大家好,又见面了,我是你们的朋友全栈君。
概述
数据分析即从数据、信息到知识的过程,数据分析需要数学理论、行业经验以及计算机工具三者结合
数据分析工具 :各种厂商开发了数据分析的工具、模块,将分析模型封装,使不了解技术的人也能够快捷的实现数学建模,快速响应分析需求
传统分析 :在数据量较少时,传统的数据分析已能够发现数据中包含的知识,包括结构分析、杜邦分析等模型,方法成熟,应用广泛。
数据挖掘 :就是充分利用了统计学和人工智能技术的应用程序,并把这些高深复杂的技术封装起来,使人们不用自己掌握这些技术也能完成同样的功能,并且更专注于自己所要解决的问题。
随着计算机科学的进步,数据挖掘、商务智能、大数据等概念的出现,数据分析的手段和方法更加丰富。
常规分析:揭示数据之间的静态关系;分析过程滞后 ;对数据质量要求高;
数据挖掘:统计学和计算机技术等多学科的结合 揭示数据之间隐藏的关系 将数据分析的范围从“已知”扩展到“未知”,从“过去”推向“将来”;
商务智能:一系列以事实为支持,辅助商业决策的技术和方法,曾用名包括专家系统、智能决策等 一般由数据仓库、联机分析处理、数据挖掘、数据备份和恢复等部分组成 对数据分析的体系化管理,数据分析的主体依然是数据挖掘;
大数据技术:从多种类型的数据中,快速获取知识的能力 数据挖掘技术的衍生
数据可视化:大数据时代,展示数据可以更好辅助理解数据、演绎数据
数据分析框架
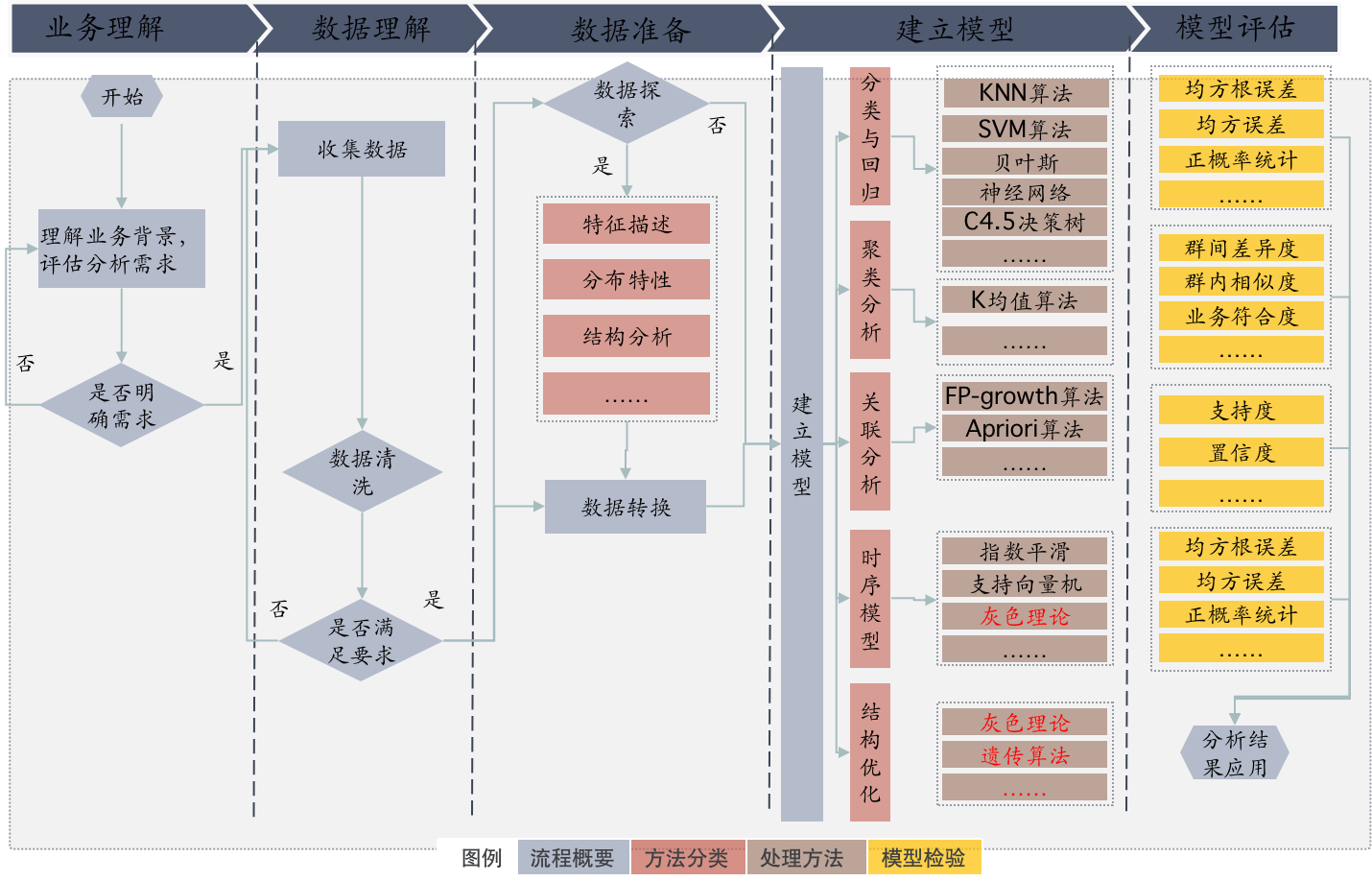
数据分析标准流程
CRISP-DM为90年代由SIG组织(当时)提出,已被业界广泛认可的数据分析流程。
1.业务理解(business understanding)
确定目标、明确分析需求
2.数据理解(data understanding)
收集原始数据、描述数据、探索数据、检验数据质量
3.数据准备(data preparation)
选择数据、清洗数据、构造数据、整合数据、格式化数据
4.建立模型(modeling)
选择建模技术、参数调优、生成测试计划、构建模型
5.评估模型(evaluation)
对模型进行较为全面的评价,评价结果、重审过程
6.部署(deployment)
分析结果应用


数据分析方法
数据清洗&数据探索
在对收集的数据进行分析前,要明确数据类型、规模,对数据有初步理解,同时要对数据中的“噪声”进行处理,以支持后续数据建模。
数据探索: 特征描述 、分布推断 、结构优化
数据清洗 :异常值判别 、缺失值处理、 数据结构统一(人为因素较多,无统一方法)
数据清洗和数据探索通常交互进行 数据探索有助于选择数据清洗方法 数据清洗后可以更有效的进行数据探索
数据清洗:1.异常值判别
数据清洗的第一步是识别会影响分析结果的“异常”数据,然后判断是否剔除。目前常用的识别异常数据的方法有物理判别法和统计判别法。
物理判别法:根据人们对客观事物、业务等已有的认识,判别由于外界干扰、人为误差等原因造成实测数据偏离正常结果,判断异常值。 比较困难。
统计判别法:给定一个置信概率,并确定一个置信限,凡超过此限的误差,就认为它不属于随机误差范围,将其视为异常值。 常用的方法(数据来源于同一分布,且是正态的):拉依达准则、肖维勒准则、格拉布斯准则、狄克逊准则、t检验。
慎重对待删除异常值:为减少犯错误的概率,可多种统计判别法结合使用,并尽力寻找异常值出现的原因;若有多个异常值,应逐个删除,即删除一个异常值后,需再行检验后方可再删除另一个异常值
检验方法以正态分布为前提,若数据偏离正态分布或样本较小时,则检验结果未必可靠,校验是否正态分布可借助W检验、D检验
常见统计判别法
|
判别方法 |
判别公式 |
剔除范围 |
操作步骤 |
评价 |
|
拉依达准则 (3σ准则) |
|
大于μ+3σ 小于μ-3σ |
求均值、标准差,进行边界检验,剔除一个异常数据,然后重复操作,逐一剔除 |
适合用于n>185时的样本判定 |
|
肖维勒准则(等概率准则) |
|
求均值、标准差,比对系数读取Zc(n)值,边界检验,剔除一个异常数据,然后重复操作,逐一剔除 |
实际中Zc(n)<3,测算合理,当n处于[25,185]时,判别效果较好 |
|
|
格拉布斯准则 |
异常检出水平: |
逐一判别并删除达到删除水平的数据;针对达到异常值检出水平,但未及删除水平的数据,应尽量找到数据原因,给以修正,若不能修正,则比较删除与不删除的统计结论,根据是否符合客观情况做去留选择 |
T(n, α)值与重复测量次数n及置信概率α均有关,理论严密,概率意义明确。当n处于[ 25, 185 ]时α=0.05,当n处于[ 3 ,25]时α=0.01,判别效果较好 |
|
|
狄克逊准则 |
|
f0 > f(n,α),说明x(n)离群远,则判定该数据为异常数据 |
将数据由小到大排成顺序统计量,求极差,比对狄克逊判断表读取 f(n,α)值,边界检验,剔除一个异常数据,然后重复操作,逐一剔除 |
异常值只有一个时,效果好;同侧两个数据接近,效果不好 当n处于[ 3 ,25]时,判别效果较好 |
|
T检验 |
|
分别检验最大、最小数据,计算不含被检验最大或最小数据时的均值及标准差,逐一判断并删除异常值 |
异常值只有一个时,效果好;同侧两个极端数据接近时,效果不好;因而有时通过中位数代替平均数的调整方法可以有效消除同侧异常值的影响 |
数据清洗:2.缺失值处理
在数据缺失严重时,会对分析结果造成较大影响,因此对剔除的异常值以及缺失值,要采用合理的方法进行填补,常见的方法有平均值填充、K最近距离法、回归法、极大似线估计法等
平均值填充:取所有对象(或与该对象具有相同决策属性值的对象)的平均值来填充该缺失的属性值;
K近邻距离法:先根据欧式距离或相关分析确定距离缺失数据样本最近的K个样本,将这K个值加权平均来估计缺失数据值;
回归:基于完整的数据集,建立回归方程(模型),对于包含空值的对象,将已知属性值代入方程来估计未知属性值,以此估计值来进行填充;但当变量不是线性相关或预测变量高度相关时会导致估计偏差;
极大似然估计:在给定完全数据和前一次迭代所得到的参数估计的情况下计算完全数据对应的对数似然函数的条件期望(E步),后用极大化对数似然函数以确定参数的值,并用于下步的迭代(M步);
多重差补法:由包含m个插补值的向量代替每一个缺失值,然后对新产生的m个数据集使用相同的方法处理,得到处理结果后,综合结果,最终得到对目标变量的估计
数据清洗规则总结为以下 4 个关键点,统一起来叫“完全合一”。
完整性:单条数据是否存在空值,统计的字段是否完善。
全面性:观察某一列的全部数值,比如在 Excel 表中,我们选中一列,可以看到该列的平均值、最大值、最小值。我们可以通过常识来判断该列是否有问题,比如:数据定义、单位标识、数值本身。
合法性:数据的类型、内容、大小的合法性。比如数据中存在非 ASCII 字符,性别存在了未知,年龄超过了 150 岁等。
唯一性:数据是否存在重复记录,因为数据通常来自不同渠道的汇总,重复的情况是常见的。行数据、列数据都需要是唯一的,比如一个人不能重复记录多次,且一个人的体重也不能在列指标中重复记录多次。
数据探索
通过数据探索,初步发现数据特征、规律,为后续数据建模提供输入依据,常见的数据探索方法有数据特征描述、相关性分析、主成分分析等。
特征描述:描述已有数据特征 数据分布特征描述
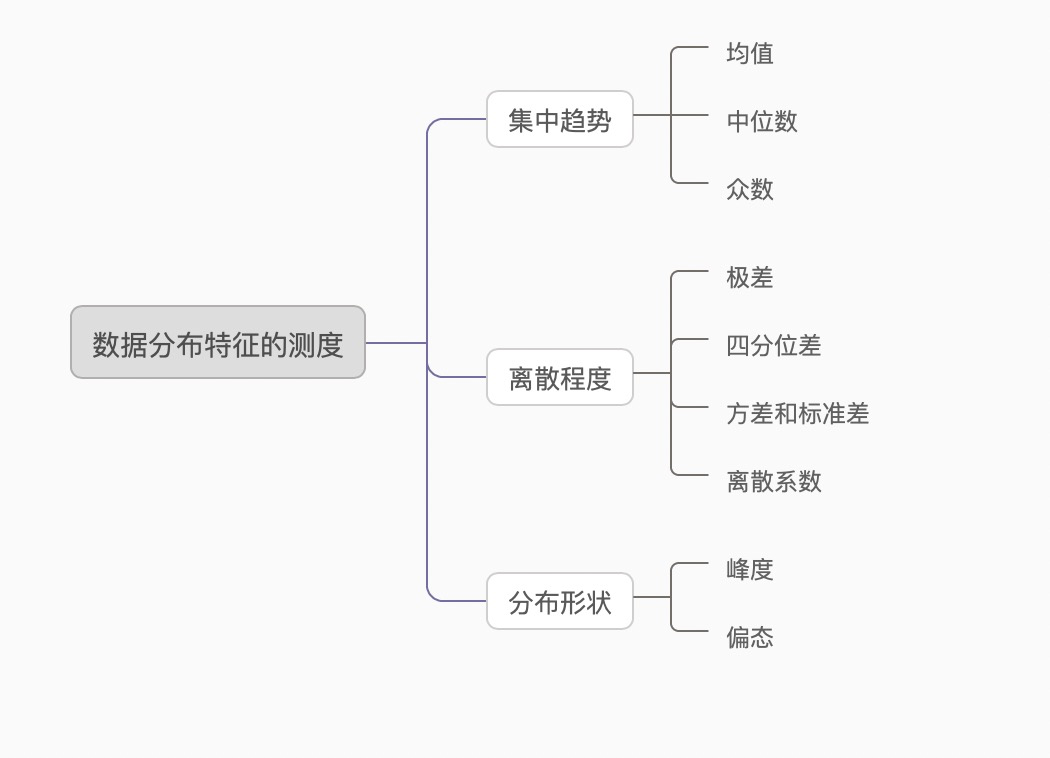
数据分布特征的测度 主要包括:集中趋势、离散趋势、分布的形状
集中趋势
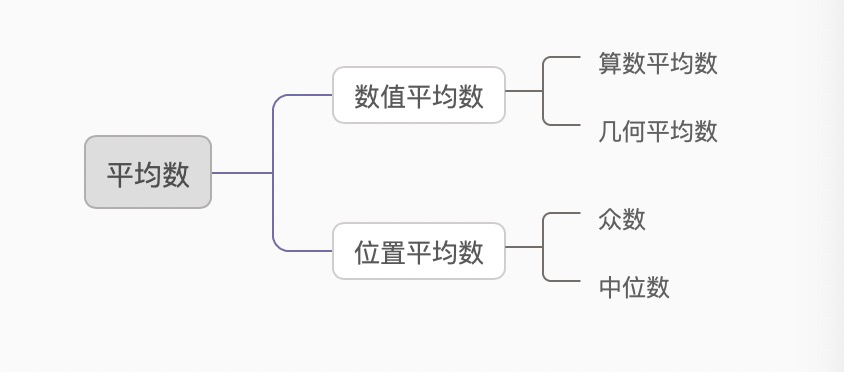
(1)算数平均数
简单算术平均数:
加权算术平均数:
(2)几何平均数
简单几何平均数
加权几何平均数
平均数为了排除极端值的干扰,可计算切尾均值
(3)众数
众数是一组数据中出现频数最多、频率最高的变量值
1.一组数据中出现次数最多的变量值
2.适合于数据量较多时使用
3.不受极端值的影响
4.一组数据可能没有众数或有几个众数
5.主要用于分类数据,也可用于顺序数据和数值型数据
(4)中位数
将总体各单位标志值按大小顺序排列后,指处于数列中间位置的标志值。
1.不受极端值的影响在有极端数值出现时,中位数作为分析现象中集中趋势的数值,比平均数更具有代表性
2.主要用于顺序数据,也可用数值型数据,但不能用于分类数据
3.各变量值与中位数的离差绝对值之和最小
众数、中位数、平均数的特点和应用
1.众数
不受极端值影响
具有不惟一一性
数据分布偏斜程度较大且有明显峰值时应用
2.中位数不受极端值影响
数据分布偏斜程度较大时应用
3.平均数
易受极端值影响
数学性质优良
数据对称分布或接近对称分布时应用
离散程度
1.极差
指所研究的数据中,最大值与最小值之差,又称全距。
2.四分位差
四分位差(quartile deviation),它是上四分位数(Q3,即位于75%)与下四分位数(Q1,即位于25%)的差。
计算公式为:Q =Q3-Q1
四分位差反映了中间50%数据的离散程度,其数值越小,说明中间的数据越集中;其数值越大,说明中间的数据越分散。四分位差不受极值的影响。此外,由于中位数处于数据的中间位置,因此,四分位差的大小在一定程度上也说明了中位数对一组数据的代表程度。四分位差主要用于测度顺序数据的离散程度。对于数值型数据也可以计算四分位差,但不适合分类数据。
四分位数是将一组数据由小到大(或由大到小)排序后,用3个点将全部数据分为4等份,与这3个点位置上相对应的数值称为四分位数,分别记为Q1(第一四分位数),说明数据中有25%的数据小于或等于Q1,Q2(第二四分位数,即中位数)说明数据中有50%的数据小于或等于Q2、Q3(第三四分位数)说明数据中有75%的数据小于或等于Q3。其中,Q3到Q1之间的距离的差的一半又称为分半四分位差,记为(Q3-Q1)/2。
3.方差
方差是在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。在许多实际问题中,研究方差即偏离程度有着重要意义。
方差是衡量源数据和期望值相差的度量值。
4.标准差
标准差(Standard Deviation) ,是离均差平方的算术平均数(即:方差)的算术平方根,用σ表示。标准差也被称为标准偏差,或者实验标准差,在概率统计中最常使用作为统计分布程度上的测量依据。
标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。平均数相同的两组数据,标准差未必相同。
分布形状
1.Pearson偏度系数是以标准差为度量单位计算的众数与算数平均数的离差,其计算公式是:
其中,m0是众数,sigma 是标准偏差。
SK通常取值为-3~+3之间,其绝对值大,表明偏斜程度大反之表明偏斜程度越小。
当SK=0时,分布为对称分布;
SK<0时,分布呈左偏分布,或称负偏态;
SK>0时,分布呈右偏斜分布,或称为正偏态
2.矩法偏度
Pearson偏度系数的思想比较容易理解,但精度程度不高。矩法偏度计算方法能够弥补这-不足,其计算公式是:
当SK=0时,分布为对称分布;
SK<0时,分布呈左偏分布,或称负偏态;
SK>0时,分布呈右偏斜分布,或称为正偏态。
峰态系数
在社会经济现象中,许多变量数列的分布曲线与正态分布曲线相比,其顶部的形态会有所不同,而这种差异通常具有重要的社会经济意义。
峰态系数就是反映数据分布峰值的高低,可以用来说明数据分布曲线的顶端尖削或扁平程度。以正态分布为参照标准,比正态分布尖削的分布为尖峰分布,比正态分布扁平的分布为平顶分布。
峰度的测量指标,常常可用标准差的四次方除以四阶中心矩的方法来计算,计算公式是:
当β=3时,数据的分布峰度表现为与正态相同;
当β>3时,为尖顶分布,表明数据分布曲线的顶部较正态分布曲线更为陡峭,且越大,顶部就越陡峭;
当β<3时,为平顶曲线,表明数据分布在众数附近比较分散,使得频数分布曲线的峰顶较正态分布曲线平缓,且值越小,顶部就越加平坦。
概率分布:推断整体数据特征 参数检验 非参数检验
概率分布可以表述随机变量取值的概率规律,是掌握数据变化趋势和范围的一个重要手段。

数据分布初步推断
假设检验是数理统计学中根据一定假设条件由样本推断总体的一种方法,可以分为参数检验和非参数检验。
参数检验:数据的分布已知的情况下,对数据分布的参数是否落在相应范围内进行检验
|
检验方法名称 |
问题类型 |
假设 |
适用条件 |
抽样方法 |
|
单样本T—检验 |
判断一个总体 平均数等于已知数 |
总体平均数等于A |
总体服从正态分布 |
从总体中抽取一个样本 |
|
F—检验 |
判断两总体方差相等 |
两总体方差相等 |
总体服从正态分布 |
从两个总体中各抽取一个样本 |
|
独立样本 T—检验 |
判断两总体平均数相等 |
两总体平均数相等 |
1、总体服从正态分布 2、两总体方程相等 |
从两个总体中各抽取一个样本 |
|
配对样本T—检验 |
判断指标实验前后平均数相等 |
指标实验前后平均数相等 |
1、总体服从正态分布 2、两组数据是同一试验对象在试验前后的测试值 |
抽取一组试验对象,在试验前测得试验对象某指标的值,进行试验后再测得试验对象该指标的取值 |
|
二项分布假设检验 |
随机抽样实验的成功概率的检验 |
总体概率等于P |
总体服从二项分布 |
从总体中抽取一个样本 |
非参数检验:一般是在不知道数据分布的前提下,检验数据的分布情况
|
检验方法名称 |
问题类型 |
假设 |
|
卡方检验 |
检测实际观测频数与理论频数之间是否存在差异 |
观测频数与理论频数无差异 |
|
K-S检验 |
检验变量取值是否为正态分布 |
服从正态分布 |
|
游程检验 |
检测一组观测值是否有明显变化趋势 |
无明显变化趋势 |
|
二项分布假设检验 |
通过样本数据检验样本来自的总体是否服从指定的概率为P的二项分布 |
服从概率为P的二项分布 |
总结:
1、参数检验是针对参数做的假设,非参数检验是针对总体分布情况做的假设;
2、二者的根本区别在于参数检验要利用到总体的信息,以总体分布和样本信息对总体参数作出推断;非参数检验不需要利用总体的信息;
特征优化:探索数据之间的关系 相关性分析 主成分分析
相关性分析
用于分析的多个变量间可能会存在较多的信息重复,若直接用来分析,会导致模型复杂,同时可能会引起模型较大误差,因此要初步探索数据间的相关性,剔除重复因素。
相关系数是考察变量之间的相关程度的变量,相关分析是优化数据结构的基础
二元变量相关分析
Pearson相关系数
特点:衡量两个变量线性相关性的强弱 在方差和协方差的基础上得到的,对异常值敏感
适用条件:服从正态分布或接近正态的单峰分布 、两个变量为连续数据
Spearman秩相关系数
特点:衡量两个变量之间联系(变化趋势)的强弱 ;在秩(排序)的相对大小基础上得到,对异常值更稳健
适用条件: 两个变量均为连续数据或等级数据
Kendall相关系数
特点:基于协同思想得到,衡量变量之间的协同趋势 ;对异常值稳健
适用条件:两个变量均为连续数据或等级数据
偏相关分析
研究两个变量之间线性相关关系时,控制可能对其产生影响的变量
距离相关分析
对观测量之间或变量之间相似或不相似程度的一种测度
检验动机:
样本数据只是总体的一个实现,因此,根据现有数据计算出来的相关系数只是变量相关系数的一个观测值,又称为样本相关系数。欲根据这个样本相关系数来估计总体相关系数,必须进行显著性检验。其原假设:在总体中,两个变量的相关系数(总体相关系数)为零
检验意义:
计算在原假设成立的情况下(也就是在两个变量相关系数为零的情况下),由于抽样的原因(收集样本数据的原因)得到当前的样本相关系数(可能这个系数并不为零,甚至还比较大)的概率。(p值越小说明越是小概率事件,不可能发生,拒绝原假设)
检验方法:
T检验(常用) :对于近似高斯分布的数据(如两个变量服从双变量正态分布), 相关系数的 样本分布 近似地服从自由度为N − 2的 t分布;如果样本容量不是特别小(通常大于30),即使观测数据不服从正态分布,依然可使用t检验。
主成分分析
Karl Pearson(1901)探究如何通过少数几个主成分(principal component)来解释多个变量间的内部结构时提出主成分分析法,旨在从原始变量中导出少数几个主分量,使其尽可能多地保留原始变量的信息,且彼此间互不相关
内涵:将彼此相关的一组指标变量转化为彼此独立的一组新的指标变量,并用其中较少的几个新指标变量就能综合反映原多个指标变量所包含主要信息的多元统计方法
应用:数据的压缩和解释,即常被用来寻找和简化判断事物或现象的综合指标,并对综合指标所包含的信息进行适当的解释
原理:设法将原来变量重新组合成一组新的互相无关的几个综合变量,同时根据实际需要从中可以取出几个较少的综合变量尽可能多地反映原来变量的信息的统计方法叫做主成分分析或称主分量分析,也是数学上用来降维的一种方法。
数据转换
数据转换或统一成适合于挖掘的形式,通常的做法有数据泛化、标准化、属性构造等,本文详细介绍数据标准化的方法,即统一数据的量纲及数量级,将数据处理为统一的基准的方法。
(1) 基期标准化法:
选择基期作为参照,各期标准化数据=各期数据/基期数据
(2)直线法:
极值法:
z-score法
(3)折线法
某些数据在不同值范围,采用不同的标准化方法,通常用于综合评价
(4)曲线法
Log函数法
Arctan函数法
对数函数法、模糊量化模式等
分类
定义:按照某种指定的属性特征将数据归类。需要确定类别的概念描述,并找出类判别准则。分类的目的是获得一个分类函数或分类模型(也常常称作分类器),该模型能把数据集合中的数据项映射到某一个给定类别。分类是利用训练数据集通过一定的算法而求得分类规则的。是模式识别的基础。分类可用于提取描述重要数据类的模型或预测未来的数据趋势。
分类的主要算法:KNN算法、决策树(CART、C4.5等)、SVM算法、贝叶斯算法、BP神经网络等
回归
定义;假定同一个或多个独立变量存在相关关系,寻找相关关系的模型。不同于时间序列法的是:模型的因变量是随机变量,而自变量是可控变量。分为线性回归和非线性回归,通常指连续要素之间的模型关系,是因果关系分析的基础。(回归研究的是数据之间的非确定性关系)
聚类分析
聚类分析对具有共同趋势或结构的数据进行分组,将数据项分组成多个簇(类),簇之间的数据差别应尽可能大,簇内的数据差别应尽可能小,即“最小化簇间的相似性, 最大化簇内的相似性”。
关联规则
时间序列分析
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/135321.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
