util.Queue;
/**
* 哈夫曼树实现
*
*/
public class HuffmanTree {
public static void main(String[] args){
String data = "In computer science and information theory, "
+ "a Huffman code is a particular type of optimal prefix code that is commonly used for lossless data compression. "
+ "The process of finding and/or using such a code proceeds by means of Huffman coding, "
+ "an algorithm developed by David A. Huffman while he was a Ph.D. student at MIT, and published in the 1952 paper "
+ "\"A Method for the Construction of Minimum-Redundancy Codes\".[1] "
+ "The output from Huffman's algorithm can be viewed as a variable-length code table for encoding a source symbol "
+ "(such as a character in a file). The algorithm derives this table from the estimated probability or frequency of occurrence"
+ " (weight) for each possible value of the source symbol. As in other entropy encoding methods, more common symbols are generally "
+ "represented using fewer bits than less common symbols. Huffman's method can be efficiently implemented, "
+ "finding a code in linear time to the number of input weights if these weights are sorted.[2] However, "
+ "although optimal among methods encoding symbols separately, Huffman coding is not always optimal among all compression methods.";
//首先对字符串中的字符出现次数进行统计
Map<Character, Integer> chars = computeCharCount(data);
System.out.println("【字母频率:】"+chars);
ArrayList<HTNode> nodes = new ArrayList<>();
//把每个节点存入链表nodes
for(Character c : chars.keySet()){
HTNode node = new HTNode();
node.setData(c);
node.setWeight(chars.get(c));
node.setLchild(null);
node.setRchild(null);
node.setLeaf(true);
nodes.add(node);
}
//建造二叉树,tree为返回的根节点
HTNode tree = buildTree(nodes);
System.out.println("【树结构:】"+tree.toString());
System.out.println("【树权重:】"+tree.getWeight());
//对节点进行编码
Map<Character, String> map_code = getCode(tree);
for(Character c : map_code.keySet()){
System.out.println("字符'"+c+"'的哈夫曼编码:"+map_code.get(c));
}
String text = "In computer science and information theory";
//根据已编好码的字符,对上面字符串进行编码(a--->0111)
String coded = encode(text,map_code);
System.out.println("字符串:"+text);
System.out.println("被编码为:"+coded);
//根据编码,进行解码(0111-->a)
String oriText = decode(coded,map_code);
System.out.println("编码:"+coded);
System.out.println("被解码为:"+oriText);
System.out.println("比较结果:"+oriText.equals(text));
}
/**
* 根据初始的结点列表,建立哈夫曼树,
* 并生成哈夫曼编码,保存在当前类的code对象中,
* 生成的树根结点,被保存在当前类的tree对象中。
* 可以反复生成哈夫曼树,每次重新构建树,将更新编码
* @param nodes
* @return
*/
public static HTNode buildTree(List<HTNode> nodes) {
while (nodes.size() > 1) {
Collections.sort(nodes);
// nodes.sort(null);
HTNode first = nodes.get(0);
HTNode second = nodes.get(1);
HTNode parent = new HTNode();
parent.setLchild(first);
parent.setRchild(second);
parent.setWeight(first.getWeight() + second.getWeight());
parent.setLeaf(false);//设置不为叶节点
nodes.remove(0);
nodes.remove(0);// 需要删除两次
nodes.add(parent);
}
return nodes.get(0);
}
/**
* 根据已建立的哈夫曼树根结点,生成对应的字符编码,
* 字符编码应为0,1字符串
* @param tree
* @return
*/
public static Map<Character, String> getCode(HTNode tree) {// 获取字符编码
// TODO
Map<Character, String> code = new HashMap<Character, String>();
Queue que = new LinkedList();// 创建队列链表
que.add(tree);
while (!que.isEmpty()) {//当队列不为空
HTNode front = (HTNode) que.poll();// 获取并移除此队列的头
String front_huffman = front.getHuffmancode();// 获取对应哈夫曼节点的编码
if (front.isLeaf()) {
code.put(front.getData(), front_huffman);// 如果是叶节点则直接放入数据和编码
} else {
if (front.getLchild() != null) {
front.getLchild().setHuffmancode(front_huffman + "0");
}
if (front.getRchild() != null) {
front.getRchild().setHuffmancode(front_huffman + "1");
}
que.add(front.getLchild());
que.add(front.getRchild());
}
}
return code;
}
/**
* 统计字符串中字符出现的频率
* @param text
* @return
*/
public static Map<Character, Integer> computeCharCount(String text) {
// TODO
Map<Character, Integer> map = new HashMap<Character, Integer>();
// 把字符串传入数组
char[] chararray = text.toCharArray();
for (int i = 0; i < chararray.length; i++) {
if (map.containsKey(chararray[i])) {
int value = map.get(chararray[i]);
map.put(chararray[i], value + 1);
} else {
map.put(chararray[i], 1);
}
}
return map;
}
/**
* 使用指定的huffman编码来对文本进行编码
* @return
*/
public static String encode(String text, Map<Character, String> code) {
char[] chararray = text.toCharArray();
String str = "";
for (int i = 0; i < chararray.length; i++) {
str += code.get(chararray[i]);
}
return str;
}
/**
* 使用预先建立好的huffman树,
* 对编码后的文本进行解码
* @param text
* @return
*/
public static String decode(String text, Map<Character, String> code) {
Queue que = new LinkedList();
char[] chararray = text.toCharArray();
for (int i = 0; i < chararray.length; i++) {
que.add(chararray[i]);
}
String tmp = "";
String result = "";
//当队列不为空时
while (!que.isEmpty()) {
String tou = "" + que.peek();
tmp += tou;
for(Character key : code.keySet()){
String value = code.get(key);
if (tmp.equals(value)) {
result += key;
tmp = "";
}
}
que.poll();
}
return result;
}
}
package 哈夫曼树;
public class HTNode implements Comparable<HTNode>{
public enum Code{
ZERO('0'), ONE('1');
private char code;
private Code(char c){
this.code = c;
}
public char getCode(){
return code;
}
}
//哈夫曼树的叶子结点数据
private char data;
//结点的编码,只有0和1两种可能
private Code code;
private double weight;
private HTNode lchild;
private HTNode rchild;
private boolean isLeaf;
//存放编码的字符串
private String huffmancode = "";
public String getHuffmancode() {
return huffmancode;
}
public void setHuffmancode(String huffmancode) {
this.huffmancode = huffmancode;
}
public char getData() {
return data;
}
public void setData(char data) {
this.data = data;
}
public double getWeight() {
return weight;
}
public void setWeight(double weight) {
this.weight = weight;
}
public HTNode getLchild() {
return lchild;
}
public void setLchild(HTNode lchild) {
this.lchild = lchild;
}
public HTNode getRchild() {
return rchild;
}
public void setRchild(HTNode rchild) {
this.rchild = rchild;
}
public boolean isLeaf() {
return isLeaf;
}
public void setLeaf(boolean isLeaf) {
this.isLeaf = isLeaf;
}
public Code getCode() {
return code;
}
public void setCode(Code code) {
this.code = code;
}
@Override
public int compareTo(HTNode o) {
if(this.weight<o.weight){
return -1;
}else{
return 1;
}
}
@Override
public String toString() {
return "HTNode [data=" + data + ", code=" + code + ", weight=" + weight
+ ", lchild=" + lchild + ", rchild=" + rchild + ", isLeaf="
+ isLeaf + ", huffmancode=" + huffmancode + "]";
}
}发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/135702.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
