大家好,又见面了,我是你们的朋友全栈君。
ArrayList简介:
ArrayList实现了List接口它是一个可调整大小的数组可以用来存放各种形式的数据。并提供了包括CRUD在内的多种方法可以对数据进行操作但是它不是线程安全的,外ArrayList按照插入的顺序来存放数据。
ArrayList的主要成员变量:
private static final int DEFAULT_CAPACITY = 10;//数组默认初始容量
private static final Object[] EMPTY_ELEMENTDATA = {};//定义一个空的数组实例以供其他需要用到空数组的地方调用
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};//定义一个空数组,跟前面的区别就是这个空数组是用来判断ArrayList第一添加数据的时候要扩容多少。默认的构造器情况下返回这个空数组
transient Object[] elementData;//数据存的地方它的容量就是这个数组的长度,同时只要是使用默认构造器(DEFAULTCAPACITY_EMPTY_ELEMENTDATA )第一次添加数据的时候容量扩容为DEFAULT_CAPACITY = 10
private int size;//当前数组的长度ArrayList的构造方法有三种:

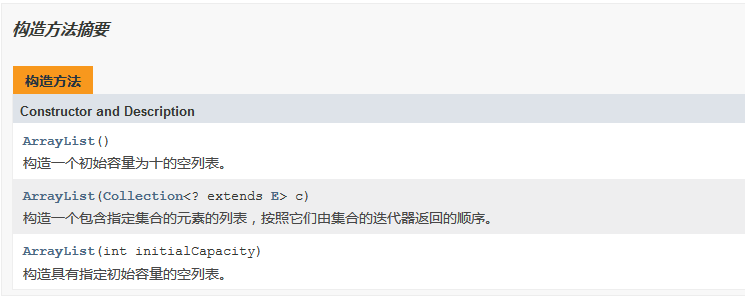
第一个构造方法用来返回一个初始容量为10的数组(具体过程后面会提到),第二个用来生成一个带数据的ArrayList这边不再赘述,第三个构造方法就是自定义初始容量。下面我将根据默认的构造方法来展开下文。
可以看到默认的构造器就是用了参数DEFAULTCAPACITY_EMPTY_ELEMENTDATA返回了一个空的数组,所以这边我们可以了解到ArrayList在创建的时候如果没有指定初始容量的话就会返回一个长度为0的空数组。下面我想从ArrayList的扩容机制开始解析,因为在所有添加数据的操作上面都要需要判断当前数组容量是否足以容纳新的数据,如果不够的话就需要进行扩容。
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
} 扩容机制:
ArrayList扩容的核心从ensureCapacityInternal方法说起。可以看到前面介绍成员变量的提到的ArrayList有两个默认的空数组:
DEFAULTCAPACITY_EMPTY_ELEMENTDATA:是用来使用默认构造方法时候返回的空数组。如果第一次添加数据的话那么数组扩容长度为DEFAULT_CAPACITY=10。
EMPTY_ELEMENTDATA:出现在需要用到空数组的地方,其中一处就是使用自定义初始容量构造方法时候如果你指定初始容量为0的时候就会返回。
从下面可以看到如果是使用了空数组EMPTY_ELEMENTDATA话,那么不会返回默认的初始容量。
//判断当前数组是否是默认构造方法生成的空数组,如果是的话minCapacity=10反之则根据原来的值传入下一个方法去完成下一步的扩容判断
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
//minCapacitt表示修改后的数组容量,minCapacity = size + 1
private void ensureCapacityInternal(int minCapacity) {
//判断看看是否需要扩容
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
下面谈谈ensureExplicitCapacity方法(modCount设计到Java的快速报错机制后面会谈到),可以看到如果修改后的数组容量大于当前的数组长度那么就需要调用grow进行扩容,反之则不需要。
//判断当前ArrayList是否需要进行扩容
private void ensureExplicitCapacity(int minCapacity) {
//快速报错机制
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
最后看下ArrayList扩容的核心方法grow(),下面将针对三种情况对该方法进行解析:
- 当前数组是由默认构造方法生成的空数组并且第一次添加数据。此时minCapacity等于默认的容量(10)那么根据下面逻辑可以看到最后数组的容量会从0扩容成10。而后的数组扩容才是按照当前容量的1.5倍进行扩容;
- 当前数组是由自定义初始容量构造方法创建并且指定初始容量为0。此时minCapacity等于1那么根据下面逻辑可以看到最后数组的容量会从0变成1。这边可以看到一个严重的问题,一旦我们执行了初始容量为0,那么根据下面的算法前四次扩容每次都 +1,在第5次添加数据进行扩容的时候才是按照当前容量的1.5倍进行扩容。
- 当扩容量(newCapacity)大于ArrayList数组定义的最大值后会调用hugeCapacity来进行判断。如果minCapacity已经大于Integer的最大值(溢出为负数)那么抛出OutOfMemoryError(内存溢出)否则的话根据与MAX_ARRAY_SIZE的比较情况确定是返回Integer最大值还是MAX_ARRAY_SIZE。这边也可以看到ArrayList允许的最大容量就是Integer的最大值(-2的31次方~2的31次方减1)。
//ArrayList扩容的核心方法,此方法用来决定扩容量
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
Java容器的快速报错机制ConcurrentModificationException:
Java容器有一种保护机制,能够防止多个进程同时修改同一个容器的内容。如果你在迭代遍历某个容器的过程中,另一个进程介入其中,并且插入,删除或修改此容器的某个对象,就会立刻抛出ConcurrentModificationException。
前文提到的迭代遍历指的就是使用迭代器Iterator(ListIterator)或者forEach语法,实际上一个类要使用forEach就必须实现Iterable接口并且重写它的Iterator方法所以forEach本质上还是使用Iterator。
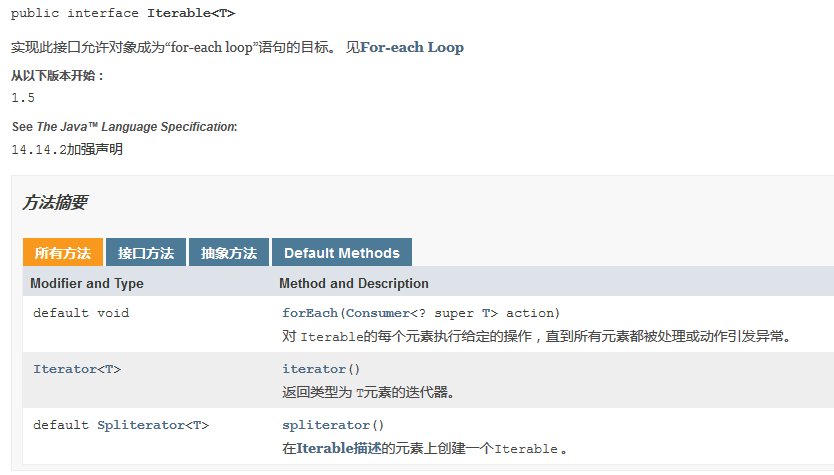
从下面方法可以看到在迭代遍历的过程中都调用了方法checkForComodification来判断当前ArrayList是否是同步的。现在来举一个栗子,假设你往一个Integer类型的ArrayList插入了10条数据,那么每操作一次modCount(继承自父类AbstractList)就加一所以就变成10,而当你对这个集合进行遍历的时候就把modCount传到expectedModCount这个变量里,然后ArrayList在checkForComodification中通过判断两个变量是否相等来确认当前集合是否是同步的,如果不同步就抛出ConcurrentModificationException。所谓的不同步指的就是,如果你在遍历的过程中对ArrayList集合本身进行add,remove等操作时候就会发生。当然如果你用的是Iterator那么使用它的remove是允许的因为此时你直接操作的不是ArrayList集合而是它的Iterator对象。在代码后面将贴出前面提到的三种情况。此外在多线程也会存在这种情况,但是如果你在多线程中使用CopyOnWriteArrayList就可以避免了。
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
int cursor; // 下一个要返回的索引
int lastRet = -1; // 返回最后一个元素的索引
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
//防止篇幅过长省去了其中代码
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
@Override
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> consumer) {
//防止篇幅过长省去其中代码
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
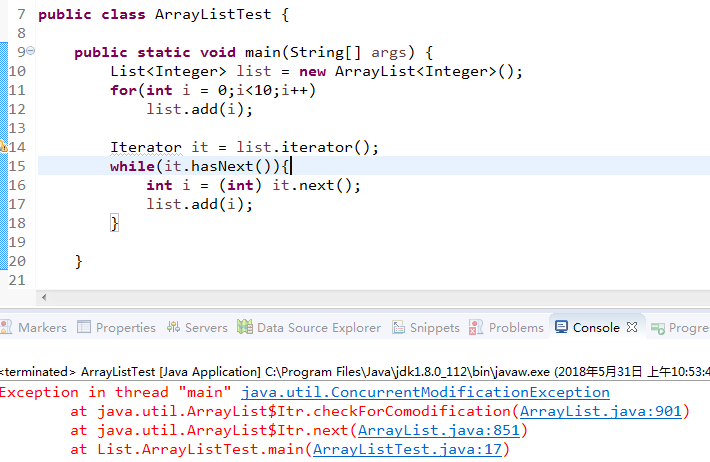
第一种情况使用Iterator:
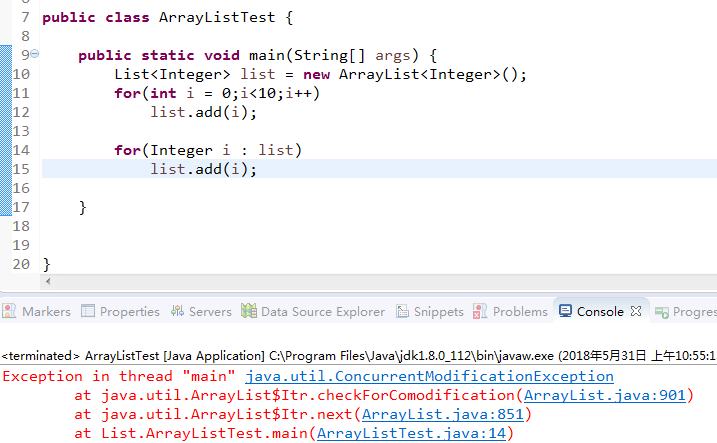
第二种情况使用forEach:
第三种情况使用Iterator自身删除数据:
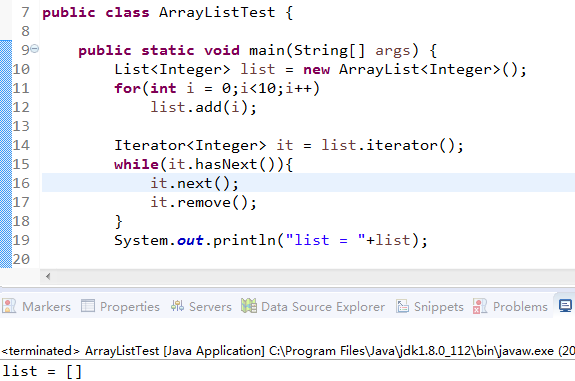
ArrayList的主要方法:
添加数据

1.add(E e)
从add(E e)方法可以看到每次添加数据ArrayList都会先调用ensureCapacityInternal来判断是否需要扩容,接着再插入数据并且每次末尾插入,所以ArrayList是按插入的顺序排序。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}2.add(int index,E element)
add(int index,E element)与前面的add只多了一个参数index,index表示你要插入的位置。此时会先判断是否会出现数组越界,然后再调用ensureCapacityInternal方法紧接着可以看到调用了System.arraycopy方法来进行操作因为该方法为本地方法(native)所以并不是用Java来实现的。根据这个方法的参数解释我们可以了解到ArrayList每次指定位置添加数据的时候都会进行数组的复制,复制的过程为把相对于当前插入位置(index)后面的数据都向后移动一位(如下图所示)。因此我们说ArrayList在对数据的插入上效率比较差,随着数据量的增大花费的时间越多。这也是我们常说的ArrayList在随机插入数据的效率上比不上LinkedList。
//index表示element要插入的位置
public void add(int index, E element) {
//判断插入的位置是否当前数组长度或是小于0,是的话会抛出IndexOutOfBoundsException
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//每一次插入数据都要把相对于当前index后面的数据向后移动一位
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
/*src - 源数组
srcPos - 源数组中的起始位置
dest - 目标数组
destPos - 目的地数据中的起始位置
length - 要复制的数组元素的数量*/
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos, int length);
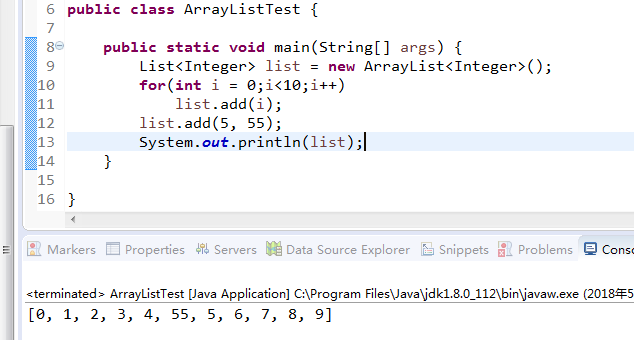
3.addAll(Collection<? extends E> c)
下面看看addAll的两个方法。首先可以看到接受的参数对象为一个集合类型。如果你试图把跟当前类型不同的集合添加进来的话有两种情况会发生:
第一种:如果你用了泛型,那么你在试图把Integer的类型的集合addAll到String类型的集合中就会在编译器抛出错误信息。
第二种:如果你不使用泛型(Object),那么你可以在一个String类型的集合中,放入Integer,类对象等等。但是当你遍历ArrayList集合要取出当中的数据进行操作的时候,除非你每次强制转换都正确,不然就会抛出ClassCastException。所以这也是使用泛型的一个好处之一吧。
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}4.addAll(int index, Collection<? extends E> c)
接下来可以看到addAll方法也提供了一个随机插入的方法。这跟前文提到的add大相径庭这边就不再赘述
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
int numMoved = size - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}删除数据
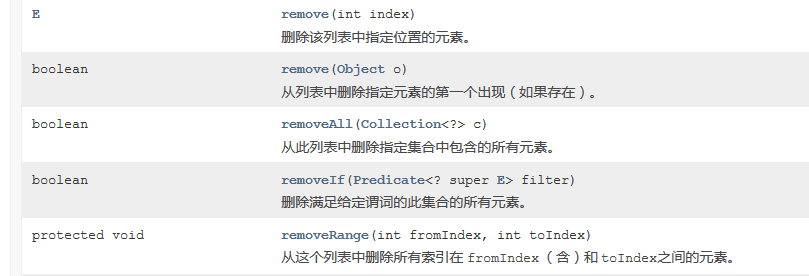
可以看到jdk1.8新增了一个方法removeIf (实现Collection接口),下面将按照顺序来依次解析。
1.remobe(int index)
很明显remove在删除的时候也用了System的本地方法arraycopy,跟前文add不同的是它把相对于插入位置的后几位数据全部向前移动一位并且,此外该方法会返回被删掉的数据。
public E remove(int index) {
rangeCheck(index);//防止数组越界
modCount++;//用于快速报错机制
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work 消除过期对象的引用
return oldValue;
}2.remove(Object o)
接着看看ArrayLsit对Object对象的remove,从方法中可以看到ArrayList在对Object对象删除操作上区分开了Null,重点要注意的是在对非空对象进行删除的时候ArrayList是调用了equals来匹配数组中的数据。也就是说如果你的集合(不局限于ArrayList)是对类进行操作,而你的类没有重写hashCode以及equals,那么你通过该方法来删除数据都是无法成功的,总之如果你要在集合中对类对象进行操作就需要重写上述的两个方法。此外就算你ArrayList中存有多个相同的Obejct对象,执行该方法也只会删除一次。或许有人会有疑问,既然使用equals那直接重写equals不就好了何必跟着重写hashCode呢?答案是如果你只重写equals是可以完成删除操作,但是你重写equals没有重写hashCode那么你在使用散列数据结构HashMap,HashSet对该类进行操作的话会出错(jdk1.8 HashMap工作原理(Get,Put)和扩容机制)。而在Object规范中提到的第二点要求就是如果两个对象经过equals比较后相同,那么他们的hashCode一定相同。所以这就是为什么要hashCode跟euqals两者同时重写。
//对传进来的对象进行区分处理
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;//只删除一次就返回
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work 消除过期对象的引用
}从测试用例可以看到,如果我们的对象没有重写hashCode以及equals的话,那么是没有办法完成操作的。因为每一次创建的对象他们的首地址都是不同的,那么在remove的时候ArrayList就会匹配不到。
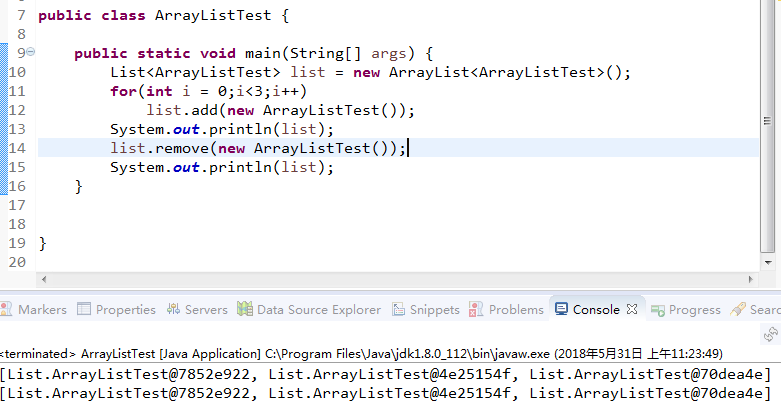
如果当我们对类进行hashCode以及equals重写之后可以看到,以及可以正常删除数据。这边可涉及到hashCode以及equals的重写规范在此处不再赘述。

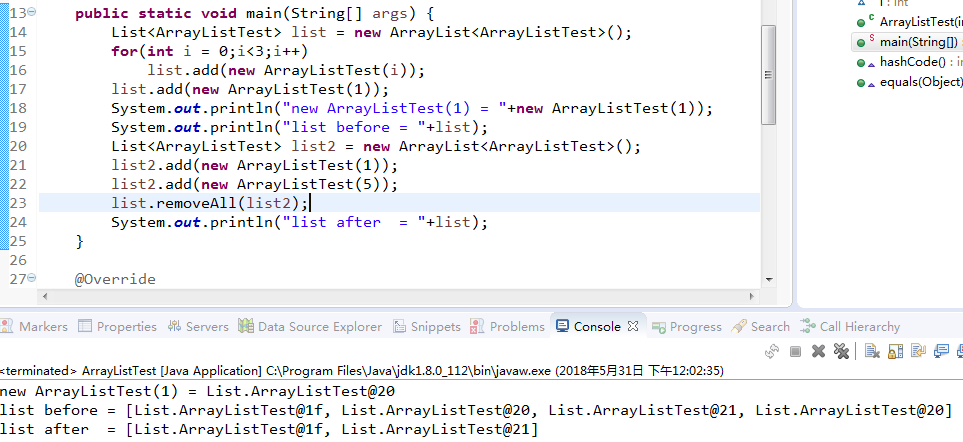
3.removeAll(Collection<?> c)
可以看到removeAll是针对集合进行删除,首先会对集合参数进行NPE判断接着可以看到ArrayList通过contains方法来对两个集合数据进行循环比较。contains实际上就是调用indexOf方法而indexOf方法又是调用的equals。紧接着拿到匹配的数据进行删除,值得一提的是这个方法可以删掉所有匹配的数据,源码后面是测试用例。
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);//判空,是的话抛出空指针异常
return batchRemove(c, false);
}
private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
int r = 0, w = 0;
boolean modified = false;
try {
for (; r < size; r++)
if (c.contains(elementData[r]) == complement)
elementData[w++] = elementData[r];//拿到所有c容器中跟当前ArrayList匹配的数据
} finally {
// Preserve behavioral compatibility with AbstractCollection,
// even if c.contains() throws.
if (r != size) {//删除
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
if (w != size) {
// clear to let GC do its work
//缩减篇幅删去代码
}
}
return modified;
}
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
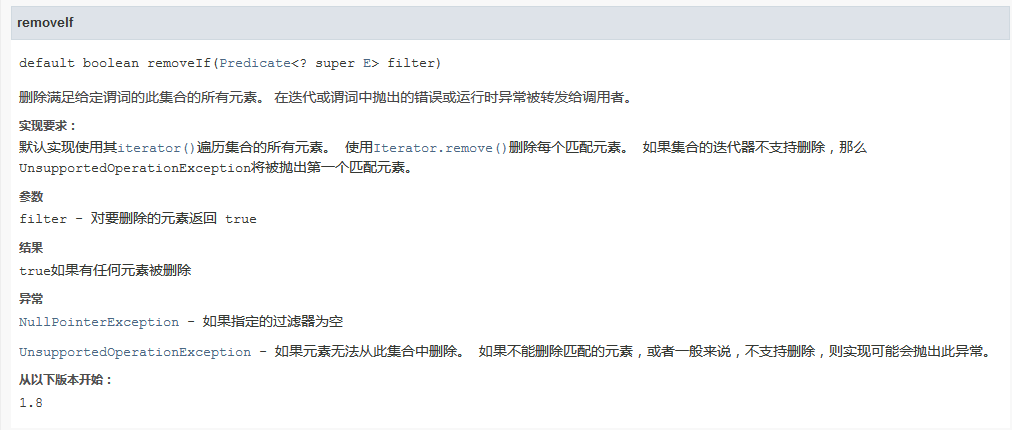
4.removeIf(Predicate<? super E> filter)
接着看看jdk1.8中新增的方法,支持使用Lambda表达式。下面来解析一下,首先可以看到用到了BitSet,它的底层数据结构就是一个long[]数组,而long是64位的可以用来存储大的内容。所以这个方法应该也是针对需要对大量对象操作才使用的吧,不然就有点浪费空间了。源码下面是实例可以看到通过lambda表达式可以很容易的完成过滤。针对代码中调用nextClearBit这个方法就是用来返回下标索引,当中用到了一堆的移位操作符,这边就不再赘述。
public boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
// figure out which elements are to be removed
// any exception thrown from the filter predicate at this stage
// will leave the collection unmodified
int removeCount = 0;
final BitSet removeSet = new BitSet(size);
final int expectedModCount = modCount;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
@SuppressWarnings("unchecked")
final E element = (E) elementData[i];
if (filter.test(element)) {
removeSet.set(i);//匹配出所有要删除的数据下标并放入BitSet中
removeCount++;
}
}
if (modCount != expectedModCount) {//快速报错机制
throw new ConcurrentModificationException();
}
// shift surviving elements left over the spaces left by removed elements
final boolean anyToRemove = removeCount > 0;
if (anyToRemove) {
final int newSize = size - removeCount;
for (int i=0, j=0; (i < size) && (j < newSize); i++, j++) {
i = removeSet.nextClearBit(i);
elementData[j] = elementData[i];//覆盖
}
for (int k=newSize; k < size; k++) {
elementData[k] = null; // Let gc do its work
}
this.size = newSize;
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
return anyToRemove;
}

5.removeRange(int fromIndex, int toIndex)
最后一种removeRange因为是protected类型的所以其他包中没有继承它的类无法直接调用,这边就不演示了。
更新数据
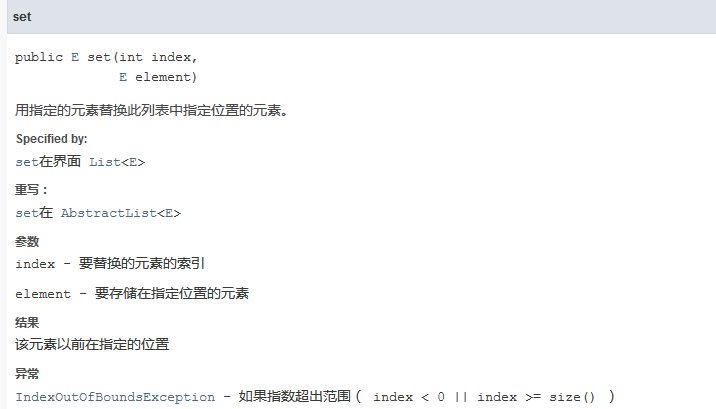
ArrayList就提供了set这个方法来更新数组中的数据,具体过程如此简单,不再赘述。
public E set(int index, E element) {
rangeCheck(index);//检查IndexOutOfBoundsException
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}获取数据
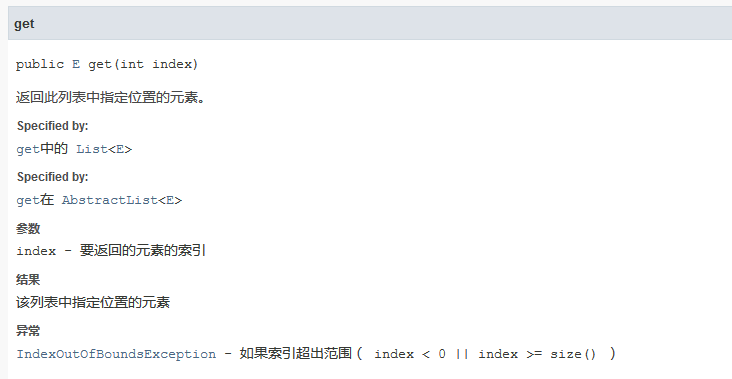
跟更新数据一样,ArrayList也只提供了get方法来进行数据获取。没有什么好说的,自己看。
public E get(int index) {
rangeCheck(index);//检查IndexOutOfBoundsException
return elementData(index);
}
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/135451.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
